hello,大家好呀,我是小楼。
最近无聊(摸)闲逛(鱼)github时,发现了一个阿里开源项目可以贡献代码的地方。
不是写单测、改代码格式那种,而是比较有挑战的性能优化,最关键的是还不难,仔细看完本文后,有点基础就能写出来的那种,话不多说,发车!

相信大家在日常写代码获取时间戳时,会写出如下代码:
long ts = System.currentTimeMillis();
读者中还有一些Gopher,我们用Go也写一遍:
UnixTimeUnitOffset = uint64(time.Millisecond / time.Nanosecond)
ts := uint64(time.Now().UnixNano()) / UnixTimeUnitOffset
在一般情况下这么写,或者说在99%的情况下这么写一点问题都没有,但有位大佬研究了Java下时间戳的获取:
http://pzemtsov.github.io/2017/07/23/the-slow-currenttimemillis.html
他得出了一个结论:并发越高,获取时间戳越慢!
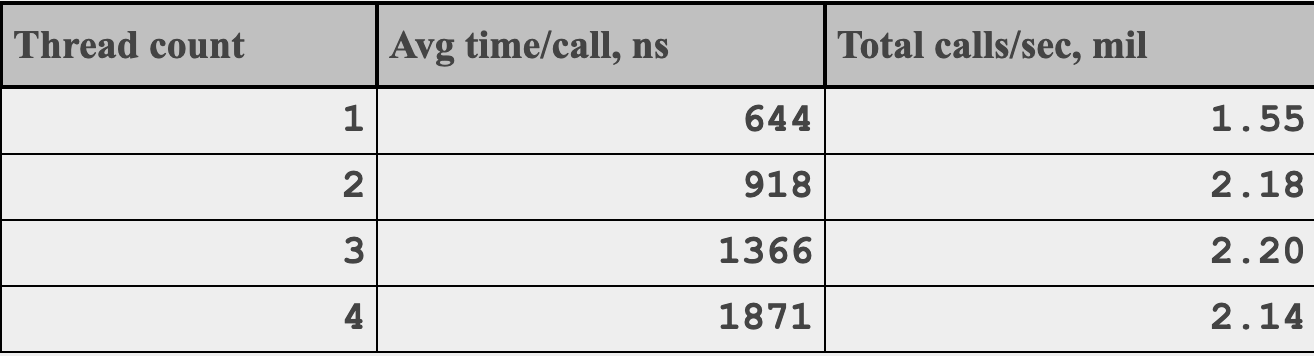
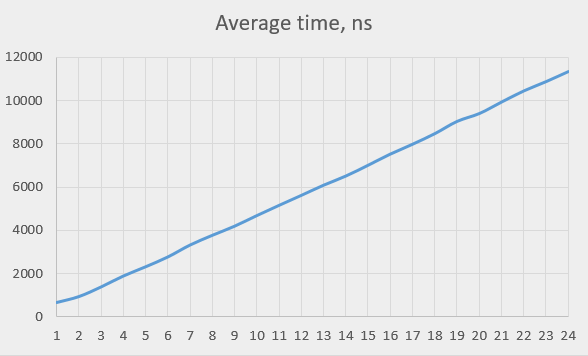
具体到细节咱也不是很懂,大概原因是由于只有一个全局时钟源,高并发或频繁访问会造成严重的争用。
我最早接触到用缓存时间戳的方式来优化是在Cobar这个项目中:
