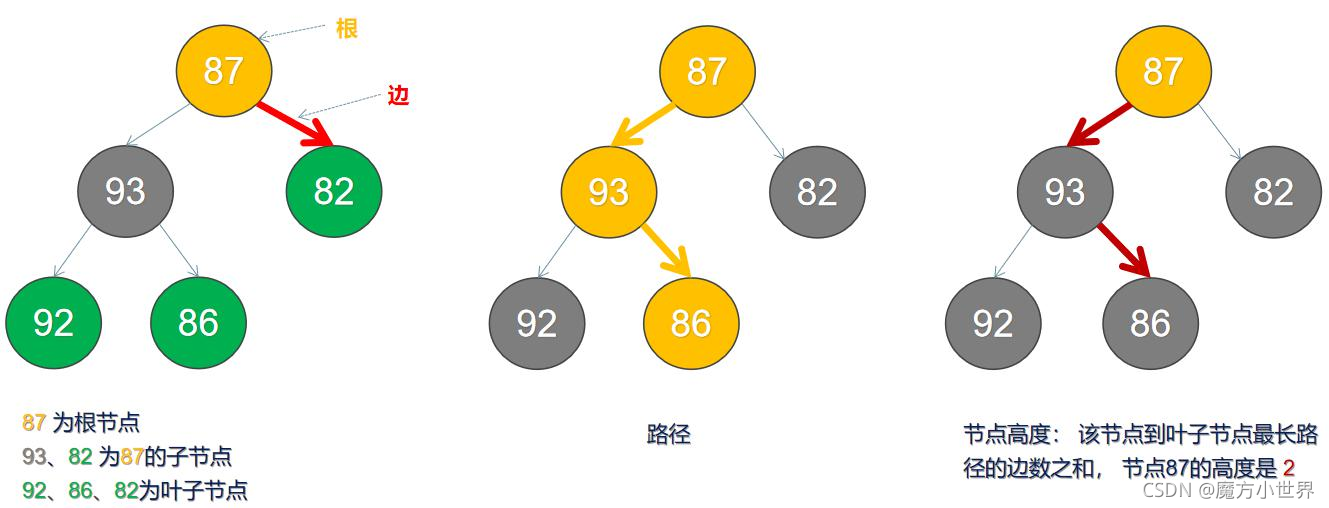
树状图是一种数据结构,它是由 n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
每个结点有零个或多个子结点;没有父结点的结点称为根结点;每一个非根结点有且只有一个父结点;除了根结点外,每个子结点可以分为多个不相交的子树;
| 专业术语 | 中 文 | 描 述 |
|
Root |
根节点 | 一棵树的顶点 |
| Child | 孩子节点 | 一个结点含有的子树的根结点称为该结点的子结点 |
| Leaf | 叶子节点 | 没有孩子的节点(度为0) |
| Degree | 度 | 一个节点包含的子树的数量 |
| Edge | 边 | 一个节点与另外一个节点的连接 |
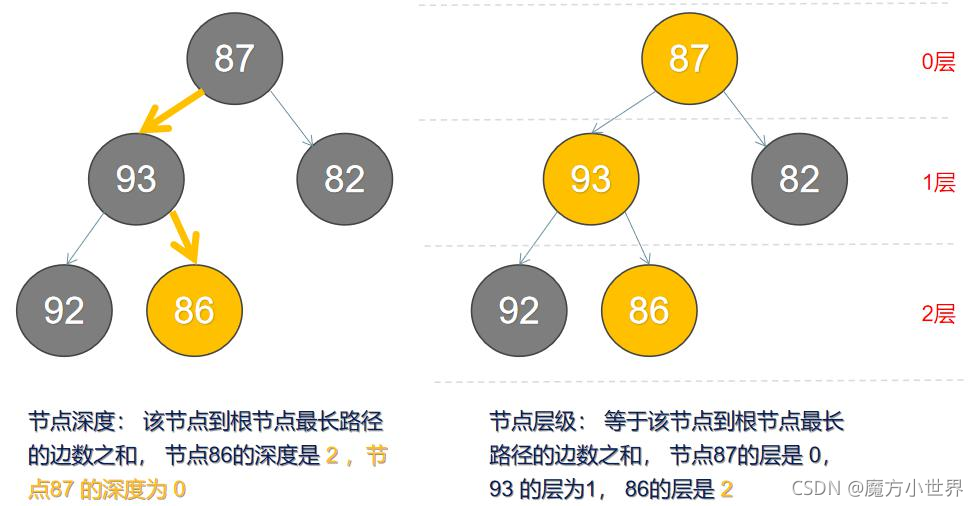
| Depth | 深度 | 根节点到这个节点经过的边的数量 |
| Height | 节点高度 | 从当前节点到叶子节点形成路径中边的数量 |
| Level | 层级 | 节点到根节点最长路径的边的总和 |
| Path | 路径 |
一个节点和另一个节点之间经过的边和 Node 的序列 |
二叉树是n(n≥0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根结点和两个互不相交的、分别称为根结点左子树和右子树的二叉树组成。
二叉树是一个每个结点最多只能有两个分支的树,左边的分支称之为左子树,右边的分支称之为右子树。
(1)在风控二叉树,第i-1层的结点总数不超过,i>=1; (2)深度为h-1的二叉树最多有-1个结点(h>=1),最少有h个结点 (3)对于任意一棵二叉树,如果叶节点为N0,而度数为2 的结点总数为N2,则N0=N2+1;
每个度为1的结点有1条边,度为2的结点有两条边。所以总边数为1*n1+2*n2,总边数等于结点数减1,即 N-1 = 1*n1+2*n2。其中总结点数又等于度为1、度为2、度为0的结点数和,即 N = n1 + n2 + n0;联立可得N0=N2+1。
1.每个结点最多有两个子树,所以二叉树中不存在度大于2的结点。 2.左子树和右子树是有顺序的,次序不能颠倒。即使树中只有一颗子树,也要区分是左子树还是右子树。
1.空二叉树。 2.只有一个根结点。 3.根结点只有左子树。 4.根结点只有右子树。 5.根结点既有左子树,又有右子树。
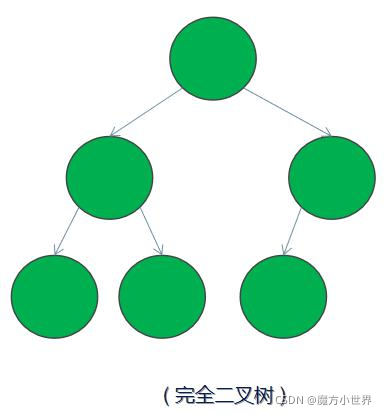
1)完全二叉树 ——若设二叉树的高度为 h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层有叶子节点,并且叶子结点都是从左到右依次排布,这就是完全二叉树(堆就是完全二叉树)。
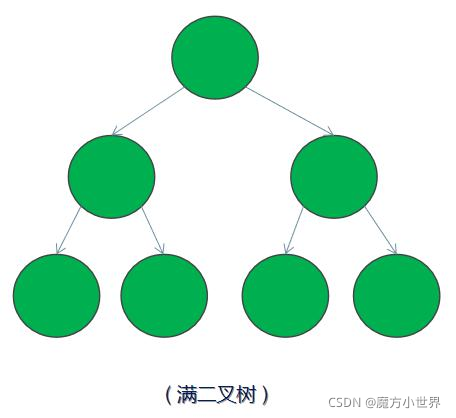
2)满二叉树 ——除了叶结点外每一个结点都有左右子节点且叶子结点都处在最底层的二叉树。
3)平衡二叉树 ——又被称为 AVL 树,它是一颗空树或左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
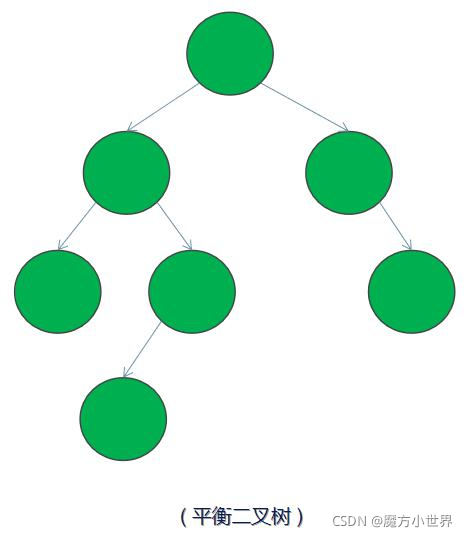
4)二叉搜索树 ——又称二叉查找树、二叉排序树(Binary Sort Tree)。它是一颗空树或是满足下列性质的二叉树:(右边>=根>=左边) 1)若左子树不空,则左子树上所有节点的值均小于或等于它的根节点的值; 2)若右子树不空,则右子树上所有节点的值均大于或等于它的根节点的值; 3)左、右子树也分别为二叉排序树。

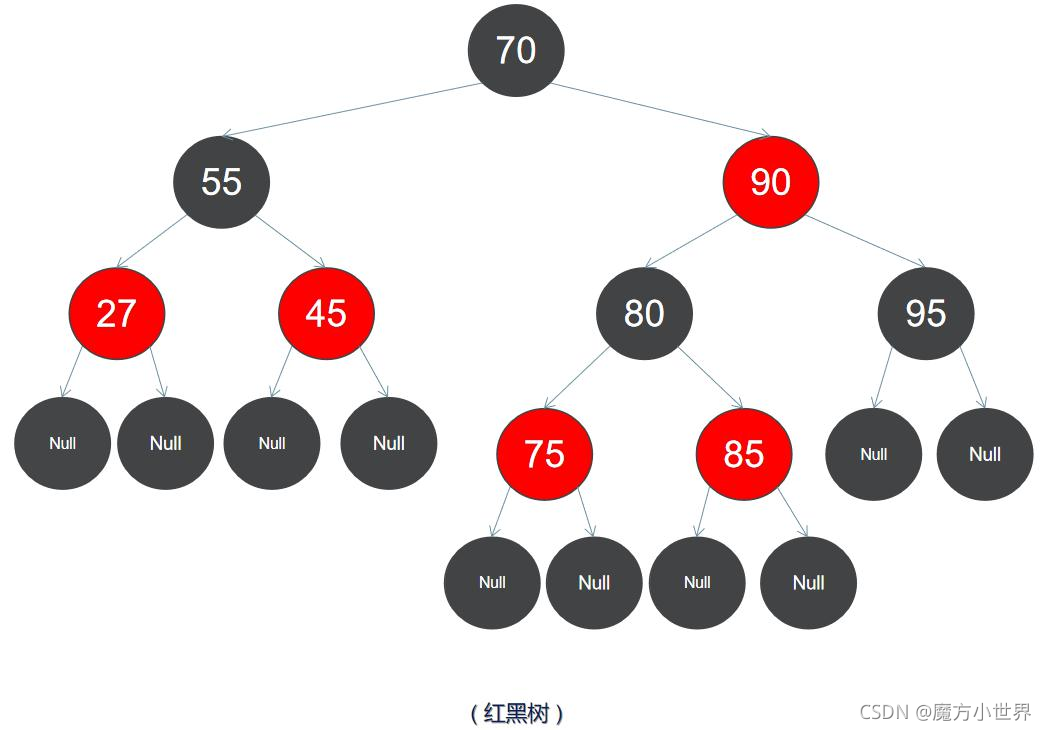
5)红黑树 ——是每个节点都带有颜色属性(颜色为红色或黑色)的自平衡二叉查找树,满足下列性质: 1)节点是红色或黑色; 2)根节点是黑色; 3)所有叶子节点都是黑色; 4)每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个 连续为红色的结点); 5)从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。 (没有度为 1的结点)。 以上规则可以保证左右子树结点数差距不超过两倍~
1.在二叉树的第i层上最多有2i-1个结点(i≥1)。 2.深度为k的二叉树最多有2k-1个结点(k≥1)。 3.对于任何一个二叉树,如果其叶子结点数为n0,度数为2的结点数为n2,那么n0=n2+1,也就是叶子结点数为度为2的结点数加1。 4.具有n个结点的完全二叉树深度为(log2n)+1。 5.对具有n个结点的完全二叉树,如果按照从上至下和从左至右的顺序对二叉树的所有结点从1开始编号,则对于任意的序号为i的结点有: A. 如果i>1,那么序号为i的结点的双亲结点序号为i/2; B. 如果i=1,那么序号为i的结点为根节点,无双亲结点; C. 如果2i<=n,那么序号为i的结点的左孩子结点序号为2i; D. 如果2i>n,那么序号为i的结点无左孩子; E. 如果2i+1<=n,那么序号为i的结点右孩子序号为2i+1; F. 如果2i+1>n,那么序号为i的结点无右孩子。
比如有以下数据:

当我们想保证查找效率时,可以用顺序表存储,当我们想保证插入和删除效率时,我们可以用链式表存储,有没有一种存储方法可以同时兼顾顺序表和链式表的优点?
使用二叉树,便可兼顾查找效率和插入删除效率~
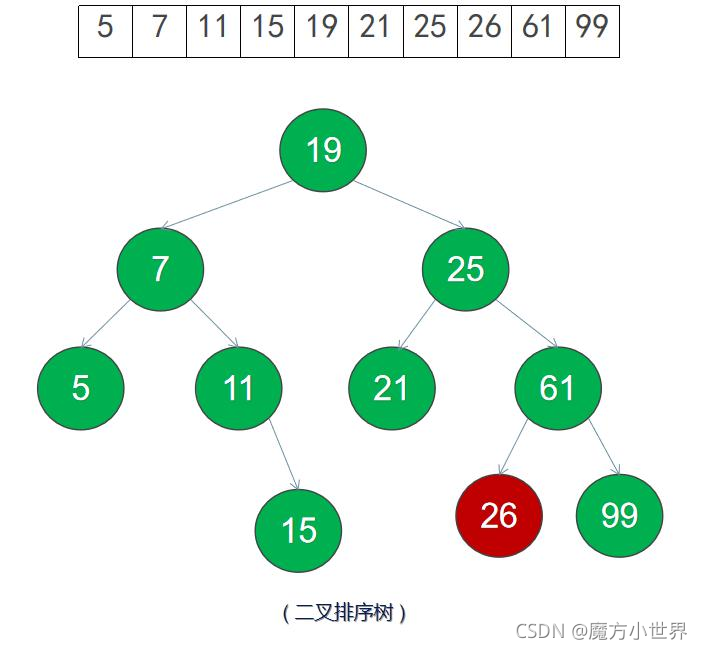
二叉树一般采用链式存储方式:每个结点包含两个指针域,指向两个孩子结点,还包含一个数据域,存储结点信息。

结点结构体定义:
1 typedef struct _BNode {
2 int data;
3 struct _BNode *lchild, *rchild;
4 }Bnode,*Btree; 1
2 //二叉树插入结点
3 /*将插入结点e,与结点root结点进行比较,若小于则去到左子树,否则
4 去右子树进行比较,重复以上操作直到找到一个空位置放置该结点
5 */
6 bool InsertBtree(Btree* root, Bnode* node) {
7 Bnode* temp = NULL;
8 Bnode* parent = NULL;
9 if (!node) { //如果插入结点为空,返回false
10 return false;
11 }else { //清空插入结点的左右子树
12 node->lchild = NULL;
13 node->rchild = NULL;
14 }
15
16 if (!(*root)) { //如果根节点不存在,将插入结点作为根节点
17 *root = node;
18 return true;
19 }else {
20 temp = *root;
21 }
22
23 while (temp != NULL) {
24 parent = temp;
25 if (temp->data>node->data) { //小于,继续向左
26 temp = temp->lchild;
27 }
28 else { //大于,继续向右(不可以有相同的值)
29 temp=temp->rchild;
30 }
31 //while循环结束,parent所处位置即为要插入结点的父结点
32 }
33 if (node->data < parent->data) {
34 parent->lchild = node;
35 }
36 else {
37 parent->rchild = node;
38 }
39 return true;
40 }将要删除的节点的值,与节点 root 节点进行比较,若小于则去到左子树进行比较,若大于则去到右子树进行比较,重复以上操作直到找到一个节点的值等于删除的值,则将此节点删除。删除时有 4 中情况须分别处理:
1.删除节点不存在左右子节点,即为叶子节点,直接删除
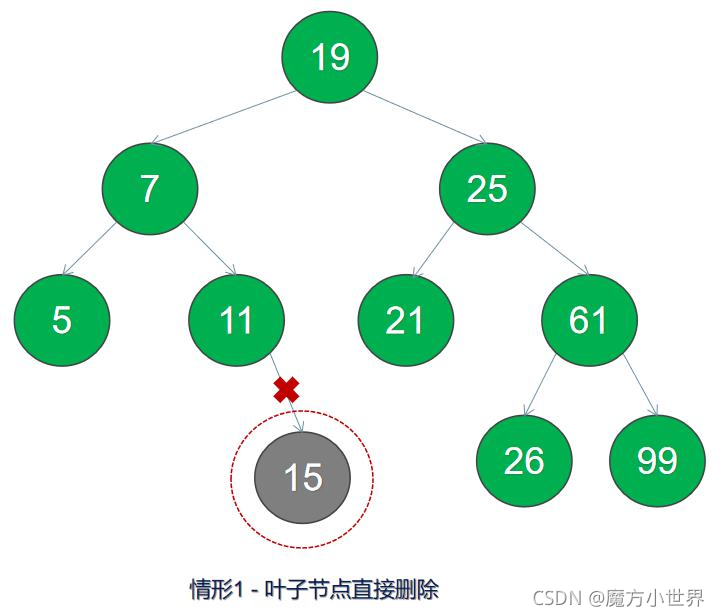
2.删除节点存在左子节点,不存在右子节点,直接把左子节点替代删除节点
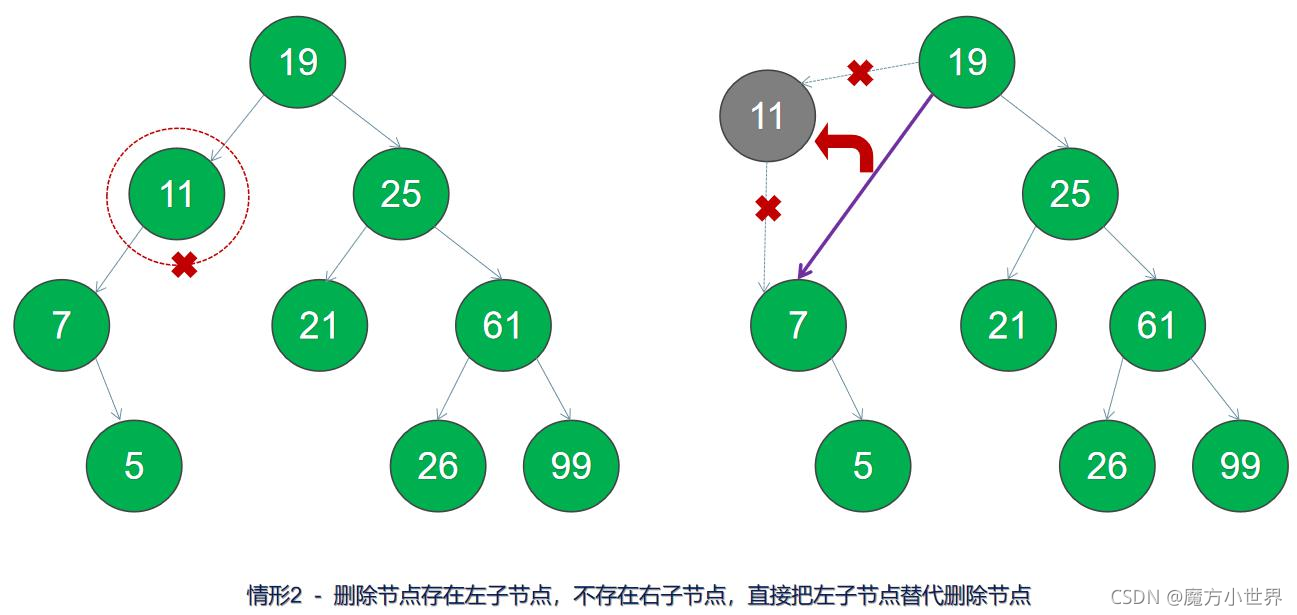
3.删除节点存在右子节点,不存在左子节点,直接把右子节点替代删除节点
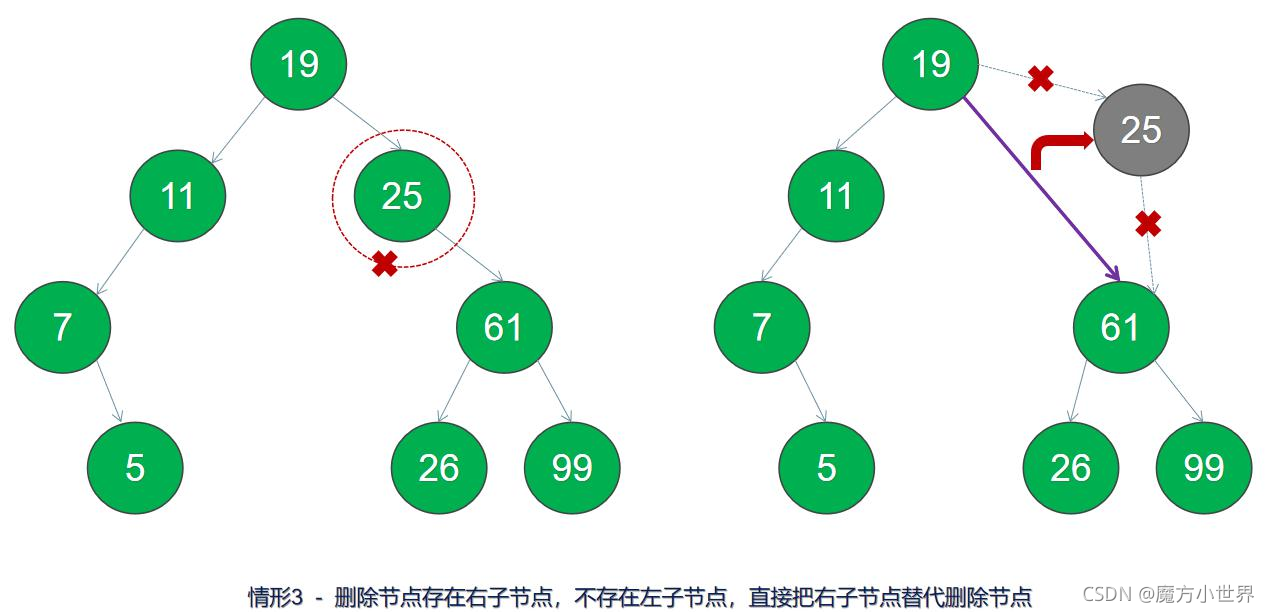
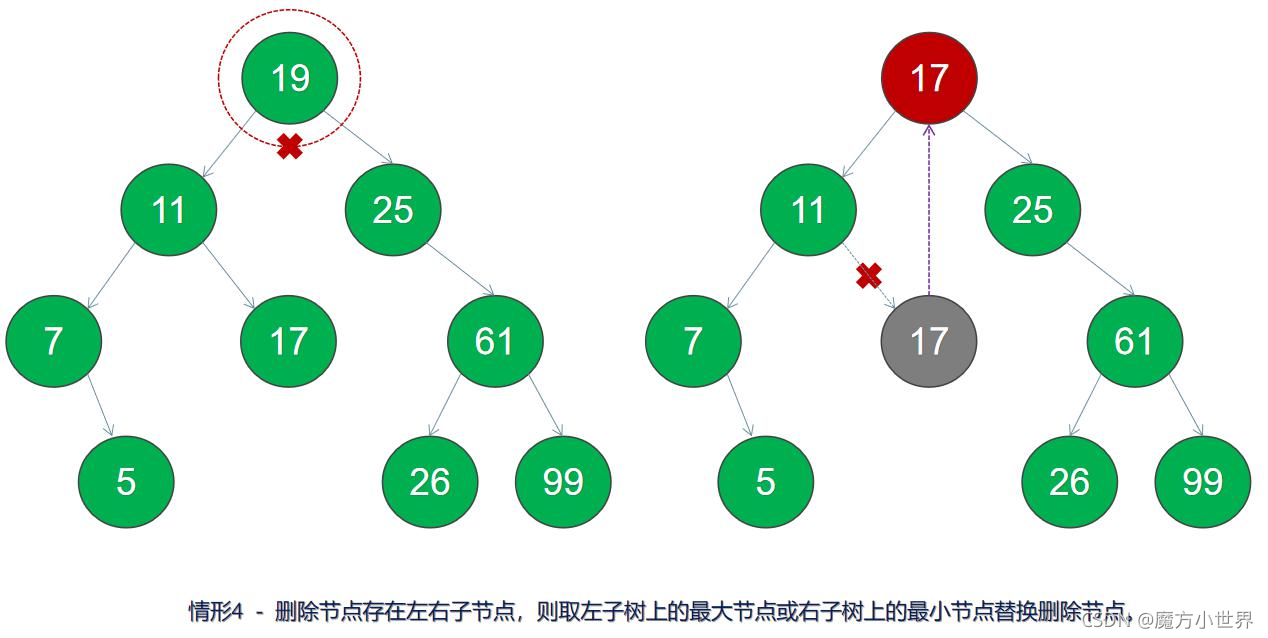
4.删除节点存在左右子节点,则取左子树上的最大节点或右子树上的最小节点替换删除节点。
代码实现:
1 //查找左子树最大值
2 int findLeftMax(Btree* root) {
3 /*采用递归方式查找
4 * if (root->rchild == NULL)
5 return root->data;
6 return findMax(root->rchild);
7 */
8 //采用循环查找
9 Btree indexNode = *root;
10 while (indexNode->rchild)
11 indexNode = indexNode->rchild;
12 return indexNode->data;
13 }
14
15
16 //采用递归的方式删除结点
17 /*
18 这种递归方式,是将要修改的结点的一层一层的返回
19 */
20 Btree deleteNode(Btree* root, int value) {
21 Btree compareNode = *root;
22 //节点为空(递归找不到value/根节点为空),直接返回
23 if (!compareNode)return compareNode;
24 //大于
25 if (compareNode->data > value) {
26 //左子树重新被赋值
27 compareNode->lchild = deleteNode(&(compareNode->lchild), value);
28 return compareNode;
29 }
30 //小于
31 else if (compareNode->data < value) {
32 //右子树重新被赋值
33 compareNode->rchild = deleteNode(&(compareNode->rchild), value);
34 return compareNode;
35 }
36 else {//等于
37 Btree temp = NULL;
38 //无左右子节点,直接返回NULL
39 if (compareNode->lchild == NULL && compareNode->rchild == NULL) {
40 delete compareNode;
41 }
42 //有左子树,返回左子树
43 else if (compareNode->lchild && compareNode->rchild == NULL) {
44 temp = compareNode->lchild;
45 delete compareNode;
46 }
47 //有右子树,返回右子树
48 else if (compareNode->rchild && compareNode->lchild == NULL) {
49 temp = compareNode->rchild;
50 delete compareNode;
51 }
52 else {
53 //这里采用左子树最大值替换
54 int leftMax = findLeftMax(&(compareNode->lchild));
55 //最大值替换删除结点的值
56 compareNode->data = leftMax;
57 //将最大值从树中删除
58 compareNode->lchild = deleteNode(&(compareNode->lchild), leftMax);
59 temp= compareNode;
60 }
61 return temp;
62 }
63 } 1 // 采用递归方式查找结点
2 /*
3 Bnode* queryByRec(Btree root, int value) {
4 if (root == NULL || root->data==value ){
5 return root;
6 }
7 else if (root->data < value) {
8 return queryByRec(root->lchild, value);
9 }
10 else {
11 return queryByRec(root->rchild, value);
12 }
13 }*/
14
15 // 使用非递归方式查找结点
16
17 Bnode* queryByLoop(Btree root, int value) {
18 while (root != NULL && root->data!=value) {
19 if (root->data>value) {
20 root = root->lchild;
21 }
22 else {
23 root = root->rchild;
24 }
25 }
26 return root;
27 }前序遍历,简单来说就是遍历根-左孩子-右孩子
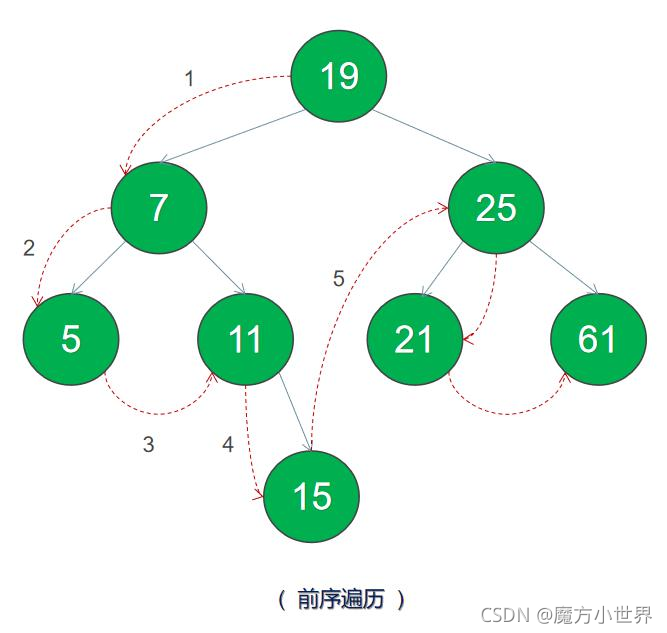
如上图,前序遍历的结果为 19 7 5 11 15 25 21 61
1 void PreOrderRec(int x)//x为根节点
2 {
3 if (x == 0)return;//若遍历完成,返回函数
4 cout<<x;
5 PreOrderRec(a[x].left);//遍历左孩子
6 PreOrderRec(a[x].right);//遍历右孩子
7 }中序遍历,相当于遍历左-根-右
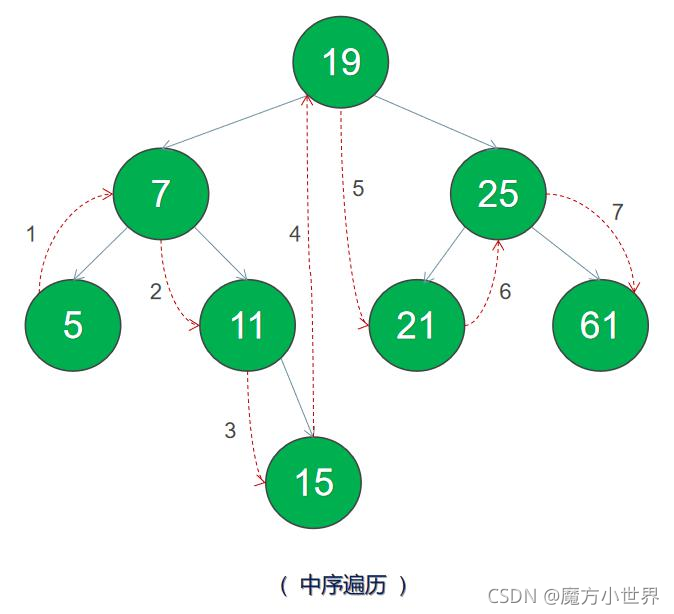
还是这个图,但中序遍历的结果为 5 7 11 15 19 21 25 61
1 void PreOrderRec(int x)//x为根节点
2 {
3 if (x == 0)return;//若遍历完成,返回函数
4 PreOrderRec(a[x].left);//遍历左孩子
5 cout<<x;
6 PreOrderRec(a[x].right);//遍历右孩子
7 }甚至代码都不需要改,只需改变遍历的顺序
后序遍历,也就是左-右-根
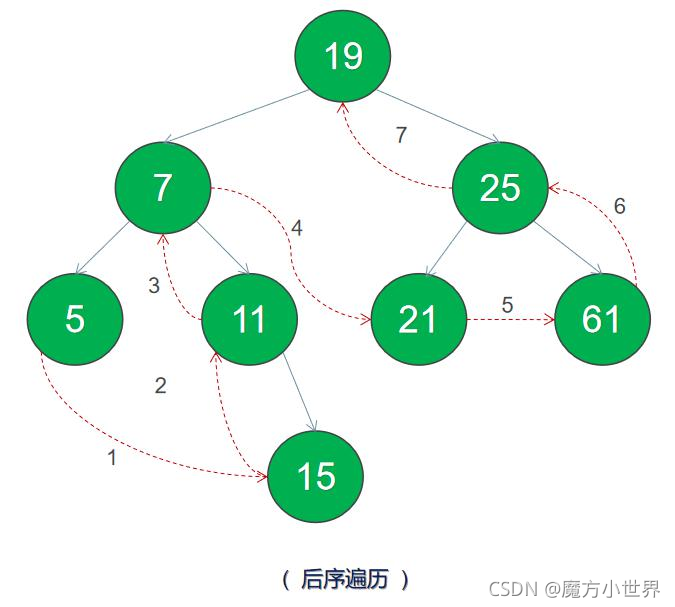
后序遍历结果为 5 15 11 7 21 61 25 19
同样,代码也不需要改变
1 void PreOrderRec(int x)//x为根节点
2 {
3 if (x == 0)return;//若遍历完成,返回函数
4 PreOrderRec(a[x].left);//遍历左孩子
5 PreOrderRec(a[x].right);//遍历右孩子
6 cout<<x;
7 }以上就是二叉树的常用操作啦,至于增加、删除节点,就类似于链表的操作,由于本蒟蒻对链表简直就算是白痴,此处就不再详解了.另外,此文摘抄了
https: //blog.csdn.net/qq_54169998/article/details/121108627?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166071783716782390559337%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166071783716782390559337&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~hot_rank-6-121108627-null-null.142^v41^pc_rank_34_1,185^v2^control&utm_term=C%2B%2B%E4%BA%8C%E5%8F%89%E6%A0%91%E8%AF%A6%E8%A7%A3&spm=1018.2226.3001.4187
一些知识点,大家有兴趣可以去看看原博客
我正在学习Ruby,遇到了inject。我正处于理解它的风口浪尖,但当我是那种需要真实世界的例子来学习一些东西的人时。我遇到的最常见的例子是人们使用inject来添加一个(1..10)范围的总和,我不太关心这个。这是一个任意的例子。在实际程序中我会用它做什么?我正在学习,所以我可以继续使用Rails,但我不必有一个以Web为中心的示例。我只需要一些我可以全神贯注的目标。谢谢大家。 最佳答案 inject有时可以通过它的“其他”名称reduce更好地理解。它是一个对Enumerable进行操作(迭代一次)并返回单个值的函数。它有许多有
