个人简介
👀个人主页: 前端杂货铺
🙋♂️学习方向: 主攻前端方向,也会涉及到服务端
📃个人状态: 在校大学生一枚,已拿多个前端 offer(秋招)
🚀未来打算: 为中国的工业软件事业效力n年
🥇推荐学习:🍍前端面试宝典 🍉Vue2 🍋Vue3 🍓Vue2&Vue3项目实战 🥝Node.js🍒Three.js
🌕个人推广:每篇文章最下方都有加入方式,旨在交流学习&资源分享,快加入进来吧
| 内容 | 参考链接 |
|---|---|
| Node.js(一) | 初识 Node.js |
| Node.js(二) | Node.js——开发博客项目之接口 |
| Node.js(三) | Node.js——一文带你开发博客项目(使用假数据处理) |
| Node.js(四) | Node.js——开发博客项目之MySQL基础 |
| Node.js(五) | Node.js——开发博客项目之API对接MySQL |
| Node.js(六) | Node.js——开发博客项目之登录(前置知识) |
| Node.js(七) | Node.js——开发博客项目之登录(对接完毕) |
文章目录
这是一个前后端分离的 myblog 博客项目,具体内容请观看如下视频~~
博客项目
前面我们基本实现了登录的功能,并且各个接口也已基本配置完毕。
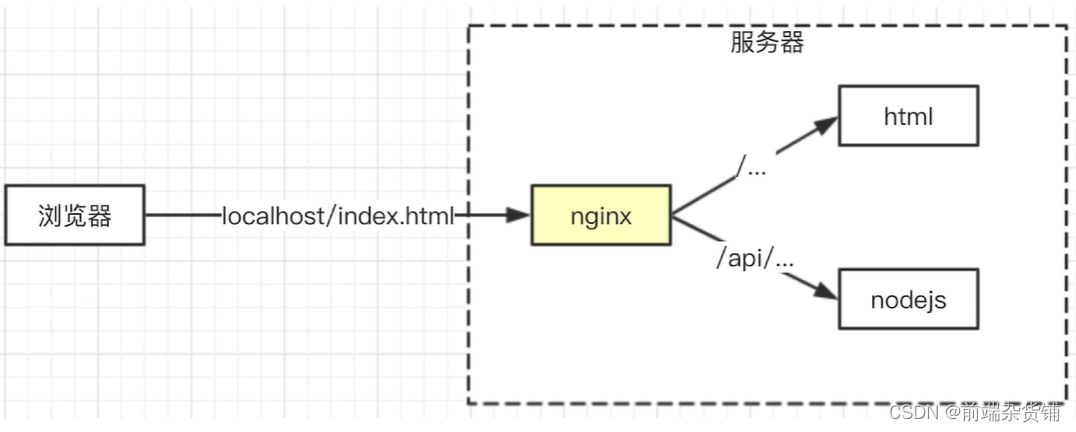
