1.1、MySQL 索引 是什么?
索引是一个单独的、存储在 磁盘 上的 数据库结构 ,包含着对数据表里 所有记录的 引用指针。
1.2、 MySQL 索引 的存储类型有哪些?
MySQL中索引的存储类型有两种,即 BTree 和 Hash。
1.3、MySQL 索引 在哪里实现的?
索引是在存储引擎中实现的。(MySQL 的存储引擎有:InnoDB、MyISAM、Memory、Heap)
1.4、存储引擎 是什么?
存储引擎就是指 表的类型 以及 表在计算机上的存储方式。
1.5、索引 的优缺点有哪些?
优点:
缺点:
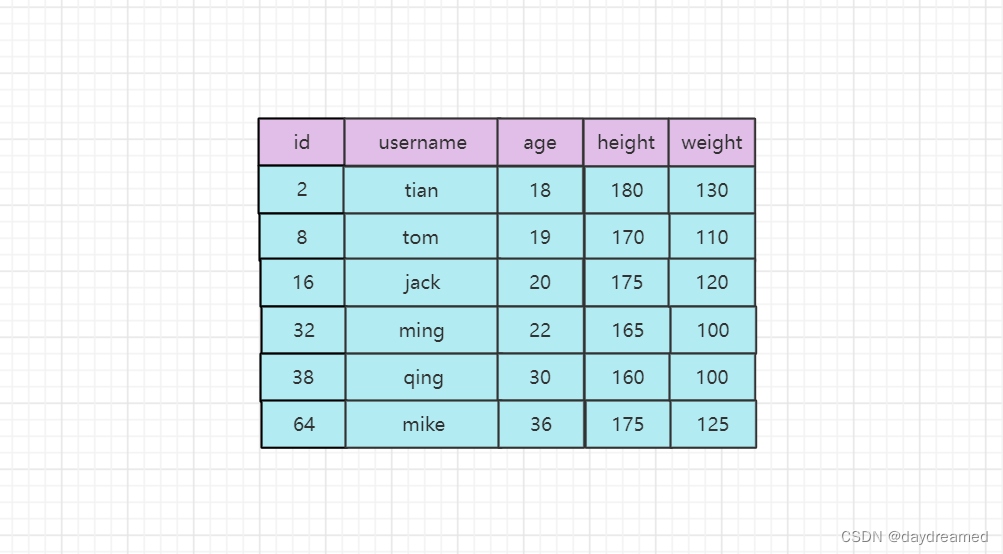
1、普通索引 和 唯一索引
普通索引:MySQL 中的基本索引类型,允许在定义索引的列中插入 重复值 和 空值
唯一索引:要求索引列的值必须 唯一,但允许 有空值
