文章目录
urllib、urllib2、urllib3、request均能通过网络访问互联网上的资源文件,它们通过使用统一资源定位符(URL)并结合re模块完成很多意想不到的操作。
注意: 在Python2中urllib和urllib2一般搭配使用的(不然Python2整两个内置库干嘛),urllib具有urllib2没有的功能,而urllib2具有urllib没有的功能。如urllib2可以接受请求对象来设置URL请求的头,urllib只接受URL;urllib提供用于生成GET查询字符串的urlencode方法,urllib2没有这样的函数。这就是为什么urllib经常与urllib2一起使用的原因之一。
urllib这个Python标准库基本上包含了基础的网络请求功能,以下urllib的演示均为Python3中的用法,Python2中单独用urllib会比较难受,上面也提到了它最好配合urllib2一起使用。
urlopen()方法发起请求,read()方法获取网页数据
from urllib import request
res = request.urlopen("http://httpbin.org/get")
print(res.read().decode()) # red()方法读取的数据是bytes的二进制格式,需要解码
urlopen()默认是GET方式请求,当传入data参数时会发起POST请求,此时传递的参数必须时bytes格式
from urllib import request
res = request.urlopen("http://httpbin.org/post", data=b'hello=world')
print(res.read().decode())
通过urllib发起的请求默认的头信息是"User-Agent": “Python-urllib/3.6”,一般网站会验证请求头的合法性,如果需要修改可以通过urllib.request中的Request对象
from urllib import request
url = "http://httpbin.org/get"
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
req = request.Request(url=url, headers=headers) # 传递的Request对象
res = request.urlopen(req)
print(res.read().decode())
此时httpbin网站返回的内容如下:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
},
"origin": "210.33.11.241, 210.33.11.241",
"url": "https://httpbin.org/get"
}
在使用爬虫时经常会配置代理隐藏我们的IP地址
from urllib import request
url = 'http://httpbin.org/ip'
proxy = {'http': '117.95.200.71:9999', 'https': '183.154.54.188:9999'} # 可以使用西刺代理配置
# 创建代理处理器
proxies = request.ProxyHandler(proxy)
# 创建opener对象
opener = request.build_opener(proxies)
resp = opener.open(url)
print(resp.read().decode())
from urllib import request
url = 'http://httpbin.org/image/jpeg'
request.urlretrieve(url, '1.jpg')
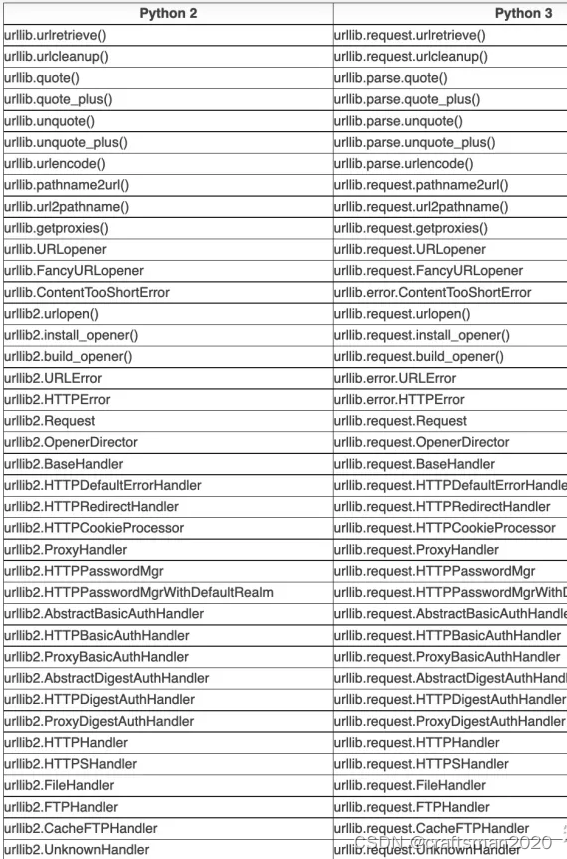
urllib2的用法其实基本和urllib相似,且它只存在于Python2版本,它的使用时需要配合urllib一起使用,要说它和urllib的区别还要看下面这个表,下表主要说明了在Python2中的urllib、urllib2中的方法整合到Python3后方法名的区别。
这里展示了一个官方使用urllib2的GET请求
import urllib2
res = urllib2.urlopen("http://httpbin.org/get")
print res.read().decode()
urllib3说一个HTTP客户端Python库,Python2和Python3在未安装的情况下均可以使用pip install urllib3即可安装,它提供了很多urllib库中没有的重要特性: 线程安全 连接池 客户端SSL/TLS验证 文件分部编码上传 协助处理重复请求和HTTP重定位 支持gzip和deflate压缩编码 支持HTTP和SOCKS代理 100%测试覆盖率
urllib3主要的特点就是在请求之前需要创建一个连接池对象
import urllib3
http = urllib3.PoolManager() # 线程池生成请求
