首先nosql可以被理解为not only sql 泛指非关系型数据库,也就是说不仅仅是sql,所以它既包含了sql的一些东西,但是又和sql不同,并在其的基础上改变或者说扩展了一些东西。
提到nosql,首先我们就要分析一下关系型数据库的行式存储和非关系型数据库的列式存储区别在哪?
行式存储我们都很熟悉,不论是mysql数据表还是我们熟悉的excel表,这些表里每一行都是完整的一条数据,它们彼此关联,彼此有关系。
以核酸检测的数据为例:
一般核酸检测需要以下几个字段:姓名、身份证号、检测机构、检测时间、结果、价格
比如是这样的:
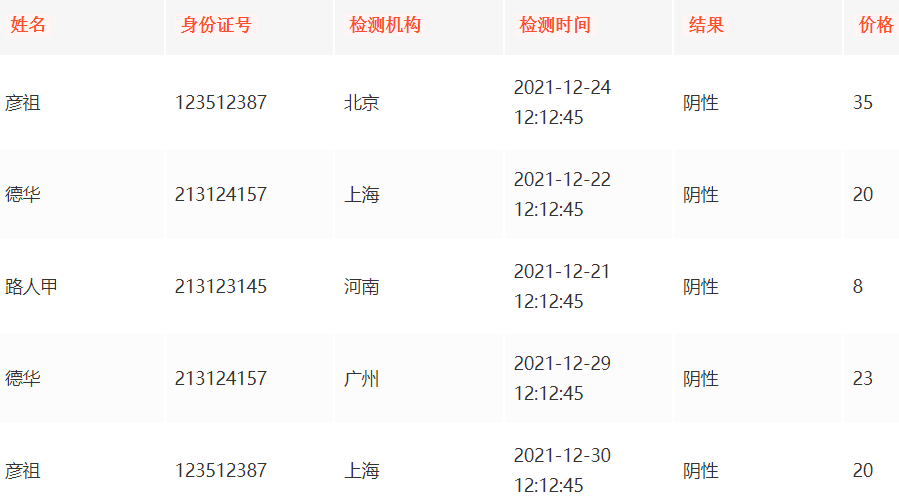

select * from 核酸记录表 where 身份证号='彦祖的身份证号'
1.先从索引查询出来彦祖的记录存储的物理地址
2.在通过物理地址去表的物理存储中查询对应地址中的数据
价格列sum就可以实现,sql如下:select sum(价格) from 核酸记录表 where 身份证号='彦祖的身份证号'
1.先从索引查询出来彦祖的记录存储的物理地址
2.在通过物理地址去表的物理存储中查询对应地址中的数据
3.拿到所有数据时候,再通过对于价格列sum聚合得到结果
select sum(价格),但是读取物理存储时候,还是读取出来了所有的字段优点:1.连续空间对于插入/更新很方便
2.对于记录查询很方便
缺点1.会查询出来很多不需要的列

姓名列,是把所有记录中的姓名这列的值使用连续空间存放到一起数据压缩和查询执行流程字典表的方式进行数据压缩姓名列,这列的所有数据如下:彦祖|德华|路人甲|德华|彦祖
对这列值去重以后,构建一张姓名列字典表,构建算法忽略,就使用自增id的方式,如下:
id |
姓名列 |
|---|---|
| 1 | 彦祖 |
| 2 | 德华 |
| 3 | 路人甲 |
这样构建字典表,对于列存储的物理存储结构,就可以执行存储字典表中的id,而不用存储具体的值,有了字典表以后姓名列存储如下:
1|2|3|2|1
价格列,这列的所有数据如下:35|20|8|23|20
对这列值去重以后,构建一张价格列字典表,构建算法忽略,就使用自增id的方式,如下:
id |
价格列 |
|---|---|
| 1 | 35 |
| 2 | 20 |
| 3 | 8 |
| 4 | 23 |
有了字典表以后价格列存储如下:
1|2|3|4|2
彦祖,20块钱做的核酸记录:select * from 核酸记录表 where 姓名=彦祖 and 价格=20
1.对于where 姓名=彦祖
首先查询姓名字典表,查询到彦祖的id=1
id |
姓名列 |
|---|---|
| 1 | 彦祖 |
| 2 | 德华 |
| 3 | 路人甲 |
2.通过查询到彦祖的id,对于性名列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
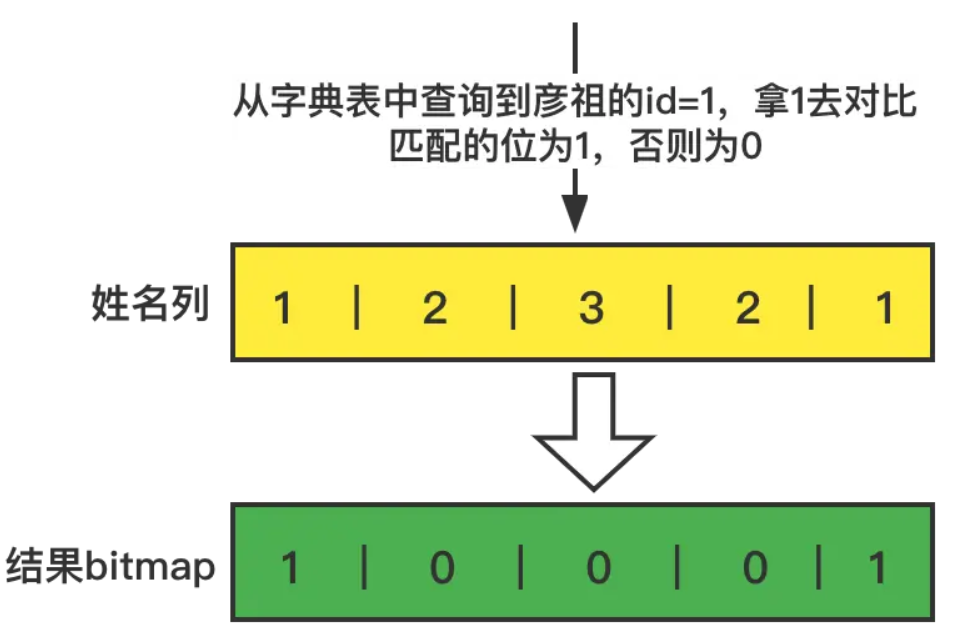
3.对于where 价格=20 和上面一样的操作,先查询价格字段表,20 的id=2
id |