2、单列索引 和 组合索引
3、全文索引
4、空间索引
空间索引 是对 空间数据类型 的字段 建立的索引
MySQL中的空间数据类型有4种,分别是 Geometry、Point、Linestring 和 Polygon
MySQL 使用 Spatial 关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引
创建空间索引的列,不允许为空值,且只能在 MyISAM 的表中创建。
5、前缀索引
MySQL 索引 的数据结构可以分为 BTree 和 Hash 两种,BTree 又可分为 BTree 和 B+Tree。
Hash:使用 Hash 表存储数据,Key 存储索引列,Value 存储行记录或行磁盘地址。
Hash 只支持等值查询(“=”,“IN”,“<=>”),不支持任何范围查询(原因在于 Hash 的每个键之间没有任何的联系),Hash 的查询效率很高,时间复杂度为 O(1)。
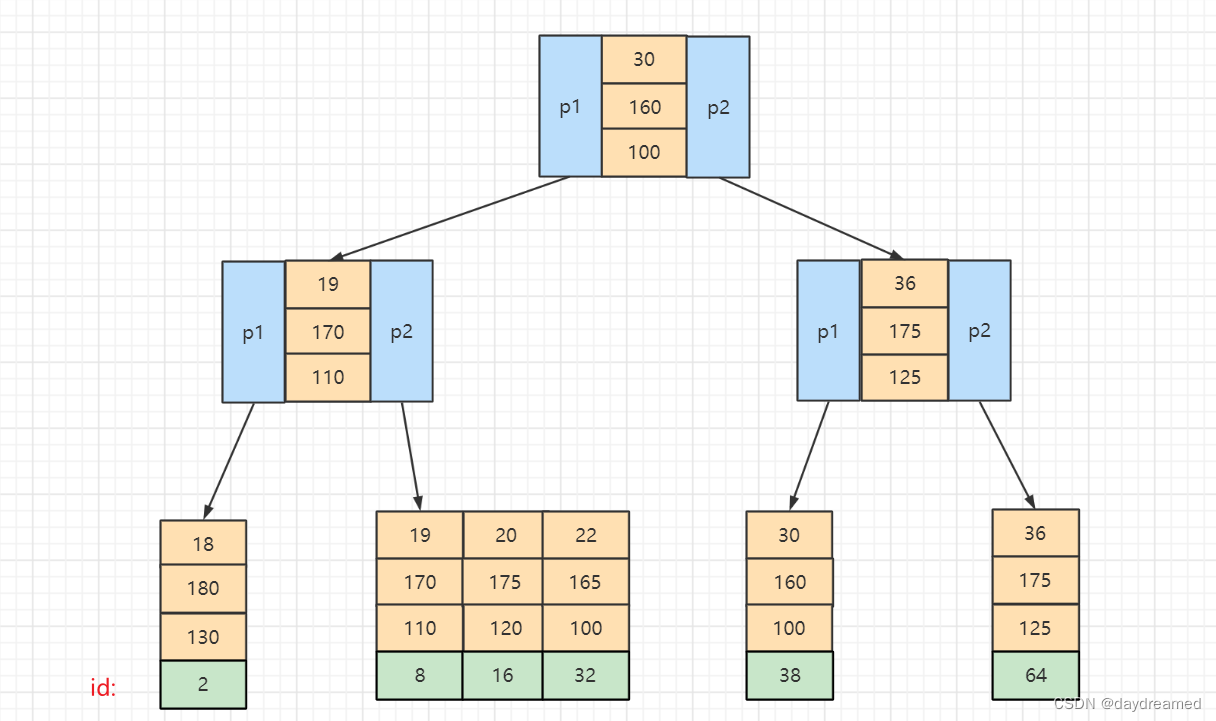
BTree:属于多叉树,又名多路平衡查找树。
性质:
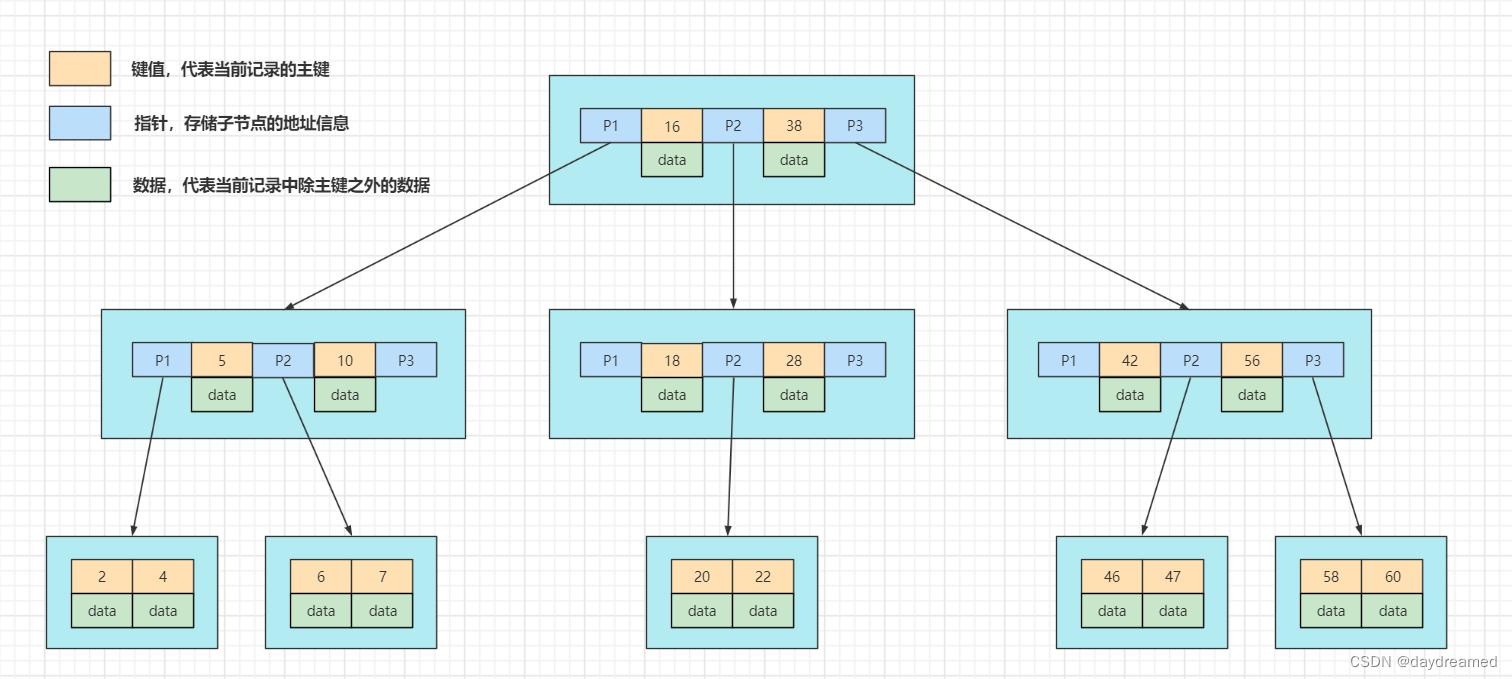
查询过程,例如:Select * from table where id = 6;
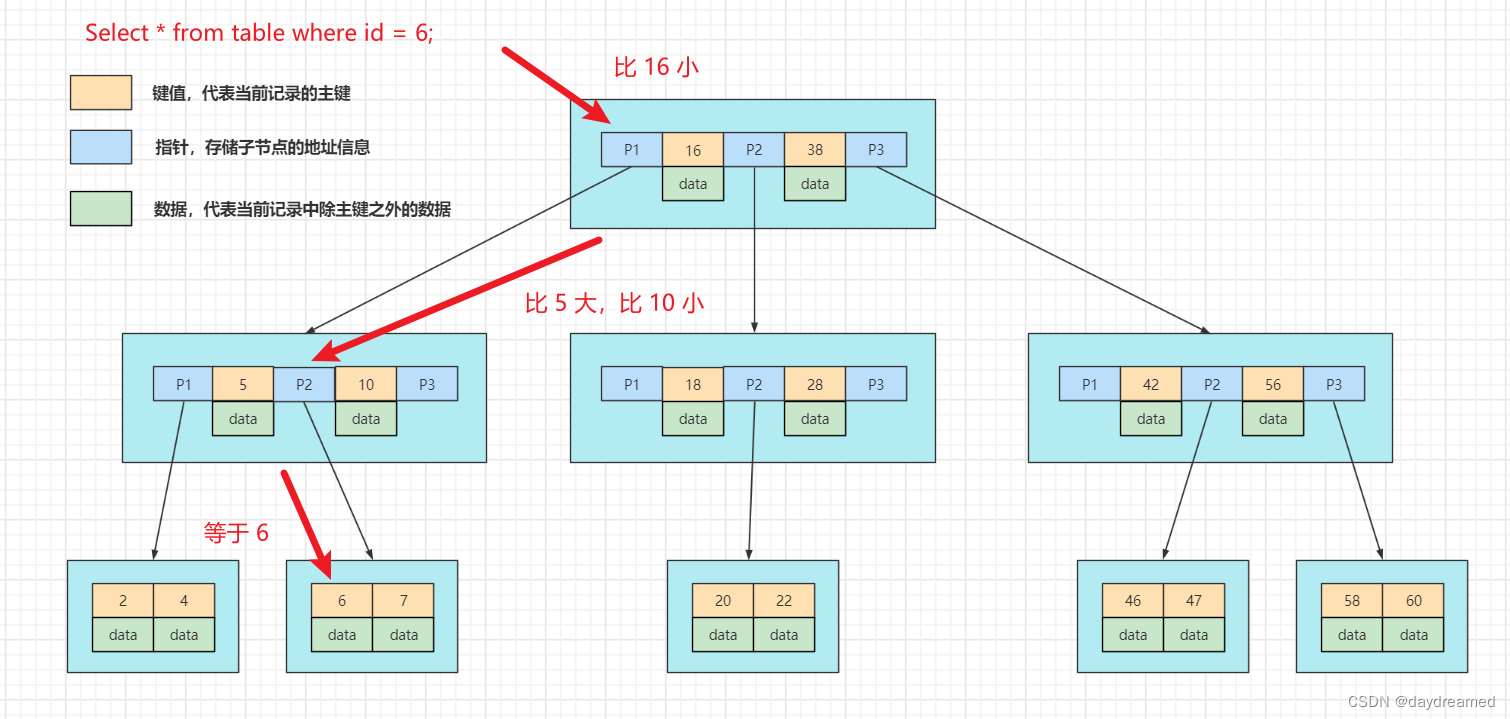
BTree 的不足:
B+Tree:在 BTree 的基本上,对 BTree 进行了优化:只有叶子节点才会存储 键值 - 数据,非叶子节点只存储 键值 和 子节点 的地址;叶子节点之间使用双向指针进行连接,形成一个双向有序链表。
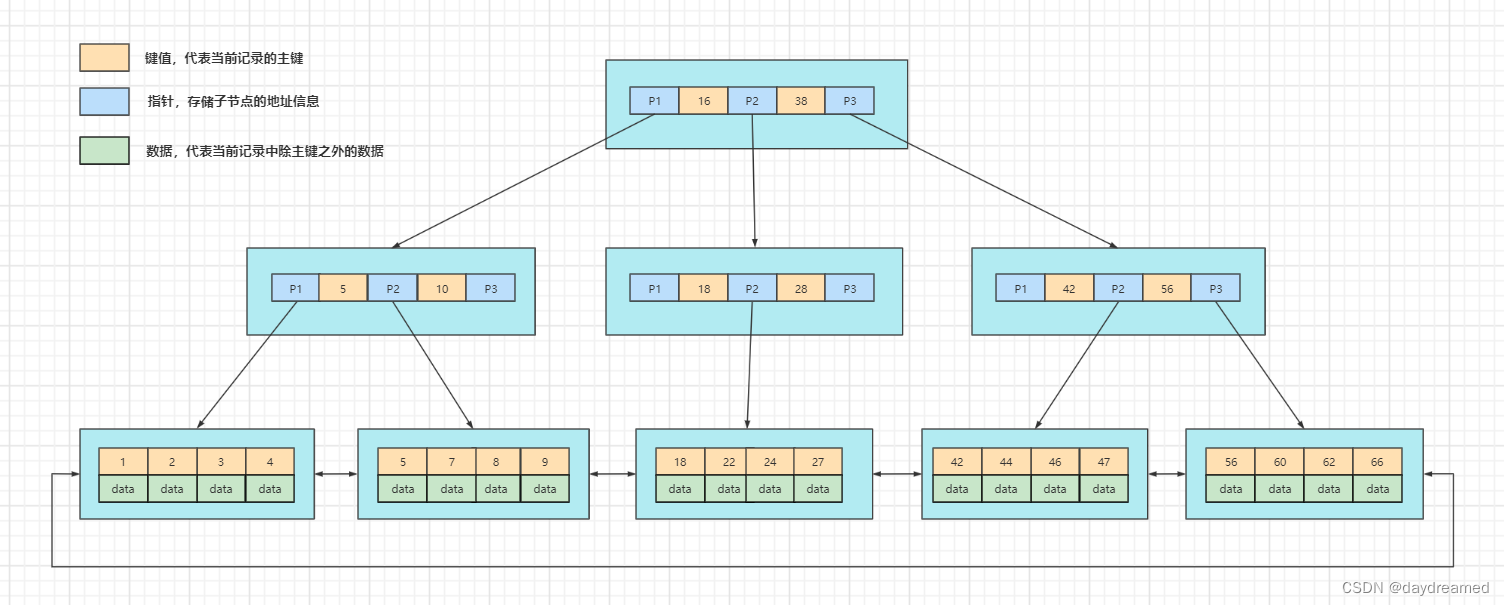
