参考资料:https://zhuanlan.zhihu.com/p/81693661
https://www.zhihu.com/question/506867139
https://blog.csdn.net/weixin_44751294/article/details/123191429
看过上面两个链接,就对docker是什么作用,怎么用有个大概的了解。简单摘要一些对我来说比较重要的点如下:
(1)docker可以让环境配置变得简单,在多人同时使用一台服务器或者时不时换电脑换机器所有的包时都很有用
(2)docker可以看作是在你的宿主上开启一个轻量化的虚拟机
(3) docker 镜像(Image): 类似与操作系统的ISO 镜像文件,docker hub上有很多大家都封装好的镜像,例如可以直接pull 深度学习镜像。
(4)docker 容器(Container)中无法直接使用主机的GPU,因为主机的GPU使用需要专有的NVIDIA驱动,所以容器要使用GPU硬件必须有个能用驱动的桥梁就是docker-nvidia。镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
(5)仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
指路我的另一篇博客:
参考链接:https://blog.csdn.net/m0_46825740/article/details/123527009
https://www.csdn.net/tags/MtTaEg2sNzYzMjIxLWJsb2cO0O0O.html
从链接2了解到有两种方法实现:方法一:直接拉取带cuda环境的pytorch环境(方便);方法二:拉取nvidia/cuda镜像后,手动配置相应环境,这种方法比较灵活。
前边版本查看方法一方法二都是一致的
先查询一下版本,把对应关系找到,之后下载对应匹配的版本,避免后续出现版本不匹配无法兼容的问题。
正常来讲docker内的CUDA版本和宿主机无关,但实际种宿主机(物理机)的 Nvidia GPU 驱动 选择 高版本, 更容易兼容Docker内不同CUDA的驱动要求。
具体可查阅知乎:显卡驱动、docker内CUDA
(1)查看显卡驱动版本
nvidia-smi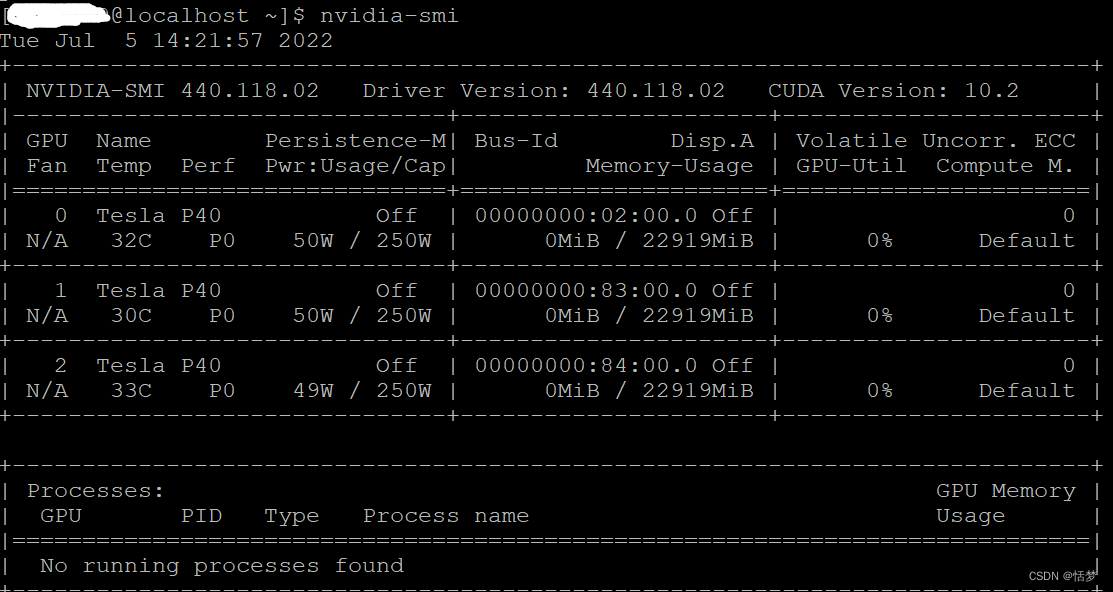
可以看到Driver Version: 440.118.02。上图中的CUDA Version: 10.2 表示驱动的最高版本。下载CUDA的版本应低于10.2。
如果需要查宿主机已经安装的cuda版本,可使用:
nvcc --version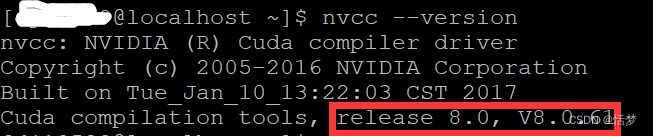
可以看到我的宿主机版本是8.0.61
(2) 查看该驱动版本支持的cuda版本
链接:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html

