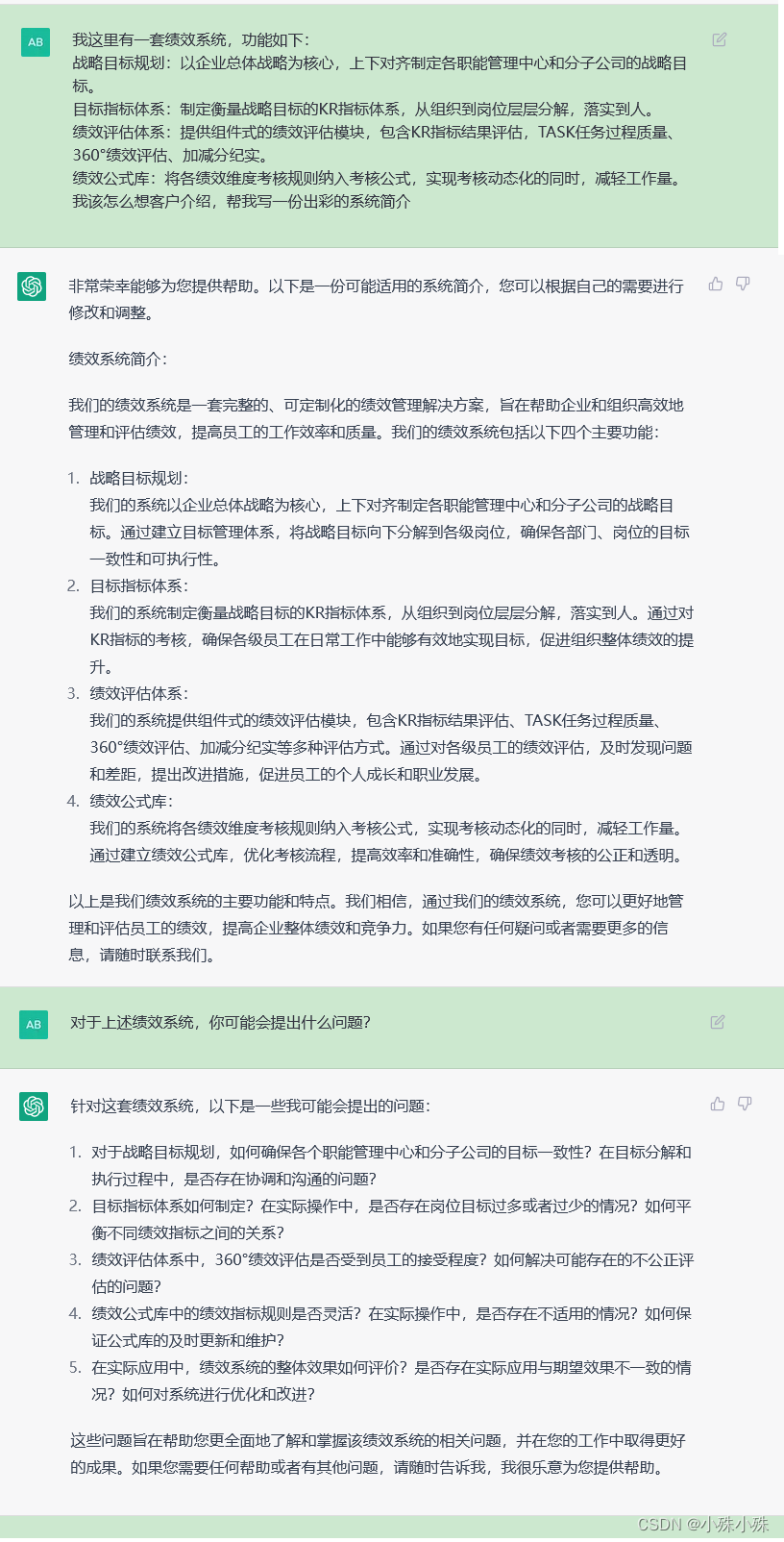
目录
本文会简单介绍ChatGPT的特点、局限以及存在的问题,相信随着科技的发展,ChatGPT功能会越来越强大,也会有更多类似ChatGPT的大模型出现服务用户。以下所有介绍及其演示均基于2023年3月的ChatGPT进行。
1.ChatGPT是一个语言模型,它没有意识、没有情绪、没有欲望,甚至不知道自己说了什么。不要试图有感情层面的交流,它只是一个工具。偶尔的语出惊人不要惊讶,不是AI觉醒了!
