目录
之前我在两篇SQLparse的开源库解析中就说过自己在寻找在python编程内可行的SQL血缘解析,JAVA去解析Hive的源码实践的话我还是打算放到后期来做,先把Python能够实现的先实现完。主要是HiveSQL的底层就是JAVA代码,怎么改写还是绕不开JAVA的。不过上篇系列我有提到过sqlparse,其实这个库用来解析血缘的话也不是不可以,但是能够实现的功能是有限的,目前我实验还行,一些较为复杂的SQL也能解析得出,算是成功达到可部署服务的水准了,但是根据SQL格式来匹配的话肯定是有些SQL格式不能完全匹配成功的,如果大家有需要血缘分析的SQL可以再次验证一下。
算是填完了之前的部分坑,目前的开发进度已经可以将SQL的表血缘分析追踪实现了,实现字段血缘的功能开发等后续将陆续上线。
首先来对该项目的目标来分析一下,说到SQL血缘分析,这偏向于数据治理。
数据治理(Data Governance)是组织中涉及数据使用的一整套管理行为。数据要产生价值,需要一个合理的“业务目标”,数据治理的所有活动应该围绕真实的业务目标而开展,建立数据标准、提升数据质量只是手段,而不是目标。
数据治理的本质是管理数据,因此需要加强元数据管理和主数据管理,从源头治理数据,补齐数据的相关属性和信息,比如:元数据、质量、安全、业务逻辑、血缘等,通过元数据驱动的方式管理数据生产、加工和使用。
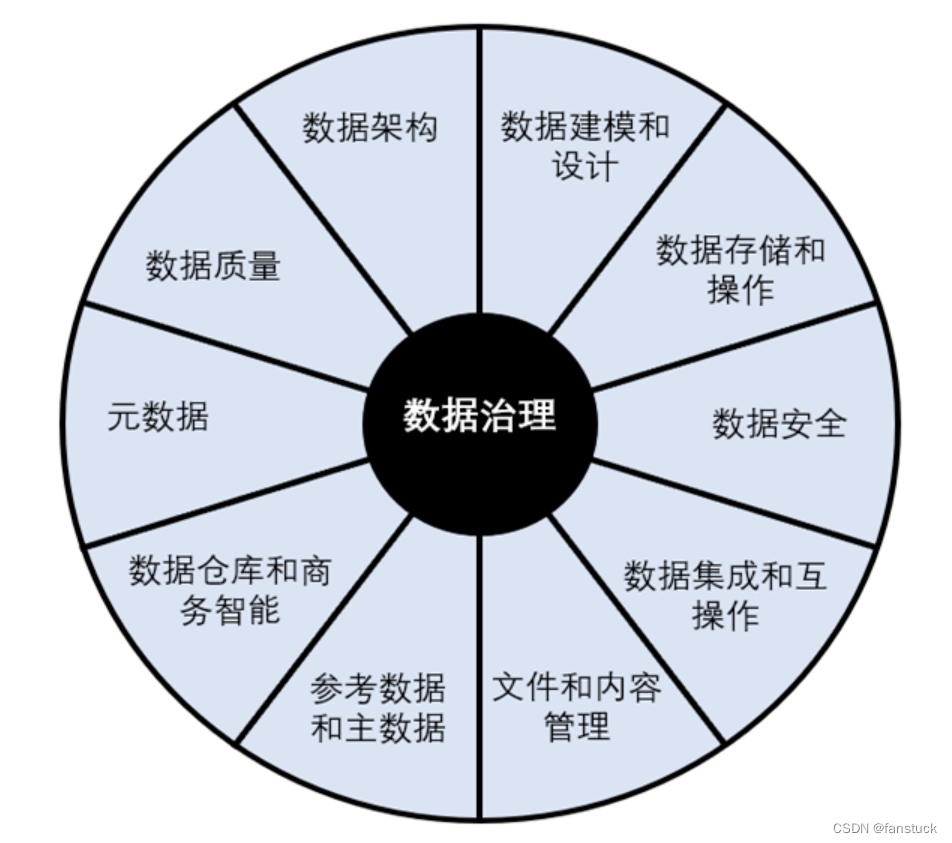
数据的质量直接影响着数据的价值,并且直接影响着数据分析的结果以及我们以此做出的决策的质量。数据模型血缘与任务调度的一致性是建管一体化的关键,有助于解决数据管理与数据生产口径不一致的问题,避免出现双重管理不一致的低效管理模式。
数据被业务场景使用时,发现数据错误,数据治理团队需要快速定位数据来源,修复数据错误。那么数据治理团队需要知道业务团队的数据来自于哪个核心库,核心库的数据又来自于哪个数据源头。我们的实践是在元数据和数据资源清单之间建立关联关系,且业务团队使用的数据项由元数据组合配置而来,这样,就建立了数据使用场景与数据源头之间的血缘关系。 数据资源目录:数据资源目录一般应用于数据共享的场景,例如政府部门之间的数据共享,数据资源目录是基于业务场景和行业规范而创建,同时依托于元数据和基础库主题而实现自动化的数据申请和使用。
也就是为什么我们需要解析SQL,追踪建表索引或者引用解析。
那么其中最重要的就是关于各个数据库之间的数据关系了,关于建表以及插入更新操作都会使数据发生一定的改变,那么这些操作就一定是被允许的?就像原来在网上看到的某某公司程序员删库跑路,或者是一不小心删错数据导致耽误产研线等等。为了防止以上事故的出现必定要为此操作上一层保险,为每个成员设定数据操作权限。这样以来提交的SQL语句就多了一层判断。
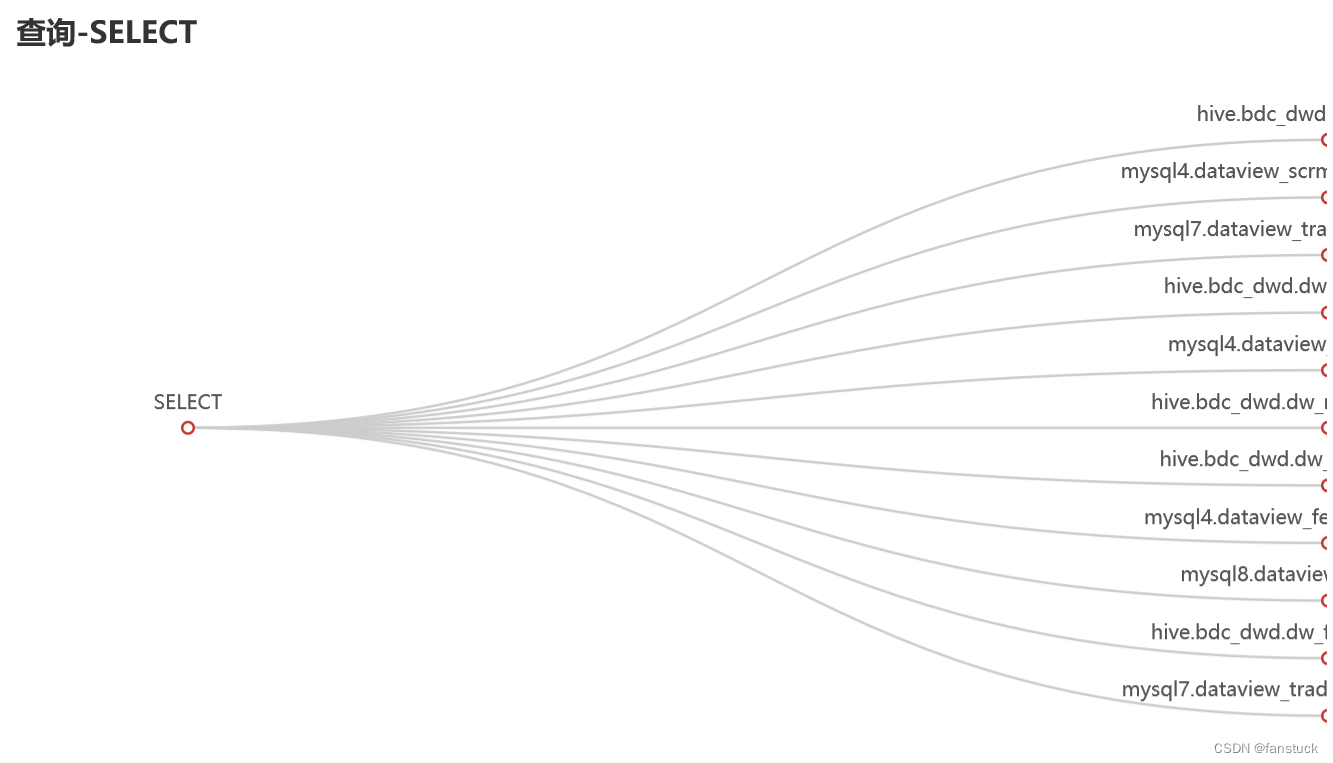
首先明白一点我们要做出的东西需要呈现一个怎样的形式,其中位于行业前排的无疑是SQLFlow:
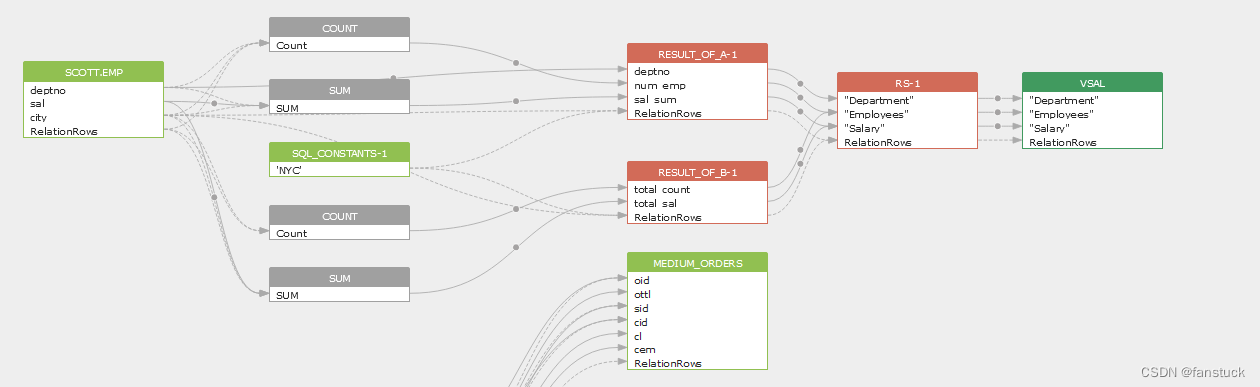
当第一次看到此图我就决定血缘追踪就应该是这个样子,能够清晰的解析出每个字段和表之间的血缘关系。以此我们设定输出的基准,我们要做的项目目标就是如此。
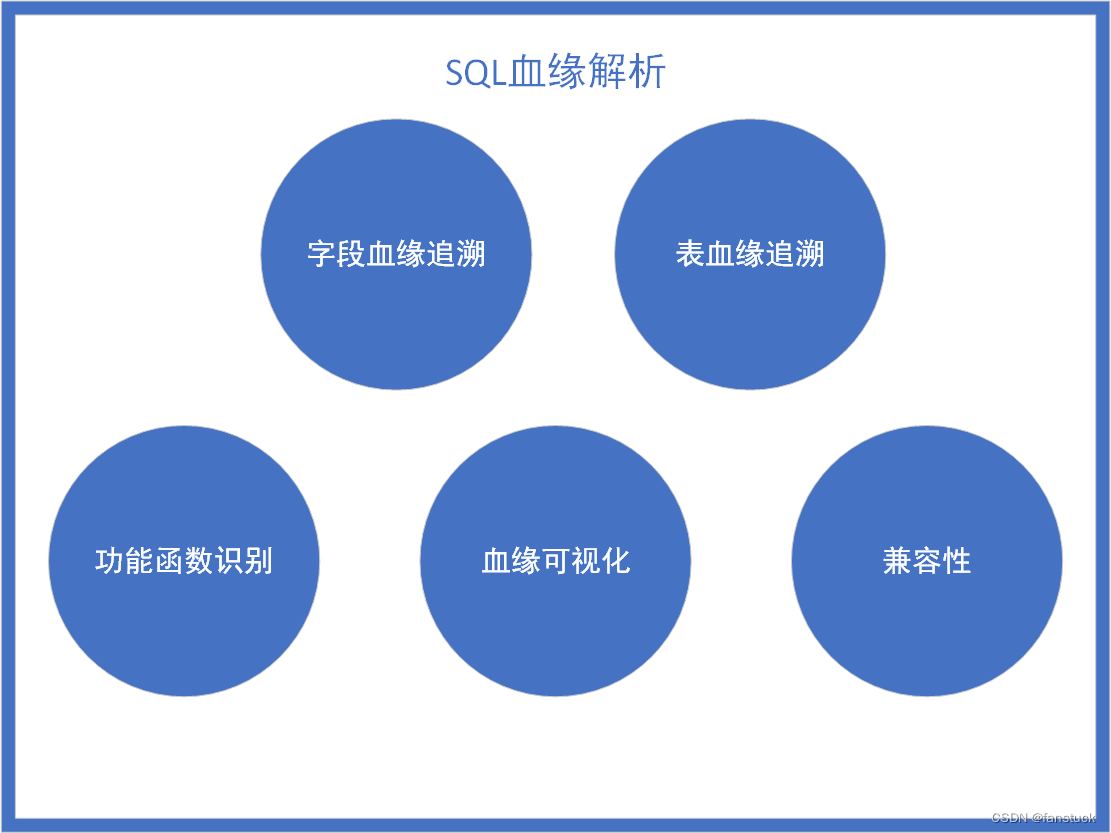
该功能也是必须要实现的功能,我们需要明白这个SQL主要是干什么事情的。如果是插入INSERT或者是CREATE就有血缘分析的必要,如果是SELECT的话那么做简单的SQL解析即可。有了研究sqlparse源码的成果我们调用相应的函数即可:
sql="select * from table1;insert into table select a,b,c from table2"
if __name__ == '__main__':
table_names=[]
#sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
type_name=get_main_functionsql(each_stmt)
print(type_name)输出:

那么对于SELECT我们就SQL涉及到的表追溯即可:

对于CREATE和INSERT的做血缘即可:
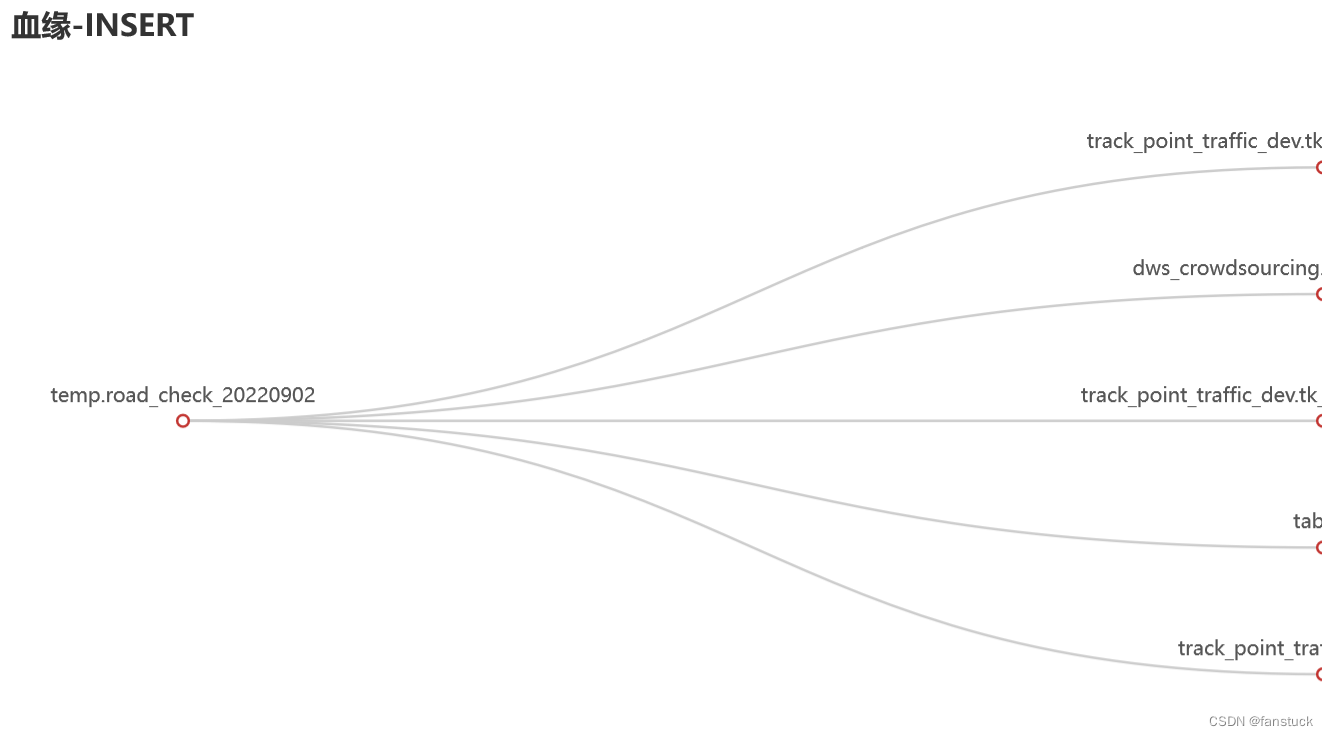
对于传入的SQL我们首先要让这条语句符合标准的SQL语句格式,这样对于传输格式保持一致,兼容很有作用。一般我们都是通过文本来读入。故需要读取文本做处理:
原始文本:

处理后:
if __name__ == '__main__':
sql=get_sqlstr('read_sql.txt')
print(sql)
得到的SQL无论是ANTRL还是SQLPARSE都是解析为一棵树的形式进行递归回溯。最终都要解析生产的SQL树:
sql="select * from table1;insert into table3 select a,b,c from table2"
if __name__ == '__main__':
#sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
table_names=[]
type_name=get_main_functionsql(each_stmt)
get_ASTTree(each_stmt) 
SQL:
select
b.product_name "产品",
count(a.order_id) "订单量",
b.selling_price_max "销售价",
b.gross_profit_rate_max/100 "毛利率",
case when b.business_type =1 then '自营消化' when b.business_type =2 then '服务商消化' end "消化模式"
from(select 'CRM签单' label,date(d.update_ymd) close_ymd,c.product_name,c.product_id,
a.order_id,cast(a.recipient_amount as double) amt,d.cost
from mysql4.dataview_fenxiao.fx_order a
left join mysql4.dataview_fenxiao.fx_order_task b on a.order_id = b.order_id
left join mysql7.dataview_trade.ddc_product_info c on cast(c.product_id as varchar) = a.product_ids and c.snapshot_version = 'SELLING'
inner join (select t1.par_order_id,max(t1.update_ymd) update_ymd,
sum(case when t4.product2_type = 1 and t5.shop_id is not null then t5.price else t1.order_hosted_price end) cost
from hive.bdc_dwd.dw_mk_order t1
left join hive.bdc_dwd.dw_mk_order_status t2 on t1.order_id = t2.order_id and t2.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join mysql7.dataview_trade.mk_order_merchant t3 on t1.order_id = t3.order_id
left join mysql7.dataview_trade.ddc_product_info t4 on t4.product_id = t3.MERCHANT_ID and t4.snapshot_version = 'SELLING'
left join mysql4.dataview_scrm.sc_tprc_product_info t5 on t5.product_id = t4.product_id and t5.shop_id = t1.seller_id
where t1.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
and t2.valid_state in (100,200) ------有效订单
and t1.order_mode = 10 --------产品消耗订单
