本文主要介绍火焰图及使用技巧,学习如何使用火焰图快速定位软件的性能卡点。
结合最佳实践实战案例,帮助读者加深刻的理解火焰图构造及原理,理解 CPU 耗时,定位性能瓶颈。
假设没有火焰图,你是怎么调优程序代码的呢?让我们来捋一下。
想当年我刚工作,还是一个技术小白时,排查问题只能靠玄学,大致能猜出问题可能是由某个功能代码导致的,此时的排查手段就是删除多余的功能代码,然后再运行查看 CPU 消耗,确定问题。(至今我工作时还会发现一些老人使用如此方法调试性能。)
public void demo() {
if (关闭1) {
// 功能1
handle1();
}
if (关闭2) {
// 功能2
handle2();
}
if (打开3) {
// 功能3
handle3();
}
// 功能4
handle4();
}
此法全靠“经验”和“运气”,而且改动了代码结构,假设这是一个已经通过测试的集成区代码,此时需要修改代码功能来调试程序是非常危险的一件事,当然有 Git 仓库可以“一键还原”,但是,是人操作,总归会有失手的时候,且定位效率太低
当程序出现性能问题时,且不确定是哪一段代码导致耗时,可以借助方法耗时来判断,此时我们只要在调用方法前后追加执行所需耗时日志,即可判定到底是哪个方法最耗时。
public void demo() {
Stopwatch stopwatch = Stopwatch.createStarted();
handle1();
log.info("method handle1 cost: {} ms",
