
package org.example.calc;
import java.util.*;
public class CalcByHand {
// 定义操作符并区分优先级,*/ 优先级较高
public static Set<String> opSet1 = new HashSet<>();
public static Set<String> opSet2 = new HashSet<>();
static{
opSet1.add("+");
opSet1.add("-");
opSet2.add("*");
opSet2.add("/");
}
public static void main(String[] args) {
String exp="1+3*4";
//将表达式拆分成token
String[] tokens = exp.split("((?<=[\\+|\\-|\\*|\\/])|(?=[\\+|\\-|\\*|\\/]))");
Stack<String> opStack = new Stack<>();
Stack<String> numStack = new Stack<>();
int proi=1;
// 基于类型放到不同的栈中
for(String token: tokens){
token = token.trim();
if(opSet1.contains(token)){
opStack.push(token);
proi=1;
}else if(opSet2.contains(token)){
proi=2;
opStack.push(token);
}else{
numStack.push(token);
// 如果操作数前面的运算符是高优先级运算符,计算后结果入栈
if(proi==2){
calcExp(opStack,numStack);
}
}
}
while (!opStack.isEmpty()){
calcExp(opStack,numStack);
}
String finalVal = numStack.pop();
System.out.println(finalVal);
}
private static void calcExp(Stack<String> opStack, Stack<String> numStack) {
double right=Double.valueOf(numStack.pop());
double left = Double.valueOf(numStack.pop());
String op = opStack.pop();
String val;
switch (op){
case "+":
val =String.valueOf(left+right);
break;
case "-":
val =String.valueOf(left-right);
break;
case "*":
val =String.valueOf(left*right);
break;
case "/":
val =String.valueOf(left/right);
break;
default:
throw new UnsupportedOperationException("unsupported");
}
numStack.push(val);
}
}grammar LabeledExpr; // rename to distinguish from Expr.g4
prog: stat+ ;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace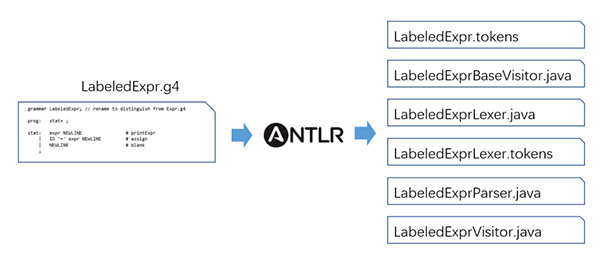 命令行如下:
命令行如下:
antlr4 -package org.example.calc -no-listener -visitor .\LabeledExpr.g4$ tree .
├── LabeledExpr.g4
├── LabeledExpr.tokens
├── LabeledExprBaseVisitor.java
├── LabeledExprLexer.java
├── LabeledExprLexer.tokens
├── LabeledExprParser.java
└── LabeledExprVisitor.javaANTLRInputStream input = new ANTLRInputStream(is);
LabeledExprLexer lexer = new LabeledExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog(); // parse
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);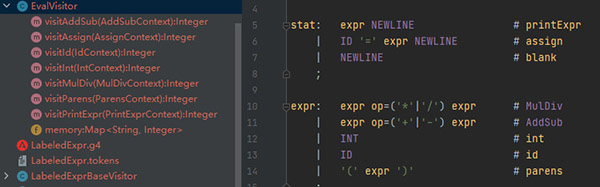 从图中可以看出,生成的代码和规则定义是对应起来的。例如visitAddSub对应AddSub规则,visitId对应id规则。以此类推…实现加减法的代码如下:
从图中可以看出,生成的代码和规则定义是对应起来的。例如visitAddSub对应AddSub规则,visitId对应id规则。以此类推…实现加减法的代码如下:
/** expr op=('+'|'-') expr */
@Override
public Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == LabeledExprParser.ADD ) return left + right;
return left - right; // must be SUB
}antlr4 -package org.example.calc -listener .\LabeledExpr.g4ANTLRInputStream input = new ANTLRInputStream(is);
LabeledExprLexer lexer = new LabeledExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog(); // parse
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new EvalListener(), tree);@Override
public void exitAddSub(LabeledExprParser.AddSubContext ctx) {
Double left = numStack.pop();
Double right= numStack.pop();
Double result;
if (ctx.op.getType() == LabeledExprParser.ADD) {
result = left + right;
} else {
result = left - right;
}
numStack.push(result);
} Visitor模式
Visitor模式
grammar SqlBase;
tokens {
DELIMITER
}
singleStatement
: statement EOF
;
statement
: query #statementDefault
;
query
: queryNoWith
;
queryNoWith:
queryTerm
;
queryTerm
: queryPrimary #queryTermDefault
;
queryPrimary
: querySpecification #queryPrimaryDefault
;
querySpecification
: SELECT selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
;
selectItem
: expression #selectSingle
;
relation
: sampledRelation #relationDefault
;
expression
: booleanExpression
;
booleanExpression
: valueExpression #predicated
;
valueExpression
: primaryExpression #valueExpressionDefault
;
primaryExpression
: identifier #columnReference
;
sampledRelation
: aliasedRelation
;
aliasedRelation
: relationPrimary
;
relationPrimary
: qualifiedName #tableName
;
qualifiedName
: identifier ('.' identifier)*
;
identifier
: IDENTIFIER #unquotedIdentifier
;
SELECT: 'SELECT';
FROM: 'FROM';
fragment DIGIT
: [0-9]
;
fragment LETTER
: [A-Z]
;
IDENTIFIER
: (LETTER | '_') (LETTER | DIGIT | '_' | '@' | ':')*
;
WS
: [ \r\n\t]+ -> channel(HIDDEN)
;
// Catch-all for anything we can't recognize.
// We use this to be able to ignore and recover all the text
// when splitting statements with DelimiterLexer
UNRECOGNIZED
: .
; 尽管SQL较为复杂,但是通过理解g4文件,也能清晰理解其结构划分。回到SelectBase.g4文件,同样我们使用Antlr4命令处理g4文件,生成代码:
尽管SQL较为复杂,但是通过理解g4文件,也能清晰理解其结构划分。回到SelectBase.g4文件,同样我们使用Antlr4命令处理g4文件,生成代码:
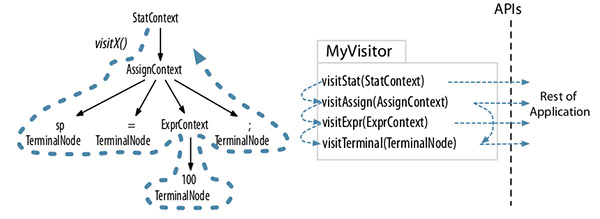
antlr4 -package org.example.antlr -no-listener -visitor .\SqlBase.g4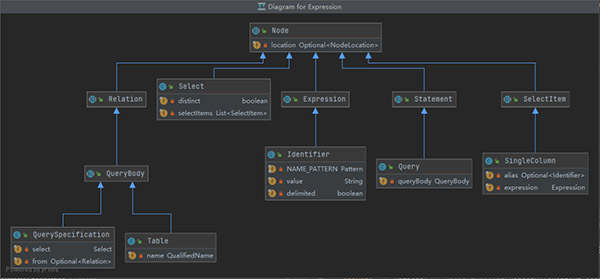 通过这个类图,可以清晰明了看清楚SQL语法中的各个基本元素。
然后基于visitor模式实现自己的解析类AstBuilder (这里为了简化问题,依然从presto源码中进行裁剪)。以处理querySpecification规则代码为例:
通过这个类图,可以清晰明了看清楚SQL语法中的各个基本元素。
然后基于visitor模式实现自己的解析类AstBuilder (这里为了简化问题,依然从presto源码中进行裁剪)。以处理querySpecification规则代码为例:
@Override
public Node visitQuerySpecification(SqlBaseParser.QuerySpecificationContext context)
{
Optional<Relation> from = Optional.empty();
List<SelectItem> selectItems = visit(context.selectItem(), SelectItem.class);
List<Relation> relations = visit(context.relation(), Relation.class);
if (!relations.isEmpty()) {
// synthesize implicit join nodes
Iterator<Relation> iterator = relations.iterator();
Relation relation = iterator.next();
from = Optional.of(relation);
}
return new QuerySpecification(
getLocation(context),
new Select(getLocation(context.SELECT()), false, selectItems),
from);
}SqlParser sqlParser = new SqlParser();
Statement statement = sqlParser.createStatement(sql);/**
* 获取待查询的表名和字段名称
*/
QuerySpecification specification = (QuerySpecification) query.getQueryBody();
Table table= (Table) specification.getFrom().get();
List<SelectItem> selectItems = specification.getSelect().getSelectItems();
List<String> fieldNames = Lists.newArrayList();
for(SelectItem item:selectItems){
SingleColumn column = (SingleColumn) item;
fieldNames.add(((Identifier)column.getExpression()).getValue());
}
/**
* 基于表名确定查询的数据源文件
*/
String fileLoc = String.format("./data/%s.csv",table.getName());
/**
* 从csv文件中读取指定的字段
*/
Reader in = new FileReader(fileLoc);
Iterable<CSVRecord> records = CSVFormat.RFC4180.withFirstRecordAsHeader().parse(in);
List<Row> rowList = Lists.newArrayList();
for(CSVRecord record:records){
Row row = new Row();
for(String field:fieldNames){
row.addColumn(record.get(field));