and t2.complete_state = 1 -----订单已经完成
group by t1.par_order_id
) d on d.par_order_id = b.task_order_id
where c.product_type = 0 and date(from_unixtime(a.last_recipient_time)) > date('2016-01-01') and a.payee_type <> 1 -----------已收款
UNION ALL
select '企业管家消耗' label,date(c.update_ymd) close_ymd,b.product_name,b.product_id,
a.task_id,(case when a.yb_price = 0 and b.product2_type = 1 then b.selling_price_min else a.yb_price end) amt,
(case when a.yb_price = 0 and b.product2_type = 2 then 0 when b.product2_type = 1 and e.shop_id is not null then e.price else c.order_hosted_price end) cost
from mysql8.dataview_tprc.tprc_task a
left join mysql7.dataview_trade.ddc_product_info b on a.product_id = b.product_id and b.snapshot_version = 'SELLING'
inner join hive.bdc_dwd.dw_mk_order c on a.order_id = c.order_id and c.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join hive.bdc_dwd.dw_mk_order_status d on d.order_id = c.order_id and d.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join mysql4.dataview_scrm.sc_tprc_product_info e on e.product_id = b.product_id and e.shop_id = c.seller_id
where d.valid_state in (100,200) and d.complete_state = 1 and c.order_mode = 10
union ALL
