
之前的文章有关于更多操作方式详细解答,本篇基于前面的知识点进行操作,如果不了解可以先看之前的文章
Python爬虫(1)一次性搞定Selenium(新版)8种find_element元素定位方式
Python爬虫(2)-Selenium控制浏览器
Python爬虫(3)-Selenium结合pywin32模拟键盘操作
Python爬虫(4)-Selenium模拟鼠标操作
Python爬虫(5)-selenium用显式等待、隐式等待、强制等待,解决反复爬取网页时无法定位元素问题
Python爬虫(6)-selenium用requests、wget、urllib3这3种方法搞定图片和PDF文件下载
Python爬虫(7)selenium3种弹窗定位后点击操作,解决点击登录被隐藏iframe无法点击的登陆问题
Python爬虫(8)selenium爬虫后数据,存入sqlit3实现增删改查
Python爬虫(9)selenium爬虫后数据,存入mongodb实现增删改查
Python爬虫(10)selenium爬虫后数据,存入csv、txt并将存入数据提取存入另一个文件
本篇继续引用之前爬取房地产的信息作为存入的数据来源
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get("https://hui.fang.anjuke.com/loupan/all/a1_m94-95_o8_w1_z3/")
def sc():
housename = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[1]/span').text
houseaddress = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[2]/span').text
housearea = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[3]').text
#连接数据库,如果数据库中没有相应的数据库名称会自动创建一个
print(housename,houseaddress,housearea)
if __name__ == "__main__":
sc()

在写入之前需要学习python的不同模式打开文件的方式,这个非常有用
| 模式 | 描述 |
|---|---|
| r | 只读方法打开文件,默认模式,无法对文件进行修改和添加 |
| rb | 二进制打开一个文件以只读模式 |
| r+ | 打开一个文件用于读写 |
| rb+ | 以二进制格式打开一个文件用户读写 |
| w | 以二进制格式打开文件用于写入,如果存在就打开文件,不然就从头开始编辑,原有内容删除,如果文件不存在就自动创建新文件 |
| w+ | 打开一个文件用于读写,如果文件存在就打开文件,从头开始编辑,原有内容删除,如果文件不存在就创建新文件 |
| wb+ | 以二进制格式打开,如果文件存在就打开,原有内容删除,文件不存在则创建 |
| a | 追加模式,新内容追加到原有内容之后,文件不存在则创建新文件 |
| ab | 以二进制模式追加,如果文件存在 |
| a+ | 打开一个文件用于读写,如果文件存在,在原有内容追加内容进去,不存在就创建新内容用于读写 |
| ab+ | 以二进制格式打开一个文件用于追加,如果文件存在则将文件放于结尾追加内容,不存在创建新文件用于读写 |
更多具体的操作方式看下面这篇文章
Python3 输入和输出
由于我需要爬虫后写入所以需要选择以a+模式打开文件并进行写入操作
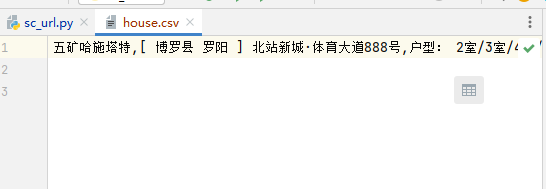
#用a+模式创建csv文件并写入
f = open('house.csv', 'a+', encoding='utf-8')
#基于文件对象构建csv写入
csv_a = csv.writer(f)
#将数据写入
csv_a.writerow([housename,houseaddress,housearea])
#关闭文件
f.close()
import csv
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get("https://hui.fang.anjuke.com/loupan/all/a1_m94-95_o8_w1_z3/")
def sc():
housename = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[1]/span').text
houseaddress = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[2]/span').text
housearea = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[3]').text
#连接数据库,如果数据库中没有相应的数据库名称会自动创建一个
print(housename,houseaddress,housearea)
#用a+模式创建csv文件并写入
f = open('house.csv', 'a+', encoding='utf-8')
#基于文件对象构建csv写入
csv_a = csv.writer(f)
#将数据写入
csv_a.writerow([housename,houseaddress,housearea])
#关闭文件
f.close()
if __name__ == "__main__":
sc()
这种方法是一次性显示所有的csv里面的内容,如果要将信息单次一条一条插入进行爬虫,就可以用for循环
import pandas as pd#导入pandas
df = pd.read_csv("house.csv", encoding='utf-8')
print(df)

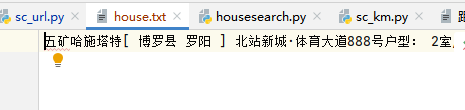
#打开txt文件以a+模式写入
sctxt = open('house.txt',mode='a+', encoding="utf-8")
#将爬虫后的文件写入
sctxt.writelines([housename,houseaddress,housearea])
#关闭文件
sctxt.close()
完整代码
import csv
import pandas as pd
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get("https://hui.fang.anjuke.com/loupan/all/a1_m94-95_o8_w1_z3/")
def sc():
housename = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[1]/span').text
houseaddress = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[2]/span').text
housearea = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[3]').text
#连接数据库,如果数据库中没有相应的数据库名称会自动创建一个
print(housename,houseaddress,housearea)
#打开txt文件以a+模式写入
sctxt = open('house.txt',mode='a+', encoding="utf-8")
#将爬虫后的文件写入
sctxt.writelines([housename,houseaddress,housearea])
#关闭文件
sctxt.close()
if __name__ == "__main__":
sc()
df = pd.read_csv("house.txt", encoding='utf-8')
print(df)

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD