超详细【入门精讲】数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本
感谢B站UP主 哈喽鹏程!!!
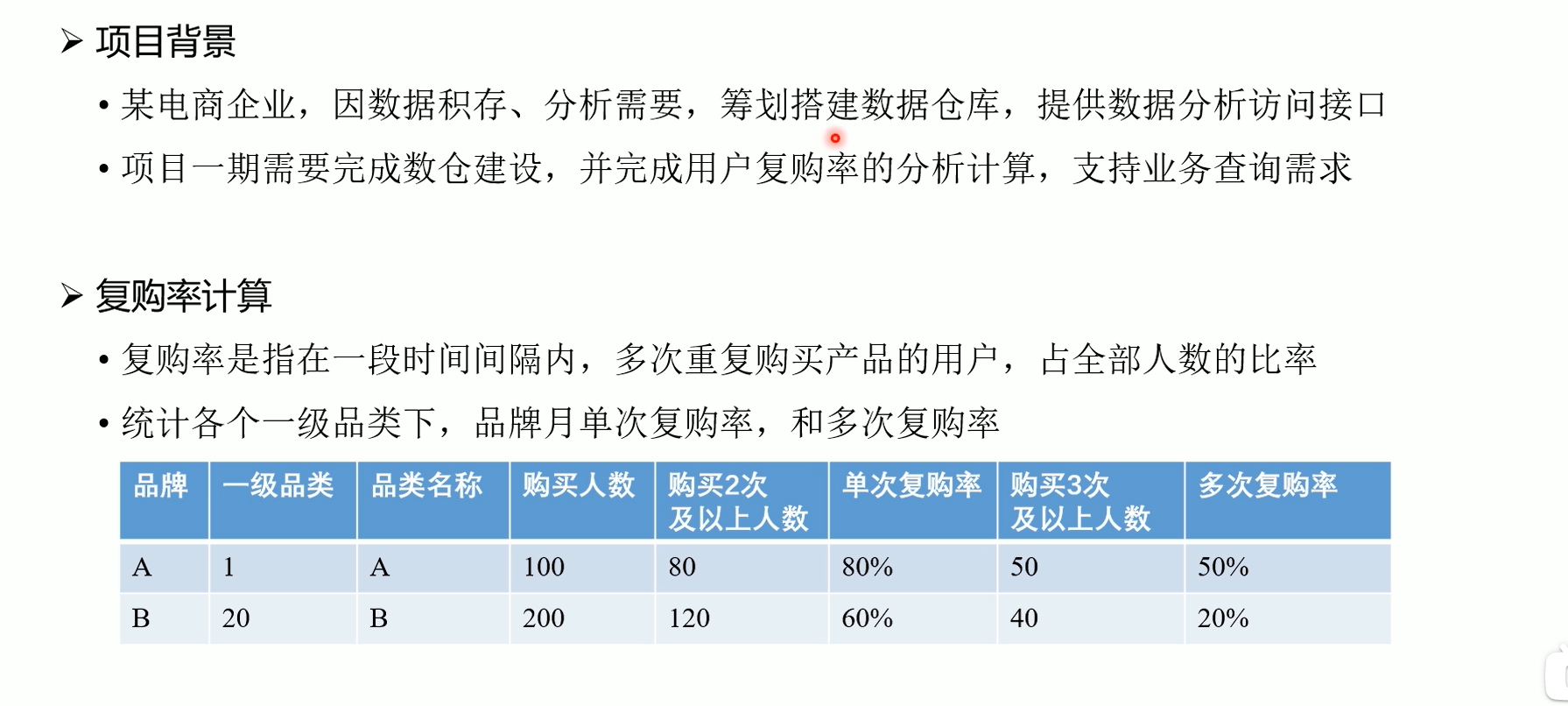
文章目录
B站课程链接:https://www.bilibili.com/video/BV1qv411y7Wv/
下载UP主 哈喽鹏程 给的资源镜像及脚本包
后续所使用的SQL脚本和shell脚本及job脚本文件,均在此下载,请自行下载
下载连接:
数据仓库的课件:
链接:https://pan.baidu.com/s/1_B2FPJYbHR-qq-5Q-Xfamw/?pwd=d3a9
提取码:d3a9
数据仓库的实验数据,资源镜像及脚本包:
链接:https://pan.baidu.com/s/1zSkL1YWa6wGkKrUW-Zl8Yw/?pwd=fwpq
提取码:fwpq
数据仓库的automaticDeploy项目代码:
链接:https://pan.baidu.com/s/1qspiJ8LbrSr58pg84ICRUA/?pwd=7nff
提取码:7nff
备用链接:
数据仓库的实验数据,资源镜像及脚本包:
链接:https://pan.baidu.com/s/1WZsfADEGUlD1U7LcEf2dww/?pwd=ik61
提取码:ik61
数据仓库的资源镜像及脚本包和automaticDeploy项目代码(最全):
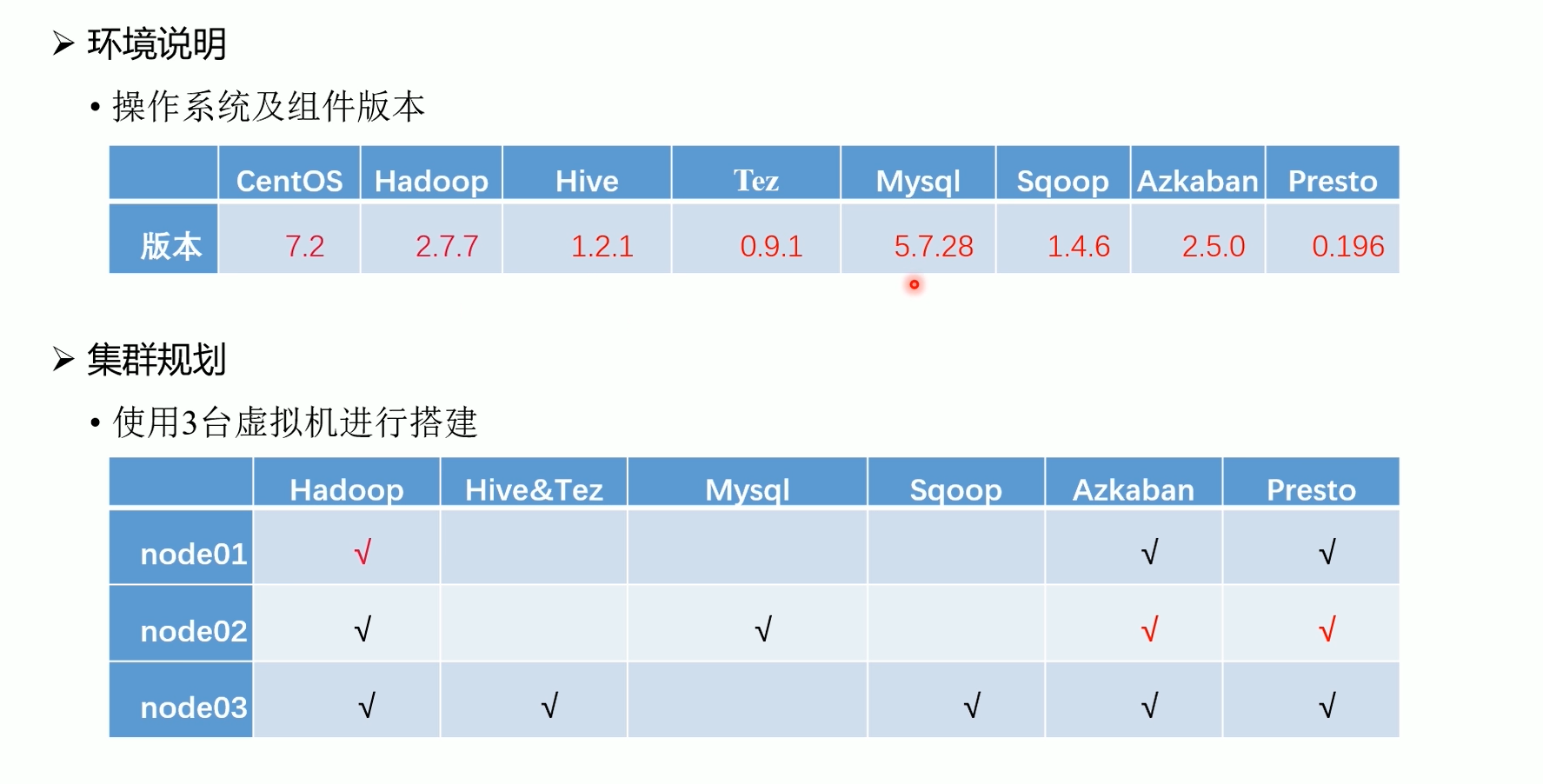
安装以下软件:
虚拟机软件: Virtual Box, 下载链接: https://www.virtualbox.org/
远程连接软件: Xshell (也可以使用其他远程连接软件, 推荐使用FinalShell,本博客使用的是FinalShell)
Virtual Box, 下载链接: https://www.virtualbox.org/
XShell,下载链接:https://www.xshell.com/zh/xshell/
FinalShell,下载链接:http://www.hostbuf.com/t/988.html,网盘连接:https://www.aliyundrive.com/s/WSvcTJZyeVM
Xshell和FinalShell均为远程连接工具,使用其中一个即可
资源镜像及脚本包的地址在第0章节
官网下载安装包,一路next就行,可以更改安装路径
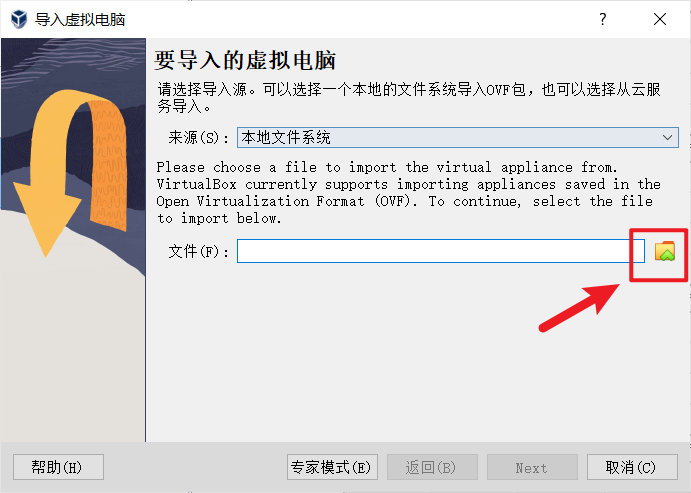
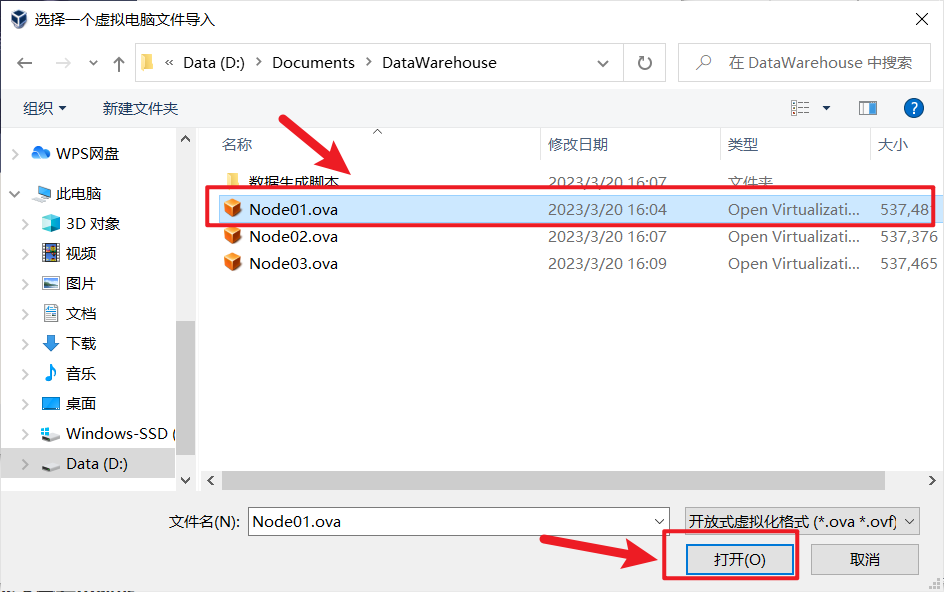
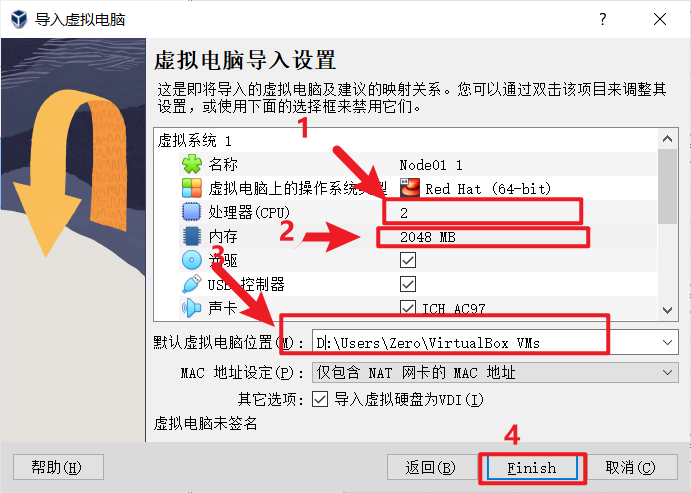
node02,node03同样的操作
虚拟机第一次打开的时候可能会有网络报错,这个时候需要操作一下
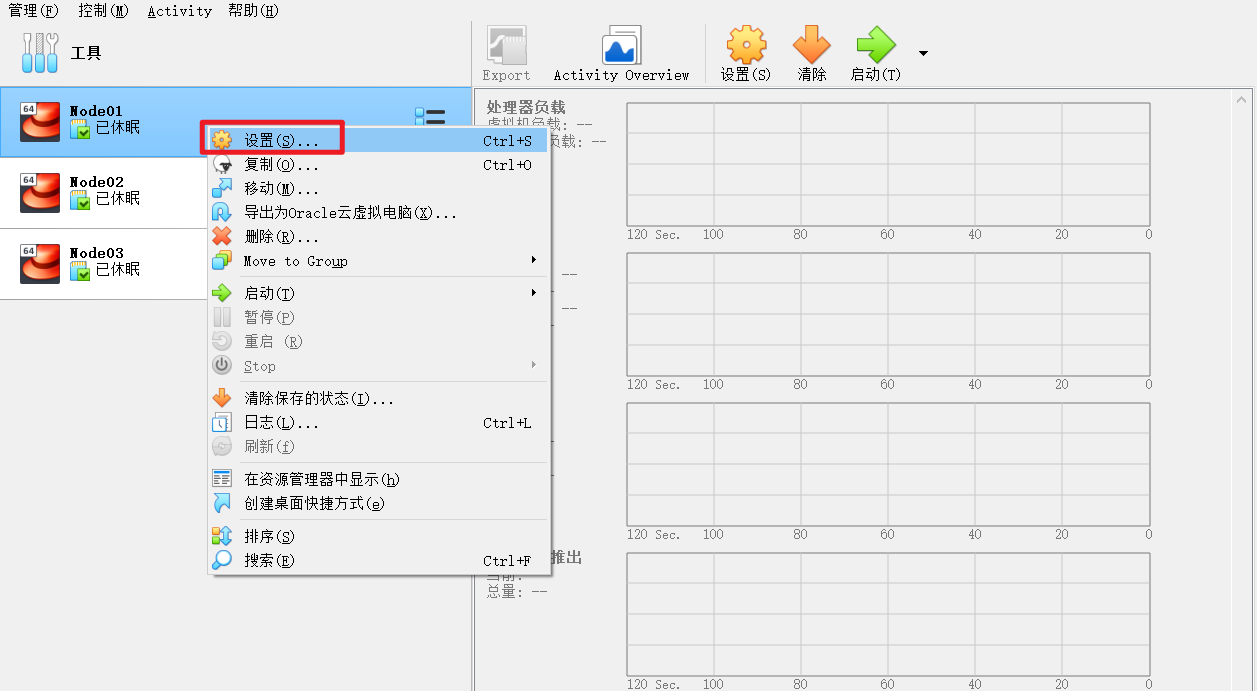
这里需要手动选择一次网卡,注意是一定要再选择一次
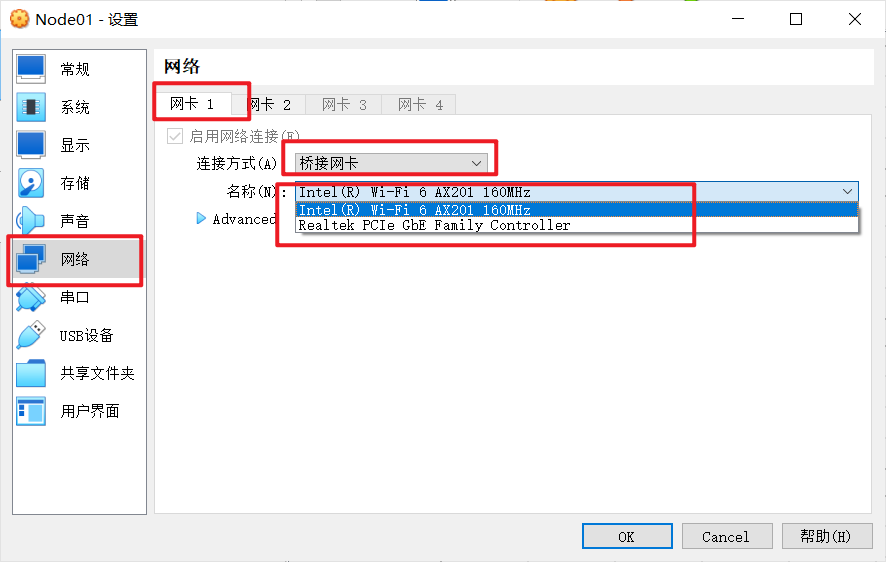
然后可以开启虚拟机了
三台虚拟机用户名及密码, 进入虚拟机
node01 root 123456
node02 root 123456
node03 root 123456
windows下查看IP地址
win+r 然后输入cmd 回车,打开命令行窗口,输入ifconfig查看主机ip地址
例如:
192.168.192.175
本地链接 IPv6 地址. . . . . . . . : fe80::8ecd:4848:96f2:2659%6
IPv4 地址 . . . . . . . . . . . . : 192.168.192.175
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : fe80::40a2:4aff:feb4:7d31%6
. . . . . . . . . . . . … . . . . . . . 192.168.192.165
在得到主机的IP地址后,分别对三台虚拟机node01、node02、node03进行修改
例如我的IP为192.168.192.175,则修改以下内容:
node01中的ifcfg-enp0s3文件中IPADDR=192.168.192.176
node02中的ifcfg-enp0s3文件中IPADDR=192.168.192.177
node03中的ifcfg-enp0s3文件中IPADDR=192.168.192.178
node02和node03中的GATEWAY=192.168.192.1
修改配置文件 ifcfg-enp0s3
[root@node01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
[root@node01 ~]# systemctl restart network
[root@node02 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
[root@node02 ~]# systemctl restart network
[root@node03 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
[root@node03 ~]# systemctl restart network
更新配置 systemctl restart network
注意node01没有GATEWAY,node02,node03有GATEWAY
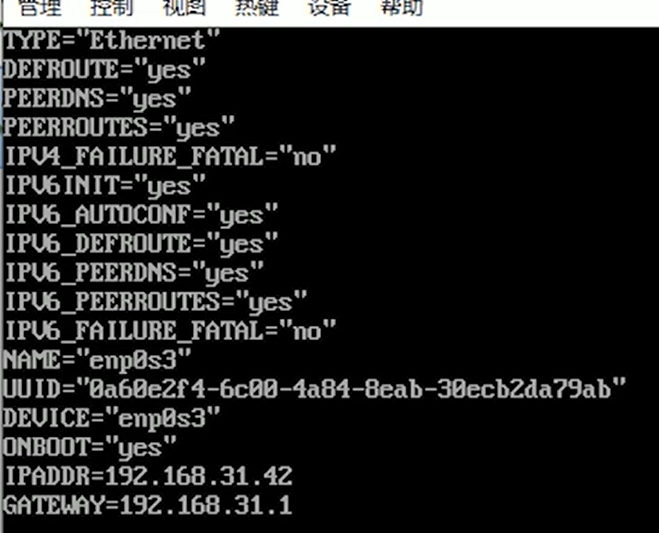
设置完成后,建议一次搞定接下来的操作,不然当主机IP地址改变了,三台虚拟机就连接不上了
解决方法1:
解决方法2:
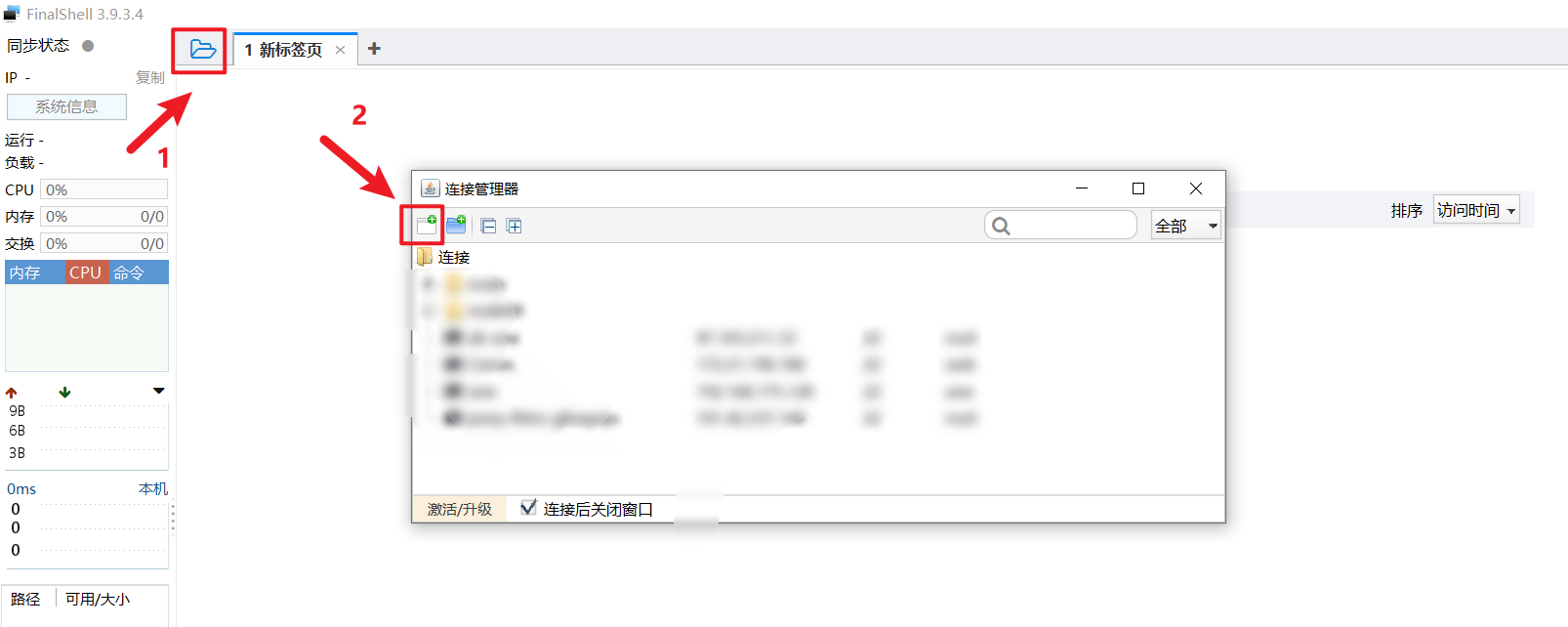
这里使用 FinalShell SSH连接虚拟机
node01配置如下, node02和node03同理
wget https://github.com/Mtlpc/automaticDeploy/archive/master.zip
这条命令在虚拟机上运行可能会有问题
建议直接去github下载 https://github.com/Mtlpc/automaticDeploy
在文章开头部分我也给了网盘下载链接
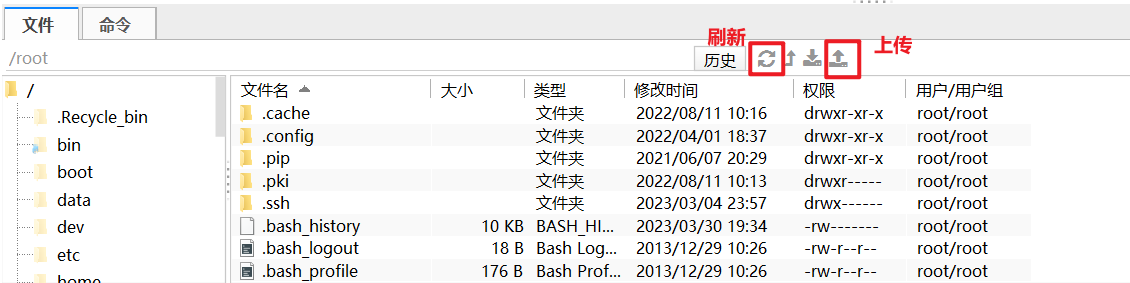
(直接去下载然后上传到node01的/home/hadoop/路径下, 如果你使用的是 FinalShell 可以直接上传,如果使用的是Xshell, 则需安装上传组件lrzsz, 安装方法在下一节)
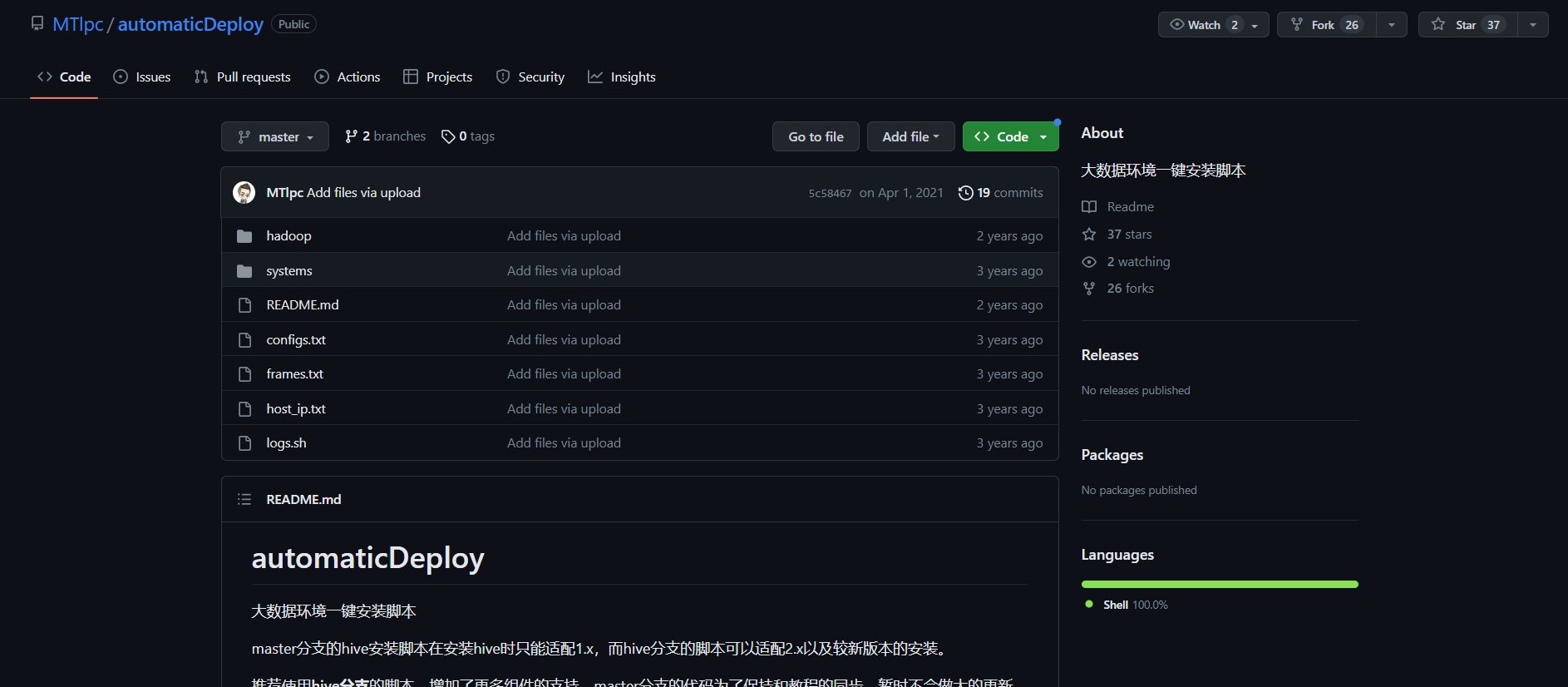
点击 <>Code,然后Download Zip, 下载下来的文件名称为 automaticDeploy-master.zip
将下载好的文件上传到 /home/hadoop 下并解压,解压后文件夹名为 automaticDeploy-master,将解压后的文件名改成 automaticDeploy,否则运行会报错
注:如果文件夹名多了master后缀或者是其他的名字,请重命名为automaticDeploy
注:如果使用finalShell 文件上传组件栏没有显示上传好的文件,请刷新一下
以下是 automaticDeploy 中的文件
[root@node01 ~]# mkdir /home/hadoop/
[root@node01 ~]# cd /home/hadoop/
# 这里需要将automaticDeploy-master.zip上传到/home/hadoop/目录下,然后再进行解压
# 注意:解压后文件夹名为 automaticDeploy-master,需要使用mv命令重命名为 automaticDeploy
[root@node01 hadoop]# unzip automaticDeploy.zip
# 给予可执行权限
[root@node01 hadoop]# chmod +x /home/hadoop/automaticDeploy/hadoop/* /home/hadoop/automaticDeploy/systems/*
# automaticDeploy文件夹下内容
[root@node01 hadoop]# ls automaticDeploy/
configs.txt frames.txt hadoop host_ip.txt logs.sh README.md systems
以下为 automaticDeploy文件夹下的主要内容:
configs.txt 文件内容如下(这个不用改):
# Mysql相关配置
mysql-root-password DBa2020* END
mysql-hive-password DBa2020* END
mysql-drive mysql-connector-java-5.1.26-bin.jar END
# azkaban相关配置
azkaban-mysql-user root END
azkaban-mysql-password DBa2020* END
azkaban-keystore-password 123456 END
!!!host_ip.txt 文件内容如下(这个需要自己手动修改):
这个需要配置成自己的3个node的ip,!这里的是未修改的!
192.168.31.41 node01 root 123456
192.168.31.42 node02 root 123456
192.168.31.43 node03 root 123456
farames.txt 文件内容如下(这个不用改):
# 通用环境
jdk-8u144-linux-x64.tar.gz true
azkaban-sql-script-2.5.0.tar.gz true
# Node01
hadoop-2.7.7.tar.gz true node01
# Node02
mysql-rpm-pack-5.7.28 true node02
azkaban-executor-server-2.5.0.tar.gz true node02
azkaban-web-server-2.5.0.tar.gz true node02
presto-server-0.196.tar.gz true node02
# Node03
apache-hive-1.2.1-bin.tar.gz true node03
apache-tez-0.9.1-bin.tar.gz true node03
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz true node03
yanagishima-18.0.zip true node03
# Muti
apache-flume-1.7.0-bin.tar.gz true node01,node02,node03
zookeeper-3.4.10.tar.gz true node01,node02,node03
kafka_2.11-0.11.0.2.tgz true node01,node02,node03
如果不使用Xshell的话, 使用FinalShell就可以不用安装, FinalShell自带文件上传组件
# 命令 rz :运行该命令会弹出一个文件选择窗口,从本地选择文件上传到服务器(receive)
# 命令 sz :将选定的文件发送(send)到本地机器
[root@node01 automaticDeploy]# yum install lrzsz -y
上传 frames.zip 压缩包到 ~ 目录下(即/root)
frames.zip 在文章开头有给出下载链接
[root@node01 ~]# cd ~
# 这里需要将frames.zip上传到 ~ 目录(即/root)下,然后再进行解压
[root@node01 ~]# unzip frames.zip -d /home/hadoop/automaticDeploy/
# 注意这里的 IP 需要改成自己设置的node节点IP
[root@node01 ~]# ssh root@192.168.192.177 "mkdir /home/hadoop"
[root@node01 ~]# ssh root@192.168.192.178 "mkdir /home/hadoop"
修改 automaticDeploy 文件夹下的 host_ip.txt 文件, 修改结果如下:
!!!这个需要配置成自己的3个node的ip!!!
192.168.192.176 node01 root 123456
192.168.192.177 node02 root 123456
192.168.192.178 node03 root 123456
将 automaticDeploy 通过scp命令拷贝到 node02 ,node03
注意:这里分别是node02和node03的IP地址
# 将修改后的automaticDeploy复制到node02,node03
[root@node01 hadoop]# scp -r /home/hadoop/automaticDeploy/ root@192.168.192.177:/home/hadoop/
[root@node01 hadoop]# scp -r /home/hadoop/automaticDeploy/ root@192.168.192.178:/home/hadoop/
拷贝完成后, 可以去 node02 , node03 上的 /home/hadoop/ 路径下进行确认
恭喜你完成了以上操作, 到这一步正式开始环境搭建
!!! 注意:在三台虚拟机上运行 ./batchOperate.sh 都是需要网络的 ,都是需要下载依赖包的
!!! 注意:运行 ./batchOperate.sh时,需要联网下载依赖包 expect 和 tcl
!!! 否则,执行./installAzkaban.sh安装Azkaban的时候,会出问题,会导致keystore无法生成,
!!! 特别是在Node02和Node03上,这两个有一定概率会没有网络,
解决方法在下一篇博客:【入门精讲】数据仓库实战——在 Node02 和 Node03 上没有网络的解决方法
# 分别在node01,node02,node03运行批处理脚本 batchOperate.sh 进行初始化
# 更新yum源, 免密钥登入,安装JDK,配置HOST
# node01
[root@node01 ~]# cd /home/hadoop/automaticDeploy
[root@node01 automaticDeploy]# cd systems/
[root@node01 systems]# ./batchOperate.sh
# node02
[root@node02 ~]# cd /home/hadoop/automaticDeploy/systems/
[root@node02 systems]# ./batchOperate.sh
# node03
[root@node03 ~]# cd /home/hadoop/automaticDeploy/systems/
[root@node03 systems]# ./batchOperate.sh
验证三台虚拟机是否能够互相免密连接
注意: 每连完一台虚拟机后都要退出, 然后再连接另一台
注:如果不能连接成功,请自行查看 host_ip.txt是否修改,./batchOperate.sh是否运行
# 分别SSH另外两台虚拟机, exit 退出SSH
# 退出示例: [root@node02 ~]# exit
# node01
[root@node01 systems]# ssh node02
[root@node01 systems]# ssh node03
# node02
[root@node02 systems]# ssh node01
[root@node02 systems]# ssh node03
# node03
[root@node03 systems]# ssh node01
[root@node03 systems]# ssh node02
脚本免密登录失败的话,可以手动进行免密登录操作
# 脚本免密登录失败的话,可以手动进行免密登录操作
# 以下为示例
[root@node01 ~]# ssh-copy-id node02
分别在三台虚拟机上依次执行
在 /home/hadoop/automaticDeploy/hadoop 路径下
[root@node01 hadoop]# ./installHadoop.sh
[root@node02 hadoop]# ./installHadoop.sh
[root@node03 hadoop]# ./installHadoop.sh
安装完成后, 更新环境变量
[root@node01 hadoop]# source /etc/profile
[root@node02 hadoop]# source /etc/profile
[root@node03 hadoop]# source /etc/profile
在 node01 上初始化 hadoop, hadoop namenode -format只能执行一次,多次运行的话,出问题
!注意:只在node01上运行
[root@node01 hadoop]# hadoop namenode -format
在 node01 上启动 hadoop 集群
注意:只在node01上运行
[root@node01 ~]# start-all.sh
jps查看是否运行成功, node01上会有6个进程
[root@node01 ~]# jps
6193 NameNode
6628 SecondaryNameNode
7412 Jps
6373 DataNode
6901 ResourceManager
7066 NodeManager
node02进程
[root@node02 ~]# jps
5952 NodeManager
6565 Jps
5644 DataNode
node03进程
[root@node03 ~]# jps
6596 Jps
5594 DataNode
5902 NodeManager
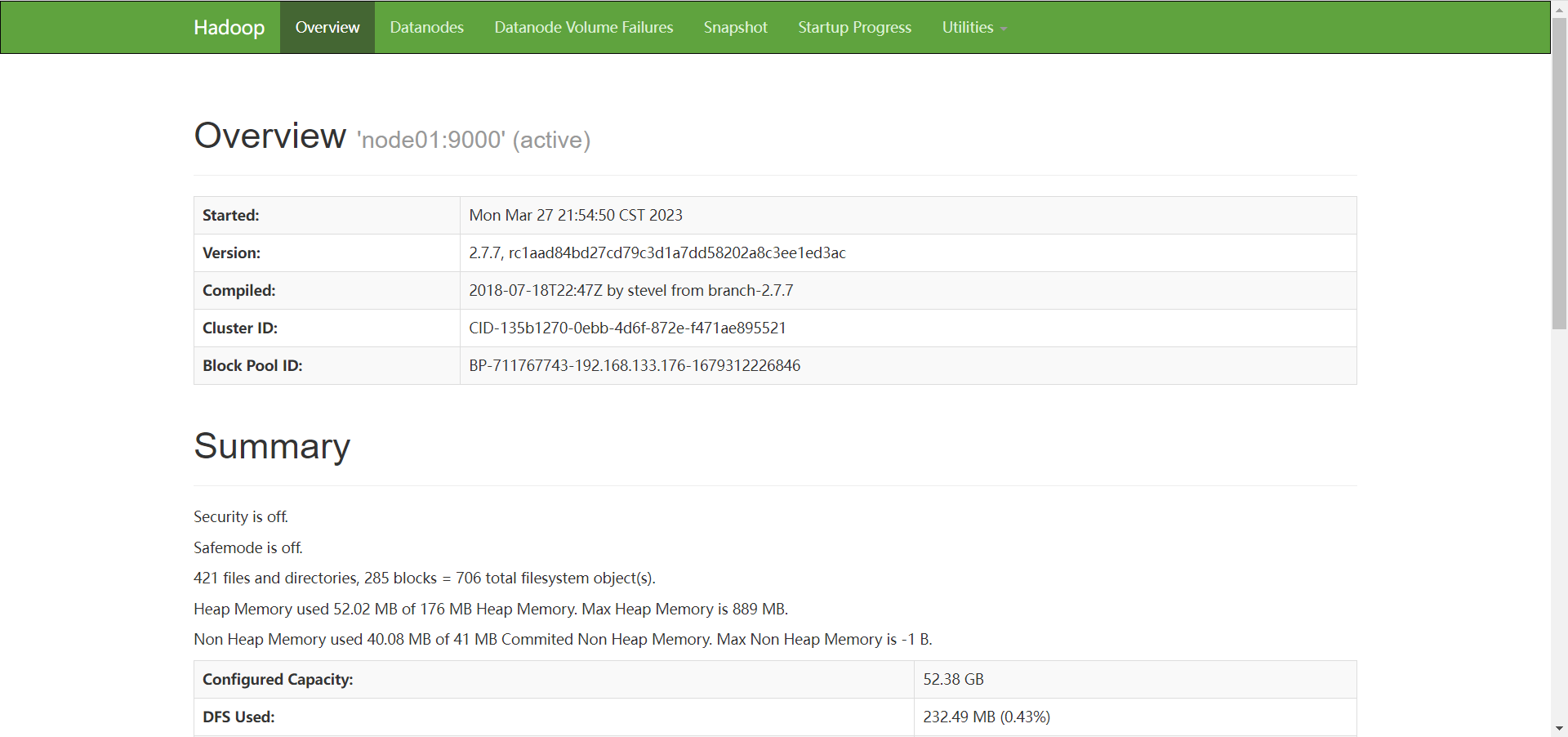
进行到这一步, hadoop已经安装成功,并且成功运行
可以打开浏览器,访问 node01 的 50070 端口, 进入hadoop的web界面
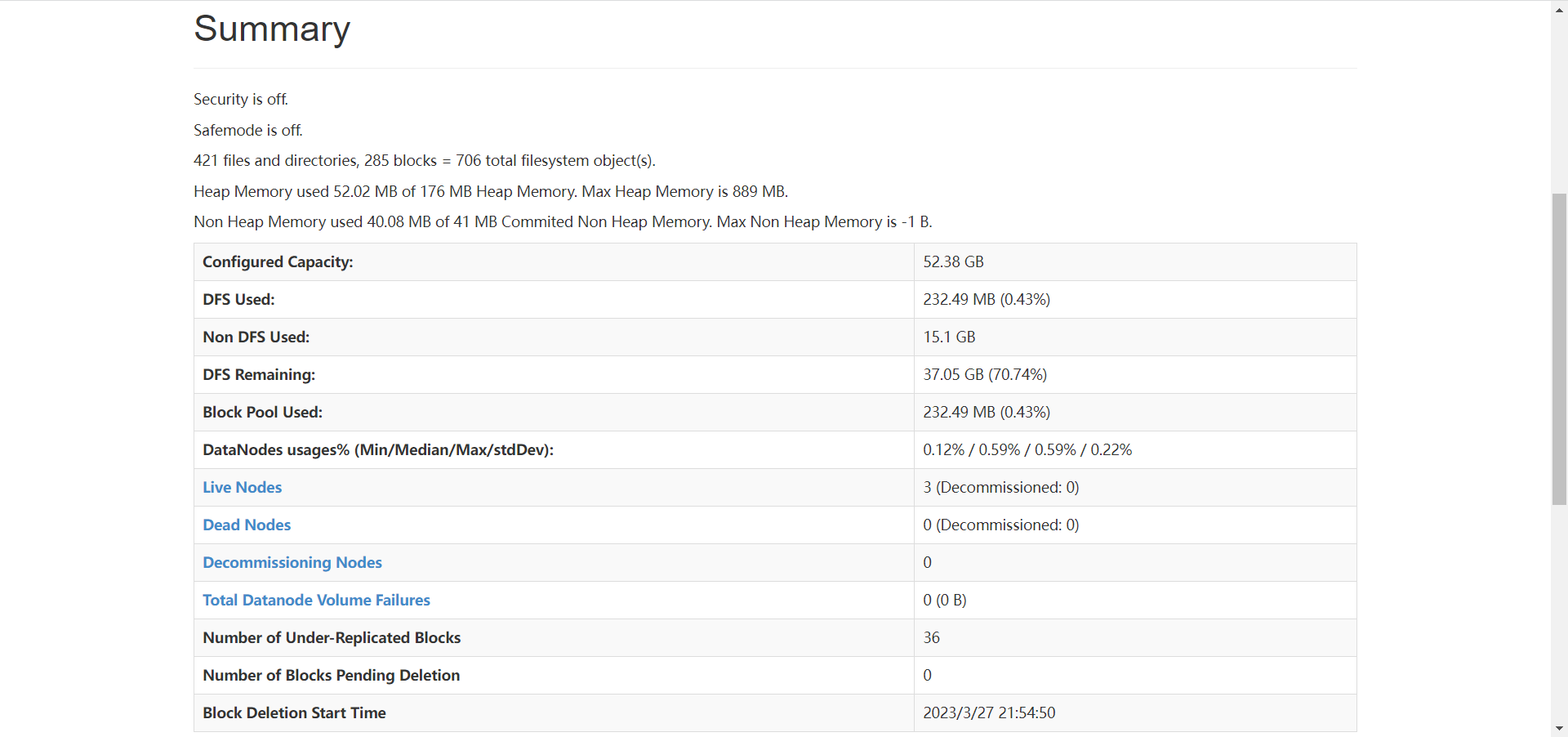
在 node02 上安装 MYSQL
[root@node02 hadoop]# ./installMysql.sh
MYSQL安装成功后, 运行MYSQL
[root@node02 hadoop]# mysql -uroot -pDBa2020*
mysql> show databases;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| azkaban |
| hive |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.01 sec)
mysql> exit;
在 node03 上安装 Hive, 安装过程会自动安装 Tez
[root@node03 hadoop]# ./installHive.sh
如果是INFO信息报错, 可以不用管
接着在 node03 上安装 Sqoop
[root@node03 hadoop]# ./installSqoop.sh
[root@node03 hadoop]# source /etc/profile
分别在node01,node02, node03 上安装 Presto
Presto服务端口为8080
# Presto服务端口为8080
[root@node01 hadoop]# ./installPresto.sh
[root@node02 hadoop]# ./installPresto.sh
[root@node03 hadoop]# ./installPresto.sh
接着分别在node01,node02, node03上安装Azkaban
[root@node01 hadoop]# ./installAzkaban.sh
[root@node02 hadoop]# ./installAzkaban.sh
[root@node03 hadoop]# ./installAzkaban.sh
为Presto安装一个插件,带来可视化的效果
Yanagishima服务端口为7080
# Yanagishima服务端口为7080
[root@node03 hadoop]# ./installYanagishima.sh
分别在node01,node02,node03上更新环境变量
# 分别在node01,node02,node03运行更新环境变量
[root@node01 hadoop]# source /etc/profile
[root@node02 hadoop]# source /etc/profile
[root@node03 hadoop]# source /etc/profile

创建数据库mall
# 导入临时环境变量
[root@node02 hadoop]# export MYSQL_PWD=DBa2020*
[root@node02 hadoop]# mysql -uroot -e "create database mall;"
进入到 /home 目录下
[root@node02 hadoop]# cd ~
上传生成数据脚本到 /root/路径下
数据生成脚本下载链接在文章开头

将数据生成脚本上传到数据库中
[root@node02 ~]# mysql -uroot mall < /root/1建表脚本.sql
[root@node02 ~]# mysql -uroot mall < /root/2商品分类数据插入脚本.sql
[root@node02 ~]# mysql -uroot mall < /root/3函数脚本.sql
[root@node02 ~]# mysql -uroot mall < /root/4存储过程脚本.sql
[root@node02 ~]# mysql
mysql> use mall;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> CALL init_data('2020-08-29',300,200,300,False);
Query OK, 0 rows affected (0.69 sec)
mysql> select count(1) from user_info;
+----------+
| count(1) |
+----------+
| 200 |
+----------+
1 row in set (0.00 sec)
mysql> show tables;
+----------------+
| Tables_in_mall |
+----------------+
| base_category1 |
| base_category2 |
| base_category3 |
| order_detail |
| order_info |
| payment_info |
| sku_info |
| user_info |
+----------------+
8 rows in set (0.00 sec)
mysql> exit;
生成了300个订单, 200个用户, 300个商品,False不删除数据
[root@node03 ~]# mkdir -p /home/warehouse/shell
[root@node03 shell]# cd /home/warehouse/shell/
# 上传sqoop_import.sh脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim sqoop_import.sh
[root@node03 shell]# chmod +x sqoop_import.sh
[root@node03 shell]# ./sqoop_import.sh all 2020-08-29
运行成功会看见 job_001 —— job_008共8个job任务
注:如果是多次运行的话,job后面的编号会累加
注意:运行./sqoop_import.sh all 2020-08-29可能会遇到报错
/bin/bash^M: 坏的解释器: 没有那个文件或目录
运行 sed ‘s/\r//’ -i sqoop_import.sh
或者 :
使用 vim 重新编辑脚本
在底行模式下输入 set ff=unix 然后回车
运行成功后:网页可视化查看数据是否导入 http://192.168.192.176:50070/
点击Utilitles 进入 Browse the file system
然后进入 /origin_data/mall/db下
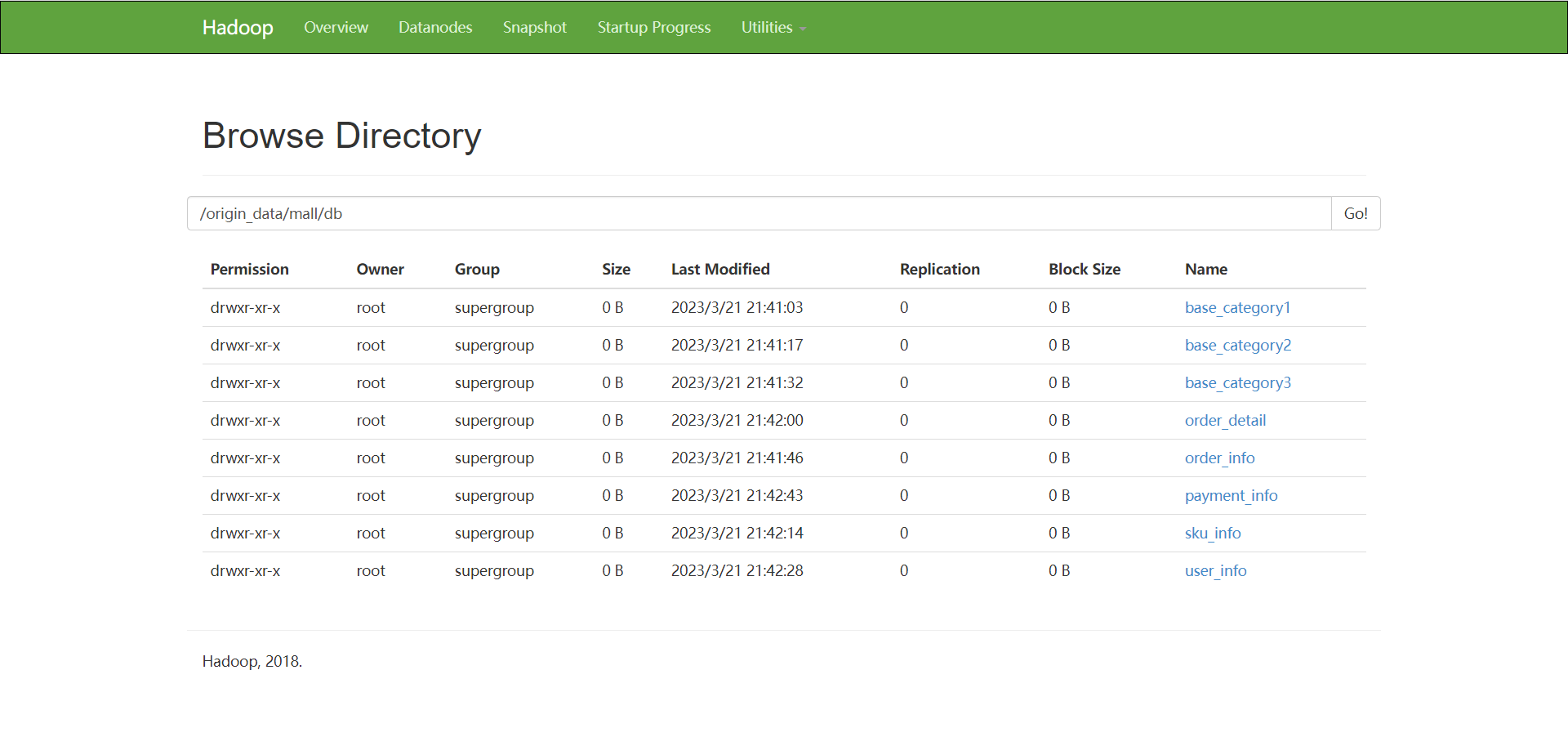
一共是8张表, 如果没有8张表的话, 多运行 ./sqoop_import.sh all 2020-08-29 命令几次,直至有8张表,
每张表都点进去到最里面,会出现 SUCCESS
导致没有8张表的原因:虚拟机性能不够,内存不够
到这里,表示我们ETL任务已经成功了
启动Hive
# 启动Hive 的 hiveserver2
[root@node03 shell]# hive --service hiveserver2 &
如果停止不动的话,回车
启动Hive的metastore服务
# 启动Hive的metastore
[root@node03 shell]# hive --service metastore &
如果停止不动的话,回车
如果这里报错 拒绝连接 , MSQL拒绝连接, 可能由于网络不通畅的问题引起, 在node03上试一下能不能连接到node02 , 连接不了的话可以重启 node02 的网络服务, systemctl restart network
[root@node02 ~]# systemctl restart network
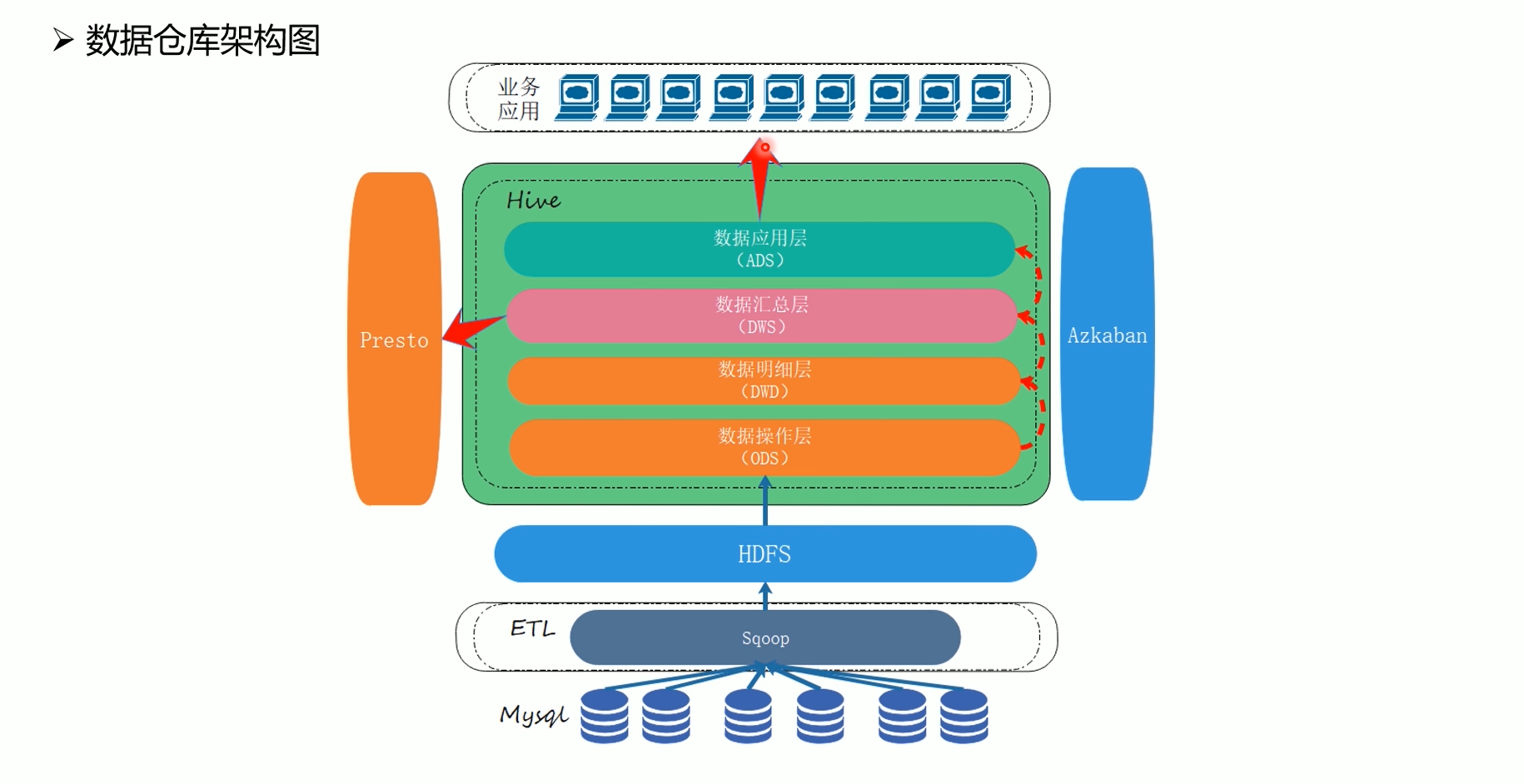
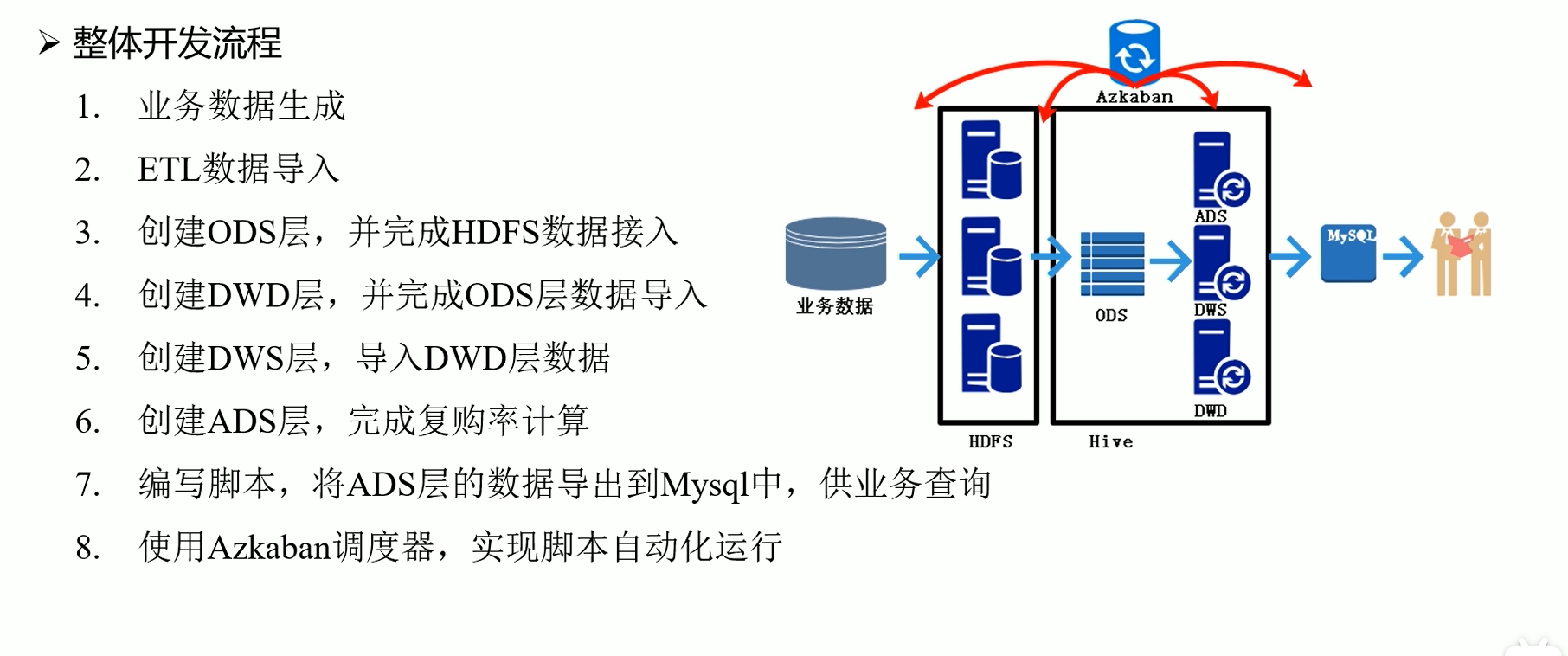
ODS层创建&数据导入
# ODS层创建&数据导入
[root@node03 ~]# cd /home/warehouse
[root@node03 warehouse]# mkdir sql/
[root@node03 warehouse]# cd sql/
# 上传ods_ddl.sql脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 sql]# vim ods_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/ods_ddl.sql
如果停止不动的话,回车
执行成功的话直接跳到下一步
如果很长时间都没有出结果, 可以 Ctrl + c 终止,然后查看刚刚Hive进行的两个服务
[root@node03 sql]# jps
2378 NodeManager
2133 DataNode
7288 RunJar
7210 RunJar
7646 Jps
# 如果出现以下内容
[root@node03 sql]# jps -m
.
