文章目录
最近ChatGPT真是火的不行啊,准备针对ChatGPT出一个系列,帮助大家更好的理解,今天我们就简单聊聊ChatGPT的底层技术支持以及演进历程。
ChatGPT是由OpenAI团队研发创造, OpenAI是由创业家埃隆·马斯克、美国创业孵化器YCombinator总裁阿尔特曼、全球在线支付平台PayPal联合创始人彼得·蒂尔等人于2015年在旧金山创立的一家非盈利的AI研究公司,拥有多位硅谷重量级人物的资金支持,启动资金高达10亿美金;OpenAI的创立目标是与其它机构合作进行AI的相关研究,并开放研究成果以促进AI技术的发展。
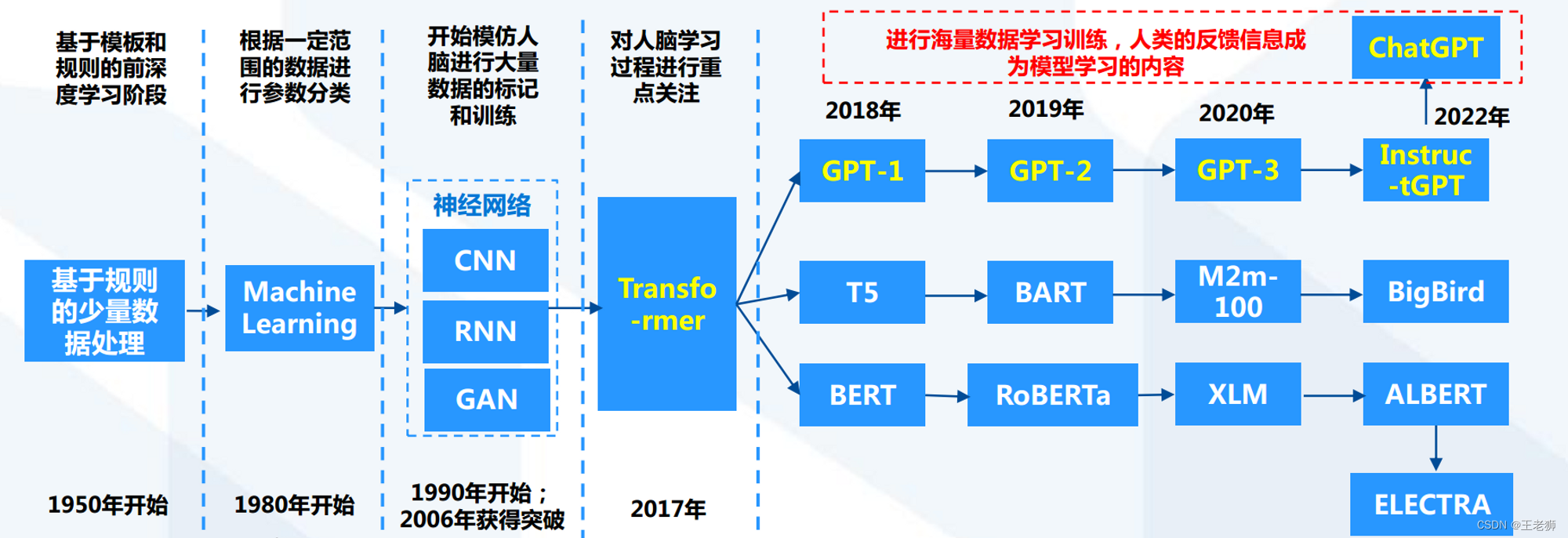
GPT即Generative Pre-training Transformer,于2018年6月由OpenAI首次提出。是一种自然语言处理模型,使用多层变换器来预测下一个单词的概率分布,通过训练在大型文本语料库上学习到的语言模式来生成自然语言文本从 GPT-1 到 GPT-3 智能化程度不断提升,ChatGPT 的到来也是 GPT-4 正式推出之前的序章。
转移学习的思想是将从一项任务中学习到的“知识”(例如,图像中的对象识别)应用于另一项任务(例如,视频中的活动识别)。在深度学习中,预训练又是转移学习的主要方法:在替代任务上训练模型(通常只是达到目的的一种手段),然后通过微调来适应感兴趣的下游任务。 基础模型通过转移学习和规模得以实现,因此转移学习使基础模型成为可能。
另外一个点就是基础模型的规模化训练。大规模化使基础模型更强大,因而GPT模型得以形成
大规模需要三个要素:
基于Transformer的序列建模方法现在应用于文本、图像、语音、表格数据、蛋白质序列、有机分子和强化学习等,这些例子的逐步形成使得使用一套统一的工具来开发各种模态的基础模型这种理念得以成熟。例如, GPT-3与GPT-2的15亿参数相比,GPT-3具有1750亿个参数,允许上下文学习,在上下文学习中,只需向下游任务提供提示,语言模型就可以适应下游有务, 这是产生的一种有兴属性。
Transformer摆脱了人工标注数据集的缺陷,模型在质量上更优、更易于并行化,所需训练时间明显更少
GPT-1模型基于Transformer解除了顺序关联和依赖性的前提,采用生成式模型方式,重点考虑了从原始文本中有效学习的能力,这对于减轻自然语言处理中对监督学习的依赖至关重要
GPT(Generative Pre-training Transformer)于2018年6月由OpenAI首次提出。 GPT模型考虑到在自然语言理解中有大量不同的任务,尽管大量的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据却很少,这使得经过区分训练的模型很难充分执行。 同时,大多数深度学习方法需要大量手动标记的数据,这限制了它们在许多缺少注释资源的领域的适用性。
在考虑以上局限性的前提下, GPT论文中证明,通过对未标记文本的不同语料库进行语言模型的生成性预训练 ,然后对每个特定任务 进行区分性微调,可以实现这些任务上的巨大收益。和之前方法不同,GPT在微调期间使用任务感知输入转换,以实现有效的传输,同时对模型架构的更改最小。

GPT-1模型的核心手段是预训练,GPT相比于Transformer等 模型进行了显著简化,相比于Transformer,GPT训练了一个12层仅decoder的解码器 。相比于Google的BERT,GPT仅采用上文 预测单词。
注: ChatGPT的表现更贴近人类意图,部分因为一开始GPT是基于上文的预测,这更贴近人类的话语模式,因为人类言语无法基于将来的话来做分析。
GPT-2在GPT-1的基础上进行诸多改进,实现执行任务多样性,开始学习在不需要明确监督的情况下执行数量惊人的任务。
在GPT-2阶段,OpenAI去掉了GPT-1阶段的有监督微调,成为无监督模型。大模型GPT-2是一个1.5B参数的Transformer,在其相关论文中它在8个测试语言建模数据集中的7个数据集上实现了当时最先进的结果。模型中,Transfomer堆叠至48层。 GPT-2的数据集增加到8 million的网页、大小40GB的文本。
机器学习系统通过使用大型数据集、高容量模型和监督学习的组合,在训练任务方 面表现出色,然而这些系统较为脆弱,对数据分布和任务规范的轻微变化非常敏感,因而使得AI表现更像狭义专家,并非通才。
