c语言文件操作

缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统声明的,取名FILE.
在VS2013提供的stdio.h中有以下的文件类型声明
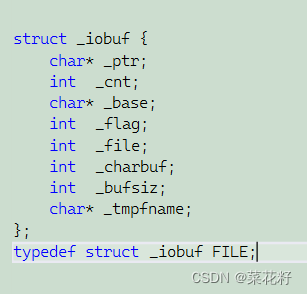
总结:FILE本质上就是一个结构体变量,它内部包含一个文件的基本信息。
不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异。每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,使用者不必关心细节。一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便。
例如

定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联的文件。
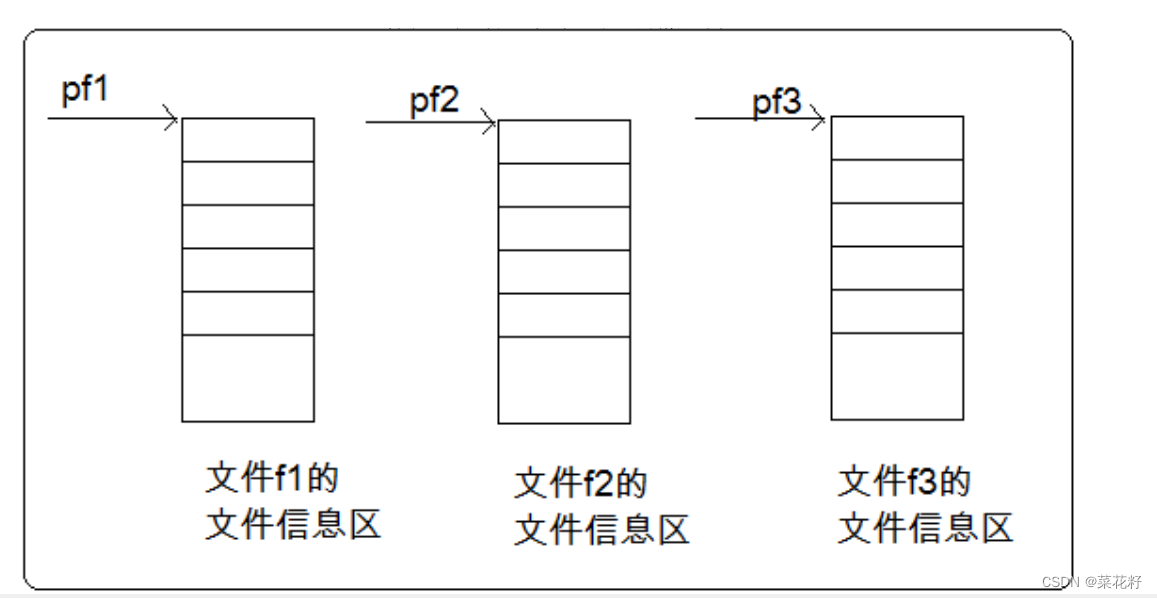
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指针和文件的关系。ANSIC 规定使用fopen函数来打开文件,fclose来关闭文件。
fopen:文件打开
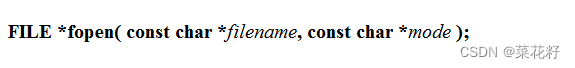
有两个参数,第一个是文件名;第二个是打开方式。
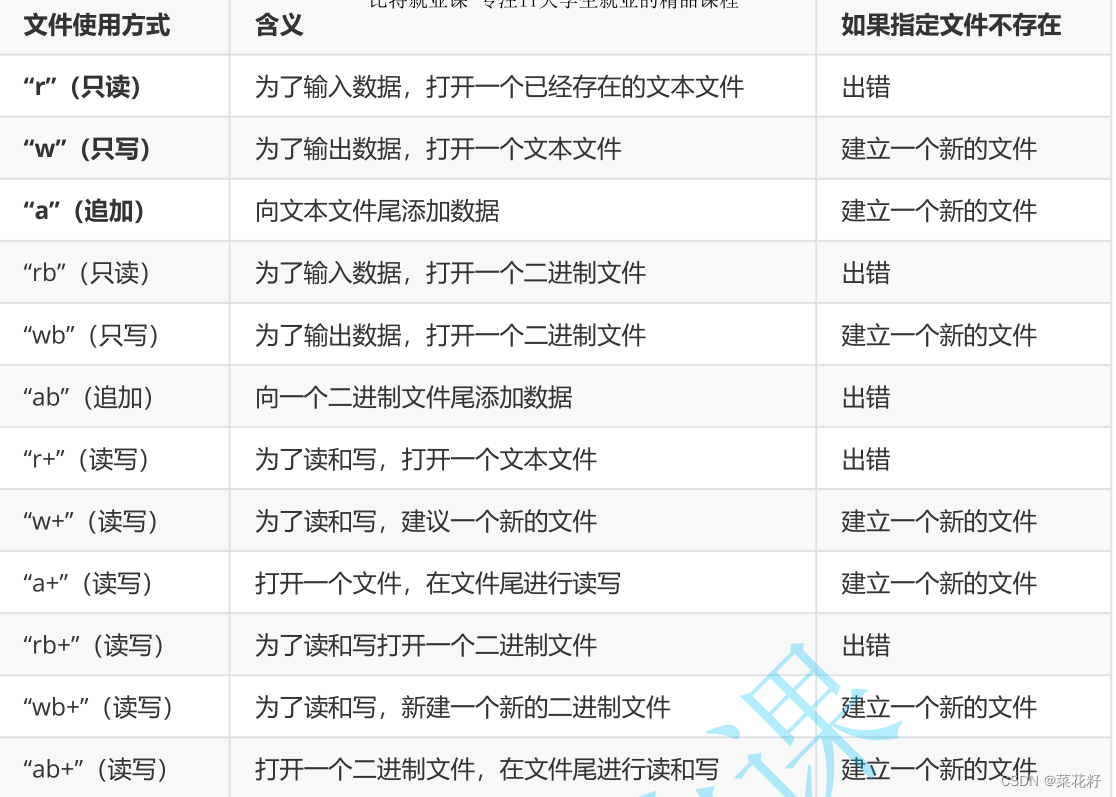