}
rowList.add(row);
}
/**
* 格式化输出到控制台
*/
int width=30;
String format = fieldNames.stream().map(s-> "%-"+width+"s").collect(Collectors.joining("|"));
System.out.println( "|"+String.format(format, fieldNames.toArray())+"|");
int flagCnt = width*fieldNames.size()+fieldNames.size();
String rowDelimiter = String.join("", Collections.nCopies(flagCnt, "-"));
System.out.println(rowDelimiter);
for(Row row:rowList){
System.out.println( "|"+String.format(format, row.getColumnList().toArray())+"|");
} cities.csv文件样例数据如下:
cities.csv文件样例数据如下:
"LatD","LatM","LatS","NS","LonD","LonM","LonS","EW","City","State"
41, 5, 59, "N", 80, 39, 0, "W", "Youngstown", OH
42, 52, 48, "N", 97, 23, 23, "W", "Yankton", SD
46, 35, 59, "N", 120, 30, 36, "W", "Yakima", WA
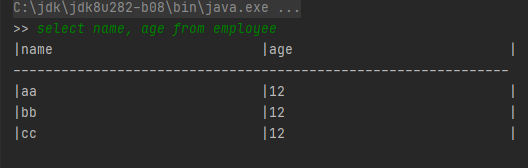
42, 16, 12, "N", 71, 48, 0, "W", "Worcester", MA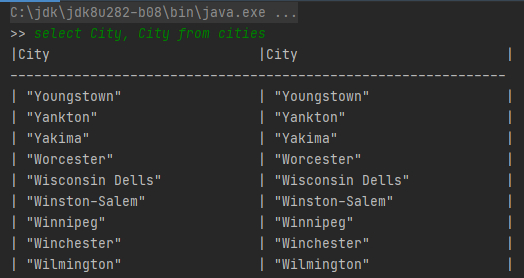 SQL样例2:select name, age from employee
SQL样例2:select name, age from employee
 本节讲述了如何基于Presto源码,裁剪g4规则文件,然后基于Antlr4实现用sql语句从csv文件查询数据。依托于对Presto源码的裁剪进行编码实验,对于研究SQL引擎实现,理解Presto源码能起到一定的作用。
本节讲述了如何基于Presto源码,裁剪g4规则文件,然后基于Antlr4实现用sql语句从csv文件查询数据。依托于对Presto源码的裁剪进行编码实验,对于研究SQL引擎实现,理解Presto源码能起到一定的作用。
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail
一般来说,我是Middleman和ruby的新手。我已经安装了Ruby我已经安装了Middleman和gem以使其运行。我需要使用slim而不是默认的模板系统。所以我安装了Slimgem。Slim的网站只说我需要'slim'才能让它工作。中间人网站说我只需要在config.rb文件中添加模板引擎,但是没有给出例子...对于没有ruby背景的人来说,这没有帮助。我在git上找了几个config.rb,它们都有:require'slim'和#Setslim-langoutputstyleSlim::Engine.set_default_options:pretty=>true#Se
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?
我有一个Rails3引擎。在初始化程序中,它需要来自某个文件夹的一堆文件。在这个文件中,我引擎的用户定义了代码、业务逻辑、配置引擎等。所有这些数据都静态存储在我的引擎主模块中(在应用程序属性中)moduleMyEngineclass我希望在开发模式下根据每个请求重新加载这些文件。(这样用户就不必重新加载服务器来查看他刚刚所做的更改)当然我可以做这样的事情而不是初始化config.to_preparedoMyEngine.application.clear!load('some/file')end但是这样我会遇到问题(因为这个文件中定义的常量不会真正被重新加载)。理想的解决方案是让我的整
许多正则表达式引擎在单行字符串中匹配.*两次,例如,在执行基于正则表达式的字符串替换时:根据定义,第一个匹配项是整个(单行)字符串,正如预期的那样。在许多引擎中有第二个匹配项,即空字符串;也就是说,即使第一个匹配项消耗了整个输入字符串,.*仍会再次匹配,然后匹配输入字符串末尾的空字符串。注意:要确保只找到一个匹配项,请使用^.*我的问题是:这种行为有充分的理由吗?一旦输入字符串被完全使用,我不希望再次尝试找到匹配项。除了反复试验之外,您能否从支持的文档/正则表达式方言/标准中收集到哪些引擎表现出这种行为?更新:revo'shelpfulanswer解释当前行为的方式;至于潜在的原因,请