下面我们来进行对博客项目的联调工作,导入相应的 HTML,进行 Nginx 配置解决跨域 以及使用 CORS 解决跨域等操作。
对于页面有需求的可以通过文章最下面的方式自行获取~~
首先我们新建一个文件夹(名为 html-test),里面存放我们的页面(.html 文件),文件内容如下:
页面呈现内容对应如下:
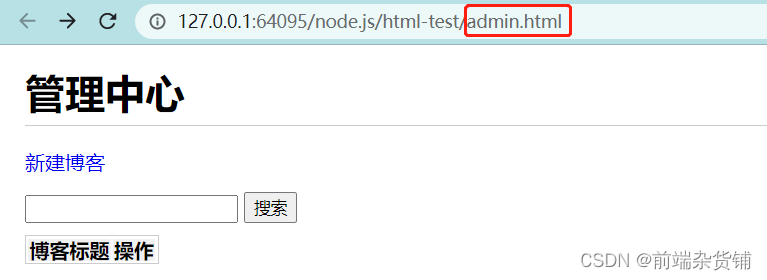


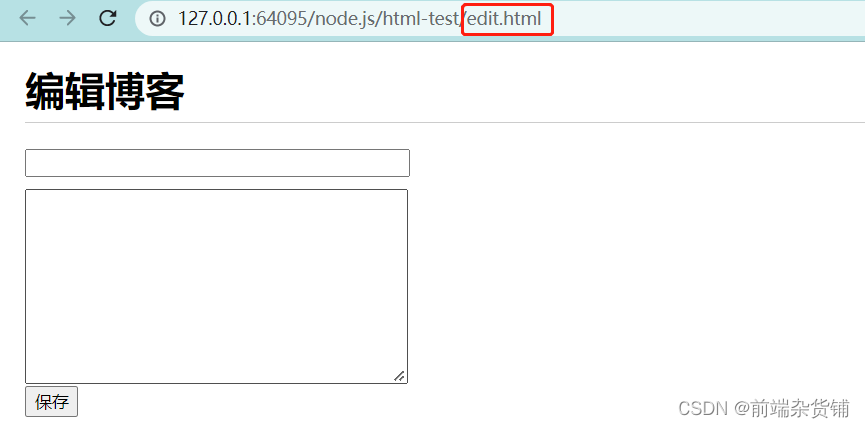


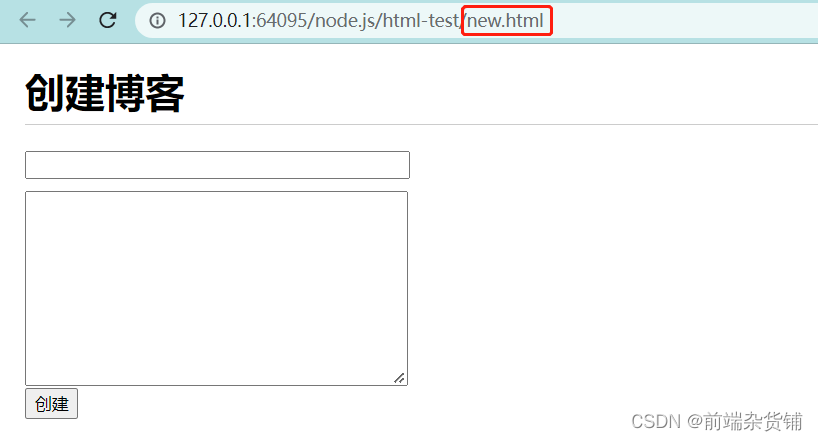
接下来,我们来开启一个新端口(前端端口)
首先在 html-test 文件目录下安装 http-server:
npm install http-server
安装成功之后,创建我们的新端口为 8001(注:8000 为后端端口,8001 为前端端口)
http-server -p 8001
但此时,前后端并不能互通,因为 8000 端口 和 8001 端口是有跨域的(8001 端口无法访问 8000 端口的 list 内容)…
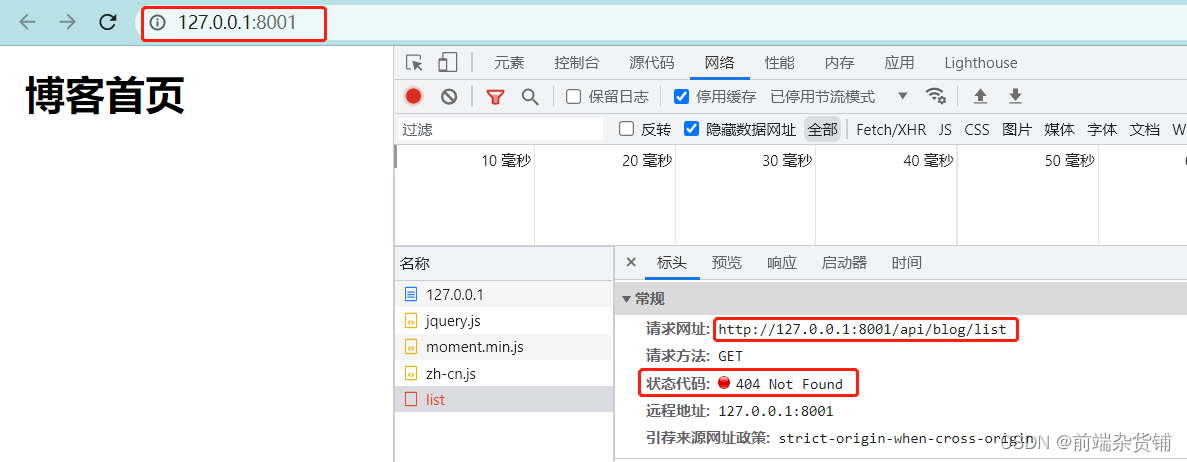
nginx 简介:
大家可以下载这个比较稳定的版本
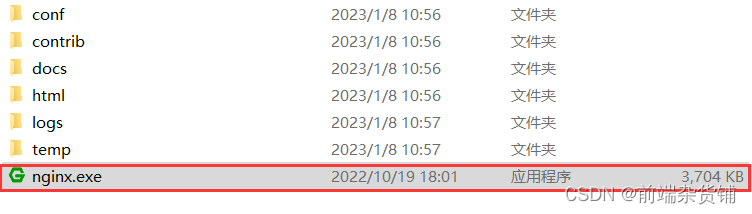
下载完成之后,我们打开这个 nginx.exe 文件(注意:会闪一下命令框,之后就消失了,但进程中已经开启了)
简单介绍一下 nginx 的几个常用命令
我们打开命令行(win+r,之后cmd回车),输入 nginx -t 测试配置文件格式(successful => 很顺利~)

我们使用编译器打开 conf 文件夹下的 nginx.conf
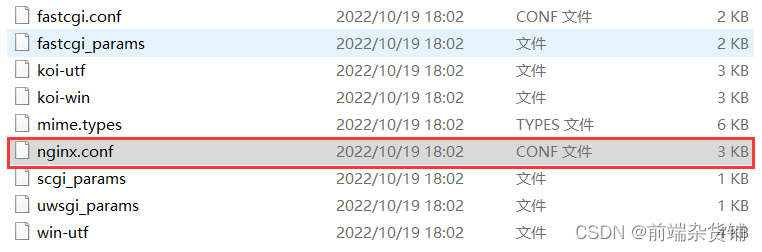
修改如下配置:
# server 的 listen 改为 8080
server {
listen 8080;
server_name localhost;
# 注释掉这几行内容
# location / {
# root html;
# index index.html index.htm;
# }
# 新增的内容(proxy_pass:代理,proxy_set_header Host $host; 配置负载均衡)
location / {
proxy_pass http://localhost:8001;
}
location /api/ {
proxy_pass http://localhost:8000;
proxy_set_header Host $host;
}
之后我们保存,并在命令行输入 nginx -t 查看是否成功(successful => 很顺利~)
nginx -t

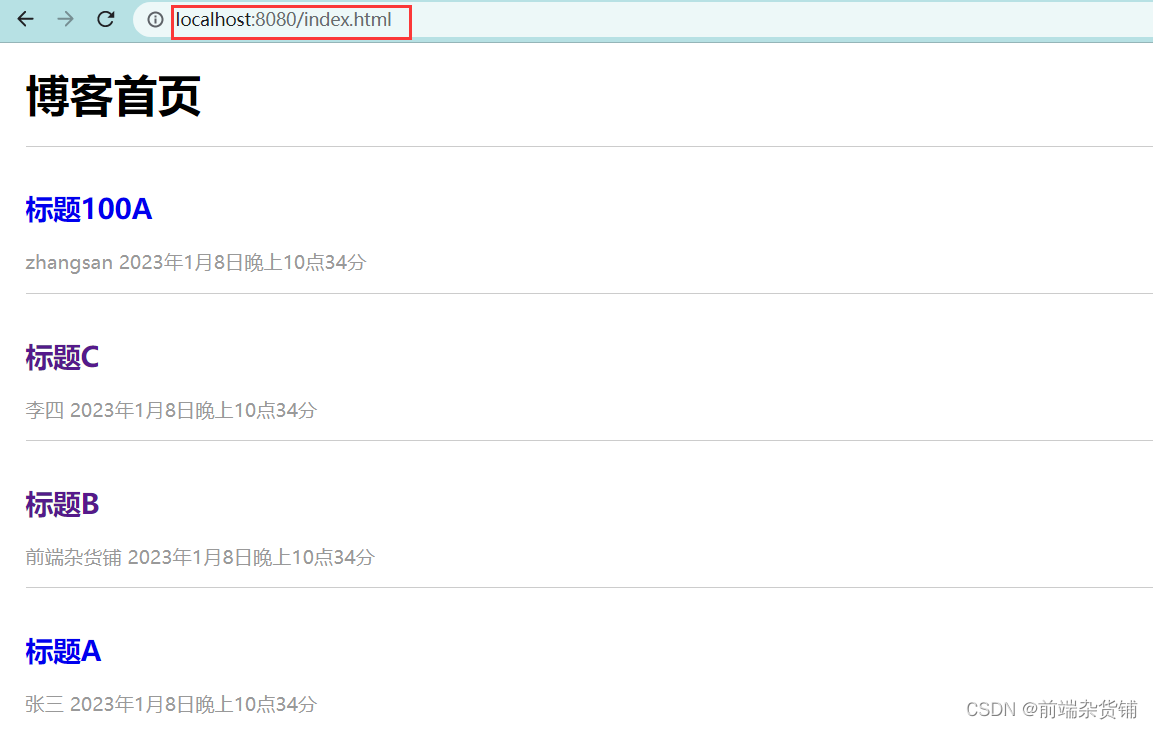
此时,我们打开 8080 端口网页
首页
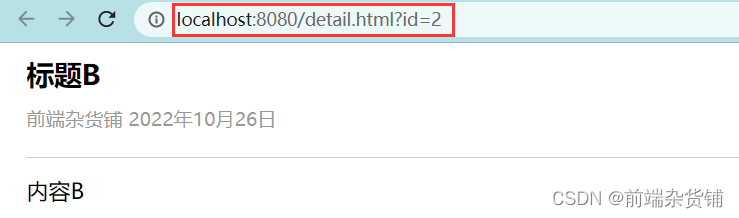