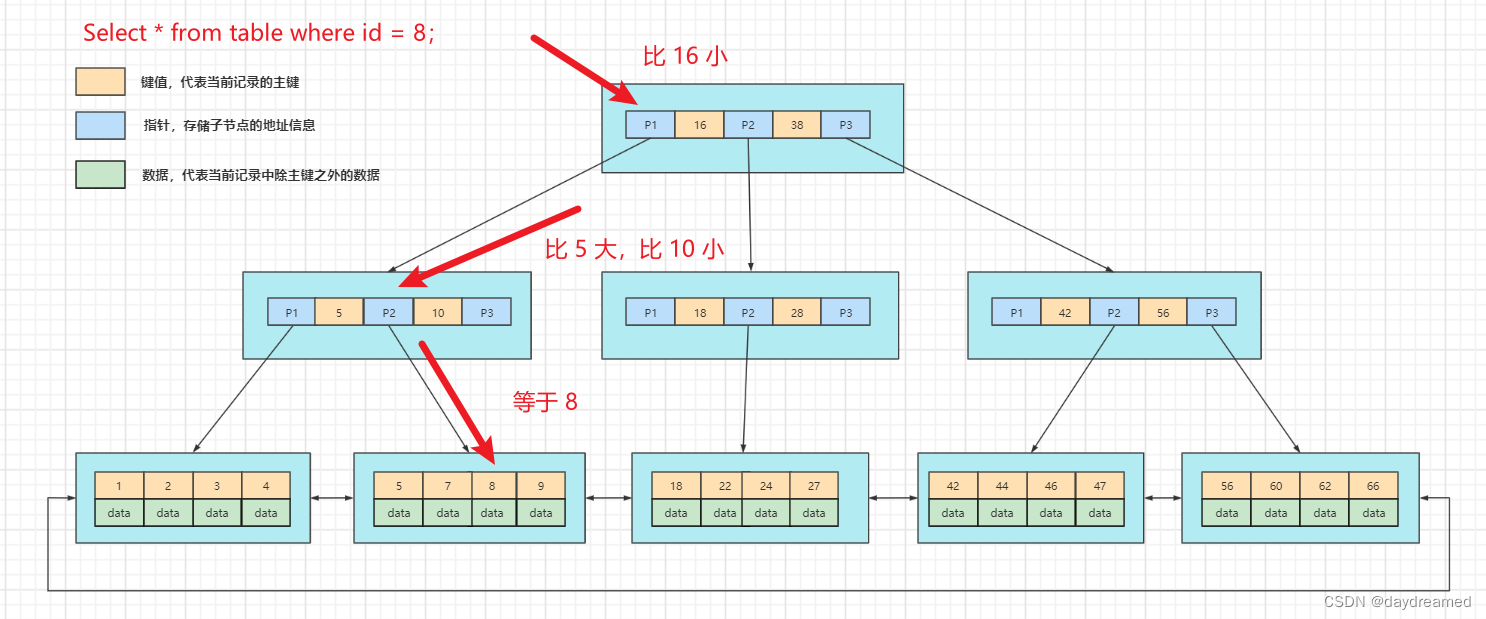
等值查询,例如:Select * from table where id = 8;
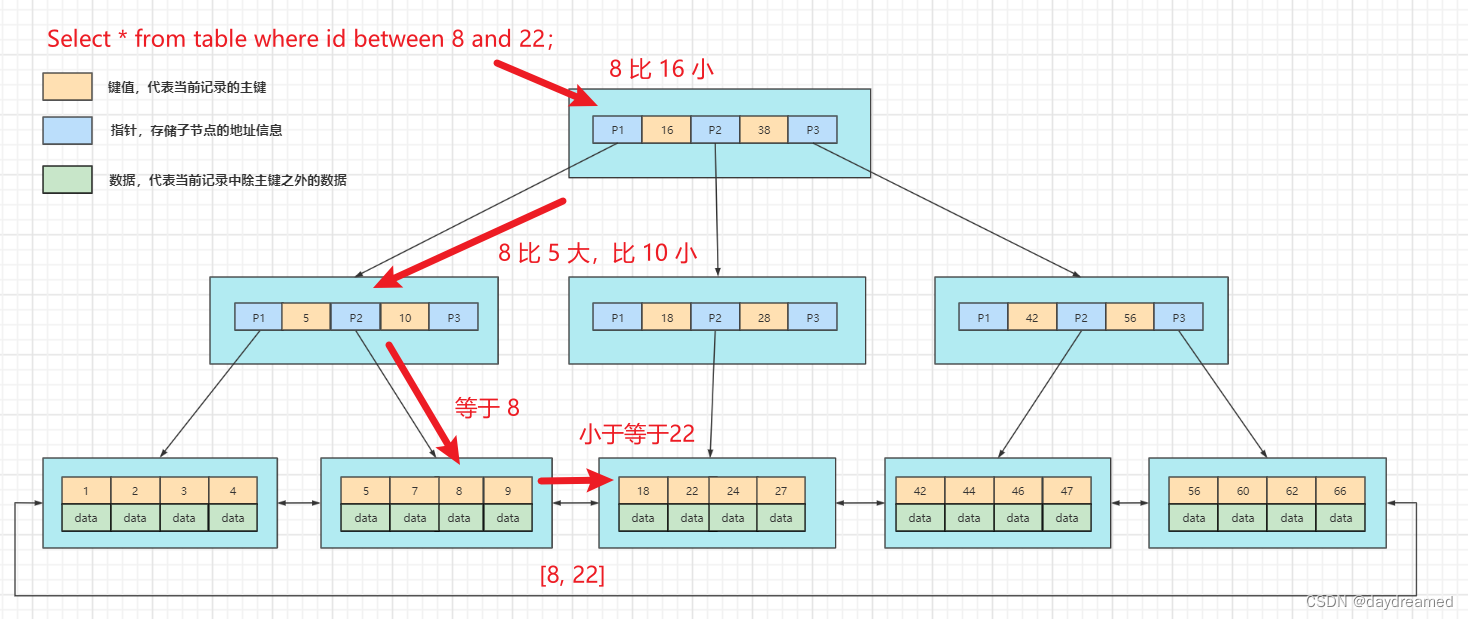
范围查询,例如:Select * from table where id between 8 and 22;
B+Tree 的优点:
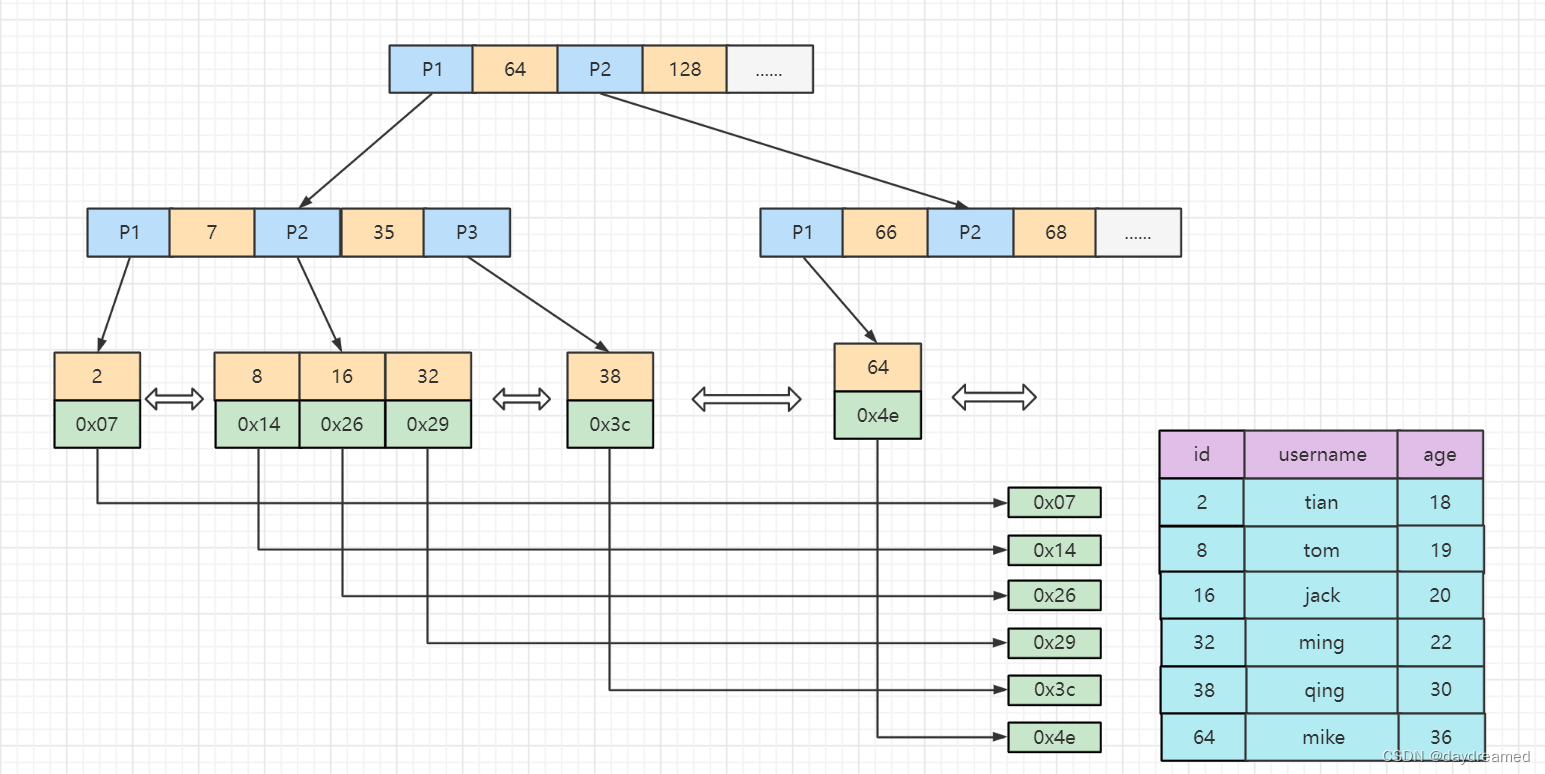
数据和索引都存储在一个文件中(.ibd)
一般情况下,聚簇索引等同于主键索引;除 聚簇索引 外的所有索引 均称为 辅助索引
InnoDB(B+Tree)叶子节点中存储的键值为索引列的值
每一张表都有一个聚簇索引
根据在 辅助索引树 中获取的 主键id,再到 主键索引树 查询数据的过程 称为 回表 查询