文件打开有很多方式。如果操作成功返回一个文件指针;如果失败,返回一个空指针。
fclose:关闭文件
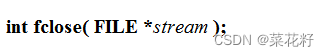
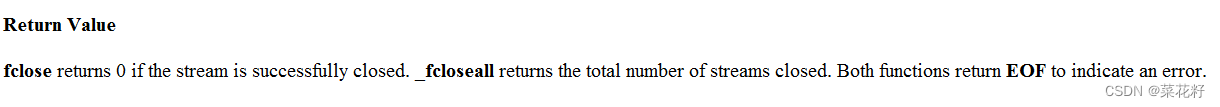
只有一个参数,文件指针。如果关闭失败返回EOF。
举个例子


由于我的路径下并没有这个文件,所以自然打开失败了。
接下来,将这个文件添加到当前路径。

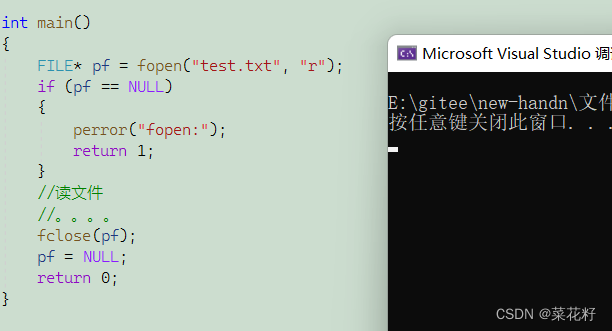
这样就是打开成功了。ps:注意在添加文件时一定要将文件扩展名打开。
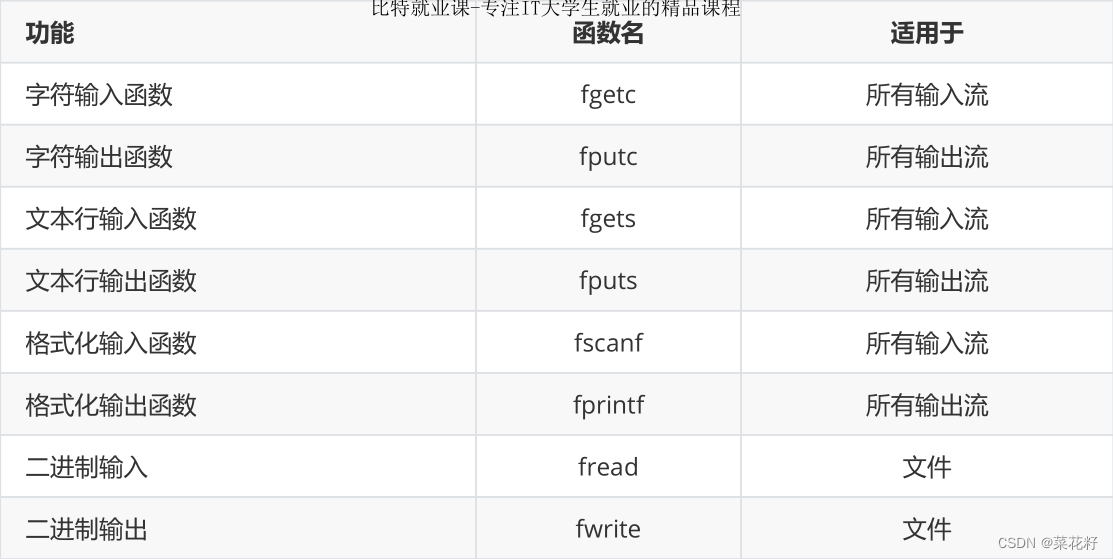


该函数只能只能操作一个字符,从文件里读取字符到内存中。如果读取成功,返回该字符的ASCII码值;如果读取失败,则返回EOF。
简单使用
打开文件,输入三个字符abc,再使用fget将其读到内存里了,这个读取是依次往后读取的。