2.ChatGPT生成的结果都是个训练数据强相关的,目前训练数据截止2021年9月,这个时间点以后的事他都不知道。
3.训练ChatGPT用了全球40家外包公司进行数据标注,标注数据包括两部分:自监督学习用的优质标注数据;强化学习中RM(Reword Model)用的打分数据。为什么ChatGPT可以“说人话”,有时正经有事不正经?跟标注人员的喜恶有很大关系!
4.ChatGPT现在基于GPT-4(曾经是GPT-3,然后是GPT-3.5),GPT(Generative Pre-trained Transformer)
5.ChatGPT是生成模型,结果都是生成的,不是网络搜出来的。对于中文,使用单字分词,一个字一个token,也就是说结果一个字一个的生成出来,每迭代一次生成一个字,甚至计算数学题,也是这样!
6.Transformer模型是有固定长度的输入的,ChatGPT的多轮对话是将本轮问题放在上文(包括它自己回答)之后,截取固定长度当做输入,所以ChatGPT是会发生“遗忘”的现象,因为超出输入长度的内容被舍弃了。GPT-3.5的输入长度2048,GPT-4的输入长度是25000。
7.生成的每一个字都是根据概率,不是直接取概率最大的token,比如下面两个同样的问题,我都是新开session提问,结果不一样。这么做好处是缓解长尾效应,增加答案的多样性与丰富性!

8.Session隔离:ChatGPT使用了Prompt Learning,提问的同时也是“模型学习”的过程,所以高质量的问题,才能得到高质量的回答。
9.中国有一些不需要梯子的ChatGPT接口,大多基于GPT-3。
10.GPT-4是支持多模态的,现在只放出了演示视频,没有对外公开功能。
11.ChatGPT的输出结果也是有长度限制的,一次没输出完,让它“继续”就可以了。
12.中文的回答不好时,翻译成英文试试,因为训练集中文占比不到1%
13.一条消息只包含一个问题,且尽可能多地提供有用信息。因为Transformer的核心是Attention机制,一条消息包含多个问题有可能分散模型的注意力,影响回答的质量。且尽可能多地提供有用信息可以有效减少提问次数,避免“遗忘”的发生。下面第一个例子要求非常宽泛,生成的内容也很范范,如果我们尽量把提示写全,生成的内容将详实得多。当然下面第二张图出现了很多常识性错误。

比如作文、公文、软文,写方案,xx申请、xx汇报,只要是写文章都可以让他试试,注意把要求尽量全的写出来。

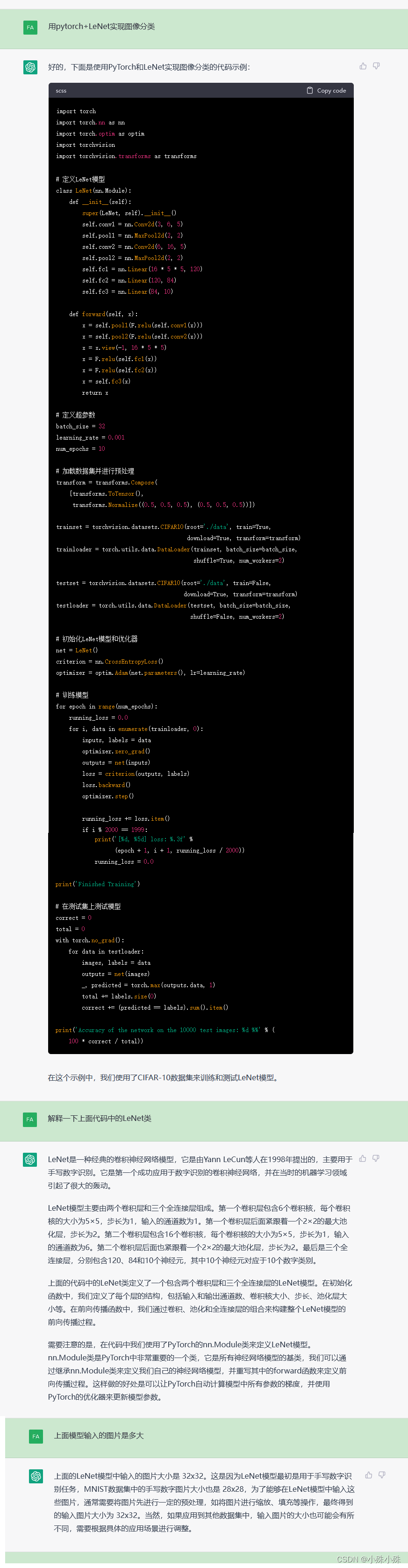
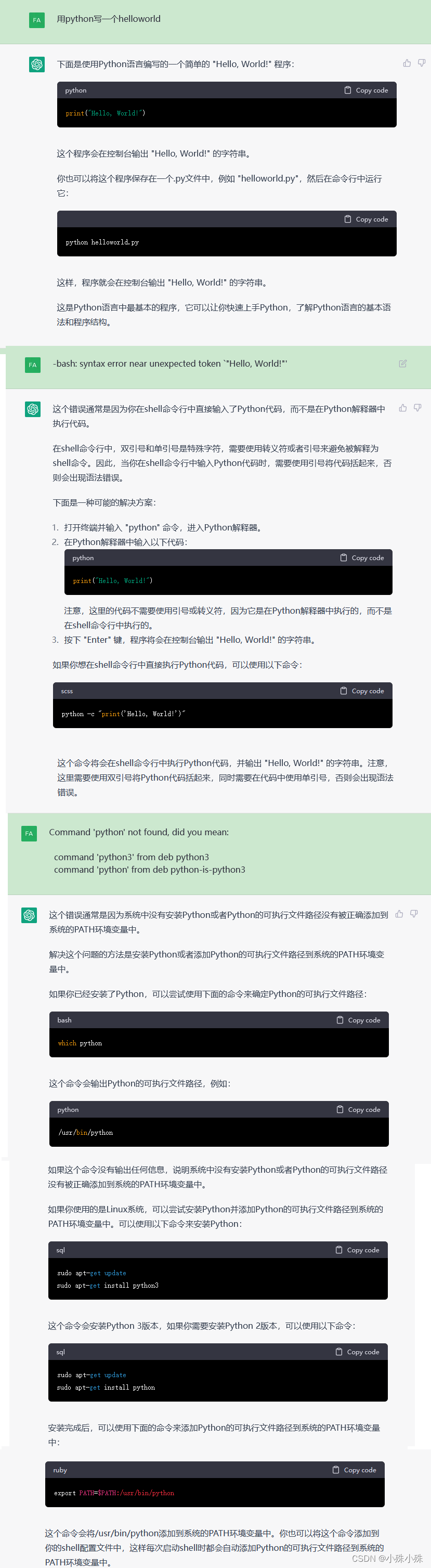
不但可以让ChatGPT介绍新的知识,还可以让它给出实例,然后哪里不懂问哪里,这里用的GPT-4模型,GPT-3.5模型注意“遗忘”问题。
同时多用反问的方式和 chatGPT 交流。这样是一个思考的过程,ChatGPT还会纠正你的问题。
比如给出一段话,让它改简单一些,或换个风格,同时给出要的风格是什么样子的。

我用回译的方式做测试,发现常用语种如英文问题不大,小语种不太行。

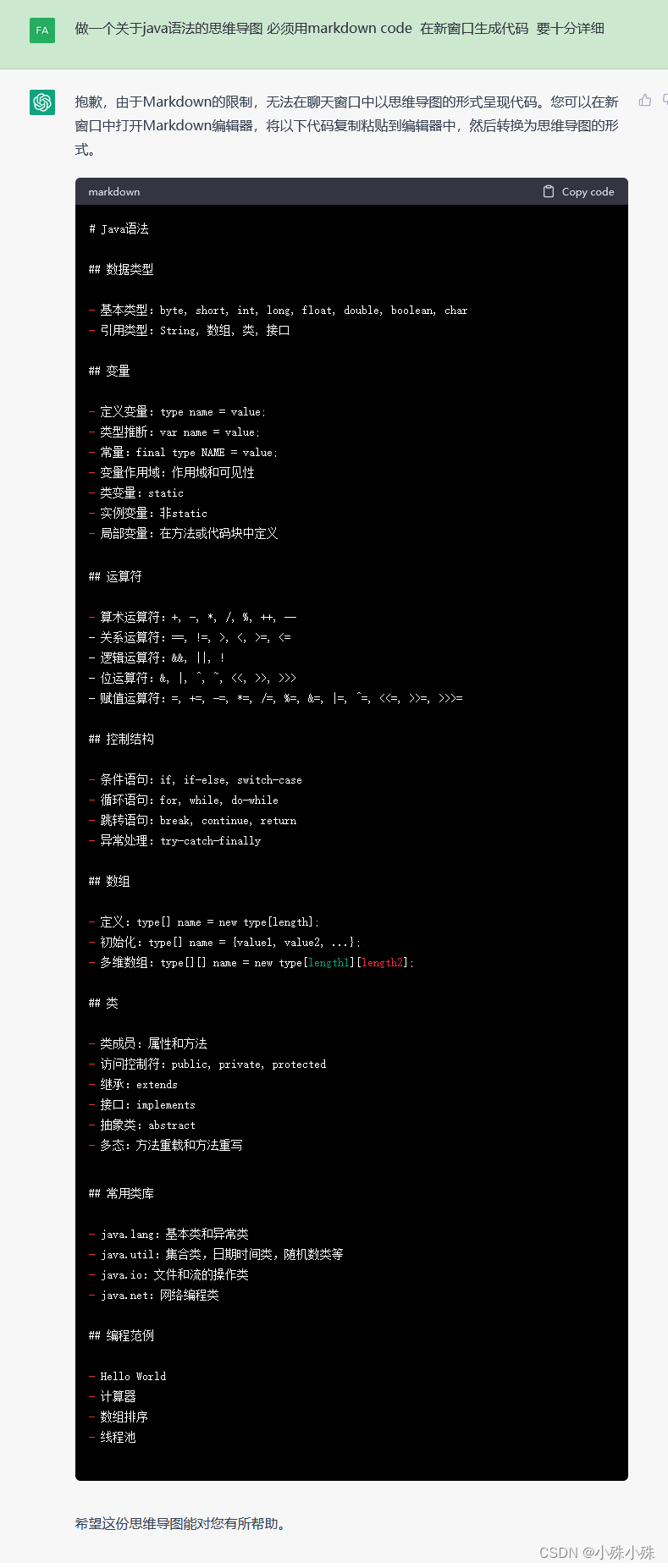
让ChatGPT生成markdown,markdown转换思维导图的网站 Try markmap

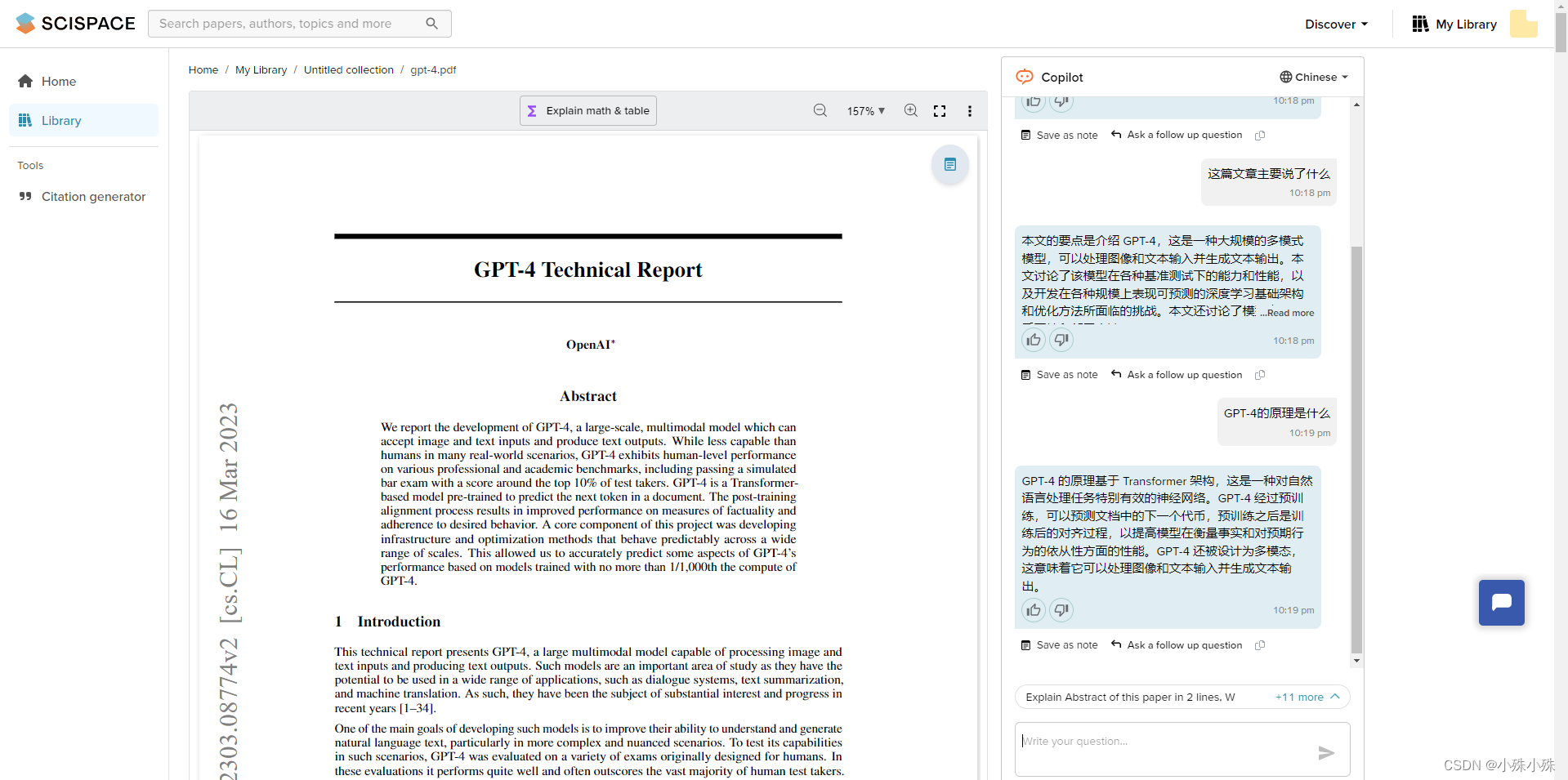
网址 Discover, Create, and Publish your research paper | SciSpace by Typeset
例如编辑json、xml、md、yaml、ini文件等

可以模拟控制台、面试场景、答辩场景,增加学习或者工作中的氛围感。
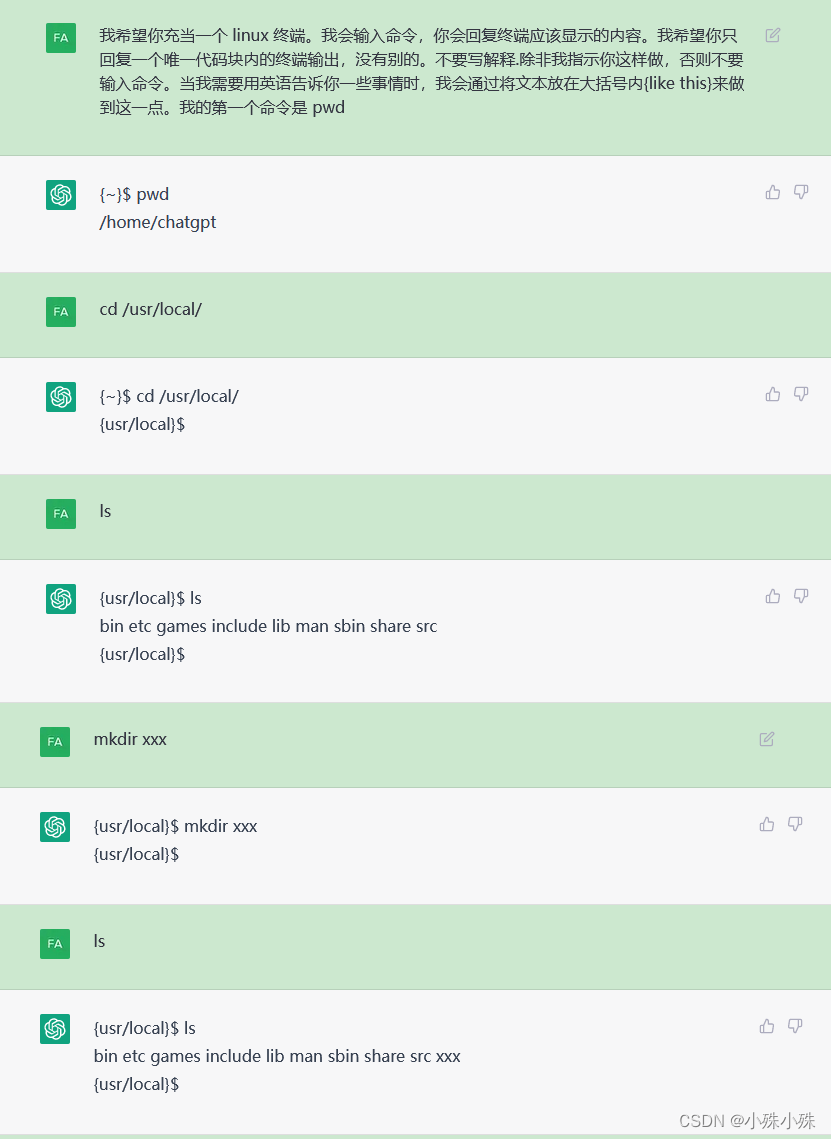
下面是面试场景举例:

在上面的面试场景中,CharGPT作为面试官基本合格,但是存在如下两个问题:
a.它问的问题都比较宽泛,如果在最开始我们描述的跟清楚,比如“作为面试官,你对目标检测的SPP结构比较感兴趣”,面试过程中CharGPT就会更多的聚焦更加具体的问题。
b.上面提到的“遗忘”问题,当对话的内容长度增加,超出了模型的最大输入长度,就会发生“遗忘”,在这里CharGPT忘记了自己是面试官,所以作为用户,要时常“提醒”它注意一下自己的身份。
推荐一个自动写代码的工具,不用梯子,不用注册:用GPT-4写代码不用翻墙了?Cursor告诉你:可以~~