(3)查看支持该cuda的pytorch版本
链接:https://pytorch.org/get-started/previous-versions/
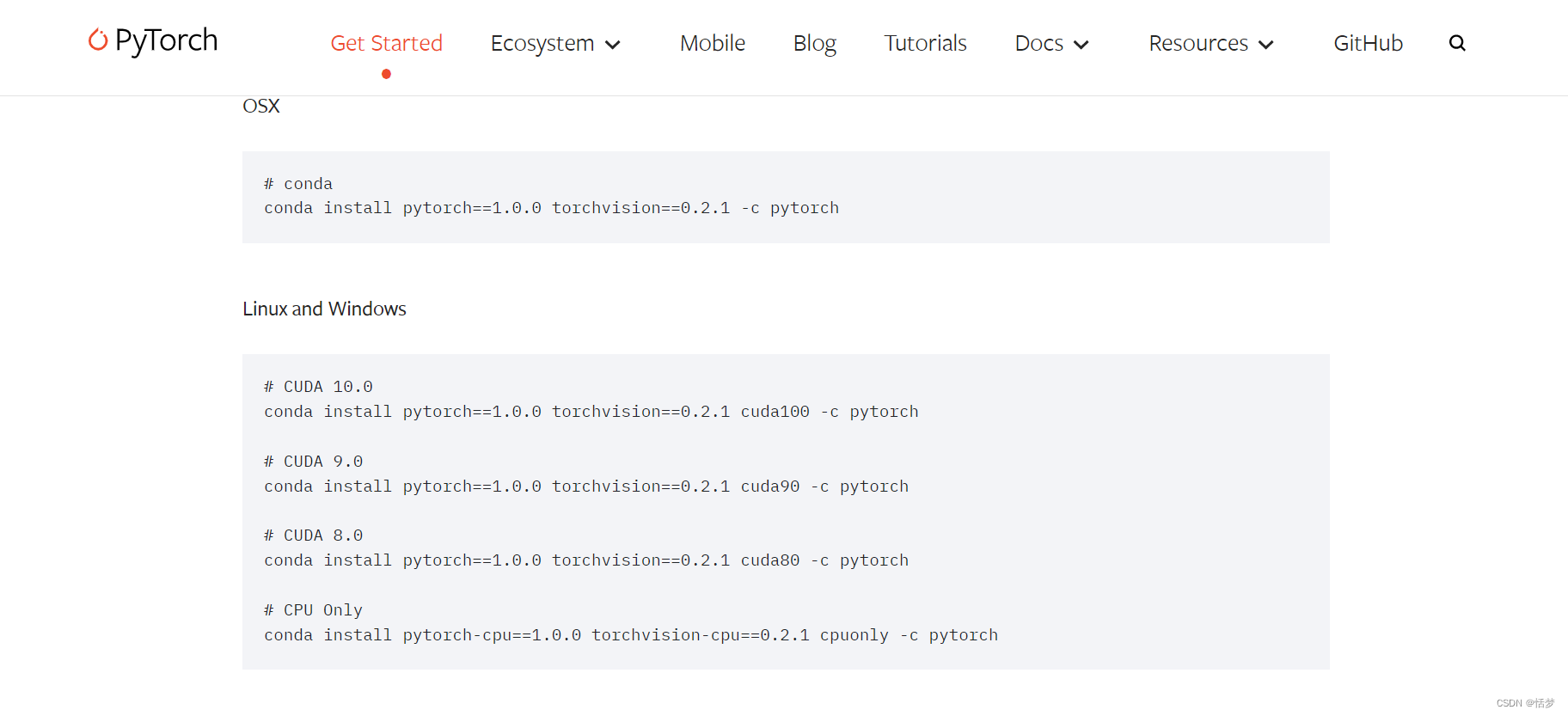
直接在docker.hub中拉取pytorch镜像:
docker pull pytorch/pytorch:1.2-cuda10.0-cudnn7-devel在镜像中建立一个容器:
docker run -it --name torch_gpu --gpus all pytorch/pytorch:1.2-cuda10.0-cudnn7-devel /bin/bash查看容器ID命令:
sudo docker ps -a进入容器命令:
docker exec -it 容器ID /bin/bash拓展:列出所有docker镜像命令:
sudo docker images
从宿主机驱动来看,下载10.2版本以下的cuda都是支持的,我初尝试先使用与宿主机一致的版本cuda版本8的。
https://hub.docker.com/r/nvidia/cuda/tags?page=1&ordering=last_updated&name=8.0-de
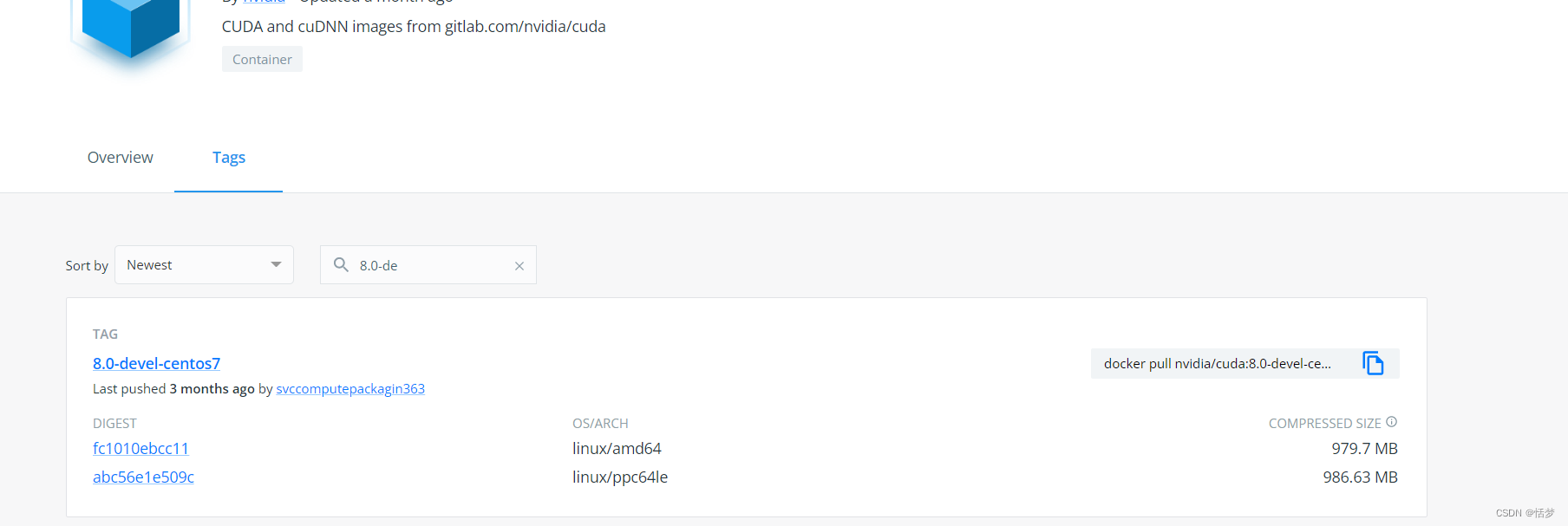
docker pull nvidia/cuda:8.0-devel-centos7我参考链接1配置 不安装nvidia-docker,无法使用镜像创建gpu容器(使用--runtime=nvidia参数出错),参考部署nvidia-docker
设置nvidia-docker的存储库和 GPG 密钥:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
更新包列表后安装包和依赖项:
sudo yum clean expire-cache
安装nvidia-docker:
sudo yum install -y nvidia-docker2
重启docker:
sudo systemctl restart docker
nvidia-docker run -it --runtime=nvidia -v /宿主机绝对路径目录:/容器内目录 --name 容器名 镜像名 /bin/bash
nvidia-docker run -it --runtime=nvidia -v /home/media:/media --name torch_gpuok nvidia/cuda:8.0-devel-centos7 /bin/bash查看容器ID命令:
sudo docker ps -a
进入容器命令:
docker exec -it 容器ID /bin/bash
验证gpu在容器内是否可以正常使用:
nvidia-smi
查看cuda版本:
nvcc -V
cudnn参考链接:https://blog.csdn.net/qq_29183811/article/details/123560206
cudnn的下载需要到官网,而且需要注册英伟达账户,下载地址:cuDNN Archive | NVIDIA Developer
下载下来是:cudnn-8.0-linux-x64-v7.1.tgz
解压:
tar -zxvf cudnn-8.0-linux-x64-v7.1.tgz解压过程中出现了:Cannot create symlink to `xxx': Operation not supported问题,我将该安装包拷贝在当前目录下,解决了该问题。
解压完目录是cuda,里边包含两个文件夹分别为include和lib64

