摘要:养成二阶思维的习惯是一个漫长、痛苦的过程,但坚持下来,总会收获很大。
本文分享自华为云社区《二阶思维》,作者:元闰子。
事情往往不是你想象的那样,有时候,看似解决了问题,却在不经意间,引发了更严重的后果。帮助我们思考、决策、解决问题的最有效方法是,运用二阶思维。
一阶思维是单纯而肤浅的,几乎人人都能做到;二阶思维则是深邃、复杂而迂回的,能做到的人少之又少。—— 霍华德·马克斯
我们的每一个行动都会导致一个后果,而每个后果,都会有进一步导致其他的后果。由行动直接导致的后果,我们称为一阶后果(First-Order Consequences);由一阶后果导致的,二阶、三阶… 后果,这里,我们统称为二阶后果(Second-Order Consequences)。
好的一阶后果,不见得会有好的二阶后果,很多时候,它们是反的。
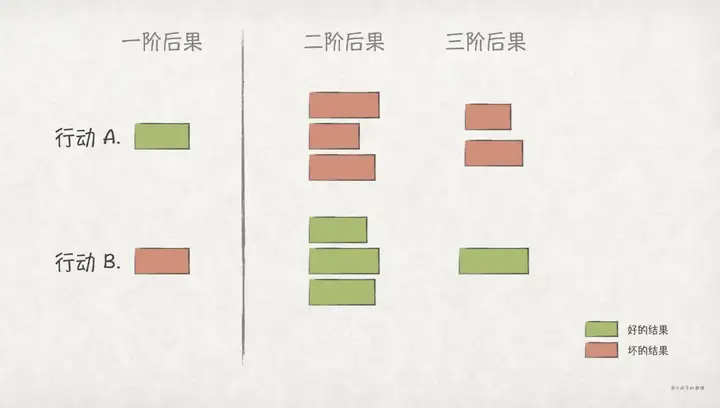
二阶思维(Second-Order Thinking),简单来说,就是做事情不能只看一阶后果,还要考虑二阶后果。相对于一阶思维,它更强调对问题的深入思考,从逻辑、系统、因果、时间等多种维度来综合考虑。
霍华德·马克斯在《投资最重要的事》中有举到一个股票投资的例子:
一阶思维的人,会这么想:“公司的前景是光明的,这表示股票会上涨”。
二阶思维的人,则会考虑到:
显然,二阶思维与一阶思维之间有着巨大的工作量差异,二阶思维对人的要求更高,实践起来也更复杂。
没有考虑二阶或者三阶后果,是造成众多痛苦而糟糕的决策的重要原因之一。—— 雷伊·达里奥
善用二阶思维,能帮助我们更好地决策、更好地找到问题根本从而解决问题。
以软件开发中需求管理为例。我们总说以客户为中心,那么,一阶思维者的做法,很有可能是,将客户/产品经理所提的每个需求都纳入到版本中。这种不假思索的做法,看似满足了客户的所有诉求,实际危害更大。它忽略了最重要的一点,开发的人力是有限的,从而很容易导致版本无法按时交付。

更好的方法是,运用二阶思维来进行需求的管理。
我们可以从多个维度来决策一个需求是否应该被纳入版本,比如,该需求能给客户带来多大的收益?在哪些场景下才有收益?没有它系统能不能正常运行?需求的工作量有多大?当前开发人力能不能满足?
这样,我们就能大致估算出每个需求的价值,然后对需求做价值的优先排序,最后根据当前的开发人力做需求裁剪。确保在交付时间点到时,我们能够为客户提供一个可用的、价值最大的软件系统。
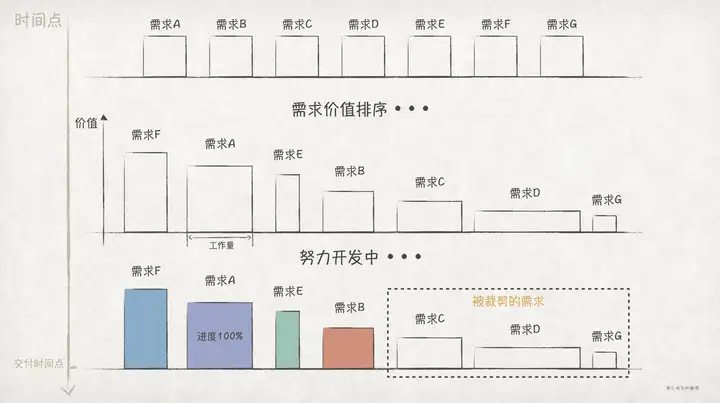
在决策中,我们用的是正向的二阶思维,也即,从眼前一步步往后推演出未来的各种可能性。
而在找问题根源时,我们用的是逆向的二阶思维,也即,从眼前要解决的问题开始,分析产生这个问题的原因,然后不断扩展、推演,一直找到问题根源。
比如,在《深入理解计算机系统的数值类型》中,有一个 double 转型为 float 的例子:
// Java
public static void main(String[] args) {
double d1 = 3.267393471324506;
System.out.print("double d1: ");
System.out.println(d1);
System.out.print("float d1: ");
System.out.println((float) d1);
}
// 输出结果
double d1: 3.267393471324506
float d1: 3.2673936从结果来看,转型的规则并不是简单的四舍五入。如果是一阶思维者,很容易会这样想,浮点数的转换应该存在精度丢失,然后就结束了。
如果是二阶思维者,你一定会有这样的疑问,为什么会得到这样的转换结果?
那么,接下来,你很可能就会这样干:

看,经过这样的层层追溯,我们最终找到了问题的答案!
经济领域中,最关键的是不管别人对你说什么,你总要问:“然后呢?”。 这个方法可以应用于几乎其他所有领域。所以,你必须经常问:“然后呢?”—— 沃伦.巴菲特
二阶思维并不是与生俱来的,它更像是一种习惯,需要我们不断地实践、总结、养成。
当你决定做一件事情前,总要问自己:“然后呢”?
这时,可以拿出你的笔,在纸上列出一阶后果、二阶后果、三阶后果、…,把所能想到的可能性都显现地列举出来,以帮助我们更好地决策。
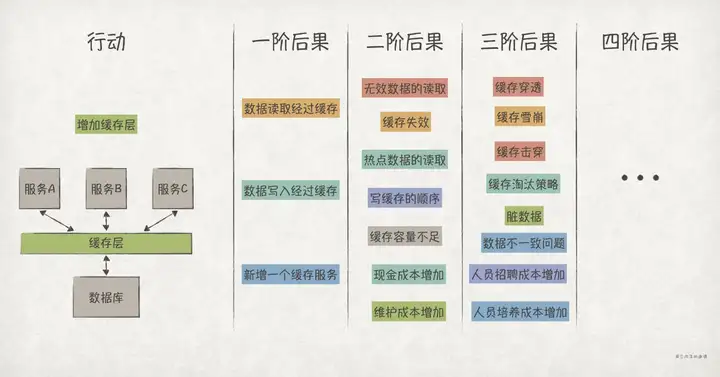
比如,作为架构师的你,想在业务服务和数据库之间加上一层缓存,来优化数据读性能。那么,在系统设计时,你不能仅仅看到这一点,而应该运用二阶思维,尽可能地,把增加缓存之后可能出现的现象/结果,都列出来,分析一遍:
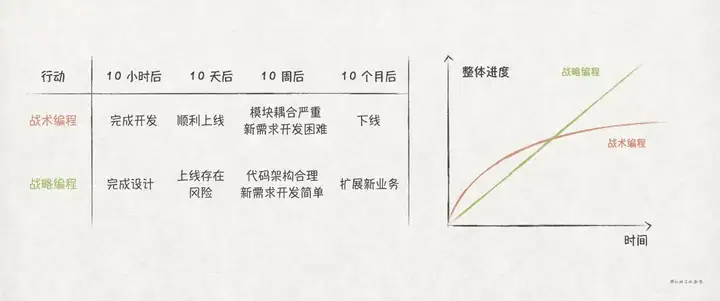
在做决策前,在时间维度上多加考虑,如果做了这件事,10 小时之后会怎样?10 天之后会怎样?10 周之后会怎样?10 个月之后会怎样?10 年之后会怎样?
比如,在《一步步降低软件复杂性》提到的 战术编程 与 战略编程 的例子,我们总是偏向战术编程,因为它能够节省大量开发时间,更快地完成需求交付。但是,当你从时间的维度来考虑时,结果就会有所不同:
另一个典型的例子是,背单词。我们总认为每天背 10 个单词好像没有多大用处,要是真能坚持下来,1 年就能认识 3650 个单词,2 年就是 7300 个单词,10 年后是 3 万多个。所以,不要低估时间的力量。
接触一个知识,碰到一个问题,多问几个:“为什么”?
要养成问 “为什么” 的习惯,通过质疑,不断找到现象或问题的根本所在。
对于一个知识,如果没有经过深度思考,只能算暂时记住,并不能纳入到你的知识体系中。
比如,对于 SSL/TLS 协议建立连接的过程,如果只是流于表面地把它背下来,可能你会因此通过面试,却无法深入理解其背后所涉及的密码学、数字证书、网络通信等原理知识(详见《假如让你来设计SSL/TLS协议》)。
对于一个问题,如果没有定位到根因,临时的规避做法,往往会导致更严重的后果。
比如,在一个分布式系统中,当出现服务请求超时现象时,一阶思维者的做法,很有可能是,通过增加请求超时时长来规避问题。然而,出现请求超时的原因有很多,如果是下游服务处理不过来导致的,增加超时时长只会让问题愈发恶劣,更好的做法是增加流控机制。
所以,多问几个“为什么”,找到根源,才能更好地解决问题。
相比一阶思维,二阶思维能够让我们更好地做出决策、找到问题的根源。但这需要更深入的思考,耗费的时间和精力也会更多。
这与人类的天然惰性是相违背的,就像在《懒惰》里提到的,“读书很容易,但思考很难”。
好消息是,二阶思维是一种习惯,能够通过不断地练习来养成。本文列出了 3 个比较容易实践的锻炼方法:
养成二阶思维的习惯是一个漫长、痛苦的过程,但坚持下来,总会收获很大。
[1] Second-Order Thinking: What Smart People Use to Outperform, Mental Models
[2] 二阶思维Second-Order Thinking——让你脱颖而出的思维方式, 芒格学院
[3] 投资最重要的事情, 霍华德·马克斯
[4] 深入理解计算机系统的数值类型, 元闰子
[5] 懒惰, 元闰子
[6] 假如让你来设计SSL/TLS协议, 元闰子
我最近从C#转向了Ruby,我发现自己无法制作可折叠的标记代码区域。我只是想到做这种事情应该没问题:classExamplebegin#agroupofmethodsdefmethod1..enddefmethod2..endenddefmethod3..endend...但是这样做真的可以吗?method1和method2最终与method3是同一种东西吗?还是有一些我还没有见过的用于执行此操作的Ruby惯用语? 最佳答案 正如其他人所说,这不会改变方法定义。但是,如果要标记方法组,为什么不使用Ruby语义来标记它们呢?您可以使用
安全产品安全网关类防火墙Firewall防火墙防火墙主要用于边界安全防护的权限控制和安全域的划分。防火墙•信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。防火墙是一个由软件和硬件设备组合而成,在内外网之间、专网与公网之间的界面上构成的保护屏障。下一代防火墙•下一代防火墙,NextGenerationFirewall,简称NGFirewall,是一款可以全面应对应用层威胁的高性能防火墙,提供网络层应用层一体化安全防护。生产厂家•联想网御、CheckPoint、深信服、网康、天融信、华为、H3C等防火墙部署部署于内、外网编辑额,用于权限访问控制和安全域划分。UTM统一威胁管理(Un
如果我说x.hello()在Java中,对象x正在“调用”它包含的方法。在Ruby中,对象x正在“接收”它包含的方法。这只是表达相同想法的不同术语,还是意识形态上的根本差异?来自Java,我发现Ruby的“接收器”想法非常令人困惑。也许有人可以解释这与Java的关系? 最佳答案 在您的示例中,x不调用hello()。包含该片段的任何对象都是“调用”(即,它是“调用者”)。在Java中,x可以称为接收者;它正在接收对hello()方法的调用。 关于java-Java中的"caller"和R
在aws-s3中,有一种方法(AWS::S3::S3Object.stream)可让您将S3上的文件流式传输到本地文件。我无法在aws-sdk中找到类似的方法。即在aws-s3中,我这样做:File.open(to_file,"wb")do|file|AWS::S3::S3Object.stream(key,region)do|chunk|file.writechunkendendAWS::S3:S3Object.read方法确实将block作为参数,但似乎没有对其执行任何操作。 最佳答案 aws-sdkgem现在支持S3中对象的分
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
在C#中你可以这样做:varlist=newList(){1,2,3,4,5};list.skip(2).take(2);//returns(3,4)我正在尝试学习所有Ruby可枚举方法,但我没有看到skip(n)的等效方法a=[1,2,3,4,5]a.skip(2).take(2)#takeexists,skipdoesn't那么,“最好的”Ruby方法是什么?所有这些都有效,但它们非常丑陋。a.last(a.length-2).take(2)(a-a.first(2)).take(2)a[2...a.length].take(2) 最佳答案
我正在使用Rails5(Ruby2.4)。我想阅读.xls文档,我想将数据转换为CSV格式,就像它出现在Excel文件中一样。有人推荐我使用Roo,所以我有book=Roo::Spreadsheet.open(file_location)sheet=book.sheet(0)text=sheet.to_csvarr_of_arrs=CSV.parse(text)但是,返回的内容与我在电子表格中看到的内容不同。例如,电子表格中的一个单元格有16:45.81当我从上面获取CSV数据时,返回的是"0.011641319444444444"如何解析Excel文档并准确获取我所看到的内容?我不在
与Smalltalk类层次结构浏览器最接近的等效项是什么?我见过一些解决方法,例如this,但它似乎不可编写脚本。 最佳答案 确实没有,至少没有包含静态和动态行为的类似Smalltalk的UI。Eclipse和IntelliJ都具有一定的结构洞察力。Eclipse有一种类似于浏览器的View。两者最大的问题是,除非您正在处理实时对象(例如,调试),否则您不一定知道对象的所有行为,因为有些行为是在运行时定义的。没有图像或部分运行时的静态View无法提供完整的图片。IntelliJ在解决问题方面做得不错。例如,具有attr_access
我刚刚在编程语言ruby中发现了一个奇怪的问题,这不是什么大问题,但我就是不明白为什么会这样。如果有人知道我的问题的问题,我会很感兴趣。在ruby中你可以写成0或者00,没关系,结果是一样的。如果您运行0===00,您还会得到true,这意味着两个输入完全相同。0.0也等于0,所以逻辑上00.0也应该等于0.0但问题是,如果你尝试使用数字00.0那么你只会得到一个错误。例如,如果您运行:a=00.0你得到这个错误:syntaxerror,unexpectedtINTEGER当然我知道这是个小问题,但如前所述,我想了解为什么计算机不将00.0视为与0.0相同?
文章目录背景一、最初的疑惑二、简单聊聊原理三、组织内实践案例四、实践带来的反思五、最后聊几句问题背景这个概念由来已久,但是在国内兴起,是最近几年;低代码即Low-Code;指提供可视化开发环境,可以用来创建和管理软件应用;简单的说就是可以通过各种组件的拖拽,实现页面的创建,交互流程和逻辑,以及数据层面的管理,更加高效的实现需求;早先在数据公司时;见识过低代码的应用,也参与过部分研发,比如元数据平台,BI分析等;不过,当时还是以数据管理的工具来定义项目,并非是低代码;从「2020年底」开始;实际上,那个时间节点,低代码平台的应用已经形成趋势了;现在的公司,将低代码平台的使用规划到业务体系中;后来