GPT-2转向更通用的系统,使其可以执行许多任务,最终无需为每个任务手动创建和标记训练数据集。
GPT-2聚焦在无监督、 zero-shot(零次学习)上,然而GPT-2训练结果也有不达预期之处,所存在的问题也亟待优化。
在GPT-2阶段,尽管体系结构是任务无关的,但仍然需要任务特定的数据集和任务特定的微调:要在所需任务上实现强大的性能,通常需要对特定于该任务的数千到数十万个示例的数据集进行微调。
GPT-3是一个具有1750亿个参数的自回归语言模型,比之前的任何非稀疏语言模型多10倍。对于所有任务,GPT-3都是在没有任何梯度更新或微调的情况下应用的,仅通过与模型的文本交互来指定任务和few-shot演示。
GPT-3在许多NLP数据集上都有很强的性能,包括翻译、问题解答和完形填空任务,以及一些需要动态推理或领域适应的任务,如解译单词、在句子中使用一个新单词或执行三位数算术。 GPT-3可以生成新闻文章样本,并且已很难将其与人类撰写的文章区分开来。
当前openAi开源得最新模型就位GPT3,Git地址为:https://github.com/openai/gpt-3
InstructGPT使用来自人类反馈的强化学习方案RLHF,通过对大语言模型进行微调,从而能够在参数减少的情况下,实现优于GPT-3的功能
InstructGPT提出的背景:使语言模型更大并不意味着它们能够更好地遵循用户的意图,例如大型语言模型可以生成不真实、有毒或对 用户毫无帮助的输出,即这些模型与其用户不一致。另外, GPT-3虽然选择了少样本学习和继续坚持了GPT-2的无监督学 习,但基于few-shot的效果,其稍逊于监督微调的方式。
基于以上背景,OpenAI在GPT-3基础上根据人类反馈的强化学习方案RHLF,训练出奖励模型去训练学习模型(即:用AI训练AI的思路)
InstructGPT的训练步骤为:对GPT-3监督微调——训练奖励模型——增强学习优化SFT(第二、第三步可以迭代循环多次)
InstructGPT与ChatGPT属于相同代际的模型,ChatGPT只是在InstructGPT的基础上增加了Chat属性,并且开放了公众测试。ChatGPT提升了理解人类思维的准确性的原因在于利用了基于人类反馈数据的系统进行模型训练

注:根据官网介绍, GhatGPT也是基于InstructGPT构建,因而可以从InstructGPT来理解ChatGPT利用人类意图来增强模型效果
机器学习(ML)中的计算历史分为三个时代:前深度学习时代、深度学习时代和大规模时代,在大规模时代,训练高级ML系统的需求快速增长,计算、数据和算法的进步是指导现代机器学习进步的三个基本因素。在2010年之前,训练计算的增长符合摩尔定律,大约每20个 月翻一番。自2010年代早期深度学习问世以来,训练计算的规模已经加快,大约每6个月翻一番。 2015年末,随着公 司开发大规模ML模型,训练计算需求增加10至100倍,出现了一种新趋势——训练高级ML系统的需求快速增长。
2015-2016年左右,出现了大规模模型的新趋势。这一新趋势始于2015年末的AlphaGo ,并持续至今,ChatGPT大模型架构也是机器学习发展到第三阶段的必然产物。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项
我刚刚看到whitehouse.gov正在使用drupal作为CMS和门户技术。drupal的优点之一似乎是很容易添加插件,而且编程最少,即重新发明轮子最少。这实际上正是Ruby-on-Rails的DRY理念。所以:drupal的缺点是什么?Rails或其他基于Ruby的技术有哪些不符合whitehouse.org(或其他CMS门户)门户技术的资格? 最佳答案 Whatarethedrawbacksofdrupal?对于Ruby和Rails,这确实是一个相当主观的问题。Drupal是一个可靠的内容管理选项,非常适合面向社区的站点。它
如何使用Ruby(和Rails,如果有相关的辅助方法)获取最近发生的星期三?最终需要实际日期(5/1/2013)。 最佳答案 time=Time.nowdays_to_go_back=(time.wday+4)%7last_wed=days_to_go_back.days.ago 关于ruby-on-rails-获取最近发生的星期三?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代