select '交易管理系统' label,date(t6.close_ymd) close_ymd,t4.product_name,t4.product_id,
t1.order_id,(t1.order_hosted_price-t1.order_refund_price) amt,
(case when t1.order_mode <> 11 then t7.user_amount when t1.order_mode = 11 and t4.product2_type = 1 and t5.shop_id is not null then t5.price else t8.cost end) cost
from hive.bdc_dwd.dw_mk_order t1
left join hive.bdc_dwd.dw_mk_order_business t2 on t1.order_id = t2.order_id and t2.acct_day=substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join mysql7.dataview_trade.mk_order_merchant t3 on t1.order_id = t3.order_id
left join mysql7.dataview_trade.ddc_product_info t4 on t4.product_id = t3.MERCHANT_ID and t4.snapshot_version = 'SELLING'
left join mysql4.dataview_scrm.sc_tprc_product_info t5 on t5.product_id = t4.product_id and t5.shop_id = t1.seller_id
left join hive.bdc_dwd.dw_fact_task_ss_daily t6 on t6.task_id = t2.task_id and t6.acct_time=date_format(date_add('day',-1,current_date),'%Y-%m-%d')
left join (select a.task_id,sum(a.user_amount) user_amount
from hive.bdc_dwd.dw_fn_deal_asyn_order a
where a.is_new=1 and a.service='Trade_Payment' and a.state=1 and a.acct_day=substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
group by a.task_id)t7 on t7.task_id = t2.task_id