我在尝试使用Faraday将文件上传到网络服务时遇到问题。我的代码:conn=Faraday.new('http://myapi')do|f|f.request:multipartendpayload={:file=>Faraday::UploadIO.new('...','image/jpeg')}conn.post('/',payload)尝试发布后似乎没有任何反应。当我检查响应时this是我所看到的:#:post,:body=>#,#,@opts={}>,#],@index=0>>,#>],@ios=[#,#,@opts={}>,#],@index=0>,#],@index=0>
我使用raise(ConfigurationError.new(msg))引发错误我试着用rspec测试一下:expect{Base.configuration.username}.toraise_error(ConfigurationError,message)但这行不通。我该如何测试呢?目标是匹配message。 最佳答案 您可以使用正则表达式匹配错误消息:it{expect{Foo.bar}.toraise_error(NoMethodError,/private/)}这将检查NoMethodError是否由privateme
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
我找不到任何使用Rack::Session::Cookie的简单示例,并且希望能够将信息存储在cookie中,并在以后的请求中访问它并让它过期.这些是我能找到的唯一示例:HowdoIset/getsessionvarsinaRackapp?http://rack.rubyforge.org/doc/classes/Rack/Session/Cookie.html这是我得到的:useRack::Session::Cookie,:key=>'rack.session',:domain=>'foo.com',:path=>'/',:expire_after=>2592000,:secret=
我是Ruby的新手,发现以下几对令人困惑示例同样有效:File.included_modulesFile::included_modulesFile.stat('mbox')#Returnsa'#'objectFile::stat('mbox')File.new("foo.txt","w")File::new("foo.txt","w")"asdf".size#Aninstancemethod"asdf"::size2+32::send(:+,3)#AnextremeexampleFile::new,尤其是我经常遇到的东西。我的问题:如果我永远避免使用::运算符来限定除类、模块和常量之
如果数组只包含一个值,我想返回数组的第一个元素。目前,我使用:vals.one??vals.first:vals.presence因此:vals=[];vals.one??vals.first:vals.presence#=>nilvals=[2];vals.one??vals.first:vals.presence#=>2vals=[2,'Z'];vals.one??vals.first:vals.presence#=>[2,"Z"]是否有内置的东西可以做到这一点,或者是否有更好的设计考虑?我的用例是特定的,涉及知道从方法(将实现上述代码)中期望什么的演示者。如果这些演示者将所有返回
在SOquestion2068165一个答案提出了使用这样的东西的想法:params[:task][:completed_at]&&=Time.parse(params[:task][:completed_at])作为DRYer的说法params[:task][:completed_at]=Time.parse(params[:task][:completed_at])ifparams[:task][:completed_at]paramsHash将来自(Rails/ActionView)表单。这是众所周知的||=习语的一种推论,如果LHS不是nil/false则设置值。像这样使用&&
我在OSX10.9.1中启动终端时反复出现问题。每次启动终端时,我都会重复以下至少30次Unknownoption:1Usage:head[-options]...-musemethodfortherequest(defaultis'HEAD')-fmakerequestevenifheadbelievesmethodisillegal-bUsethespecifiedURLasbase-tSettimeoutvalue-iSettheIf-Modified-Sinceheaderontherequest-cusethiscontent-typeforPOST,PUT,CHECKIN-
我经常编写代码以在遇到nil/空值时提供默认值。例如:category=order.category||"Any"#ORcategory=order.category.empty??"Any":order.category我即将扩展try方法来处理这个习语。category=order.try(:category,:on_nill=>"Any")#ORcategory=order.try(:category,:on_empty=>"Any")我想知道Rails/Ruby是否有一些方法来处理这个习惯用法?注意:我正在尝试消除||的重复/或/?基于运算符的习语。本质上,我正在寻找与try方