stopwatch.elapsed(TimeUnit.MILLISECONDS));
handle2();
log.info("method handle2 cost: {} ms",
stopwatch.elapsed(TimeUnit.MILLISECONDS));
handle3();
log.info("method handle3 cost: {} ms",
stopwatch.elapsed(TimeUnit.MILLISECONDS));
handle4();
log.info("method handle4 cost: {} ms",
stopwatch.stop().elapsed(TimeUnit.MILLISECONDS));
}
此法较上一个方法的优势是,不改变代码的逻辑情况下,只是增强了一些观测点位,由方法的耗时来定位性能瓶颈。但是,假设方法的处理调用栈很深,就不得不在子方法中再次埋点,此时判定流程即为:埋点 -> 发版 -> 定位 -> 埋点 -> 发版 -> 定位 -> .......且本质上也是改了代码,就有出错的可能。 心累,不高效!
一般企业的软件服务都是部署在 Linux 操作系统上,有经验的老手排查性能最方便的办法就是 top 定位。
top -p pid -H
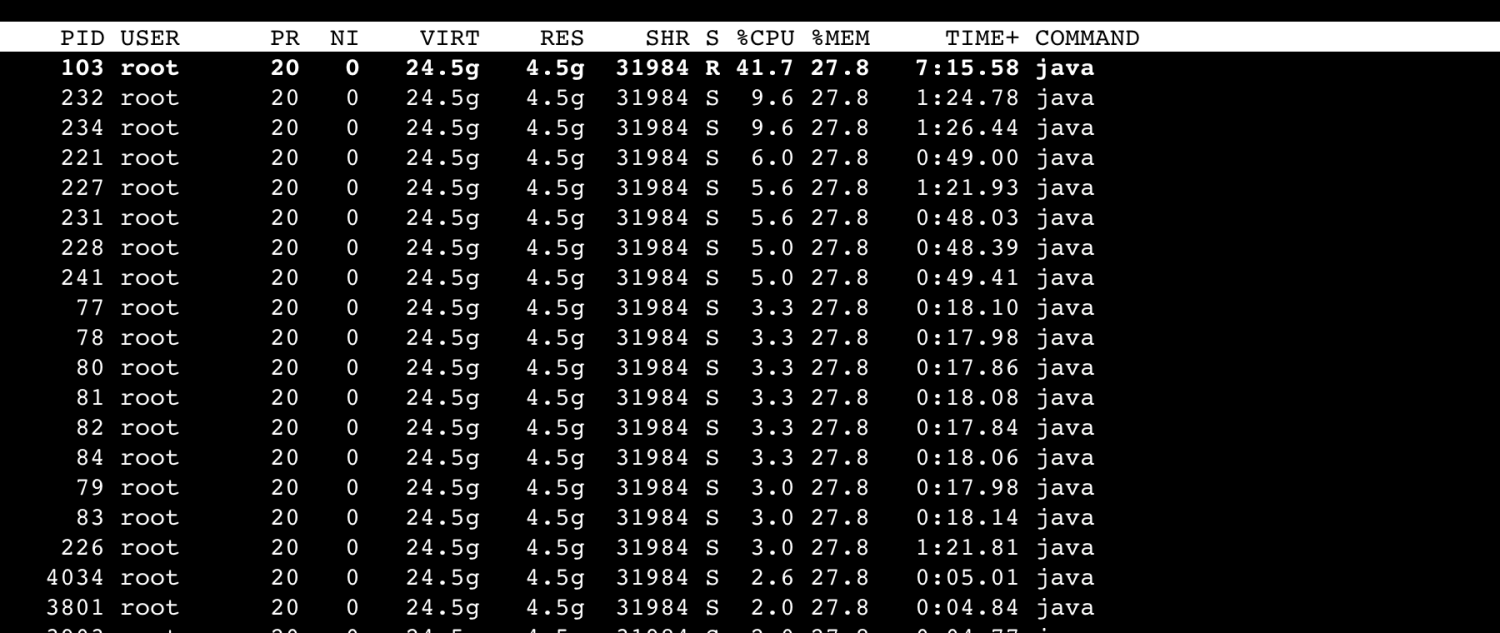
明显看到,pid 103 消耗了 40%的 CPU, 找到对应的 stack 线程信息如下(忽略查找办法,我假设你已经会了:)):
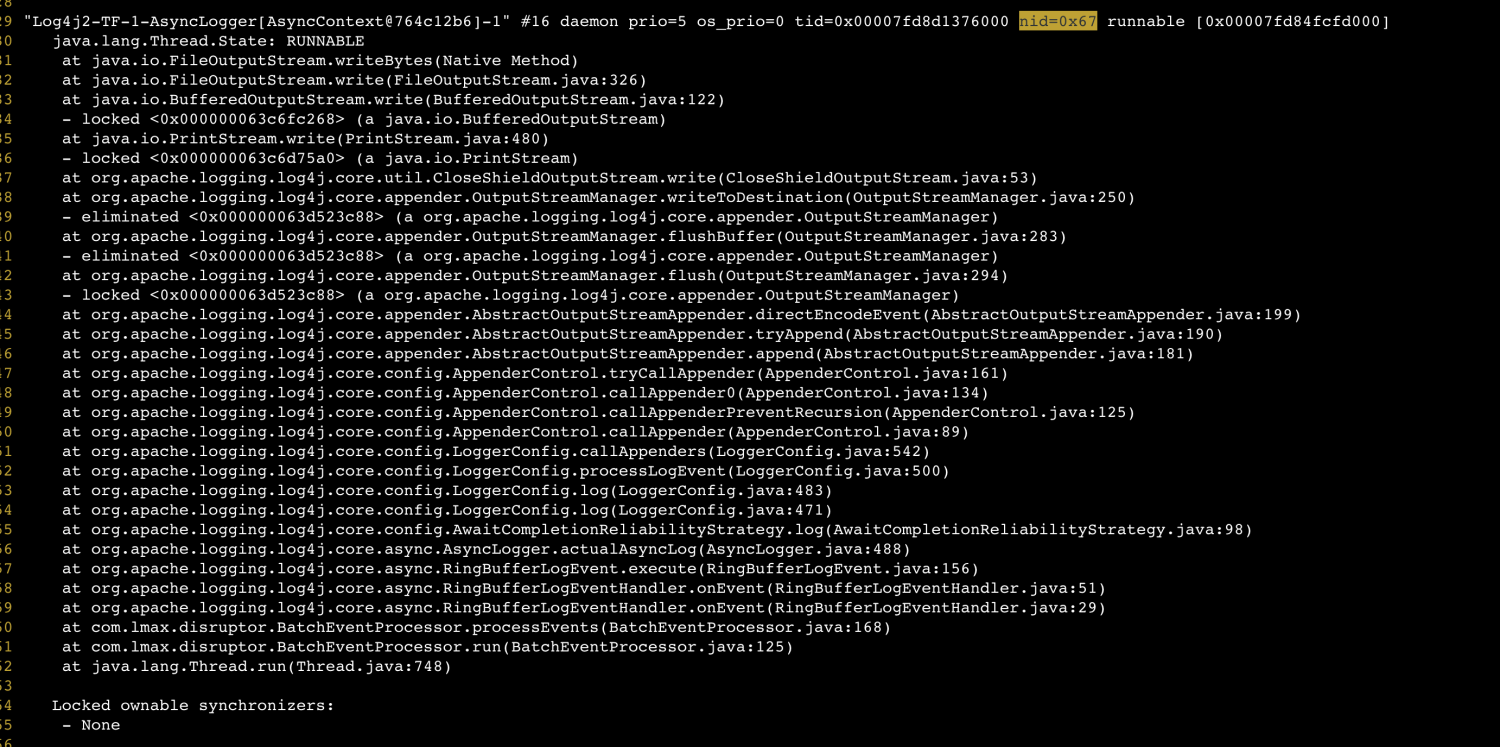
此时可以得出结论,当前最耗 CPU 的线程是写入磁盘文件,追查代码最终会定位到是因为在高并发场景下打了大量的 INFO 日志,导致磁盘写入成为瓶颈。
总结:TOP 命令对于找 CPU 性能瓶颈时很有效的,但是存在如下几个问题:
火焰图(Flame Graphs),因其形似火焰而得名。
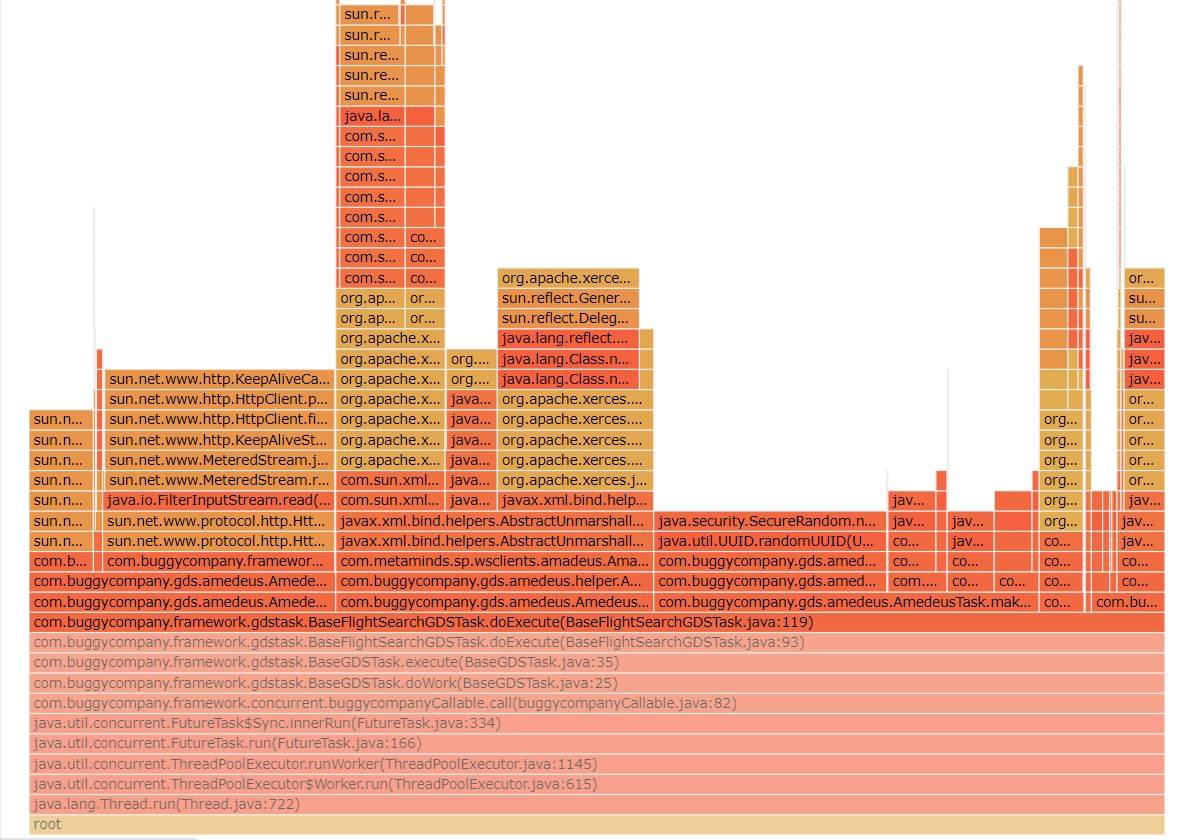
如上就是一个典型的火焰图,它由各种大小/颜色的方块组成,每个方块内部还标识了文字,整个图片顶部凹凸不平,形似一簇簇“火苗”,因此得名火焰图。
火焰图是 SVG 生成,因此可以与用户互动,鼠标悬浮在某个方块时,会详细展示内部文字。点击后,即会以当前被点击方块为底向上展开。
特征
使用火焰图分析之前,我们得首先了解火焰图的基本构造
那此时你已经知道了火焰图,如何定位软件问题呢?我们需要一套寻找性能瓶颈的方法论。
可以明确的是 CPU 消耗高的口径
CPU 消耗高的口径 = 调用栈出现频率最高的一定是吃 CPU 的
如上我们已经知道了火焰图的构造,及“物料”含义,此时我们的关注点应该在方形的宽度上,方形的宽度大小代表了该调用栈在整个抽样历史中出现的次数。次数意味着频率,即出现次数越多的即可能最消耗 CPU。

但只关注最长的是没用的,如底部的 root 和中部的方块都很宽,只能说明这些方法是“入口方法”,即每次发起调用都会经过的方法。
我们更应该关注火焰山顶部的"平顶山"(plateaus)出现的次数多,即没有子调用,抽样出现的频率高,说明执行方法的时间较长,或者执行频率太高(如长轮询),即CPU 大部分执行都分配给了“平顶山”,它才是性能瓶颈的根因。
总结方法论:火焰图看“平顶山”,山顶的函数可能存在性能问题!
实践是检验真理的唯一标准!下面我将以一个小的 Demo 来展示如何定位程序性能问题,加深对火焰图使用的理解。
Demo 程序如下:
public class Demo {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(20);
while (true) {
executorService.submit(Demo::handle1);
executorService.submit(Demo::handle2);
executorService.submit(Demo::handle3);
executorService.submit(Demo::handle4);
}
}
@SneakyThrows
private static void handle4() {
Thread.sleep(1000);
}
@SneakyThrows
private static void handle2() {
Thread.sleep(50);
}
@SneakyThrows
private static void handle3() {
Thread.sleep(100);
}
@SneakyThrows
private static void handle1() {
Thread.sleep(50);
}
}
代码很简单,当然现实中也不会这么写,主要是配合演出。。
主要是开了一个线程池,且分别执行四个 task,不同的 task 耗时不一致,此时我们的性能瓶颈在 handle4 这个任务上,在知道结论的前提下,我们比较看火焰图得出答案的是否符合预期!
当前我是在自己的 Mac 上运行的程序,idea 执行这一段程序非常便捷,那如何获取当前运行 main 函数的 PID?
此时需要用到 TOP 命令,上面是个 while 死循环,很明显吃 CPU最厉害,只要找到归属 Java 线程的最高一个 PID 即为所求。
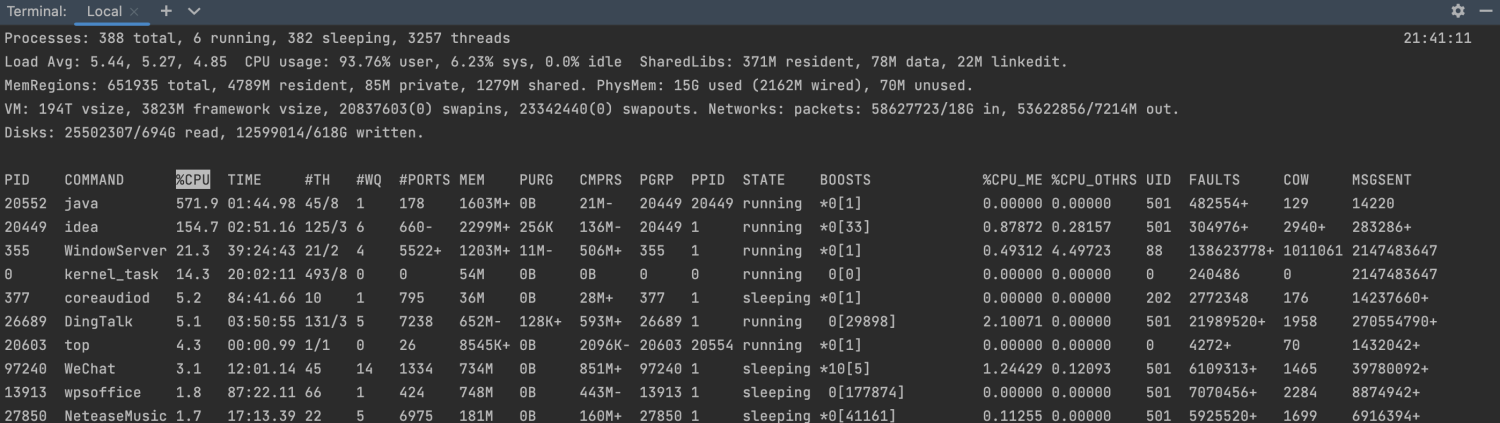
很明显得到 COMMAND = java 最高的 PID = 20552
此时执行如下命令获取堆栈信息,并写入 tmp.txt 文件
jstack -l 20552 > tmp.txt
生成火焰图的工具有很多,我一般会借助 FastThread,在线分析堆栈,非常方便,同时支持生成火焰图,方便我们定位问题
打开官网首页,选择刚刚 dump 的堆栈文件,点击 Analyze,此时只需要等待网站分析好后(正常 3~5 s),即可查看火焰图
fastThread 网站分析报告非常丰富,一般的问题我们直接通过它给出的结论基本能定位到问题了,本文暂且无需关注,感兴趣的话,后续我会分享,直接拉到 Flame Graph 子标题处
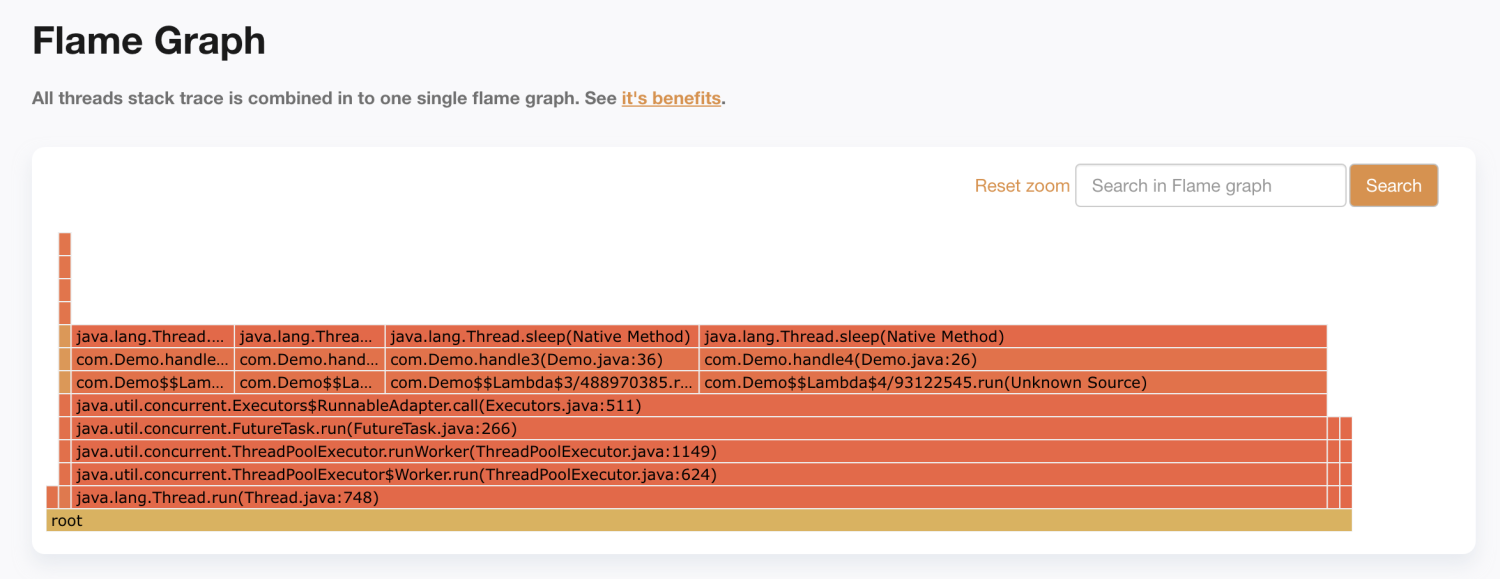
此时明显能看出4个“平顶山”,且 com.Demo.handle4 宽度最大,com.Demo.handle3 次之,符合预期!
基于上述小 Demo ,我们深入理解下火焰图的生成原理。
举个例子,便于你理解,假设我们要观测一个人在忙些什么,哪些事最占用他的时间,会怎么做?
从时间维度的话,且不考虑成本的话,我肯定安排一个监控摄像头,全天候 24h,360度监控他,然后再安排人员,逐帧排查,并汇总他所做的事,得出:睡觉 8h,工作8h,玩手机 4h,吃饭2h,其它2h。从而得出结论:睡觉占用他时间最多。
由上可以总结一套分析流程:
记录(监控)-> 分析&归并(逐帧排查) -> Top N -> 得出结论
带着流程去看我们应该如何排查 CPU 在执行中,哪些事(进程/线程)最占用它的时间呢?
简单粗暴的方法是每时每刻都记录执行的方法堆栈,再汇总归并,得出最耗时的方法栈在哪。此法的问题在于
其实只要采样去观测 CPU 在干什么就好了,这是一个概率学问题,如果 CPU 因为执行某个方法耗时,大概率采样下来,得到的归并结果也是最多的,虽然有误差,但是多次统计下,差不了多少的。
同理,dump 下的堆栈,查看大多数线程在干什么,依据堆栈内每个方法出现的频率聚合,出现的频次最多的就是当前 CPU 分配执行最多的方法。
"pool-1-thread-18" #28 prio=5 os_prio=31 tid=0x00007f9a8d4c0000 nid=0x8d03 sleeping[0x000000030be59000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at com.Demo.handle2(Demo.java:31)
at com.Demo$$Lambda$2/1277181601.run(Unknown Source)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- <0x00000006c6921ac0> (a java.util.concurrent.ThreadPoolExecutor$Worker)
至于我们的 jstack 信息如何被处理成火焰图的格式,社区已经为常见的 dump 格式都提供了工具,stackcollapse-jstack.pl 处理 jstack 输出。
Example input:
"MyProg" #273 daemon prio=9 os_prio=0 tid=0x00007f273c038800 nid=0xe3c runnable [0x00007f28a30f2000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:121)
...
at java.lang.Thread.run(Thread.java:744)
Example output:
MyProg;java.lang.Thread.run;java.net.SocketInputStream.read;java.net.SocketInputStream.socketRead0 1
火焰图的介绍到此结束,相信你又多了一种排查问题的手段!
存在即合理,工具之开发重要性而言不必多说,我始终持包容态度面对新事物,它确确实实解决了某些痛点而脱颖而出的。
后续我会介绍更多排查问题的手段,如果你喜欢本文风格,请关注或留言,欢迎讨论!
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
是否存在GC.disable会降低性能的情况?只要我使用的是真正的RAM而不是交换内存,就可以这样做吗?我正在使用MRIRuby2.0,据我所知,它是64位的,并且使用的是64位的Ubuntu:ruby2.0.0p0(2013-02-24revision39474)[x86_64-linux]Linux[redacted]3.2.0-43-generic#68-UbuntuSMPWedMay1503:33:33UTC2013x86_64x86_64x86_64GNU/Linux 最佳答案 GC.disable将禁用垃圾回收。像rub
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我尝试在Internet上搜索有关使用angularJS进入RubyonRails项目与RubyonRailspure的View性能的信息。我的问题是因为2个月前我开始使用纯AngularJS,现在我需要将AngularJS集成到一个新项目中,但需要展示使用带有RubyonRails的AngularJS呈现View的性能如何,并消除对RubyonRails的负担.例如:带Rails的Angular:使用RubyonRails获取数据(从数据库或GET请求),将信息发送到file.js.erb并使用AngularJS操作数据并显示带有解析数据的View。纯粹的Rails:(自然流程)使用
我觉得我理解require和require_dependency之间的区别(来自Howarerequire,require_dependencyandconstantsreloadingrelatedinRails?)。但是,我想知道如果我使用一些不同的方法(参见http://hemju.com/2010/09/22/rails-3-quicktip-autoload-lib-directory-including-all-subdirectories/和Bestwaytoloadmodule/classfromlibfolderinRails3?)来加载所有文件会发生什么,所以我们:
