摘要:SQL语句解析完成后被解析成Query结构,在进行优化时是以Query为单位进行的,Query的优化分为基于规则的逻辑优化(查询重写)和基于代价的物理优化(计划生成),主入口函数为subquery_planner。subquery_planner函数接收Query(查询树),返回一个Plan(计划树)。
本文分享自华为云社区《openGauss内核分析(六) 执行计划生成》,作者:Gauss松鼠会。
SQL语句解析完成后被解析成Query结构,在进行优化时是以Query为单位进行的,Query的优化分为基于规则的逻辑优化(查询重写)和基于代价的物理优化(计划生成),主入口函数为subquery_planner。subquery_planner函数接收Query(查询树),返回一个Plan(计划树)。
Plan* subquery_planner(PlannerGlobal* glob, Query* parse, PlannerInfo* parent_root, bool hasRecursion,
double tuple_fraction, PlannerInfo** subroot, int options, ItstDisKey* diskeys, List* subqueryRestrictInfo)
{
PlannerInfo* root = NULL;
Plan* plan = NULL; //返回结果
…
preprocess_const_params(root, (Node*)parse->jointree); // 常数替换等式
…
if (parse->hasSubLinks) {
pull_up_sublinks(root); //提升子链接
DEBUG_QRW("After sublink pullup");
}
/* Reduce orderby clause in subquery for join */
reduce_orderby(parse, false); //减少orderby
DEBUG_QRW("After order by reduce");
if (u_sess->attr.attr_sql.enable_constraint_optimization) {
removeNotNullTest(root); //删除NotNullTest
DEBUG_QRW("After soft constraint removal");
}
…
if ((LAZY_AGG & u_sess->attr.attr_sql.rewrite_rule) && permit_from_rewrite_hint(root, LAZY_AGG)) {
lazyagg_main(parse); // lazyagg重写
DEBUG_QRW("After lazyagg");
}
…
parse->jointree = (FromExpr*)pull_up_subqueries(root, (Node*)parse->jointree); //提升子查询
…
if (parse->setOperations) {
flatten_simple_union_all(root); //UNIONALL优化
DEBUG_QRW("After simple union all flatten");
}
…
expand_inherited_tables(root); //展开继承表
…
parse->targetList = (List*)preprocess_expression(root, (Node*)parse->targetList, EXPRKIND_TARGET); //预处理表达式
…
parse->havingQual = (Node *) newHaving; //处理HAVING子句
…
reduce_outer_joins(root); //外连接消除
…
reduce_inequality_fulljoins(root); //全连接重写
…
plan = grouping_planner(root, tuple_fraction); //主要的计划过程
…
return plan;
}subquery_planner函数由函数standard_planner调用,standard_planner函数由exec_simple_query->pg_plan_queries->pg_plan_query->planner函数调用。standard_planner将Query(查询树)生成规划好的语句,可用于执行器实际执行。
PlannedStmt* standard_planner(Query* parse, int cursorOptions, ParamListInfo boundParams)
{
PlannedStmt* result = NULL; //返回结果
PlannerGlobal* glob = NULL;
double tuple_fraction;
PlannerInfo* root = NULL;
Plan* top_plan = NULL;
…
glob = makeNode(PlannerGlobal);
/* primary planning entry point (may recurse for subqueries) */
top_plan = subquery_planner(glob, parse, NULL, false, tuple_fraction, &root); //主规划过程入口
…
/* build the PlannedStmt result */
result = makeNode(PlannedStmt); //构造PlannedStmt
result->commandType = parse->commandType;
result->queryId = parse->queryId;
result->uniqueSQLId = parse->uniqueSQLId;
result->hasReturning = (parse->returningList != NIL);
result->hasModifyingCTE = parse->hasModifyingCTE;
result->canSetTag = parse->canSetTag;
result->transientPlan = glob->transientPlan;
result->dependsOnRole = glob->dependsOnRole;
result->planTree = top_plan; //执行计划
result->rtable = glob->finalrtable;
result->resultRelations = glob->resultRelations;
…
return result;
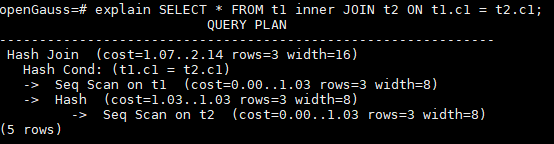
}仍然以前文的join列子来说明
SELECT * FROM t1 inner JOIN t2 ON t1.c1 = t2.c1;复制在planner函数打断点,用gdb查看standard_planner返回的PlannedStmt
(gdb) bt
#0 planner (parse=0x7fd93a410288, cursorOptions=0, boundParams=0x0) at planner.cpp:389
#1 0x0000000001936fbd in pg_plan_query (querytree=0x7fd93a410288, cursorOptions=0, boundParams=0x0, underExplain=false) at postgres.cpp:1197
#2 0x0000000001937381 in pg_plan_queries (querytrees=0x7fd939b81090, cursorOptions=0, boundParams=0x0) at postgres.cpp:1315
#3 0x000000000193a6b8 in exec_simple_query (query_string=0x7fd966ad2060 "SELECT * FROM t1 inner JOIN t2 ON t1.c1 = t2.c1;", messageType=QUERY_MESSAGE, msg=0x7fd931056210)
at postgres.cpp:2560
#4 0x0000000001947104 in PostgresMain (argc=1, argv=0x7fd93a2cf1c0, dbname=0x7fd93a2ce1f8 "postgres", username=0x7fd93a2ce1b0 "test") at postgres.cpp:8403
#5 0x0000000001890740 in BackendRun (port=0x7fd931056720) at postmaster.cpp:8053
#6 0x00000000018a00b1 in GaussDbThreadMain<(knl_thread_role)1> (arg=0x7fd97c55c5f0) at postmaster.cpp:12181
#7 0x000000000189c0de in InternalThreadFunc (args=0x7fd97c55c5f0) at postmaster.cpp:12755
#8 0x00000000024bf7d8 in ThreadStarterFunc (arg=0x7fd97c55c5e0) at gs_thread.cpp:382
#9 0x00007fd9a60cfdd5 in start_thread () from /lib64/libpthread.so.0
#10 0x00007fd9a5df8ead in clone () from /lib64/libc.so.6
(gdb) p *result
$14 = {type = T_PlannedStmt, commandType = CMD_SELECT, queryId = 0, hasReturning = false, hasModifyingCTE = false, canSetTag = true, transientPlan = false, dependsOnRole = false,
planTree = 0x7fd93a409d58, rtable = 0x7fd939b81660, …}
(gdb) p *result->planTree->lefttree
$46 = {type = T_SeqScan, plan_node_id = 2, parent_node_id = 1, exec_type = EXEC_ON_DATANODES, startup_cost = 0, total_cost = 1.03, plan_rows = 3, multiple = 1, plan_width = 8,…}将Query规划后得到PlannedStmt
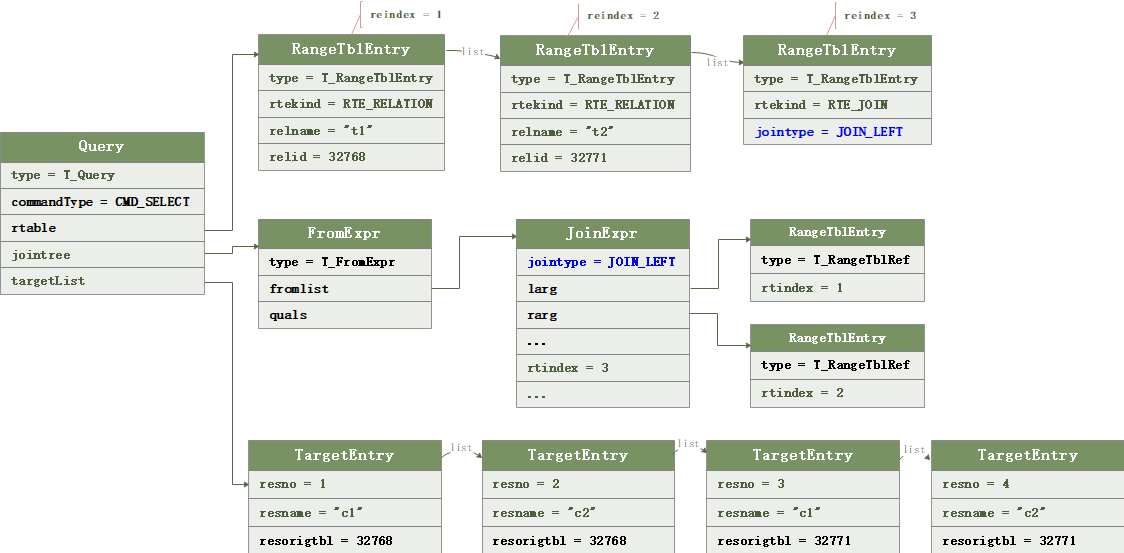
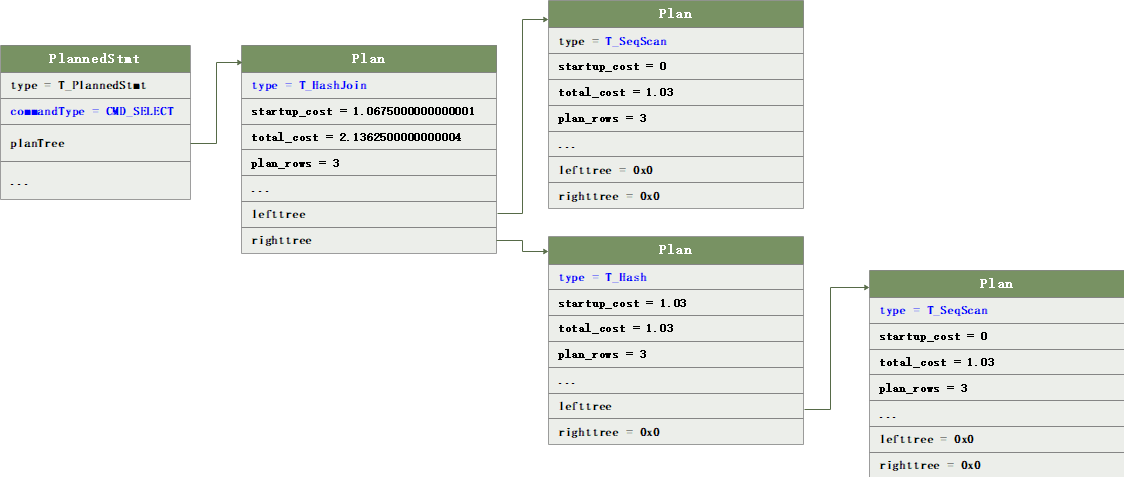
可以看到,Plannedstmt 与explain执行计划是一致的
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否