文章目录
解题思路
这道题是让我们使用前序遍历的方式来创建字符串,但是有一点需要注意的是,再创建的字符串中,需要将每一个左右子树用括号括起来。这里扩括号的时候有两点需要注意的细节:
- 当左右子树都为空时,该节点左右子树的括号都可以省略掉。
- 当左子树不为空,右子树为空时,省略掉右子树的括号。
- 当左子树为空,右子树不为空时,左子树的括号不能省略掉。
代码实现
class Solution {
public:
string tree2str(TreeNode* root) {
if(root == nullptr)
return "";
string str = to_string(root->val);
//左右子树都为空,省略掉左右子树的括号
//左不为空右为空,省略掉右子树的括号
//左为空,右不为空时,左子树的括号不能省略
if(root->left || root->right){
str += '(';
str += tree2str(root->left);
str += ')';
}
if(root->right){
str += '(';
str += tree2str(root->right);
str += ')';
}
return str;
}
};

解题思路
首先,定义一个队列q、记录当前层节点个数的变量levelnum 和vector <vector < int > >来存储遍历后的结果。 然后判断根节点是不是空, 如果不是空先将根节点入队列,然后levelnum置为1。
外层循环控制队列是否为空,如果为空,则说明节点已经全部出队。该树也已经被访问完了。内层循环来控制每一层节点的个数,然后在队列中按照对头——对尾的顺序依次访问队列中的每一个节点,每访问一个节点,就让该节点出队,并让该节点的左右非空孩子节点入队,这样一来,上一层的节点全部出队后,下一层的节点也就全部入队了。内层循环每循环完一次,就将新队列中的元素个数赋给levelnum 。这样每一层的节点就被依次插入二维数组中的每一行中了。
代码实现
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> vv;
queue<TreeNode*> q;
int levelnum = 0;
if(root){
q.push(root);
levelnum = 1;
}
while(!q.empty())
{
vector<int> v;
while(levelnum--)
{
TreeNode* tmp = q.front();
v.push_back(tmp->val);
q.pop();
if(tmp->left)
q.push(tmp->left);
if(tmp->right)
q.push(tmp->right);
}
vv.push_back(v);
levelnum = q.size();
}
return vv;
}
};

解题思路
这道题目和上一道题的不同点在于:上一道题目是从上到下依次遍历每一层的元素,这道题是从下到上依次遍历每一层。所以对于这道题目,我们只需要将上一道题目的代码拷贝过来,然后将结果逆置一下就可以了。
代码实现
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> q;
vector<vector<int>> vv;
int levelSize = 0;
if(root)
{
q.push(root);
levelSize = 1;
}
while(!q.empty())
{
vector<int> v;
while(levelSize--)
{
TreeNode* tmp = q.front();
v.push_back(tmp->val);
if(tmp->left) q.push(tmp->left);
if(tmp->right) q.push(tmp->right);
q.pop();
}
vv.push_back(v);
levelSize = q.size();
}
return vv;
}
vector<vector<int>> levelOrderBottom(TreeNode* root) {
vector<vector<int>> vv = levelOrder(root);
reverse(vv.begin(),vv.end());
return vv;
}
};

解题思路
先定义两个栈,用来存储从根节点到p和从根节点到q的路径,将他们的路径中的每一个节点存储到栈中。我们需要找的就是这两条路径中相同的那个节点。也就是我们需要先控制栈中的元素个数相同,然后再比较栈顶的元素是否相同,如果不相同则同时弹出两个栈中栈顶的元素,直到两个栈中栈顶的元素相同,此时栈顶的元素就是我们要找的公共祖先。
代码实现
class Solution {
public:
//定义两个栈,找到两个节点的路径,压入栈中
bool GetPath(TreeNode* root, TreeNode* x, stack<TreeNode*>& path)
{
//节点为空,直接返回false
if(root == nullptr)
return false;
//节点不为空
path.push(root);
if(root == x)
return true;
if(GetPath(root->left,x,path))
return true;
if(GetPath(root->right,x,path))
return true;
path.pop();
return false;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
stack<TreeNode*> pPath,qPath;
GetPath(root,p,pPath);
GetPath(root,q,qPath);
while(pPath.size() != qPath.size())
{
if(pPath.size() > qPath.size())
pPath.pop();
else
qPath.pop();
}
while(pPath.top() != qPath.top())
{
pPath.pop();
qPath.pop();
}
return pPath.top();
}
};

解题思路
当前节点的指针用cur表示,再定义一个prev指针,让prev来表示当前节点cur的前一个结点,这样通过不断递归的方式访问每一个节点之后就可以将二叉树转换成双向循环链表了。这里我们需要注意的是,prev一定要使用引用传参,因为每一层节点的prev都是上一次函数调用的cur。
代码实现
class Solution {
public:
void InOrderConvert(Node* cur, Node* &prev)
{
if(cur == nullptr)
return;
InOrderConvert(cur->left, prev);
cur->left = prev;
if(prev)
prev->right = cur;
prev = cur;
InOrderConvert(cur->right, prev);
}
Node* treeToDoublyList(Node* root) {
if(root == nullptr) return nullptr;
Node* prev = nullptr;
InOrderConvert(root, prev);
Node* cur = root;
while(cur && cur->left)
{
cur = cur->left;
}
Node* Rcur = root;
while(Rcur && Rcur->right)
{
Rcur = Rcur->right;
}
cur->left = Rcur;
Rcur->right = cur;
return cur;
}
};

解题思路
大思路很简单,但是这道题目写起来却不是很容易,通过前序我们可以找到根节点,中序分割出左右子树,如果区间还存在说明还有节点未构建完,如果区间不存在说明已经没有节点可以构建,直接返回空。
代码实现
class Solution {
public:
TreeNode* _buildTree(vector<int>& preorder, vector<int>& inorder, int& prei, int begin,int end)
{
if(begin > end)
return nullptr;
//创建根节点
TreeNode* newnode = new TreeNode(preorder[prei]);
//分割左右子区间
int rooti = begin;
while(rooti <= end)
{
if(inorder[rooti] == preorder[prei])
break;
else
rooti++;
}
prei++;
//递归创建左右子树
newnode->left = _buildTree(preorder, inorder, prei, begin, rooti - 1);
newnode->right = _buildTree(preorder, inorder, prei, rooti + 1, end);
return newnode;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int i = 0;
return _buildTree(preorder, inorder, i, 0, inorder.size() - 1);
}
};

解题思路
因为后续序列和前序序列有一点点不同,所以这里我们必须从后往前依次访问后序序列中的每一个元素,这样才能找出每一棵子树的根节点并从中序将左右子区间分割开。这里和前序不一样的是,这里我们需要先构建右子树,在构建左子树,最后将根节点和左右子树链接起来。
代码实现
class Solution {
public:
TreeNode* _buildTree(vector<int>& inorder, vector<int>& postorder, int &pos, int begin, int end)
{
if(begin > end)
return nullptr;
TreeNode* newnode = new TreeNode(postorder[pos]);
int rooti = begin;
while(rooti <= end)
{
if(postorder[pos] == inorder[rooti])
break;
else
rooti++;
}
pos--;
//分割左右子区间
newnode->right = _buildTree(inorder, postorder, pos, rooti + 1, end);
newnode->left = _buildTree(inorder, postorder, pos, begin, rooti - 1);
return newnode;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
int i = postorder.size() - 1;
return _buildTree(inorder, postorder, i, 0, postorder.size() - 1);
}
};

解题思路
前序遍历的顺序是根、左子树、右子树。因此最后我们遍历整棵树的时候,一定是先访问左路节点,然后访问左路节点的右子树,左路节点的右子树又可以看作一棵二叉树、然后继续二叉子树的前序遍历,最后直到遍历访问整棵二叉树。
我们需要定义一个栈st、一个vector v 和一个 TreeNode* cur,cur初始化为root。定义一个while循环,循环结束的条件是cur不为空,或者st不为空,首相我们先将左路节点依次插入栈中,同时也将左路节点插入到vector中,这时左路节点就已经访问完了,然后将栈顶元素保存下来并出栈,并将cur指向栈顶元素的右子树,做像上面一样的操作。这样就能保证每棵子树都能够按照根——左子树——右子树的顺序访问每一个节点,最后遍历整棵树就能达到预期的结果。
代码实现
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
TreeNode* cur = root;
vector<int> v;
stack<TreeNode*> st;
while(cur || !st.empty())
{
while(cur)
{
v.push_back(cur->val);
st.push(cur);
cur = cur->left;
}
//访问每个根节点的右子树
TreeNode* tmp = st.top();
st.pop();
cur = tmp->right;
}
return v;
}
};

解题思路
中序遍历的思路和前序遍历的思路也差不多,有一点不同的就是中序遍历的顺序是左子树——根——右子树,和前序遍历一样,先将根节点入栈,不同的是入栈的同时不能访问节点,等到左路节点全部入栈后,先将该节点保存,然后访问该节点并将该节点弹出栈,然后将cur指向该节点的右子树。然后while循环中重复和前序遍历一样的操作。
代码实现
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> v;
TreeNode* cur = root;
while(cur || !st.empty())
{
while(cur)
{
st.push(cur);
cur = cur->left;
}
TreeNode* tmp = st.top();
v.push_back(tmp->val);
st.pop();
cur = tmp->right;
}
return v;
}
};

解题思路
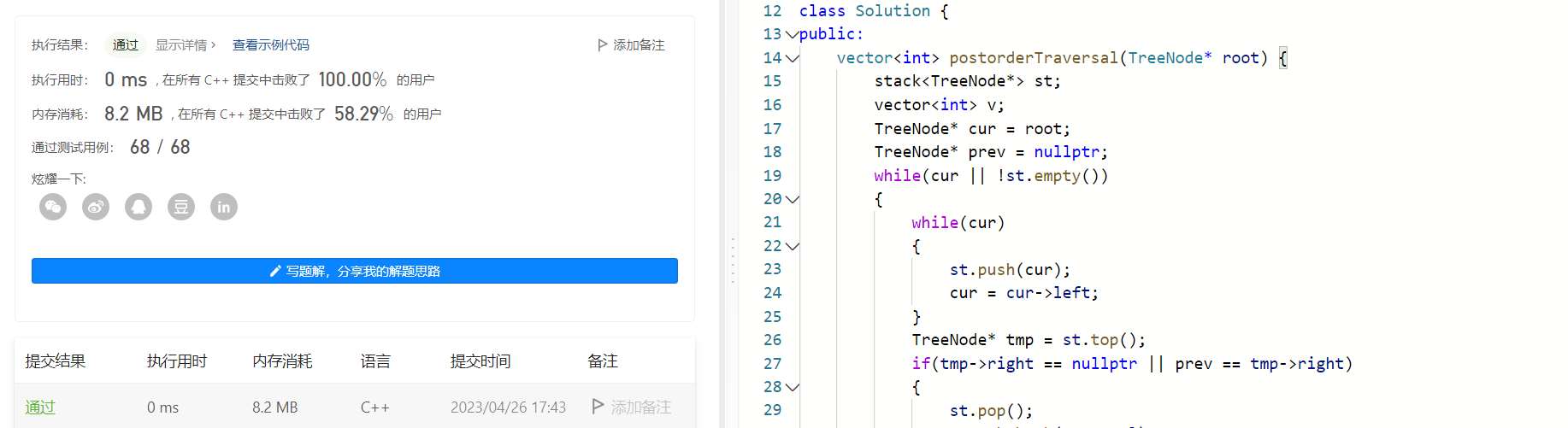
后序遍历的顺序是左子树——右子树——根,所以我们在访问根节点的时候必须保证左子树和右子树都已经被访问过了才行。同样,和上面的思路一样,我们同样是先将左路节点入栈并且不访问,当左路节点全部入栈后。取栈顶元素,这时我们需要先判断该节点是否有右子树,或者该节点的右子树是否被访问过。判断该节点的右子树是否被访问过的方法是:设置一个指针 prev 来记录前一个访问过的节点,因为只有右子树访问完才能访问根节点,所以我们只需要判断该节点的右子树是否是上一个访问过的节点就可以了。 同时,如果右子树为空也能直接访问该节点。
代码实现
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> v;
TreeNode* cur = root;
TreeNode* prev = nullptr;
while(cur || !st.empty())
{
while(cur)
{
st.push(cur);
cur = cur->left;
}
TreeNode* tmp = st.top();
if(tmp->right == nullptr || prev == tmp->right)
{
st.pop();
v.push_back(tmp->val);
prev = tmp;
}
else
{
cur = tmp->right;
}
}
return v;
}
};
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
我一直在尝试在Ruby中实现BinaryTree类,但我得到了stackleveltoodeep错误,尽管我似乎没有在该特定代码段中使用任何递归:1.classBinaryTree2.includeEnumerable3.4.attr_accessor:value5.6.definitialize(value=nil)7.@value=value8.@left=BinaryTree.new#stackleveltoodeephere9.@right=BinaryTree.new#andhere10.end11.12.defempty?13.(self.value==nil)?true:
我有一个表,'jobs'和一个枚举字段'status'。status具有以下枚举集:enumstatus:[:draft,:active,:archived]使用ransack,我如何过滤表,比如说,所有事件记录? 最佳答案 你可以像这样在模型中声明自己的掠夺者:ransacker:status,formatter:proc{|v|statuses[v]}do|parent|parent.table[:status]end然后您可以使用默认的搜索语法_eq来检查相等性,如下所示:Model.ransack(status_eq:'ac
我一直在使用postgres关注railscast的全文搜索,但我不断收到以下错误#的未定义局部变量或方法“作用域”我关注了railscast确切地。我安装了所有正确的gem。(pg_search,pg)。这是我的代码文章Controller(我在这里也使用acts_as_taggable)defindex@articles=Article.text_search(params[:query]).page(params[:page]).per_page(3)ifparams[:tag]@articles=Article.tagged_with(params[:tag])else@art









