用 Go 语言的小伙伴对协程应该都非常熟悉了,而 Java 直到 2022 年 9 月 20 日,JDK19 才终于提供了协程(官方说法是 Virtual Thread 虚拟线程,不过看介绍就是协程 Coroutine)的测试版本功能。
在 Java 中,我们一直依赖线程作为并发服务器应用程序的构建基础。每个方法中的每个语句都在线程内执行,并且每个线程都提供一个堆栈来存储局部变量和协调方法调用,以及出错时的上下文,开发人员可以使用线程的堆栈来跟踪程序的具体执行过程。
以下参考 OpenJDK 官方文档:https://openjdk.org/jeps/425
Thread-Per-Request,翻译过来就是一个请求一个线程。服务器应用程序通常处理相互独立的并发用户请求,因此应用程序通过在某个请求的持续时间内将一个线程专门用于处理这个请求是非常有意义且必要的。这种 thread-per-request 风格易于理解、易于编程、易于调试和分析,因为它使用平台的并发单元来表示应用程序的线程数量,比如你有 100 个并发请求,那就对应 100 个线程。
但是,服务器应用程序的可伸缩性受 Little 定律支配,它与延迟、并发性和吞吐量相关,这里我简单介绍下 Little 定律,不是什么重点知识,大伙儿随便看下就行:
Little 定律是由 John Little 在 1961 年提出的,在一个具有稳定流量和容量的队列中,平均用户数等于平均流量和平均服务时间的乘积。
具体来说,假设我们有一个队列,它有一定的容量,同时有一定的流量在进出队列。如果我们令队列中平均用户数为 L,平均流量为 λ,平均服务时间为 W,则 Little 定律可以表示为:
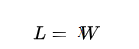
这个定律适用于任何类型的任务,包括服务请求、进程、线程、作业、数据包等等。它可以用来预测系统的吞吐量、延迟和并发性,并且在系统设计和性能优化中非常有用。
如果我们想要在平均服务时间 W(请求处理时间)不变的情况下,增大平均流量 λ(吞吐量),那么平均用户数(L)势必要同比例增长,换句话说,对于给定的请求处理持续时间(即延迟),应用程序同时处理的请求数(即并发性)必须与吞吐量成比例增长。
例如,假设一个平均延迟为 50ms(W = 0.05) 的应用程序通过并发处理 10 个请求(L = 10)来实现每秒 200 个请求的吞吐量(λ = 200)。为了使该应用程序扩展到每秒 2000 个请求的吞吐量(λ = 2000),它需要并发处理 100 个请求(L = 100)。
如果每个请求都需要一个单独的线程进行处理,那么随着吞吐量的增加,线程数量将会急剧增加。
不幸的是,可用线程的数量是有限的,因为 JDK 线程的本质其实是操作系统线程,详细可看下这篇文章 Java 线程和操作系统的线程有啥区别?,而操作系统线程成本很高,所以我们不可能拥有太多线程,这使得 Thread-Per-Request 风格难以实现。如果每个请求在其持续时间内消耗一个 Java 线程,并因此消耗一个操作系统线程,那么在其他资源(例如 CPU 或网络连接)耗尽之前,线程的数量必定会成为性能限制的重要因素,所以 JDK 当前的线程实现使得应用程序的吞吐量被限制在远低于硬件可以支持的水平,有同学可能会说不是有线程池吗?即使线程被池化也会发生这种情况,因为池化虽然有助于避免启动新线程的高成本,但并不会增加线程总数。
为了充分利用硬件,开发者们放弃了 Thread-Per-Request 的风格,转而采用线程共享(Thread-Sharing)。不是在一个线程上从头到尾处理一整个请求,而是在等待 I/O 操作完成时将该线程返回到线程池中,以便该线程可以为其他请求提供服务, I/O 操作完成后再利用回调函数进行通知。
通俗来说,在异步风格中,请求的每个阶段可能在不同的线程上执行,并且每个线程以交错的方式运行属于不同请求的阶段。这种细粒度的线程共享允许大量并发操作而不会消耗大量线程,消除了操作系统线程稀缺对吞吐量的限制。
举个例子,假设有一个网络服务器程序,需要处理来自客户端的请求并进行数据库查询,然后将结果返回给客户端。如果使用传统的线程池来处理请求,每当有一个请求到来时,就需要从线程池中取出一个线程进行处理。但是在请求过程中,当线程需要等待数据库查询结果时,它就会被阻塞,无法进行其他的请求处理,浪费了一个线程资源。如果使用异步 IO 操作,当线程需要进行数据库查询时,它可以将这个线程释放给线程池中的其他请求,等到数据库查询完成后,再将线程恢复执行,将查询结果返回给客户端。这样,一个线程就可以处理多个请求,从而提高并发能力。
但是由于不是一个线程处理一整个请求,这就导致我们必须将请求处理逻辑分解为小阶段,通常编写为 lambda 表达式,然后使用 API 将它们组合成一个顺序管道(比如 CompletableFuture)。
如果实际用过 lambda 表达式的同学肯定会深有感触,这简直是对 Debug 的灾难性打击:
并且,从另一个角度来说,这种编程风格与 Java 平台不一致,因为应用程序的并发单元(异步管道)不再是平台的并发单元(简单来说就是 100 个并发请求不是对应 100 个线程了,可能就对应 10 个线程)。
除开上述两种编程风格的缺点考虑,使用进程/线程模型还有一个不容忽视的弊端,那就是上下文切换的开销。而协程的上下文切换代价较小,其优势在于可以将一个线程切换为多个协程,每个协程之间可以轻松地进行切换,从而提高应用程序的吞吐量。
举个例子,我们只需要启动 100 个线程,每个线程上运行 100 个协程,这样不仅减少了线程切换开销,而且还能够同时处理 100 * 100 = 10000 个请求。
所以什么是协程(Coroutine)?
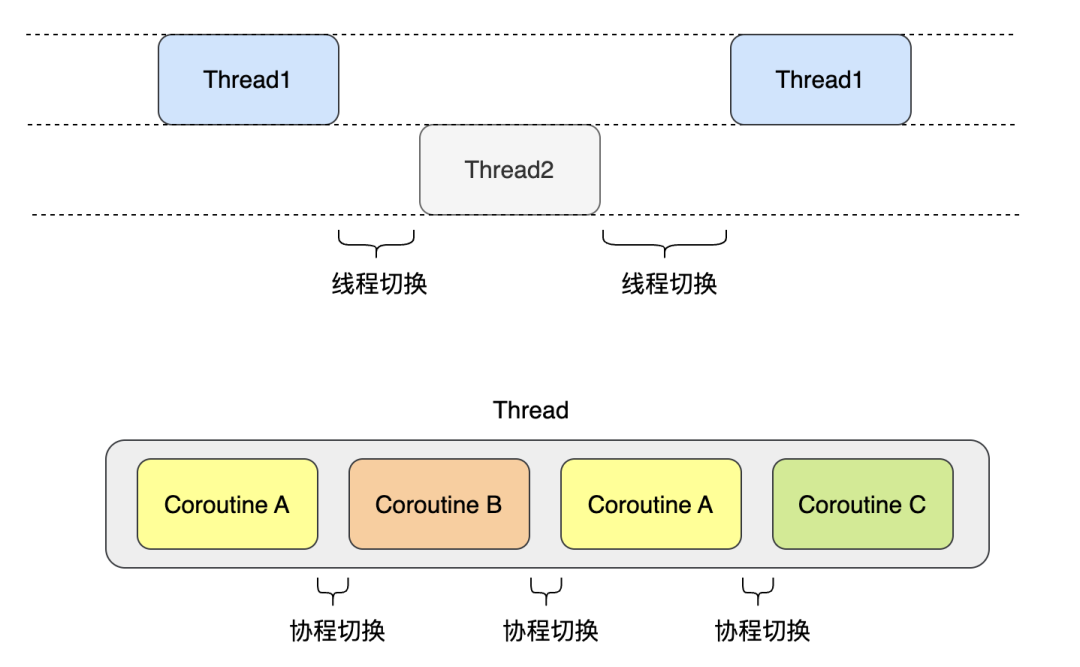
分析下协程相对于进程/线程的好处:
协程运行在线程之上,所以必然受到线程的限制。
如果协程调用了一个阻塞 IO 操作,由于操作系统并不知道协程的存在(因为协程运行在用户态),它只知道线程,因此在协程调用阻塞 IO 操作的时候,操作系统会让协程之上对应的线程陷入阻塞状态,也就是说当前的协程和其它绑定在该线程之上的协程都会陷入阻塞而得不到调度。
因此在协程中要么就别调用导致线程阻塞的操作,要么就采用异步编程的方式。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts