最近趁着有空想复习一下Kafka原理,之前学的是Kafka1.9的版本,需要Zookeeper作为基础,专门存放Kafka的元数据使用,如Broker、Consumer、Topic等;但下载的时候发现Kafka已经升级到3.3的版本,真是时光飞逝,岁月荏苒呀,更新速度太快了!不过话又说回来,程序猿不就是活到老学到老嘛,啥也不说了,开干!顺嘴提一句,3.1以后的版本可以不用Zookeeper支持,Kafka自己支持了,这样可以减少资源占用,也可以在没有必要的情况下不用单独安装Zookeeper!
程序猿,你懂得,阿里服务器,CPU 1核, 内存2G
[root@Genterator ~]# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
1 Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
[root@Genterator ~]# cat /proc/meminfo | grep MemTotal
MemTotal: 1790344 kB
[root@Genterator ~]# free -h
total used free shared buff/cache available
Mem: 1.7Gi 1.4Gi 134Mi 0.0Ki 212Mi 204Mi
Swap: 2.5Gi 114Mi 2.4Gi
kafka每个broker的内存默认为1G,对于咱们这种屌丝程序猿只能用硬盘充当内存使用了!此处使用了Linux的交换分区,==当虚拟机内存不足时, 把一部分不用的硬盘空间虚拟成内存使用,从而解决内存不足问题。==虽然性能不及内存,但好在还能凑合使用,学习、测试完全ok!
[root@Genterator ~]# docker-compose -v
docker-compose version 1.27.4, build 40524192
Kafka使用最新版,在复习的过程中顺便体验一下新版的性能与特色,重申一遍:新版不在需要ZK的支持!

由于Kafka官方并未提供docker镜像,此处使用的是Docker Hub中的bitnami/kafka,使用人数较多,估计坑也踩得差不多了,算比较安全稳定点的
不说废话,直接上配置文件
version: "3.6"
services:
kafka1:
container_name: kafka1
image: 'bitnami/kafka:3.3.1'
user: root
ports:
- '19092:9092'
- '19093:9093'
environment:
# 允许使用Kraft
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# 定义kafka服务端socket监听端口(Docker内部的ip地址和端口)
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 定义安全协议
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
#定义外网访问地址(宿主机ip地址和端口)
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://11.21.13.15:19092
- KAFKA_BROKER_ID=1
- KAFKA_KRAFT_CLUSTER_ID=iZWRiSqjZAlYwlKEqHFQWI
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@172.23.0.11:9093,2@172.23.0.12:9093,3@172.23.0.13:9093
- ALLOW_PLAINTEXT_LISTENER=yes
# 设置broker最大内存,和初始内存
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
volumes:
- /opt/volume/kafka/broker01:/bitnami/kafka:rw
networks:
netkafka:
ipv4_address: 172.23.0.11
kafka2:
container_name: kafka2
image: 'bitnami/kafka:3.3.1'
user: root
ports:
- '29092:9092'
- '29093:9093'
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://11.21.13.15:29092 #修改宿主机ip
- KAFKA_BROKER_ID=2
- KAFKA_KRAFT_CLUSTER_ID=iZWRiSqjZAlYwlKEqHFQWI #哪一,三个节点保持一致
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@172.23.0.11:9093,2@172.23.0.12:9093,3@172.23.0.13:9093
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
volumes:
- /opt/volume/kafka/broker02:/bitnami/kafka:rw
networks:
netkafka:
ipv4_address: 172.23.0.12
kafka3:
container_name: kafka3
image: 'bitnami/kafka:3.3.1'
user: root
ports:
- '39092:9092'
- '39093:9093'
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://11.21.13.15:39092 #修改宿主机ip
- KAFKA_BROKER_ID=3
- KAFKA_KRAFT_CLUSTER_ID=iZWRiSqjZAlYwlKEqHFQWI
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@172.23.0.11:9093,2@172.23.0.12:9093,3@172.23.0.13:9093
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_HEAP_OPTS=-Xmx512M -Xms256M
volumes:
- /opt/volume/kafka/broker03:/bitnami/kafka:rw
networks:
netkafka:
ipv4_address: 172.23.0.13
networks:
name:
netkafka:
driver: bridge
name: netkafka
ipam:
driver: default
config:
- subnet: 172.23.0.0/25
gateway: 172.23.0.1
注:其中11.21.13.15的ip为我乱写的,代表我阿里云服务器的ip地址,如有雷同,纯属巧合!
[root@Genterator ~]# docker-compose up -d
kafka1...done
kafka2...done
kafka3...done
检查kafka运行是否正常
[root@Genterator ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
606a05866b2a bitnami/kafka:3.3.1 "/opt/bitnami/script…" 5 hours ago Up 5 hours 0.0.0.0:39092->9092/tcp, 0.0.0.0:39093->9093/tcp kafka3
57f0ff2fb97d bitnami/kafka:3.3.1 "/opt/bitnami/script…" 5 hours ago Up 5 hours 0.0.0.0:19092->9092/tcp, 0.0.0.0:19093->9093/tcp kafka1
98a8b542a8bb bitnami/kafka:3.3.1 "/opt/bitnami/script…" 5 hours ago Up 5 hours 0.0.0.0:29092->9092/tcp, 0.0.0.0:29093->9093/tcp kafka2
选择一个kafka节点进入到容器中,找到对应的安装kafka路径/opt/bitnami/kafka
[root@Genterator ~]# docker exec -it kafka1 /bin/bash
root@57f0ff2fb97d:cd /opt/bitnami/kafka
LICENSE NOTICE bin config libs licenses logs site-docs
root@57f0ff2fb97d:/opt/bitnami/kafka# cd bin
# 创建一个副本为3、分区为5的topic
root@57f0ff2fb97d:/opt/bitnami/kafka/bin# ./kafka-topics.sh --create --topic foo --partitions 5 --replication-factor 3 --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092
Created topic foo.