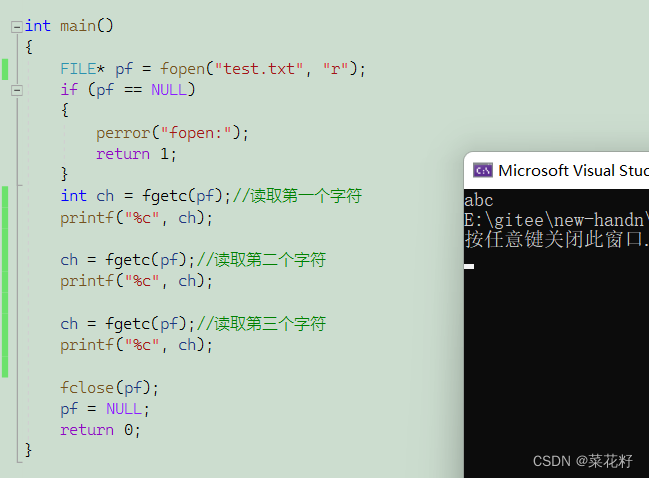

该函数是将内存里的文件写入文件里(也只能操作一个字符)。第一个参数是写入的字符,第二个参数是要写的文件名。



作用就是把str所指向的字符串写入文件里。


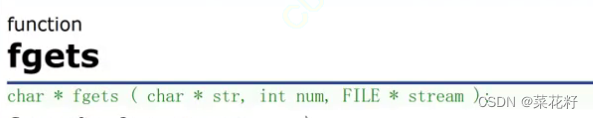

从文件里读取num个字符存放str所指向的空间里。
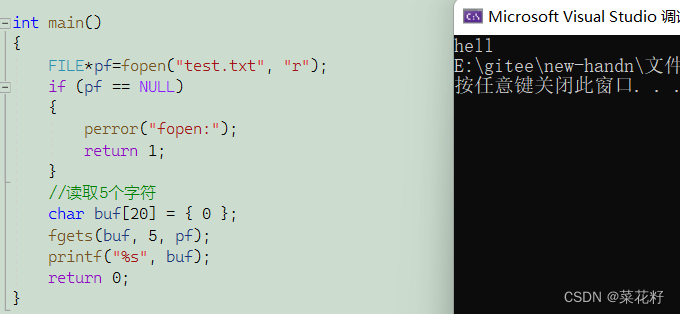
注意因为读取的是字符串,所以最后还会读取\0作为结束标志。故使用fgets读取n个字符时,实际上只能看到n-1个字符。
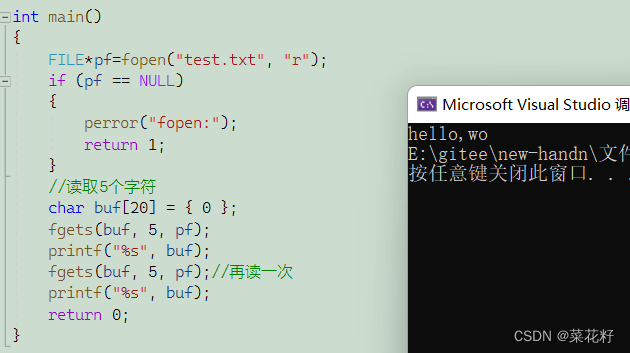
可以看到它是从上一次读取的末尾接着读的并不是又到最开始部分。
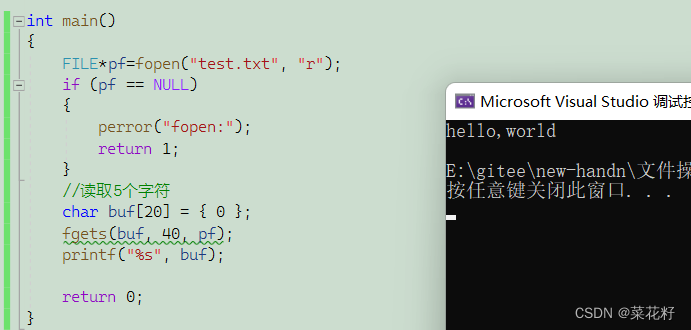
如果读取的字符数超过了该行的字符数,那么它会自动在末尾停下。同时,该函数只读取一行,不会将下一行的hehe读出来。


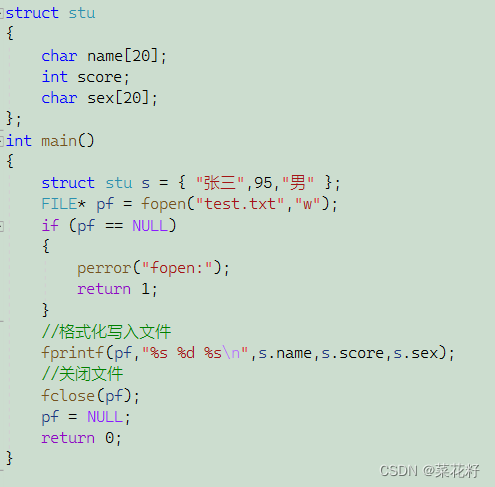
该函数是格式化存入,从内存里读取数据存放到文件里。该函数又两个参数,第一个是文件名,第二个是可变参数列表。其实对比一下printf就明白,fprintf的使用其实与printf一样,只是需要在前面加上文件名。



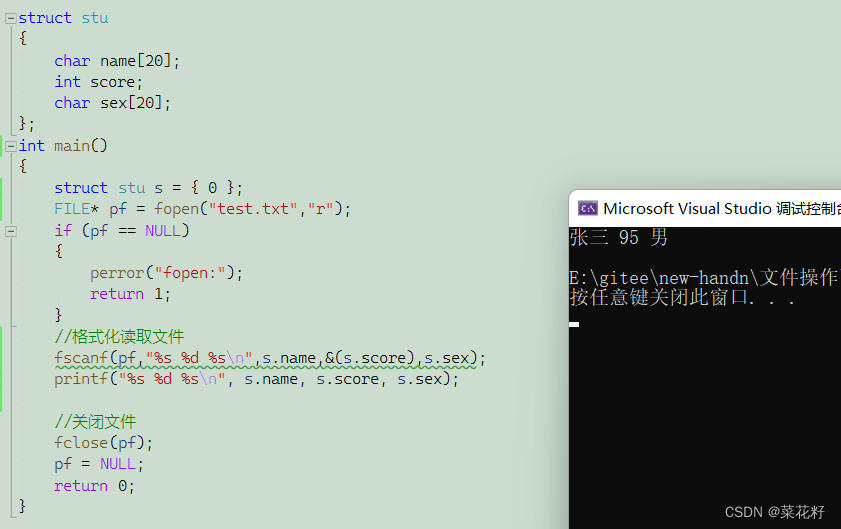
该函数是格式化读取,从该文件里读取数据到内存中。与scanf的使用一样,只是前面加上文件名。
fscanf,fprintf,scanf,printf的联系

我们在写程序时直接使用printf,scanf。就是因为程序默认打开了这三个流,所以我们不必写文件名。但其他文件并没有默认打开,所以我们在使用fprintf,fscanf的时候需要写上文件名。实际上fprintf(stdout…)=printf(…)


有四个参数。第一个是要写入的数据地址,第二个是写入数据的大小,第三个是要写入的个数,第四个是要写入的文件。
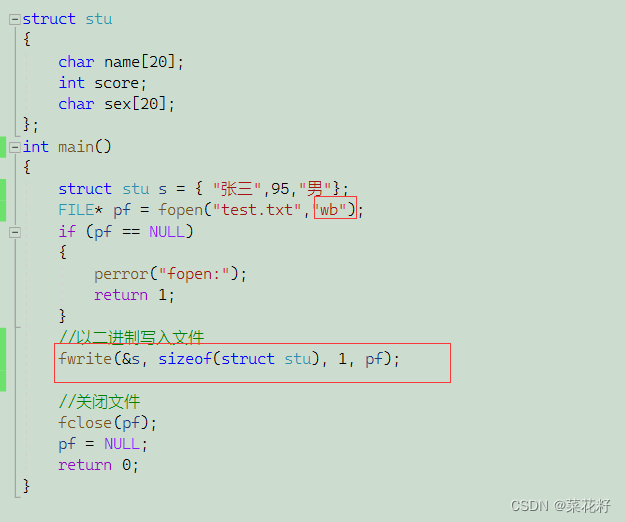

此时就是以二进制形式保存的,注意汉字的二进制储存任然是汉字。


fread的参数和fwrite的参数一模一样。实际上区别是fwrite是写入,fread是读出。
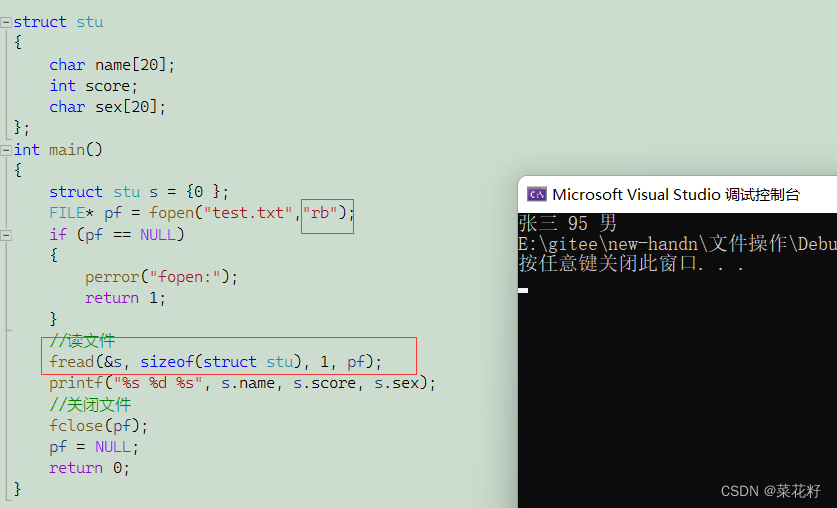

读到几个数据,fread就返回几个数。如果一个都没有读到就返回0.


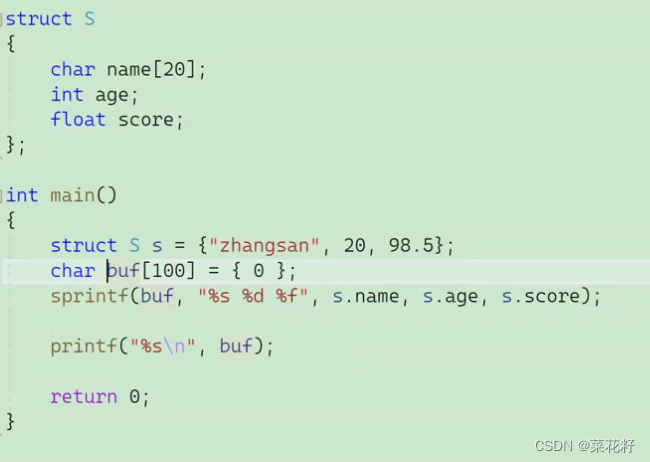
将一个类型转化为字符串。注意它只起到转化作用,不会打印。
以下是将一个结构体转化为字符串打印出来


把一个字符串转化为某种类型。
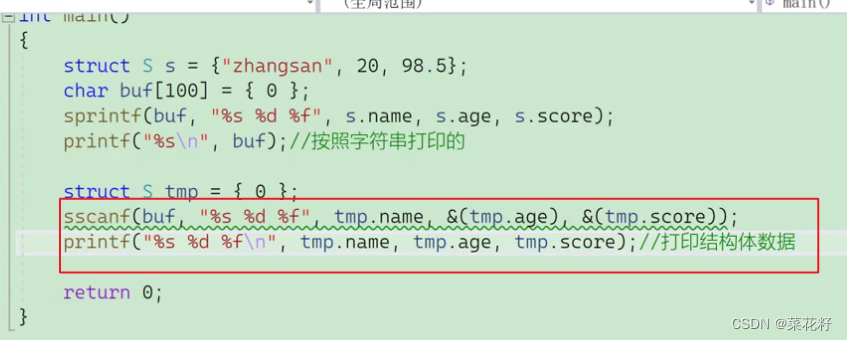

两次打印的方式不同但结果是一样的。


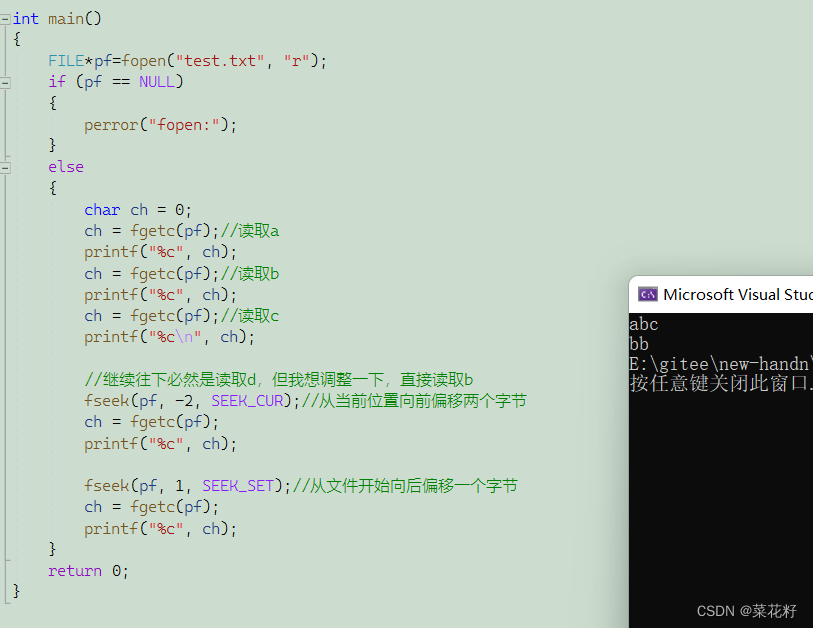
