微信小程序端引入富文本样式
富文本提交图片json error
可以设置文字大小,居中,可以插入图片,设置图片大小,居中。
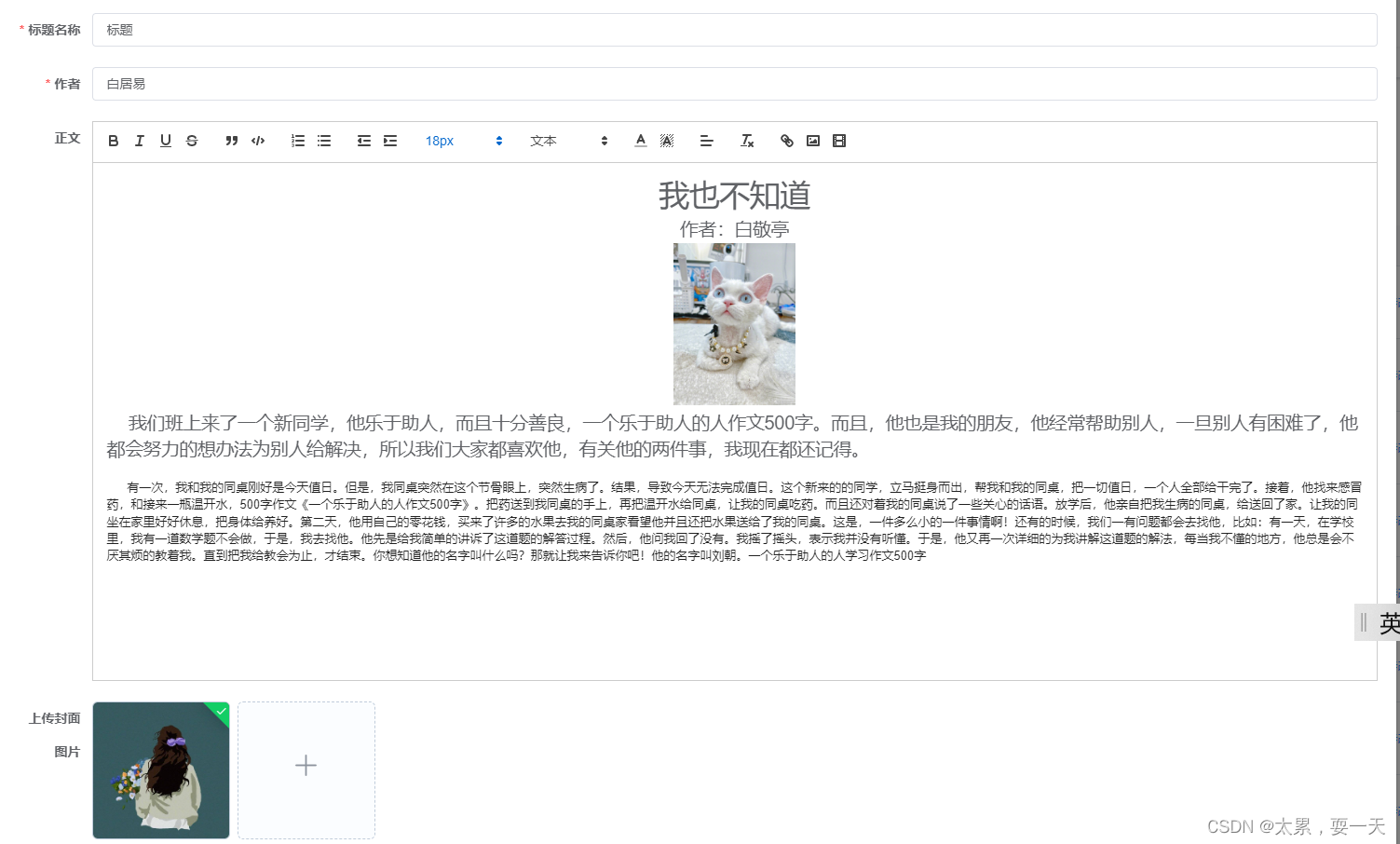

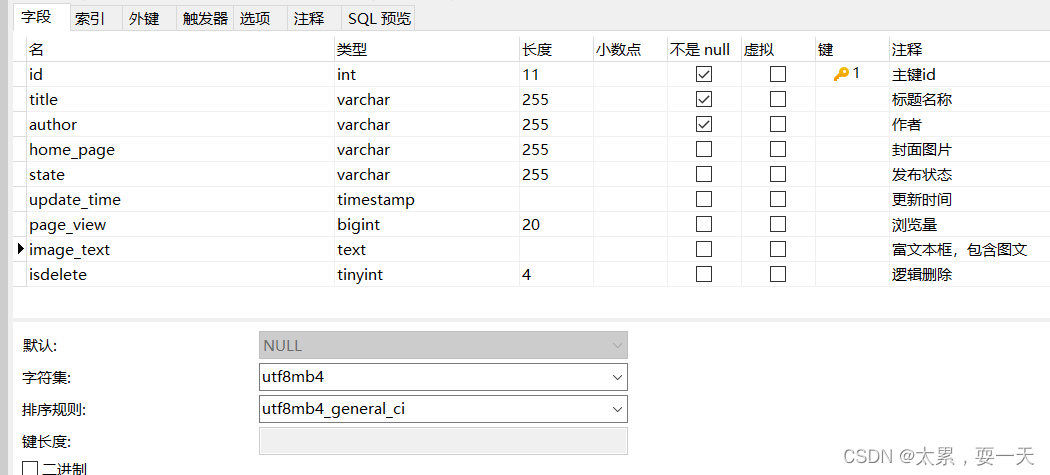
在定义的富文本框字段【显示类型】需要选择【富文本控件】
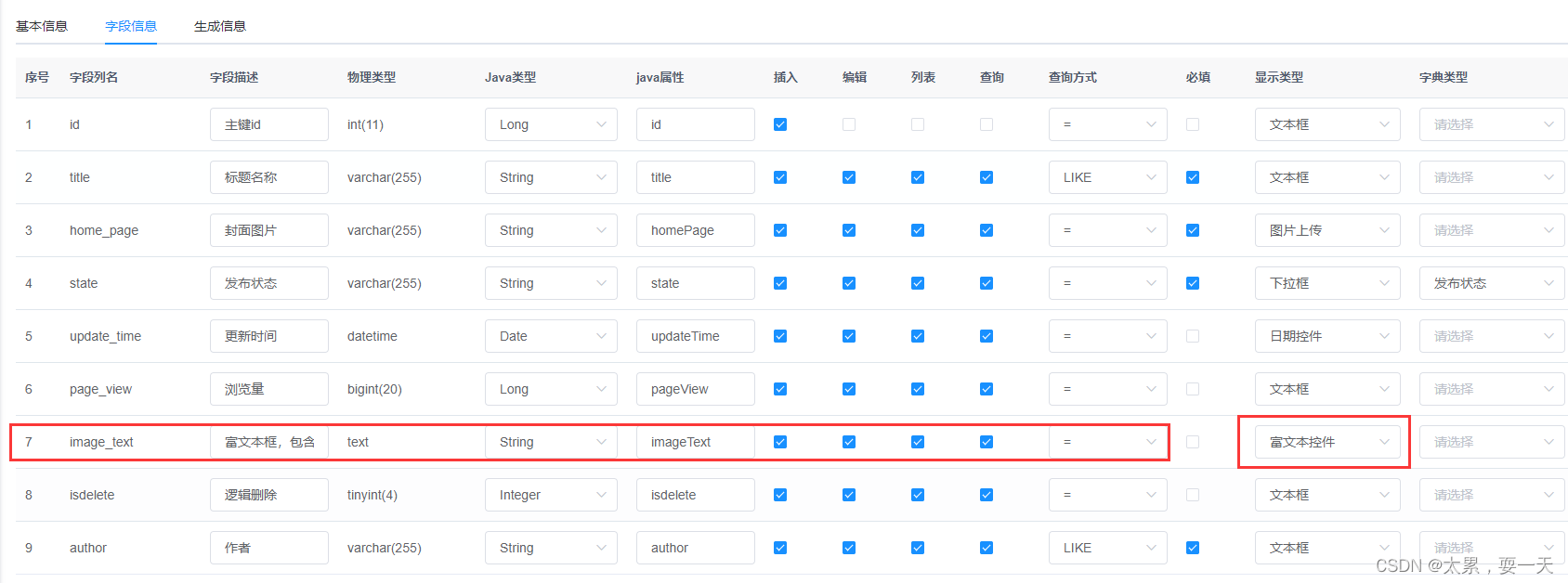
**遇到问题:**生成代码后会在添加列表的弹框中出现富文本框,但是在富文本中上传图片的时候会显示json错误,无法上传图片包括富文本下面上传封面图片的时候也会出现无法上传图片的情况。
解决方法:
在application.yml文件中把不做仿xss攻击的路径加上
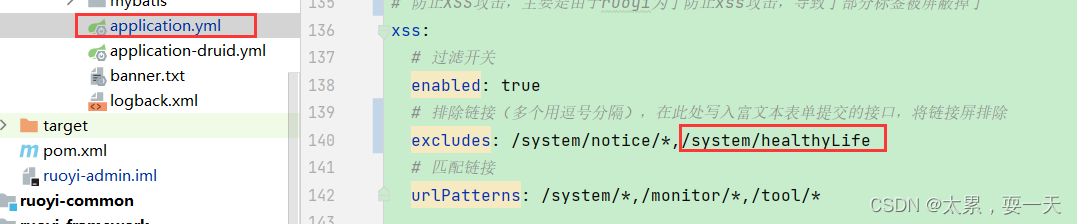 来源:
来源:
富文本提交图片json error
遇到问题:
富文本下面上传封面图片的时候会出现无法上传图片的情况,图片闪一下就消失了。
解决办法:
把此文件中的这一段注释掉即可。
**遇到问题:**富文本框中的图片插入后过大,没办法改变大小
**解决办法:**通过阅读博客【若依(ruoyi)前后端分离 quill-editor 实现图片上传拖拽修改图片大小】解决
若依(ruoyi)前后端分离 quill-editor 实现图片上传拖拽修改图片大小
具体解决方法:
步骤1:在vue.config.js 文件中添加 一下内容
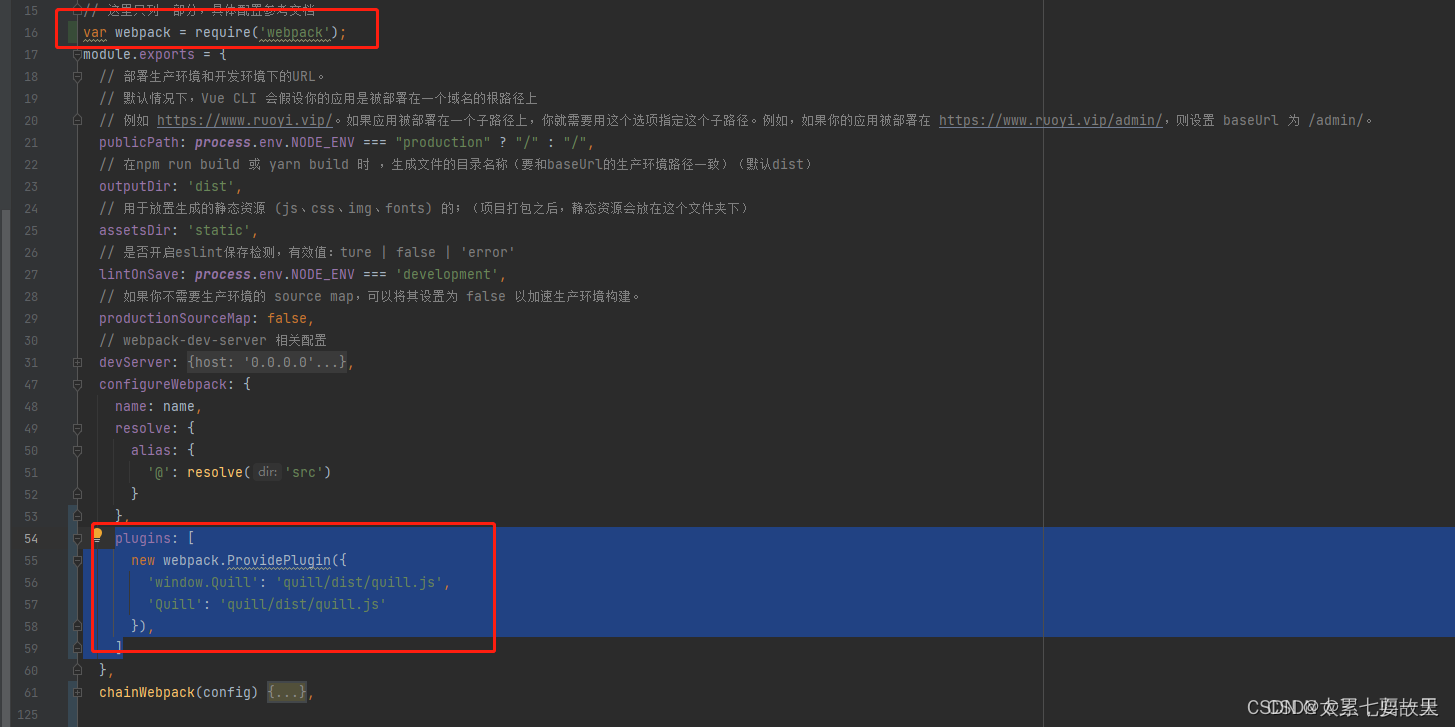
var webpack = require('webpack');
plugins: [ new webpack.ProvidePlugin({ 'window.Quill': 'quill/dist/quill.js', 'Quill': 'quill/dist/quill.js' }), ]
步骤2:
在terminal终端命令行输入:
npm install quill-image-drop-module --save
npm i quill-image-resize-module --save
npm install quill-image-extend-module --save
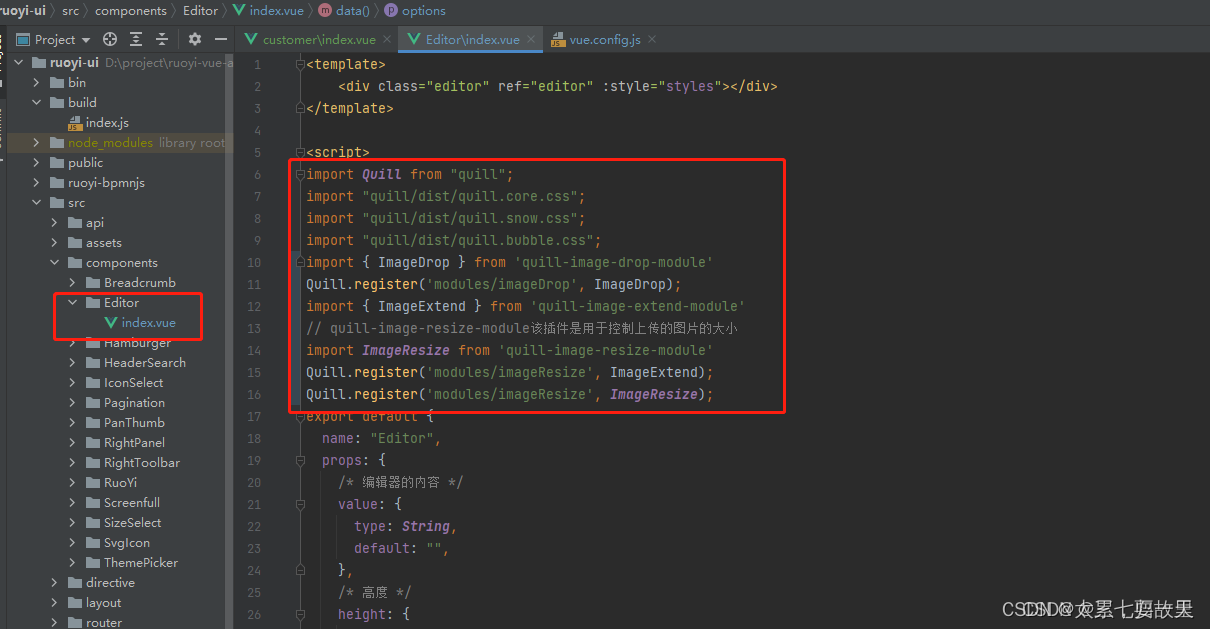
步骤3:在一下内容按照图片位置放在指定位置
import { ImageDrop } from 'quill-image-drop-module'
Quill.register('modules/imageDrop', ImageDrop);
import { ImageExtend } from 'quill-image-extend-module'
// quill-image-resize-module该插件是用于控制上传的图片的大小
import ImageResize from 'quill-image-resize-module'
Quill.register('modules/imageResize', ImageExtend);
Quill.register('modules/imageResize', ImageResize);
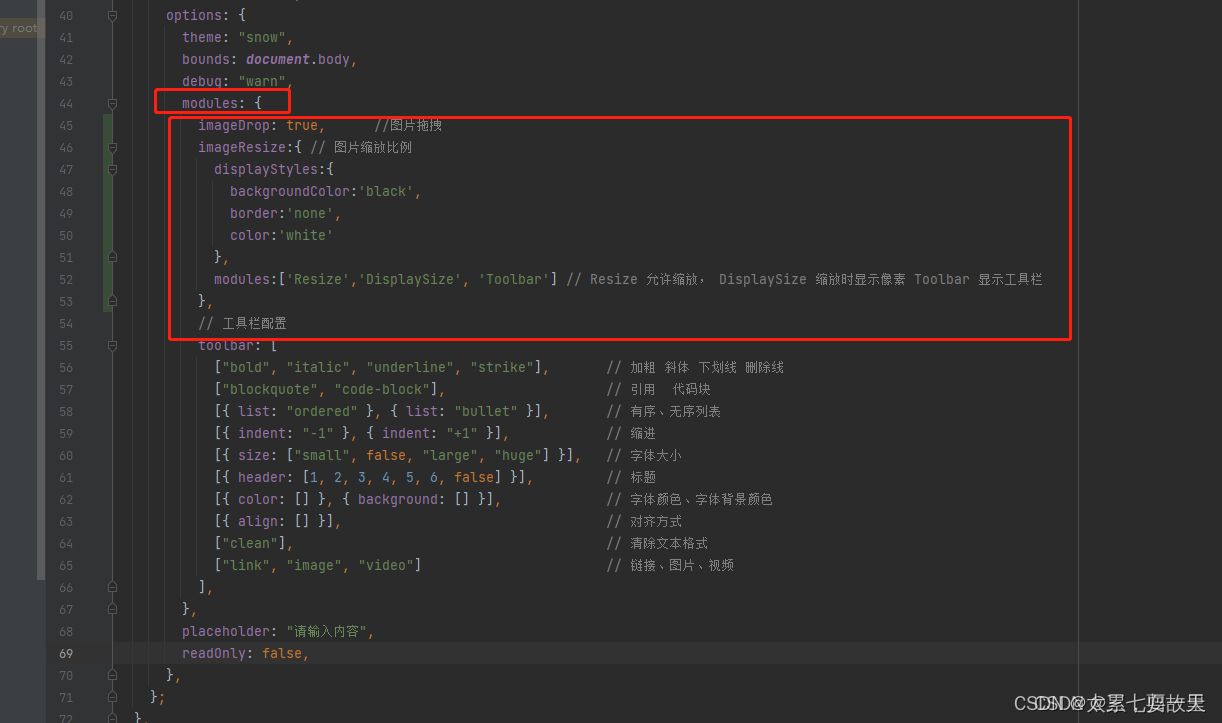
imageDrop: true, //图片拖拽
imageResize:{ // 图片缩放比例
displayStyles:{
backgroundColor:'black',
border:'none',
color:'white'
},
modules:['Resize','DisplaySize', 'Toolbar'] // Resize 允许缩放, DisplaySize 缩放时显示像素 Toolbar 显示工具栏
},
 以上亲测可用。
以上亲测可用。
4.1首先用.js文件从后端获取数据
export function listHealthyLife(query) {
return request({
url: '/system/healthyLife/list',
method: 'get',
params: query
})
}
4.2新建页面,不要忘记在page.json中注册
新建列表页面:
<template>
<view class="page">
<view class="box_1">
<view class="list_1">
<view class="list-items_1-0" v-for="(item, key) in listHealthyLife" :key="key" @click="showDetails(item.imageText)">
<view class="group_6-0">
<image class="image_2-0" :src="item.homePage" mode="aspectFill"></image>
<!-- <img src="D:\ruoyi\uploadPath\upload\2022\06\21\11.jpg" class="image_2-0"></img> -->
<view class="text-wrapper_3-0">
<text lines="1" class="text_4-0">{{item.title}}</text>
<text lines="1" class="text_5-0">{{item.updateTime}}</text>
</view>
</view>
</view>
<uni-pagination style="margin-top: 50rpx;" v-show="total>0" :total="total" :current="current" :pageSize="pageSize" @change="handlePage">
</uni-pagination>
</view>
</view>
</view>
</template>
<script>
import {listHealthyLife} from "@/api/system/healthyLife.js"
export default {
data() {
return {
constants: {},
listHealthyLife: [],
// 分页参数
total: 0,
current: 1,
pageSize: 7,
};
},
created() {
this.getList();
},
methods: {
getList() {
listHealthyLife({pageNum: this.current, pageSize: this.pageSize}).then(response => {
this.listHealthyLife = response.rows;
this.total = response.total;
console.log(this.total)
});
},
// 触发跳转
showDetails(index) {
uni.navigateTo({
url: '/pages/jiankangshenghuo/details?detail='+encodeURIComponent(JSON.stringify(index))
});
// 分页点击事件
handlePage(params) {
console.log(params) //可以打印看看params
this.current = params.current;
this.getList() // 点击的时候去请求查询列表
},
}
};
</script>
新建详情页面:
<template>