# 查看topic详细信息
root@57f0ff2fb97d:/opt/bitnami/kafka/bin# kafka-topics.sh --describe --topic foo --bootstrap-server kafka1:9092, kafka2:9092, kafka3:9092
Topic: foo TopicId: 83kWG4PUT9u4fOzG5WgFoA PartitionCount: 5 ReplicationFactor: 3 Configs:
Topic: foo Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: foo Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: foo Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: foo Partition: 3 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Topic: foo Partition: 4 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
在图形化界面中可以看到:
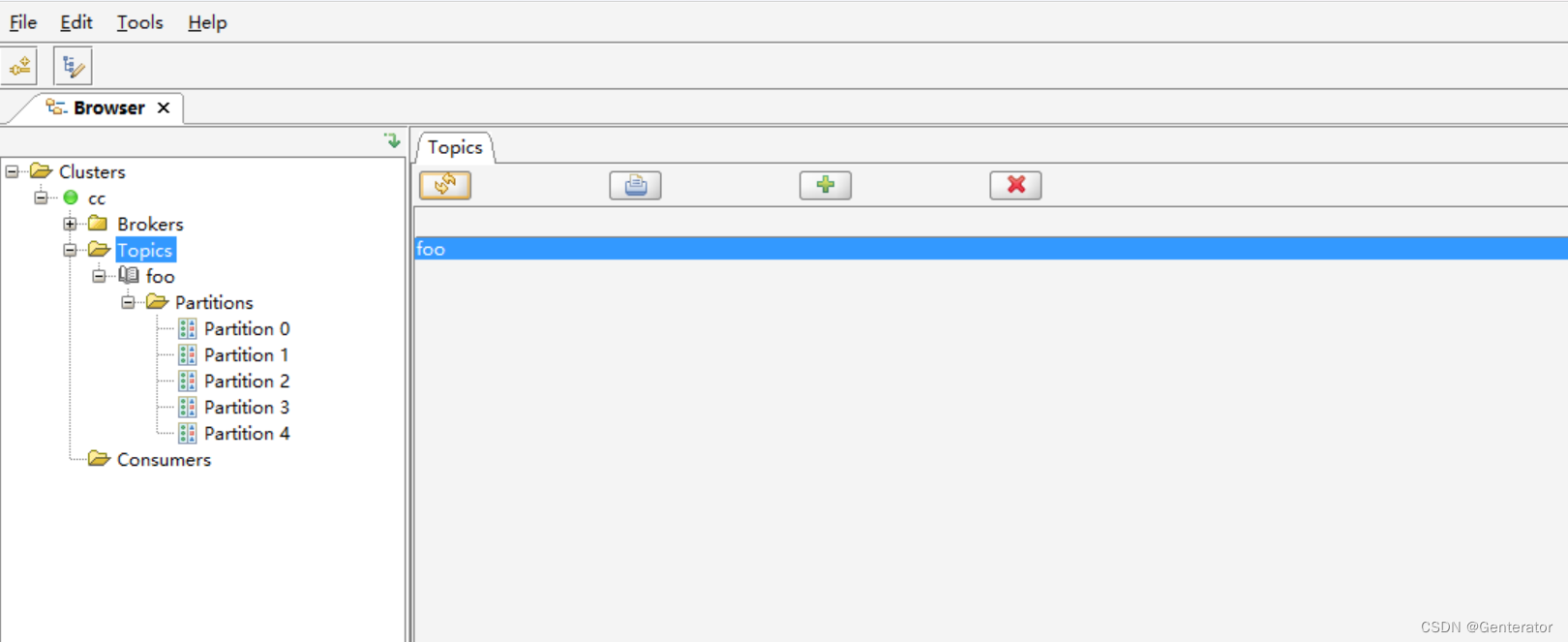
此时我在kafka1上进行生产,kafka2和kafka3将进行消费
root@57f0ff2fb97d:/opt/bitnami/kafka/bin# kafka-console-producer.sh --broker-list 172.23.0.11:9092,172.23.0.12:9092,172.23.0.13:9092 --topic foo
>Hello
>Kafka
root@57f0ff2fb97d:/opt/bitnami/kafka/bin# kafka-console-consumer.sh --bootstrap-server 172.23.0.11:9092,172.23.0.12:9092,172.23.0.13:9092 --topic foo
root@57f0ff2fb97d:/opt/bitnami/kafka/bin# kafka-topics.sh --delete --topic foo --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss
如何使用Capistrano将Rails应用程序部署到无法访问外部网络或存储库的生产或暂存服务器?我已经设法完成部署的一半,并意识到Capistrano没有在我的本地机器上下载gitrepo,但它首先连接到远程服务器并尝试在那里下载Git存储库。我希望有一个类似Javaee的构建系统,其中创建可交付成果并将该可交付成果发送到服务器。就像您构建.ear文件并将其部署到您想要的任何服务器上一样。显然在RoR中,你被迫(据我所知)在该服务器上构建应用程序,在那里创建一个gem存储库,在那里克隆最新的分支等等。有什么方法可以将准备运行的包发送到远程服务器吗? 最佳答