由于Cobar是一款数据库中间件,它的QPS可能会非常高,所以才有了这个优化,我们瞅一眼他的实现:
/**
* 弱精度的计时器,考虑性能不使用同步策略。
*
* @author xianmao.hexm 2011-1-18 下午06:10:55
*/
public class TimeUtil {
private static long CURRENT_TIME = System.currentTimeMillis();
public static final long currentTimeMillis() {
return CURRENT_TIME;
}
public static final void update() {
CURRENT_TIME = System.currentTimeMillis();
}
}
timer.schedule(updateTime(), 0L, TIME_UPDATE_PERIOD); // TIME_UPDATE_PERIOD 是 20ms
...
// 系统时间定时更新任务
private TimerTask updateTime() {
return new TimerTask() {
@Override
public void run() {
TimeUtil.update();
}
};
}
Cobar之所以这么干,一是因为往往他的QPS非常高,这样可以减少获取时间戳的CPU消耗或者耗时;其次是这个时间戳在Cobar内部只做统计使用,就算不准确也并无大碍,从实现上看也确实是弱精度。
后来我也在其他的代码中看到了类似的实现,比如Sentinel(不是Redis的Sentinel,而是阿里开源的限流熔断利器Sentinel)。
Sentinel作为一款限流熔断的工具,自然是自身的开销越小越好,于是同样都是出自阿里的Sentinel也用了和Cobar类似的实现:缓存时间戳。
原因也很简单,尽可能减少对系统资源的消耗,获取时间戳的性能要更优秀,但又不能和Cobar那样搞个弱精度的时间戳,因为Sentinel获取到的时间戳很可能就决定了一次请求是否被限流、熔断。
所以解决办法也很简单,直接将缓存时间戳的间隔改成1毫秒
去年我还写过一篇文章《低开销获取时间戳》,里面有Sentinel这段代码:
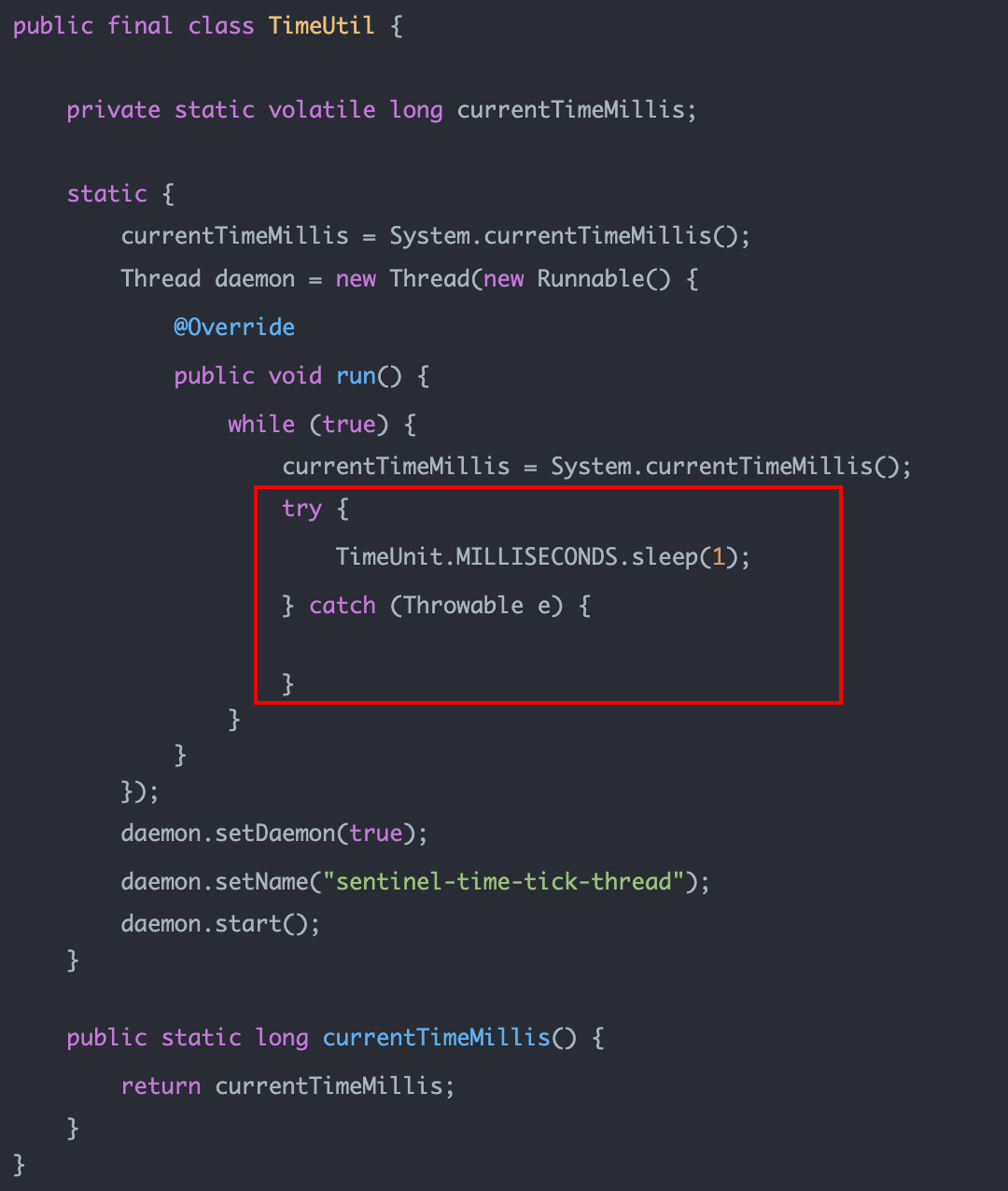
甚至后来的Sentinel-Go也采取了一模一样的逻辑:
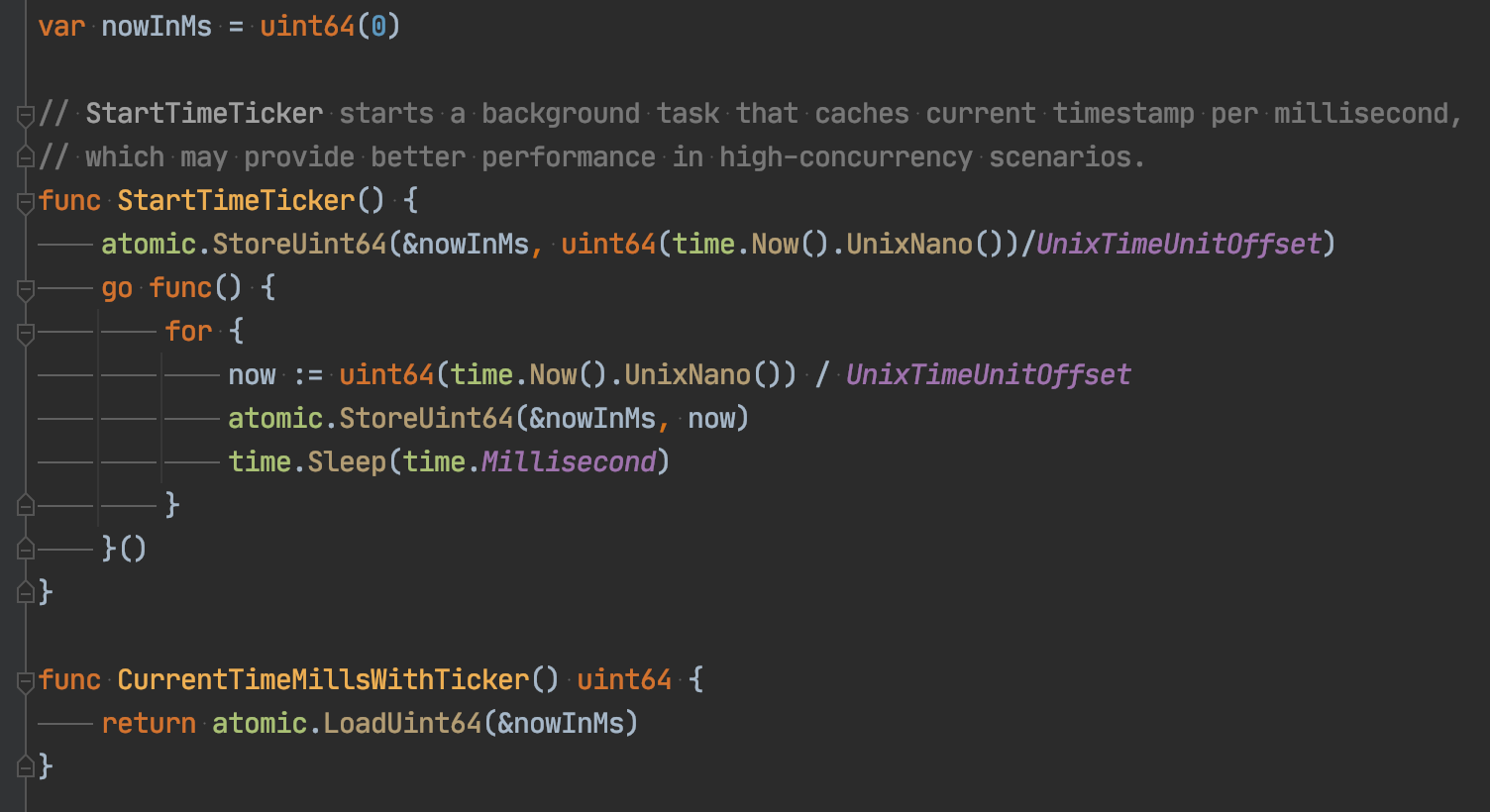
以前没有多想,认为这样并没有什么不妥。
直到前两天晚上,没事在Sentinel-Go社区中瞎逛,看到了一个issue,大受震撼:
提出这位issue的大佬在第一段就给出了非常有见解的观点:
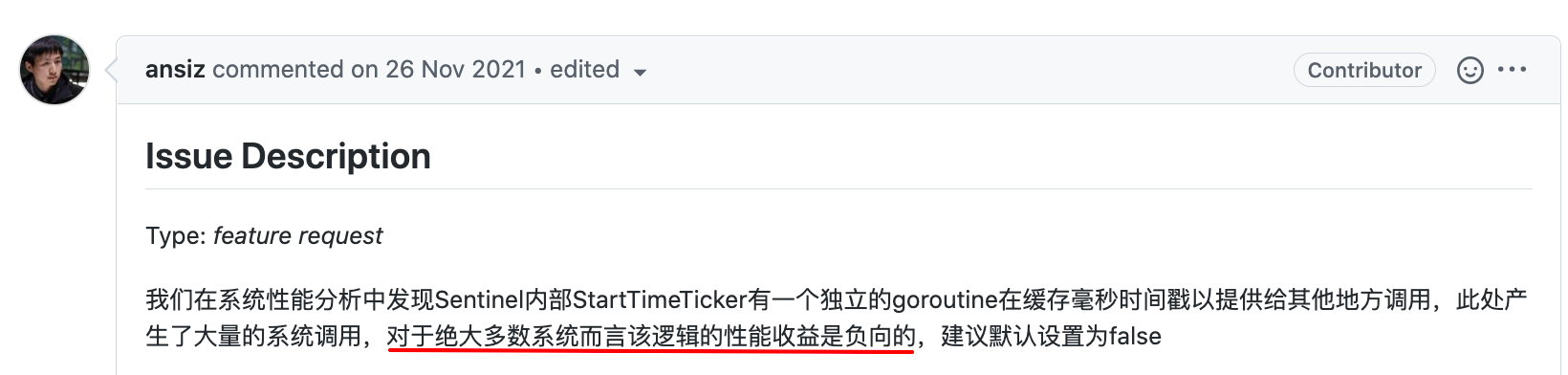
说的比较委婉,什么叫「负向收益」?
我又搜索了一下,找到了这个issue:
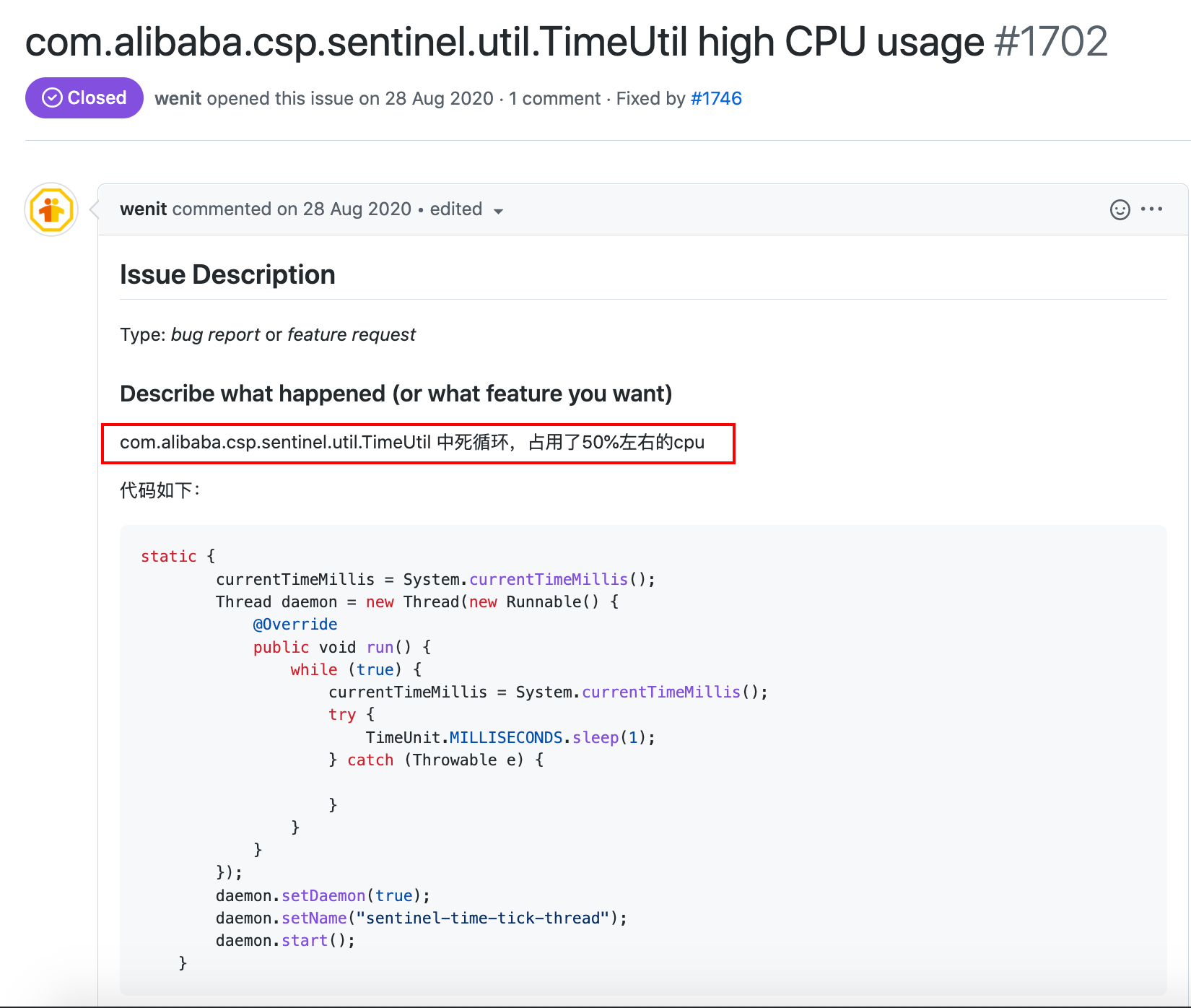
TimeUtil吃掉了50%的CPU,这就是「负向收益」,还是比较震惊的!

看到这个issue,我简单地想了下:
但这只是我们的想当然,如果有数据支撑就又说服力了。为此前面提出「负向收益」的大佬做了一系列分析和测试,我们白嫖一下他的成果:

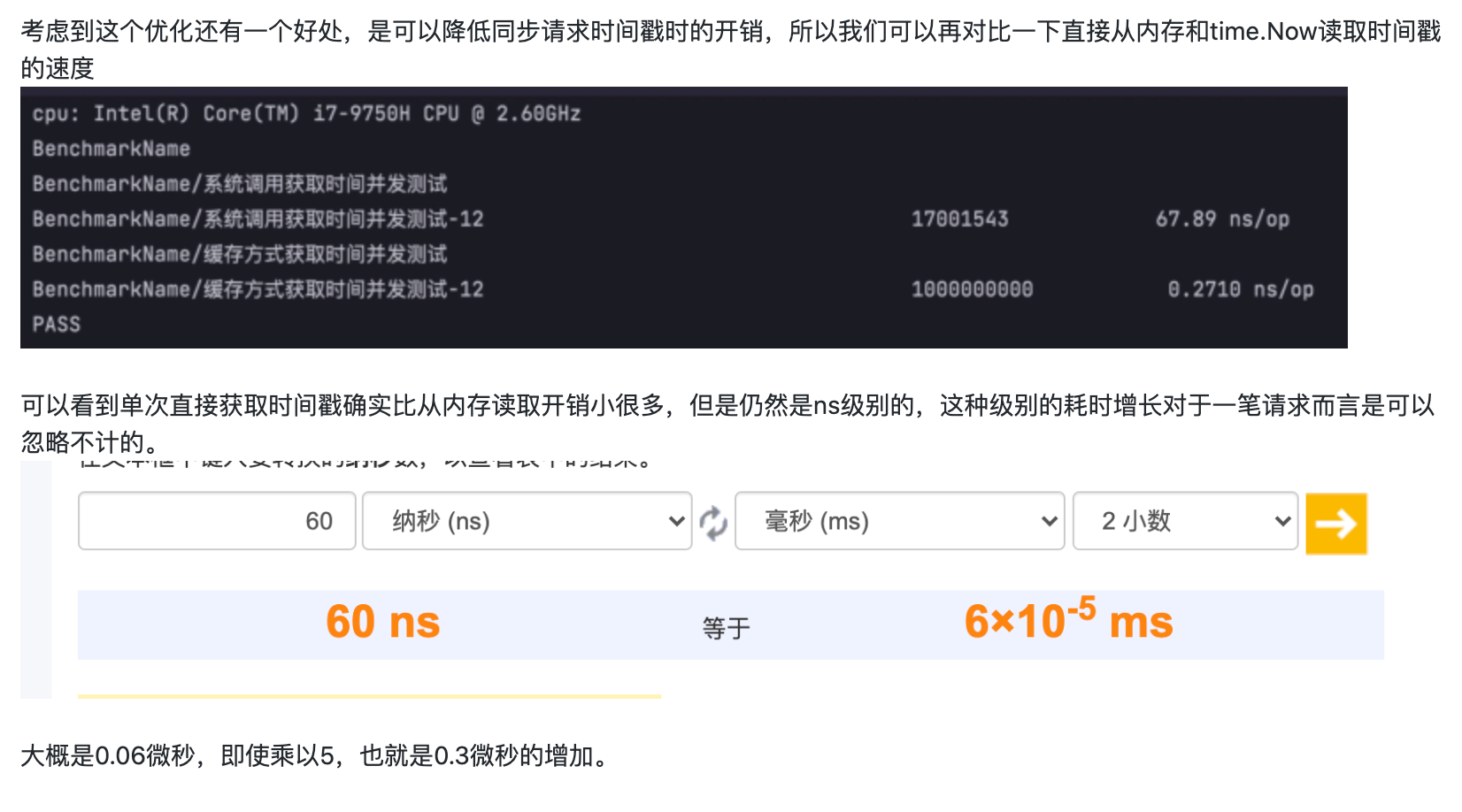
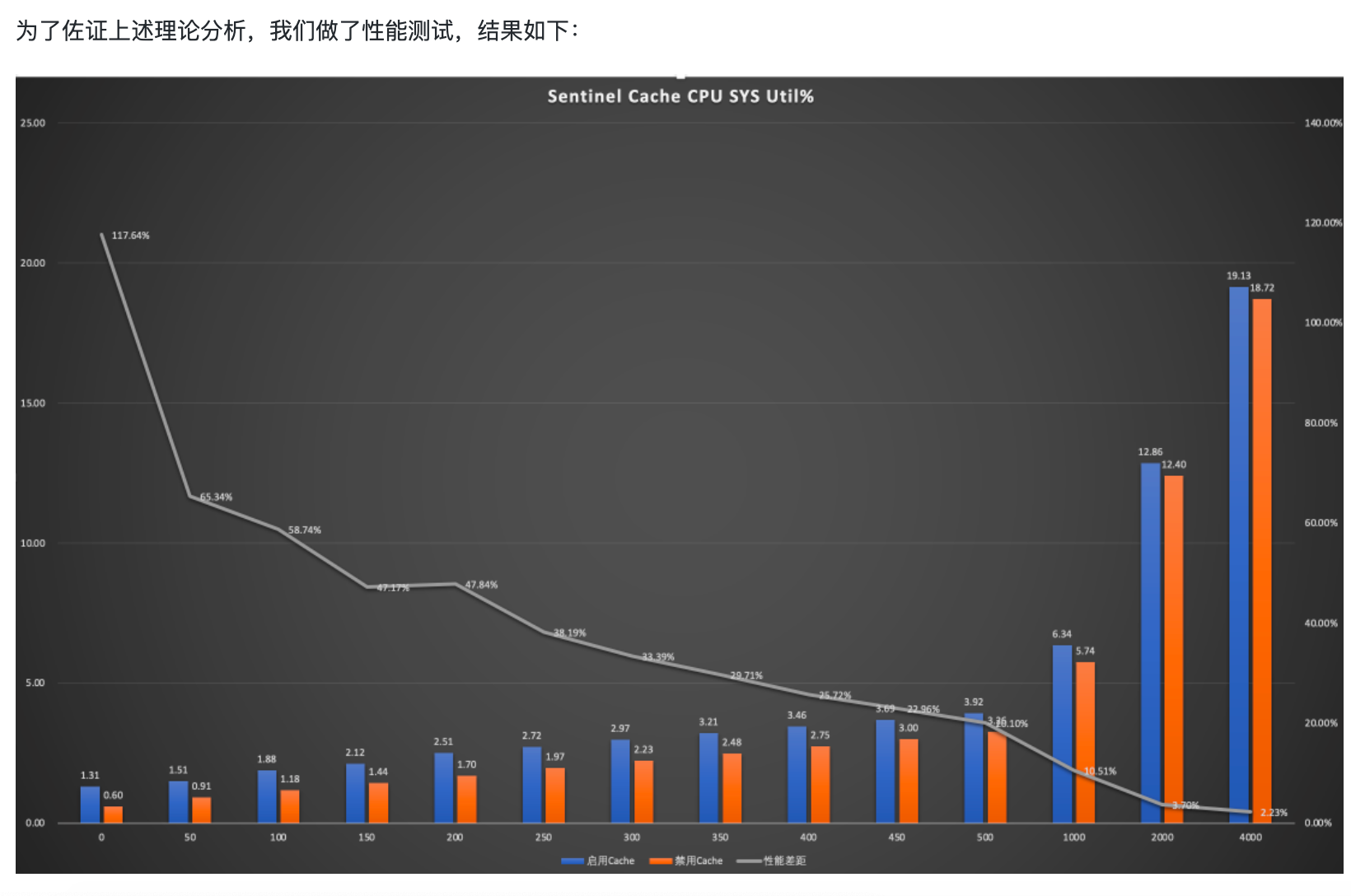
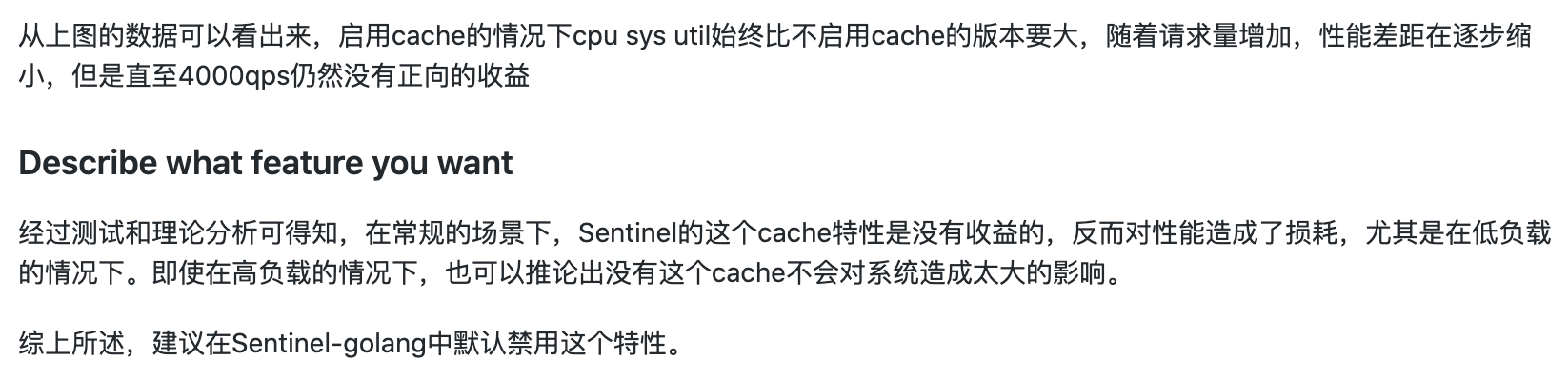
看完后我跪在原地,久久不能起身。

课代表来做个总结:
这一顿操作下来,连Sentinel社区的大佬也觉得很棒,竖起来大拇指:

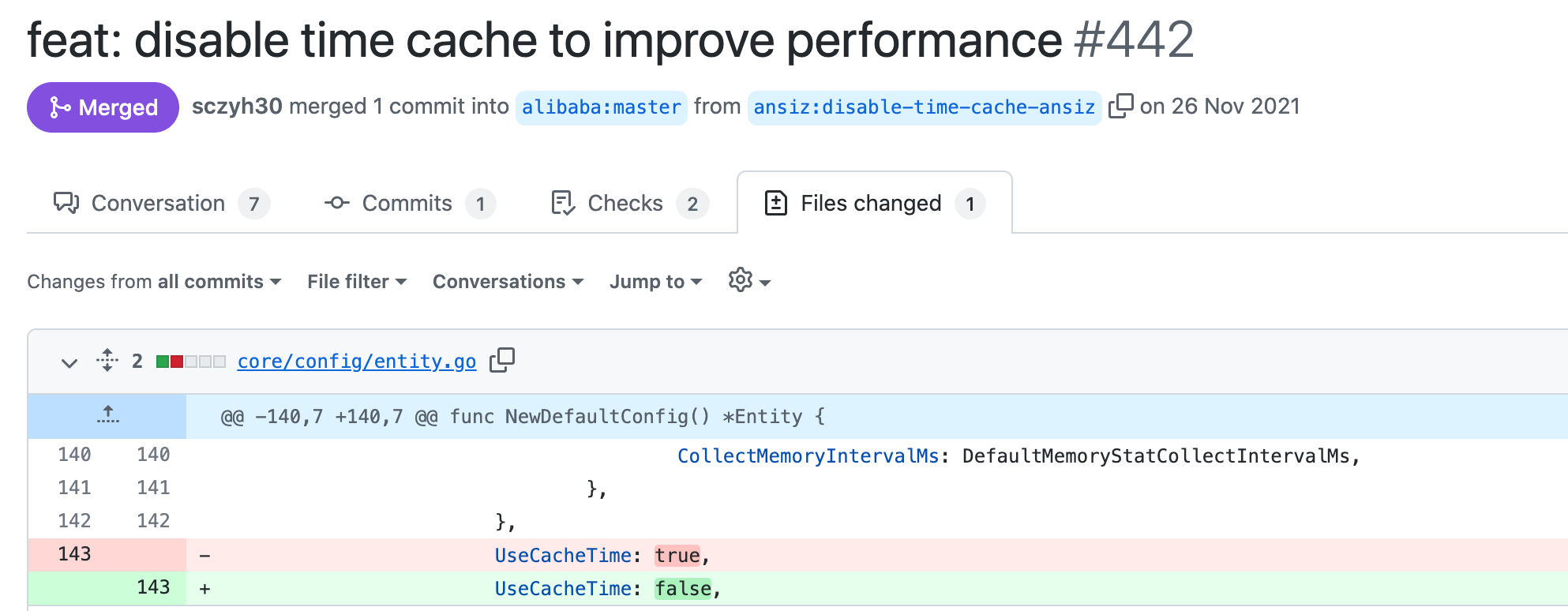
然而做了这么多测试,最后的修改就只是把true改成false:
本来我以为看到这位大佬的测试已经是非常有收获了,没想到接下去的闲逛又让我发现了一个更了不得的东西。