left join (select t1.par_order_id,sum(t1.order_hosted_price - t1.order_refund_price) cost
from hive.bdc_dwd.dw_mk_order t1
where t1.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2) and t1.order_type = 1 and t1.order_stype = 4 and t1.order_mode = 12
group by t1.par_order_id) t8 on t1.order_id = t8.par_order_id
where t1.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
and t1.order_type = 1 and t1.order_stype in (4,5) and t1.order_mode <> 12 and t4.product_id is not null and t1.order_hosted_price > 0 and t6.is_deal = 1 and t6.close_ymd >= '2018-12-31'
)a
left join mysql7.dataview_trade.ddc_product_info b on a.product_id = b.product_id and b.snapshot_version = 'SELLING'
where b.product2_type = 1 -------标品
and close_ymd between DATE_ADD('day',-7,CURRENT_DATE) and DATE_ADD('day',-1,CURRENT_DATE)
GROUP BY b.product_name,
b.selling_price_max,
b.gross_profit_rate_max/100,
b.actrul_supply_num,
case when b.business_type =1 then '自营消化' when b.business_type =2 then '服务商消化' end
order by count(a.order_id) desc
limit 10
if __name__ == '__main__':
table_names=[]
sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
type_name=get_main_functionsql(each_stmt)
blood_table(each_stmt)
Tree_visus(table_names,type_name)
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o