<view class="page">
<view class="friendsCircle-content">
<rich-text :nodes="article" class="ql-editor"></rich-text>
</view>
</view>
</template>
<script>
import '@/components/quillCSS/quill.bubble.css'
import '@/components/quillCSS/quill.core.css'
import '@/components/quillCSS/quill.snow.css'
export default {
components: {
uParse //注册组件
},
data() {
return {
article:'',
};
},
onLoad: function (option) { //option为object类型,会序列化上个页面传递的参数
this.article=JSON.parse(decodeURIComponent(option.detail));
console.log(this.article)
},
methods:{
}
}
</script>
**遇到问题:**但是此时,会有的富文本样式显示不出来的情况,所以需要再修改一下
解决办法:
步骤1:
在ruoyi-ui中找到quill源文件,在dist目录下可以看到
quill.bubble.css
quill.core.css
quill.snow.css
以上三个文件,把这三个文件复制到一个文件夹中,打开这三个文件把所有带*号的部分都删除
步骤2:
在微信小程序详情页面应用这三个文件
/*Vue-Quill-Editor样式*/
@import 'mdui/quill.bubble.css';
@import 'mdui/quill.core.css';
@import 'mdui/quill.snow.css';
步骤3:
在小程序富文本中加入 class=“ql-editor”,如下:
<rich-text :nodes="article" class="ql-editor"></rich-text>
再次运行即可。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我正在使用Postgres.app在OSX(10.8.3)上。我已经修改了我的PATH,以便应用程序的bin文件夹位于所有其他文件夹之前。Rammy:~phrogz$whichpg_config/Applications/Postgres.app/Contents/MacOS/bin/pg_config我已经安装了rvm并且可以毫无错误地安装pggem,但是当我需要它时我得到一个错误:Rammy:~phrogz$gem-v1.8.25Rammy:~phrogz$geminstallpgFetching:pg-0.15.1.gem(100%)Buildingnativeextension
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我有这个代码:context"Visitingtheusers#indexpage."dobefore(:each){visitusers_path}subject{page}pending('iii'){shouldhave_no_css('table#users')}pending{shouldhavecontent('Youhavereachedthispageduetoapermissionic错误')}它会导致几个待处理,例如ManagingUsersGivenapractitionerloggedin.Visitingtheusers#indexpage.#Noreason