res = http.request('GET', 'http://httpbin.org/get')
print(res.data.decode())
post请求只需要将request()方法的第一个参数改为POST,并设置fields参数即可
import urllib3
http = urllib3.PoolManager() # 线程池生成请求
res = http.request('POST', 'http://httpbin.org/post', fields={'hello': 'world'})
print(res.data.decode())
设置headers的方法和设置参数一样方便,只需要加入headers参数即可
headers = {'X-Something': 'value'}
res = http.request('POST', 'http://httpbin.org/post', headers=headers, fields={'hello': 'world'})
最后介绍一个杀手级神器——requests,你会发现它一样也很好用,requests使用了urllib3的库,并且继承了所有urllib2的特性,最关键的是它不需要urllib3一样在编码时收到开启线程池,简单粗暴,不过它同样也要使用pip install requests安装。另外,requests会自动实现持久连接keep-alive
格外简单的演示:
import requests
res = requests.get('http://httpbin.org/get')
print(res.text)
在实际使用中推荐使用后两种,因为毕竟方便,而若时没有安装这些库的情况下,Python3的urllib也是一个不错的选择。
和urllib比较示例:
###urllib
from urllib import request,parse
import json
if __name__ == '__main__':
while True:
baseurl = 'http://fanyi.baidu.com/sug'
keyword = input('请输入你要查询的单词:')
data = {
'kw': keyword
}
data = parse.urlencode(data).encode() # 需要给数据编码,现在data是bytes格式,
#调试用的的话可以输入以下代码(已注释)
#data = parse.urlencode(data)
#print(data)
rsp = request.urlopen(baseurl, data=data)
json_data = rsp.read().decode()#解码后的数据是json格式,所以要import json
#print(json_data)
json_data = json.loads(json_data)
for i in json_data['data']:
print(i['k'], '---->', i['v'])
---------------------------------------------------------------------------------------
#####requests
import requests
if __name__ == '__main__':
while True:
baseurl = 'http://fanyi.baidu.com/sug'
keyword = input('请输入你要查询的单词:')
data = {
'kw': keyword
}
#这里不用给data进行编码
#但是下面要指明post方法
#rsp=requests.request('post',url=baseurl,data=data)
#上下两代码等价
rsp = requests.post(url=baseurl, data=data)
#而这里也不用导入 json模块,直接使用对象的json()方法即可
json_data = rsp.json()
for i in json_data['data']:
print(i['k'], '---->', i['v'])
总的来说,requests将urlib进行了更高级的封装,不用人为的编码解码,将其自动化,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
rails中是否有任何规定允许站点的所有AJAXPOST请求在没有authenticity_token的情况下通过?我有一个调用Controller方法的JqueryPOSTajax调用,但我没有在其中放置任何真实性代码,但调用成功。我的ApplicationController确实有'request_forgery_protection'并且我已经改变了config.action_controller.consider_all_requests_local在我的environments/development.rb中为false我还搜索了我的代码以确保我没有重载ajaxSend来发送
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识