组合索引
主键索引(聚簇索引):
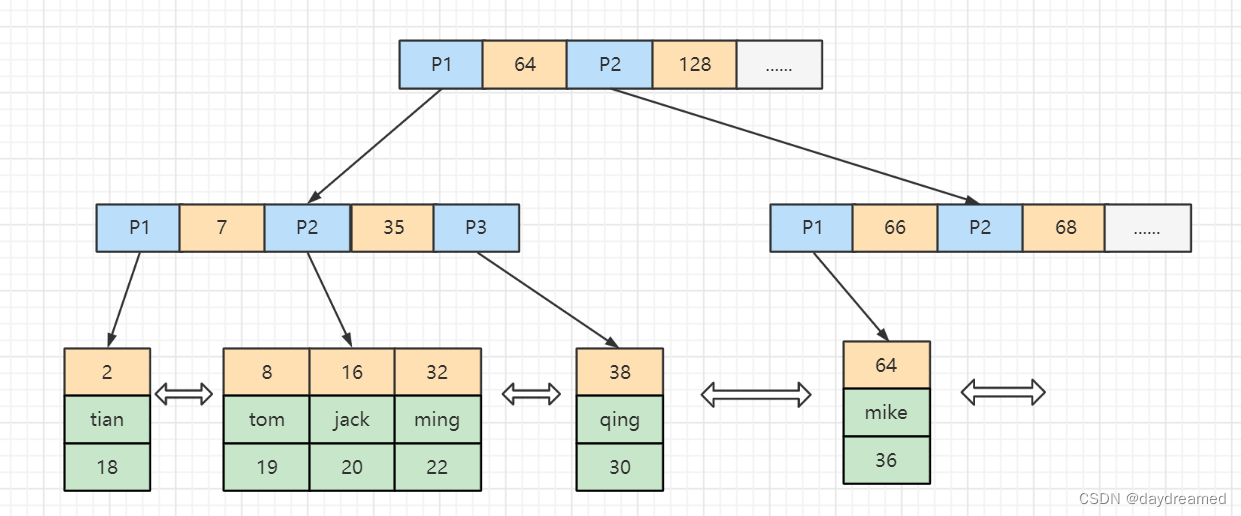
辅助索引:
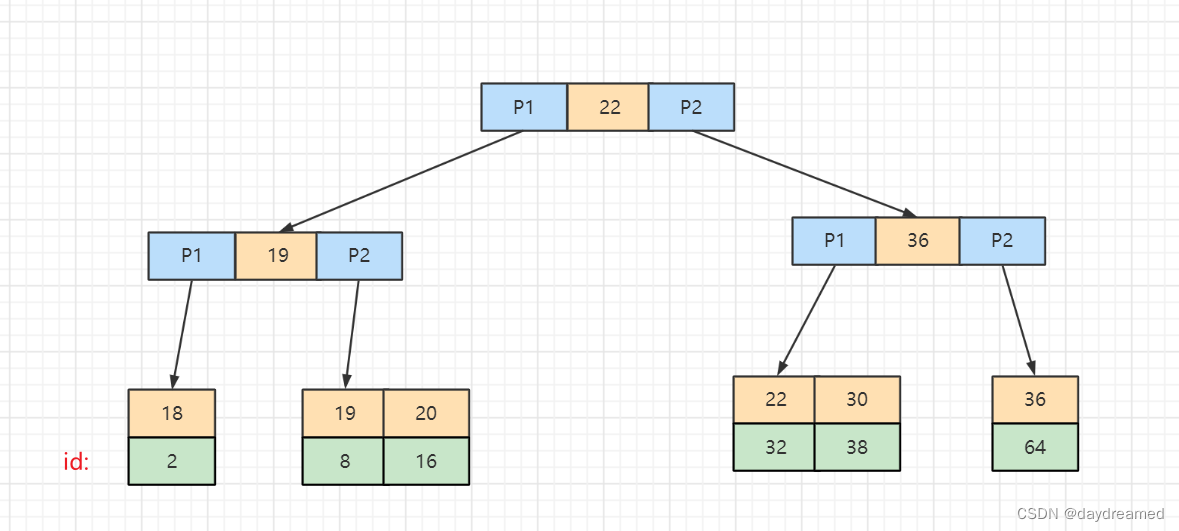
组合索引:
覆盖索引:
create index idx on user(name, age, gender);
-- 使用覆盖索引
explain select name, age, gender from user where name ='万叶' and age = 18 and gender = '0';

-- 未使用覆盖索引
explain select * from user where name ='万叶' and age = 18 and gender = '0';

5.1、MySQL 索引 的基本语法
创建表时:
create table table_name(
[col_name data_type] [unique | fulltext | spatial...],
[unique...] [index | key] [index_name] (col_name [length], ...)
);
create table user (
id INT NOT NULL,
name CHAR(30) NOT NULL,
unique index uniqueIdx(id)
);
表已存在时:
-- 第一种
alter table table_name
add [unique...] [index | key] [index_name] (col_name [length], ...);
alter table user add unique index uniqueIdx(id);
-- 第二种
create [unique...] index index_name
on table_name (col_name [length], ...);
create unique index uniqueIdx on user(id);
-- 删除索引
drop index index_name on table_name;
5.2、怎么判断要不要加索引?
加索引:
不加索引:
5.3、只要创建了索引,就一定会生效吗?
不一定。当使用 组合索引 时,如果没有遵循 最左匹配 原则,索引不生效。
例如,创建 id、name、age 组合索引
5.4、怎样判断索引是否生效?
使用 explain 关键字。
例如:
explain select * from user where id = 1;

5.5、怎么避免索引失效?
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我一直在努力学习如何处理由数组组成的数组。假设我有这个数组:my_array=[['ORANGE',1],['APPLE',2],['PEACH',3]我将如何找到包含'apple'的my_array索引并删除该索引(删除子数组['APPLE',2]因为'apple'包含在该索引的数组中)?谢谢-我非常感谢这里的帮助。 最佳答案 您可以使用Array.select过滤掉项目:>>a=[['ORANGE',1],['APPLE',2],['PEACH',3]]=>[["ORANGE",1],["APPLE",2],["PEACH",3
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果