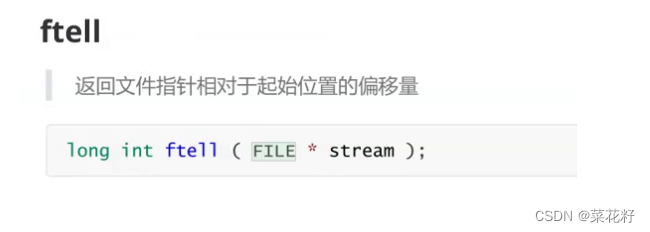
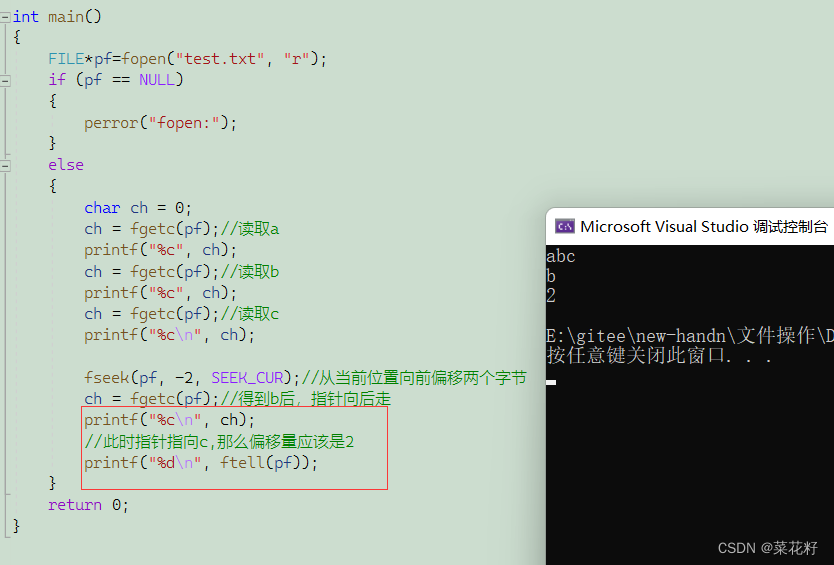
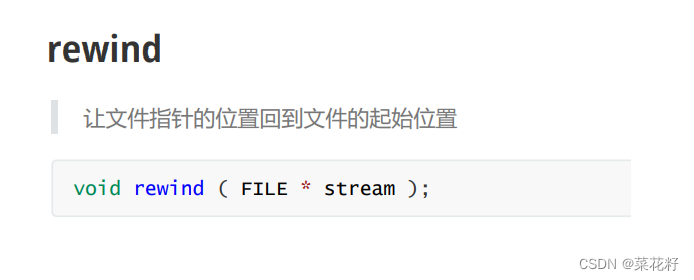
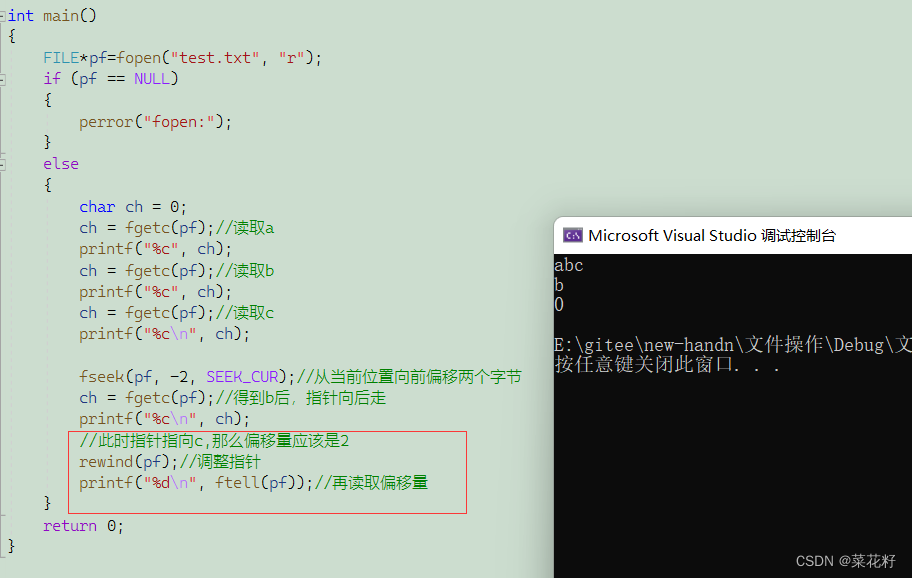
有三个参数。第一个是文件名,第二个是偏移量,第三个是起始位置。

起始位置有三种选项。第一个是SEEK_SET,从文件的起始位置开始;第二个是SEEK_CUR,从当前位置开始;第三个是SEEK_END,从文件的末尾开始。
例子

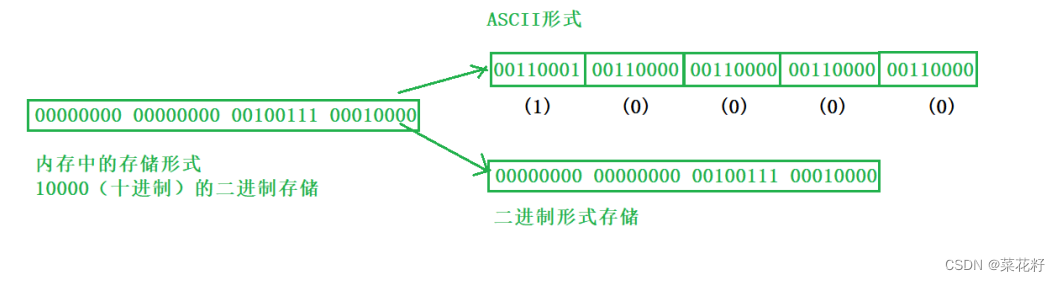
如果把10000按二进制形式存储,那么10000就会直接转换为二进制。如果按ASCII码值存储,则会看成1个字符1和4个字符0,而字符1的ASCII码值是49,字符0的ASII码值是48。



在c语言中EOF是文件结束的标志,所以很多时候就会错误的认为feof是用来判断文件是否结束的,实际上并不是。feof应当是用来判断文件是因为什么原因而结束的(注意此时文件已经结束了)。
牢记:在文件读取过程中,不能用feof函数的返回值直接用来判断文件的是否结束。
而是应用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束。

ps:在fgetc里如果读取失败返回EOF,在fgets里如果读取失败返回NULL;所以feof就用来判断是否为EOF,NULL如果是就说明是读取失败。同样fread会返回它所读到的数据个数,如果读到的数据个数小于要读的数据个数,那么可以判断fread读取失败。
一般使用文本文件

二进制文件



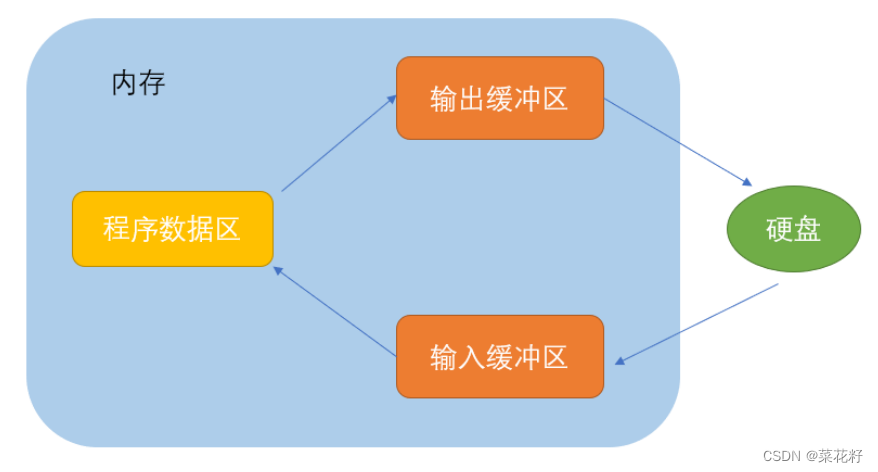
简单来说,无论是输入还是输出都需要先在缓冲区停留。直到缓冲区充满或者程序运行结束后才会到应到的位置。因为缓冲区在内存里,所以有时写文件时突然关机,那么可能文件没有保存就会随着内存的重置而清零。

我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\