进入解压的目录,然后执行以下命令:
cp ./include/* /usr/local/cuda/include/
cp ./lib/* /usr/local/cuda/lib64/
安装完成后,使用一下命令可以查看`cudnn`版本信息:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
可能由于版本不同头文件名儿不同,可以进文件夹去看,参考链接里的是
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
我是直接安装miniconda安装的python,miniconda下载路径
获取miniconda 安装文件
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py37_4.10.3-Linux-x86_64.sh执行安装:
chmod +x Miniconda3-py37_4.10.3-Linux-x86_64.sh
./Miniconda3-py37_4.10.3-Linux-x86_64.sh中间会出现Miniconda3 will now be installed into this location: (猜想:此处最好要改到docker容器里(没尝试),我没改之后出现一些错误)
验证:
conda -V出错:bash: conda: command not found
之后使用:
export PATH="/root/miniconda3/bin:$GOPATH/bin:$PATH"就可以了。

使用https://pytorch.org/get-started/previous-versions/
查找下载对应版本:
conda install pytorch==1.0.0 torchvision==0.2.1 cuda80 -c pytorch安装成功。
验证出错:

尝试了几种方法都不行。
之后先使用了卸载命令:
conda uninstall pytorch
conda uninstall libtorch之后通过直接下载whl文件,直接安装:
通过下载下载链接:
进到whl文件目录,执行下面语句:
pip install torch-1.0.1-cp37-cp37m-linux_x86_64.whl

这个警告没有处理,后续再看。。。

测试出错,之后又安装numpy解决。

再安装torchvison:

暂时告一段落。。。。。。。。。。。。。。。
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模