既然上面分析出来,在QPS比较高的情况下,收益才能抵消被抵消,那么有没有可能实现一个自适应的算法,在QPS较低的时候直接从系统获取,QPS较高时,从缓存获取。
果不其然,Sentinel(Java版,版本>=1.8.2)已经实现了!
我们捋一下它的实现:

我们首先看最核心的缓存时间戳的循环(每毫秒执行1次),在这个循环中,它将缓存时间戳分成了三个状态:
这三个状态怎么流转呢?答案在开头调用的check方法中:
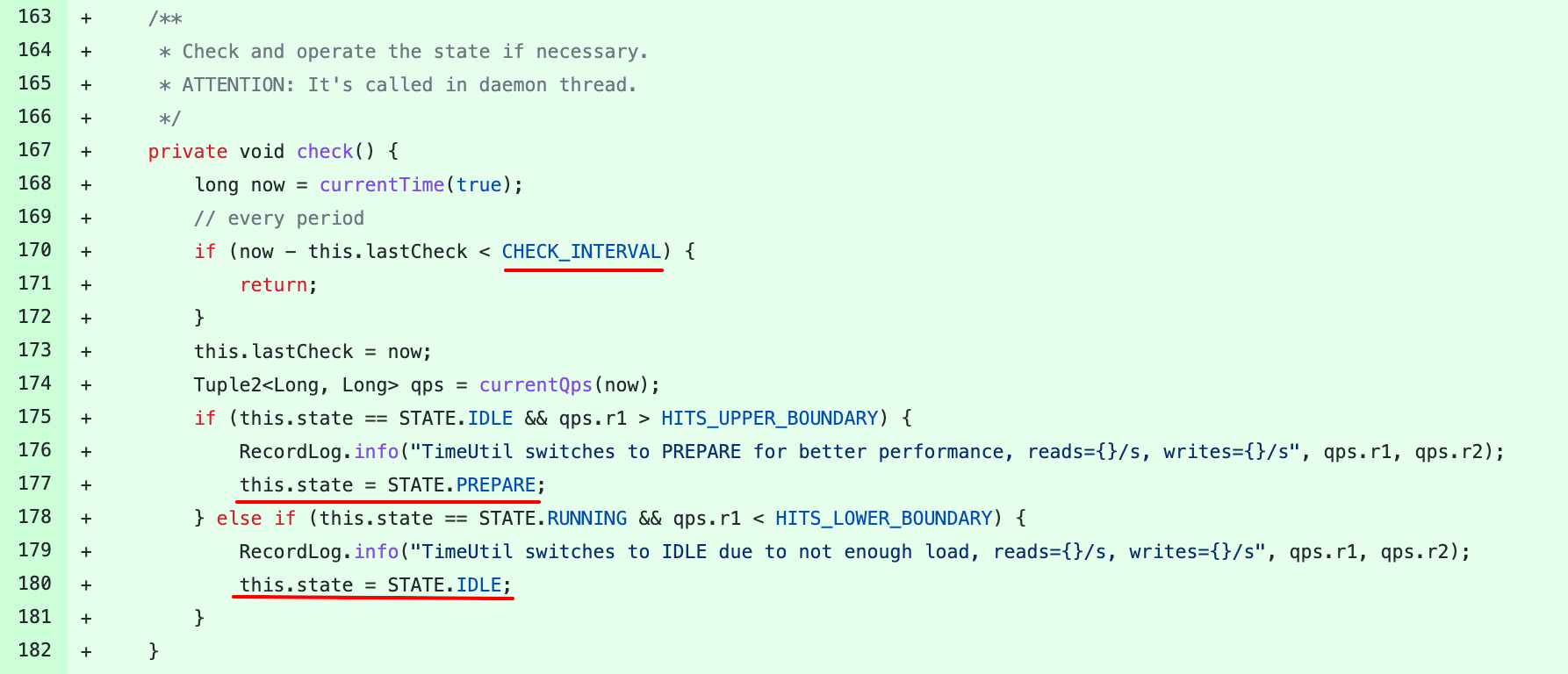
首先check逻辑有个间隔,也就是每隔一段时间(3秒)来做一次状态转换;
其次如果当前状态是空闲态并且读QPS大于HITS_UPPER_BOUNDARY(1200),则切换为准备态。
如果当前状态是运行态且读QPS小于HITS_LOWER_BOUNDARY(800),则切换为空闲态。
发现似乎少了切换到运行态的分支,看上面的循环中,第三个准备态的分支运行一次就将状态切换为运行态了。
这是为啥?其实准备态只是为了让程序从空闲态切换到运行态时过渡的更平滑,因为空闲态下缓存时间戳不再更新,如果没有过渡直接切换到运行态,那可能切换后获取的时间戳是有误差的。
文字可能不直观,我们画一个状态流转图:
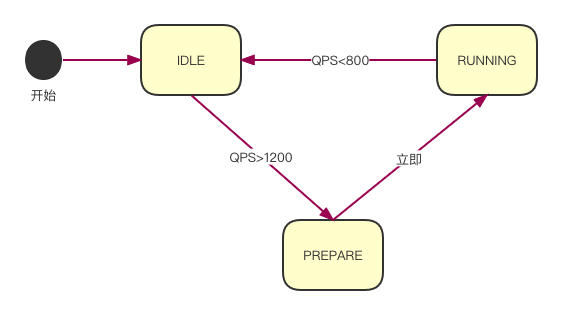
最后这些准备好了,获取时需要做两件事:一是统计读时间戳的QPS,二是获取时间戳;如果是空闲态或准备态则直接获取系统时间返回,如果是运行态则从缓存中拿时间戳。

当程序比较空闲时,不会缓存时间戳,降低CPU的消耗,QPS较高时缓存时间戳,也能降低CPU的消耗,并且能降低获取时间戳的时延,可谓是一举两得。
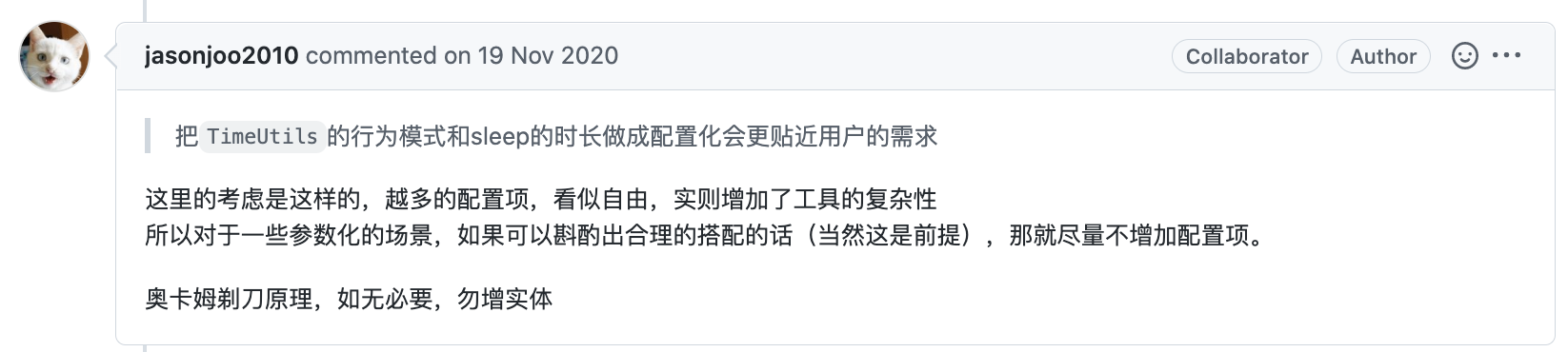
但这中间我有个疑问,这里QPS的高低边界不知道是如何得出的,是拍脑袋还是压测出来的,不过这个数值似乎并不一定绝对准确,可能和机器的配置也有关系,所以我倾向这个值可以配置,而不是在代码中写死,关于这点,这段代码的作者也解释了原因:
最后可能你会问,这QPS咋统计呀?
这可是Sentinel的强项,利用LeapArray统计,由于这不是本文重点,就不展开了,有兴趣可以参考我之前的文章《Sentinel-Go 源码系列(三)滑动时间窗口算法的工程实现》,虽然文章是Go的,但算法和Java的是一模一样,甚至实现都是照搬。
有没有测试数据支撑呢?有另一位大佬在评论区贴出了他的测试数据,我们看一下:
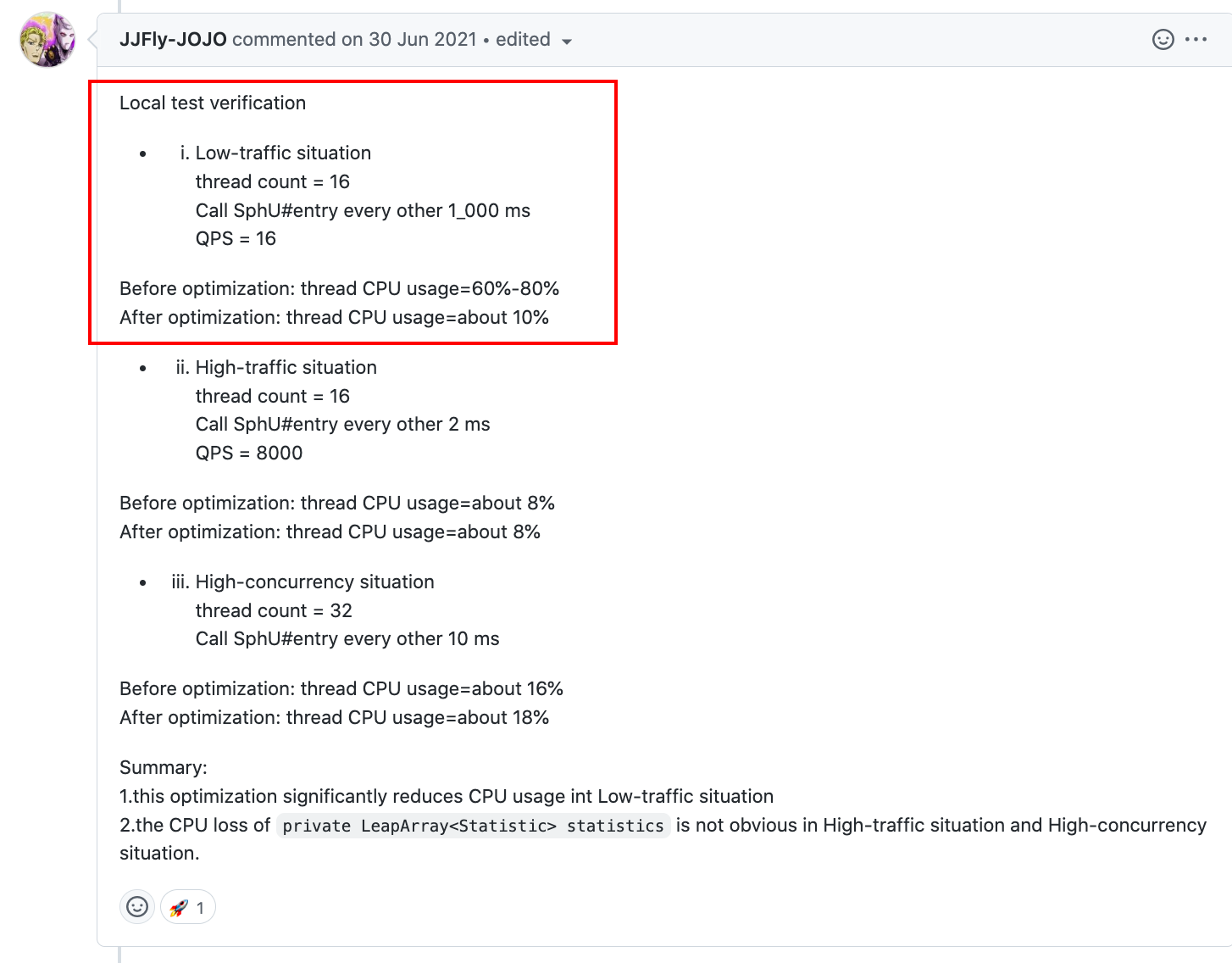
在低负载下,CPU消耗降低的特别明显,高负载则没什么变化,这也符合我们的预期。
看到这里你是不是觉得该点题了?没错,Sentinel-Go还没实现上述的自适应算法,这是个绝佳的机会,有技术含量,又有参考(Java版),是不是心动了?
社区中也有该issue:
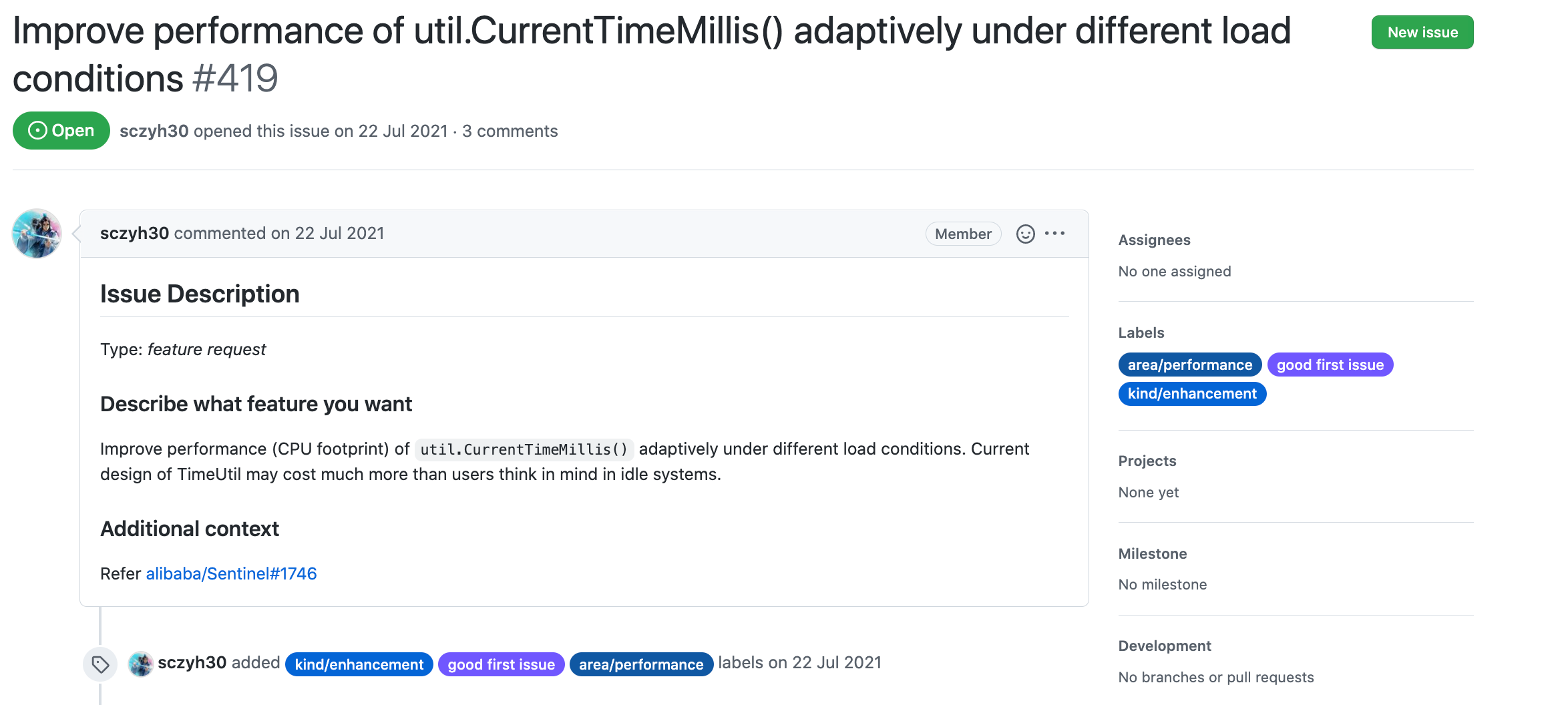
这个issue在2021年8月有个哥们认领了,但截止目前还没贡献代码,四舍五入等于他放弃了,所以你懂我意思吧?
如果你觉得文章还可以,麻烦动动小手,点个关注、在看、赞,你的鼓励是我持续创作的动力!
对了,如果觉得还不过瘾,可以再看看这些相关文章:
感谢阅读,我们下期再见~
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b