详情页
作者页
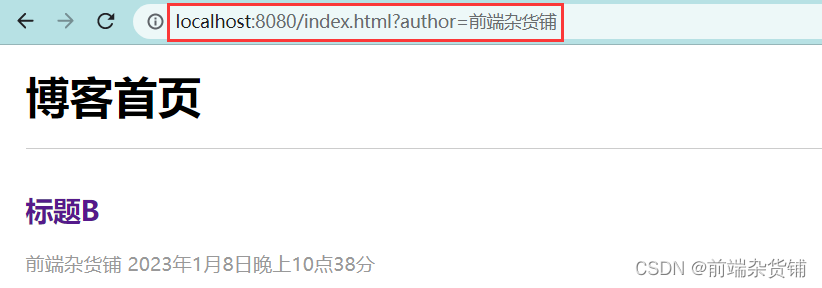
为什么要进行联调?
接下来,修改一下 .router/blog.js 文件的内容
blog.js
我们设置一下管理员的判断,进行强制查询。之后把获取博客、新建博客、更新博客的返回值修改一下
// 获取博客列表 GET 请求
if (method === 'GET' && req.path === '/api/blog/list') {
// 博客的作者,req.query 用在 GET 请求中
let author = req.query.author || ''
// 博客的关键字
const keyword = req.query.keyword || ''
if (req.query.isadmin) {
// 管理员界面
const loginCheckResult = loginCheck(req)
if (loginCheckResult) {
// 未登录
return loginCheckResult
}
// 强制查询自己的博客
author = req.session.username
}
// 查询的结果
const result = getList(author, keyword)
return result.then(listData => {
return new SuccessModel(listData)
})
}
......
// 修改获取博客详情、新建博客、更新博客里面的内容如下
if (loginCheckResult) {
return loginCheckResult
}
联调结果如下:
myblog
除了使用 nginx 反向代理解决跨域,其实我们还可以使用 CORS 来解决跨越的问题
CORS 解决跨域简介
设置响应头(允许传入 cookie、允许网页来源、允许的请求类型)
创建 cros-http-test 文件夹,终端键入 npm init,初始化文件
npm init
具体文件目录如下:
app.js
在这里我们设置对应响应头,用来解决跨域
const http = require('http')
const server = http.createServer((req, res) => {
console.log('req url method: ', req.url, req.method)
// 允许跨域传递参数
res.setHeader('Access-Control-Allow-Credentials', true)
// 允许跨域的 origin,* 代表所有的(需谨慎使用)
res.setHeader('Access-Control-Allow-Origin', '*')
// 允许的 method (请求类型)
res.setHeader('Access-Control-Allow-Methods', 'GET, POST, OPTIONS, PUT, PATCH, DELETE')
res.writeHead(200, {'Content-Type': 'application/json'})
res.end(
JSON.stringify({ errno: 0, msg: 'CORS nodejs' })
)
})
server.listen(8000)
console.log('OK')
在终端运行 app.js


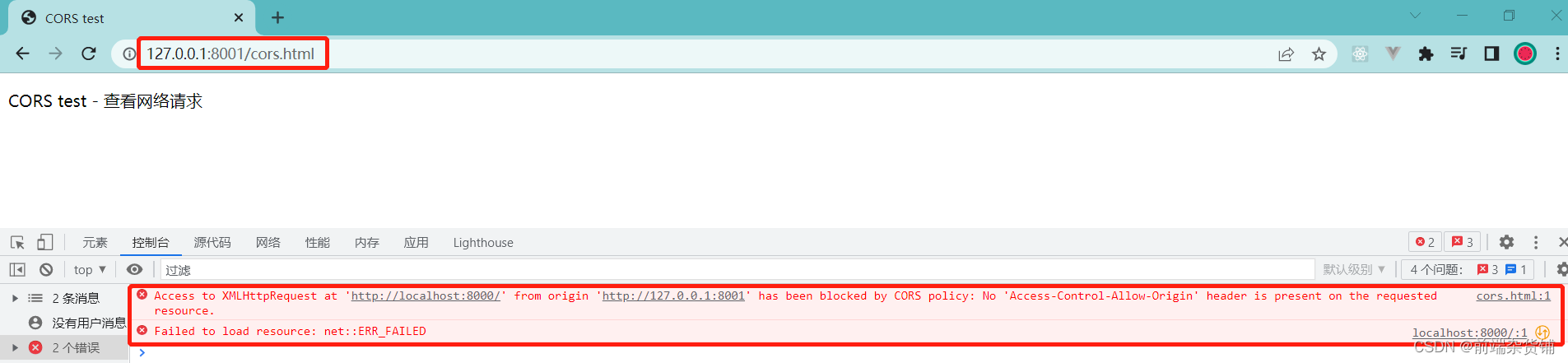
若不设置这三个响应头,则会出现跨域的报错(如果看到类似如下错误,则表示出现跨域辽…)
至此,我们完成了HTML页面的导入,使用 nginx 解决了跨域的问题,并成功完成了与前端联调的工作。继续跟进学习吧!
后续会对该项目进行多次重构【多种框架(express,koa)和数据库(mysql,sequelize,mongodb)】
如果你需要该项目的 源码,请通过本篇文章最下面的方式 加入 进来~~

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我正在学习http://ruby.railstutorial.org/chapters/static-pages上的RubyonRails教程并遇到以下错误StaticPagesHomepageshouldhavethecontent'SampleApp'Failure/Error:page.shouldhave_content('SampleApp')Capybara::ElementNotFound:Unabletofindxpath"/html"#(eval):2:in`text'#./spec/requests/static_pages_spec.rb:7:in`(root)'