监管机构已经卷到需要监控进程了,为了跟上通报步伐查了下资料,打算浅试一下camille,依据原作的文档初步了解到需要python3 、adb、frida、模拟器(木木-已成功、夜神)、root手机,开始逐个尝试,记录一下所遇到的情况。
原作祭上:
camille/use.md at master · zhengjim/camille · GitHub
https://www.cnblogs.com/zhengjim/p/15508738.html
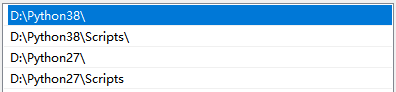
Python38、pip更新
电脑中如果有多个python环境的,记得改好名哦,不然会报错,我是配置了环境变量然后让38的置顶
pip如果久没用了也记得升级一下,基本报错后自动复制提示命令就行

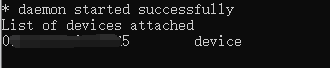
adb shell
如果是用的手机就直接adb devices,如果是模拟器需在对应路径下运行adb connect

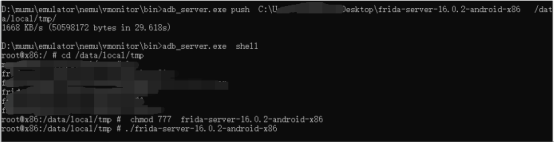
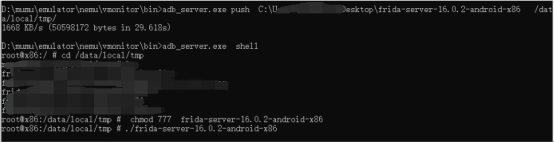
adb基本思路 就是 先查看cpu版本 然后下载对应版本的frida后 将文件push进去 放到自己熟悉的路径,然后给文件赋权后直接运行frida

官方祭上: https://github.com/frida/frida/releases
frida在电脑中可以直接使用pip安装,在root手机/模拟器中则需要去官方下载匹配的版本并放置在root手机/模拟器中并运行
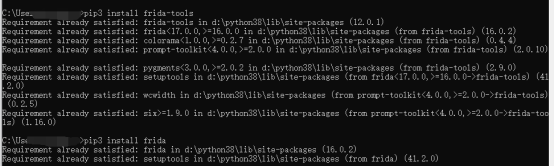

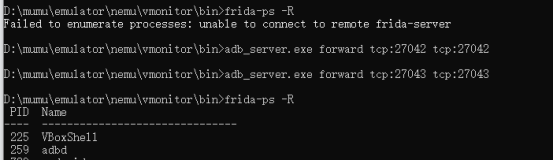
在实际使用过程中可以通过frida-ps -R命令查看机器的进程列表来判断frida-server是否启动,如果提示 unable to connect to remote frida-server则需要进行端口转发
官方祭上:https://github.com/zhengjim/camille
下载好源码后解压到本机,进入camille目录下,pip再安装一个txt文件
pip install -r requirements.txt


使用camille的两个基础命令
python camille.py APP包名
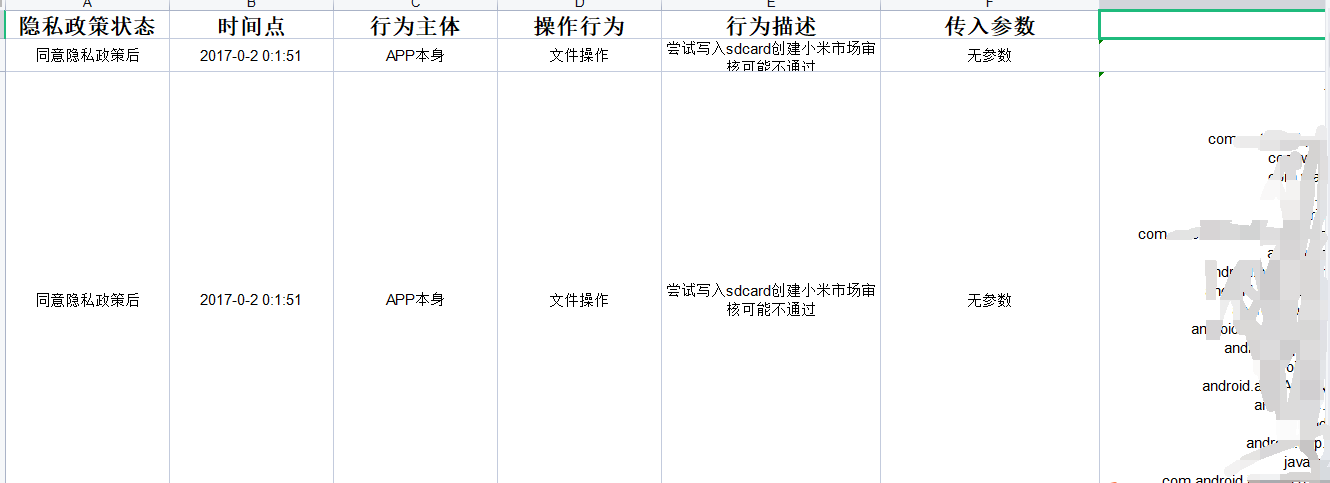
python camille.py APP包名 -ns -f D:\camille\1.xls
python camile.py APP包名 -npp -f D:\camille\123.xls
① frida not executable: 64-bit ELF file
因为我的模拟器cpu是x86,并不是x86_64,frida没下对cpu型号导致报错
指路主流模拟器CPU型号,但是不保准,我的mumu是x86,并不是x86_64,被忽悠了
夜神 x86 默认连上
雷电 x86_64 默认连上
网易mumu x86_64 adb connect 127.0.0.1:7555
逍遥 x86_64 adb connect 127.0.0.1:21503
蓝叠 x86 默认连上
腾讯手机助手 暂不支持adb连接

指路参考链接:http://www.manongjc.com/detail/25-ucjqyfnoneluxul.html
虽然并没有解决到我上面的报错,指不定有人需要
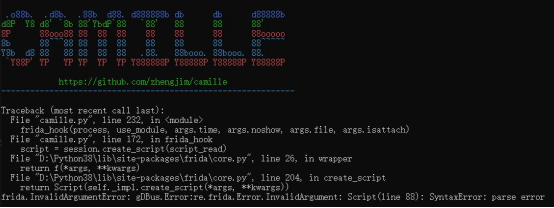
② Script(line 88): SyntaxError : parse error
因为我的python环境之前装过frida,然后升级frida的时候没有对frida-tools同步升级导致frida的版本和frida-tools的对应不上,frida和frida-tools有对应的版本,当时解决方法是重新指定版本安装frida和frida-tools,frida官方github里面Assets就能找到对应的tools版本
pip install frida==16.0.2
pip install frida-tools==12.0.1
指路参考链接:https://blog.csdn.net/qq_41374107/article/details/104654146
虽然也没有解决我的报错,但指不定有人需要
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
假设我在Store的模型中有这个非常简单的方法:defgeocode_addressloc=Store.geocode(address)self.lat=loc.latself.lng=loc.lngend如果我想编写一些不受地理编码服务影响的测试脚本,这些脚本可能已关闭、有限制或取决于我的互联网连接,我该如何模拟地理编码服务?如果我可以将地理编码对象传递到该方法中,那将很容易,但我不知道在这种情况下该怎么做。谢谢!特里斯坦 最佳答案 使用内置模拟和stub的rspecs,你可以做这样的事情:setupdo@subject=MyCl
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我有一个gem,它有一个根据Rails.env的不同行为的方法:defself.envifdefined?(Rails)Rails.envelsif...现在我想编写一个规范来测试这个代码路径。目前我是这样做的:Kernel.const_set(:Rails,nil)Rails.should_receive(:env).and_return('production')...没关系,只是感觉很丑。另一种方法是在spec_helper中声明:moduleRails;end而且效果也很好。但也许有更好的方法?理想情况下,这应该有效:rails=double('Rails')rails.sho
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..