价格列 |
|---|---|
| 1 | 35 |
| 2 | 20 |
| 3 | 8 |
| 4 | 23 |
4.通过查询到价格20的id,对于价格列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
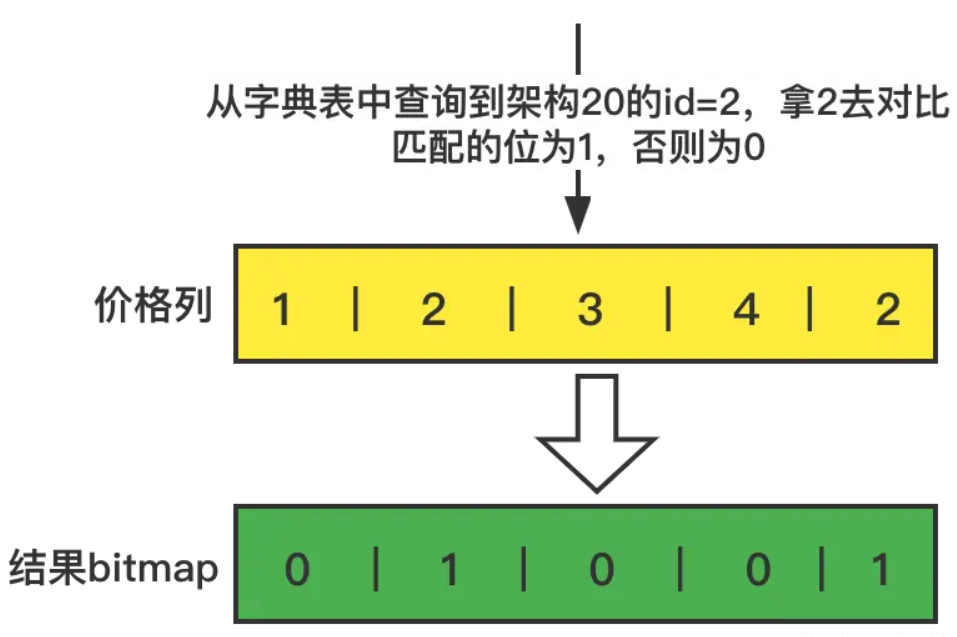
5.对于两个where条件的结果bitmap做与运算,bitmap中,位为1的索引就是要查询数据的所有列的索引,如该例子中,两个结果bitmap与运算后的结果是00001,所以所有列的第5个值,拼接起来就是我们要查询的数据。
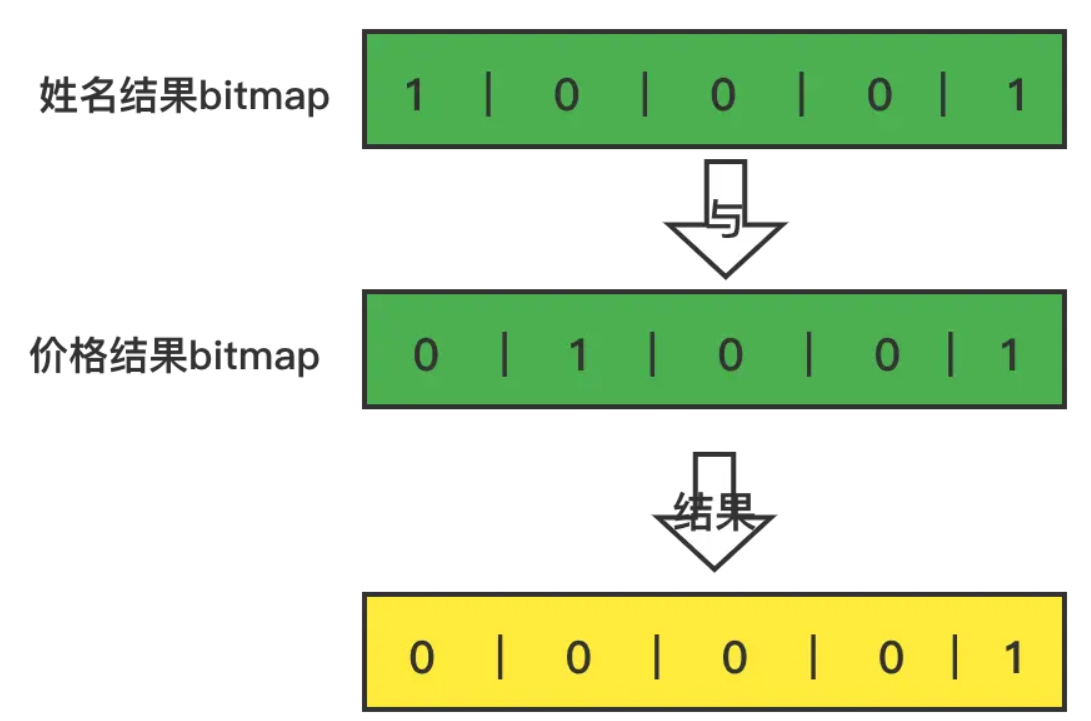
6.所以我们把所有列的第五个值拿出来组装后就是我们需要的数据
数据压缩,在数据压缩上列存储有一定的优势select sum(价格) from 核酸记录表 where 身份证号='彦祖的身份证号'
分开存储的,按照上面讲的查询流程,其实最后我们得到的结果bitmap,拿到位=1的索引后,我们不需要查询所有的列,只需要拿着索引去价格列中获取相应位置的值,然后在进行sum聚合每一个列进行操作,没有行存储连续空间那么方便优点:1.数据压缩比较有优势
2.任何列都可以做索引
3.查询时只有涉及到的列会被读取
缺点1.每次查询时,都需要对查询到的列进行数据重新组装
2.插入/更新操作比较困难
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or