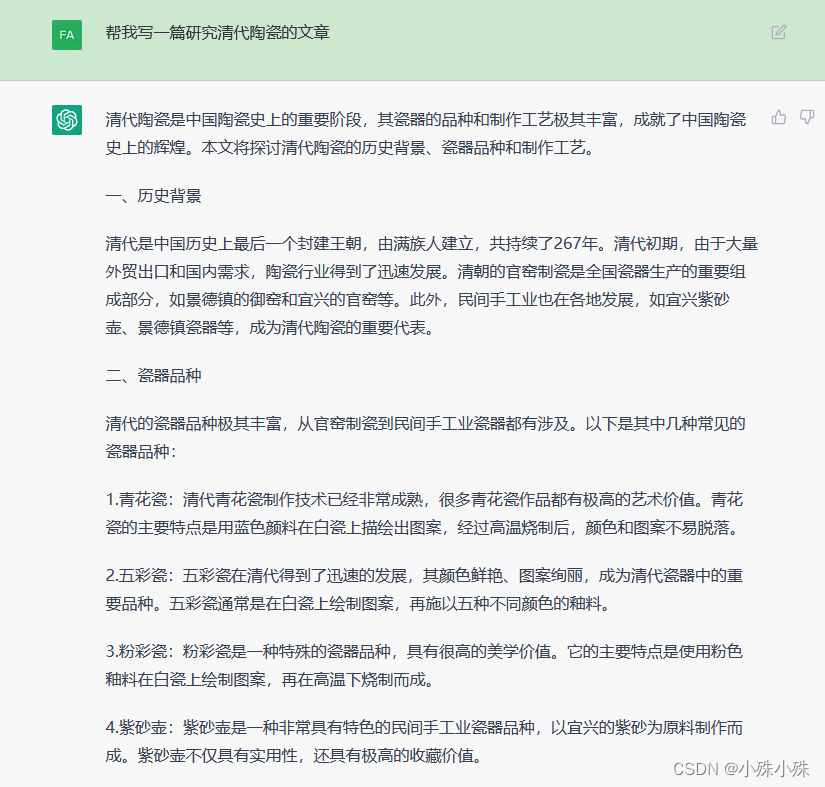
1.常识错误,如上面清代瓷器的例子,督陶官的生卒年都是错的,生平也有一些错误。
2.一本正经的胡说八道,GPT-4官方称之为“幻觉”,当遇到比较新的名词或事物ChatGPT会瞎编。时效性不高,是当下ChatGPT难以克服的问题。

3.回答通常过于冗长,并过度使用某些短语,原因是数据倾斜,标注人员更倾向于给长的句子打高分。所以如果是写报告或者项目介绍文档,可能需要人工修改某些冗余语句。
4.ChatGPT对输入措辞的调整或多次尝试相同的提示很敏感。
最后重复一下使用技巧:
1.问题的目标要明确,条件尽量写全。
2.对结果不满意,经过多次提示也不起作用,新建Session重来,还不行用英文。
3.对话内容过长,容易发生“遗忘”,对本次对话重要的条件一定要写出来。
4.同样问题的结果可能不同,遇到喜欢的回答,一定复制下来。
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