.
.
7288 RunJar .... /... /... / ....... / hadoop.hive.metastore.HiveMetaStore
.
.
.
# kill metastore服务
[root@node03 sql]# kill -9 7288
# 然后再重启 metastore, metasore服务需要连接mysql服务, 所以需要与node02网络通畅
[root@node03 sql]# hive --service metastore &
# 没有报错,重新执行 hive -f /home/warehouse/sql/ods_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/ods_ddl.sql
hive -f /home/warehouse/sql/ods_ddl.sql执行完后,进入Hive查看, 一共8张表
## 进入hive
[root@node03 shell]# hive
hive>use mall;
OK
Time taken: 0.55 seconds
hive>show tables;
OK
ods_base_category1
ods_base_category2
ods_base_category3
ods_order_detail
ods_order_info
ods_payment_info
ods_sku_info
ods_user_info
Time taken: 1.247 seconds, Fetched: 8 row(s)
hive>exit;
数据有了,然后完成数据的导入
[root@node03 shell]# cd ..
[root@node03 shell]# cd shell/
# 上传obs_db.sh脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim ods_db.sh
[root@node03 shell]# chmod +x ods_db.sh
[root@node03 shell]# ./ods_db.sh 2020-08-29
注意:运行./ods_db.sh 2020-08-29可能会遇到报错
/bin/bash^M: 坏的解释器: 没有那个文件或目录
运行 sed ‘s/\r//’ -i ods_db.sh
或者 :
使用 vim 重新编辑脚本
在底行模式下输入 set ff=unix 然后回车
执行完成后,进入Hive查看数据是否导入
## 进入hive
[root@node03 shell]# hive
hive> use mall;
OK
Time taken: 0.55 seconds
hive> show tables;
hive> select count(1) from ods_user_info;
Query ID = root_20230327220623_2ce7b554-c007-4d37-b282-87a3227c2f16
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1679925264749_0002)
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
--------------------------------------------------------------------------------
Map 1 .......... SUCCEEDED 2 2 0 0 0 0
Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
--------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.56 s
--------------------------------------------------------------------------------
OK
200
Time taken: 9.383 seconds, Fetched: 1 row(s)
# 200条数据
hive> exit;
创建并执行dwd_ddl.sql
[root@node03 shell]# cd /home/warehouse/sql/
# 上传dws_ddl.sql脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 sql]# vim dwd_ddl.sql
[root@node03 warehouse]# hive -f /home/warehouse/sql/dwd_ddl.sql
创建并执行dwd_db.sh
[root@node03 shell]# cd /home/warehouse/shell/
# 上传dwd_db.sh脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim dwd_db.sh
[root@node03 shell]# chmod +x dwd_db.sh
[root@node03 shell]# ./dwd_db.sh 2020-08-29
执行完成后,进入Hive查看数据是否接入
## 进入hive
[root@node03 shell]# hive
hive>use mall;
hive> show tables;
OK
dwd_order_detail
dwd_order_info
dwd_payment_info
dwd_sku_info
dwd_user_info
dws_sale_detail_daycount
dws_user_action
ods_base_category1
ods_base_category2
ods_base_category3
ods_order_detail
ods_order_info
ods_payment_info
ods_sku_info
ods_user_info
Time taken: 0.25 seconds, Fetched: 15 row(s)
hive>select * from dwd_sku_info where dt='2020-08-29' limit 2;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
1005 809 897 yOBnLRZwkMelSEscgCqY WKMEMUmBWcwdaTrdsCJLJUIFaldKps 4.47 36 703 70 12 待产护理 妈妈专区 母婴 2020-08-29 14:55:39.0 2020-08-29
1009 283 3827 YEZiTSLYKJbooDbvZMMx cReVrXNVoJsRjsmifcWyCtmdDKOOED 0.83 69 928 98 16 汽修工具 维修保养 汽车用品 2020-08-29 21:11:59.02020-08-29
Time taken: 0.711 seconds, Fetched: 2 row(s)
hive> exit;
创建并执行dws_ddl.sql
# DWS层创建&数据接入 node03
[root@node03 shell]# cd /home/warehouse/sql/
# 上传dws_ddl.sql脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim dws_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/dws_ddl.sql
创建并执行dws_db.sh
[root@node03 sql]# cd ../shell/
# 上传dws_db.sh脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim dws_db.sh
[root@node03 shell]# chmod +x dws_db.sh
[root@node03 shell]# ./dws_db.sh 2020-08-29
执行完成后,进入Hive查看数据是否接入
[root@node03 shell]# hive
hive> use mall;
hive> show databases;
hive> select * from dws_user_action where dt="2020-08-29" limit 2;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
1 3 1593 2 665 2020-08-29
10 1 434 1 434 2020-08-29
Time taken: 0.35 seconds, Fetched: 2 row(s)
# !!! 注意这里的SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder不用管
hive> exit;
创建并执行ads_sale_ddl.sql
# ADS层复购率统计 node03
[root@node03 shell]# cd /home/warehouse/sql/
# 上传ads_sale_ddl.sql脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 sql]# vim ads_sale_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/ads_sale_ddl.sql
创建并执行ads_sale.sh
[root@node03 sql]# cd /home/warehouse/shell/
# 上传ads_sale.sh脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim ads_sale.sh
[root@node03 shell]# chmod +x ads_sale.sh
[root@node03 shell]# ./ads_sale.sh 2020-08-29
[root@node03 shell]# hive
hive> use mall;
hive> exit;
创建并执行mysql_sale.sql
# ADS层数据导入
# node02
[root@node02 ~]# mkdir -p /home/warehouse/sql
# 上传mysql_sale.sql脚本(所有脚本文件均有提供链接),或者手动编写
[root@node02 sql]# vim mysql_sale.sql
[root@node02 sql]# export MYSQL_PWD=DBa2020*
[root@node02 sql]# mysql -uroot mall < /home/warehouse/sql/mysql_sale.sql
[root@node02 sql]# mysql
mysql> use mall;
mysql> show tables;
+-------------------------------+
| Tables_in_mall |
+-------------------------------+
| ads_sale_tm_category1_stat_mn |
| base_category1 |
| base_category2 |
| base_category3 |
| order_detail |
| order_info |
| payment_info |
| sku_info |
| user_info |
+-------------------------------+
9 rows in set (0.00 sec)
mysql> exit;
创建并执行sqoop_export.sh
# node03
[root@node03 ~]# cd /home/warehouse/shell/
# 上传sqoop_export.sh脚本(所有脚本文件均有提供链接),或者手动编写
[root@node03 shell]# vim sqoop_export.sh
[root@node03 shell]# chmod +x sqoop_export.sh
[root@node03 shell]# ./sqoop_export.sh all
如果这里报错 拒绝连接 MYSQLIO的问题, 一般这个拒绝连接错误都是MYSQL的问题, 可能由于网络不通畅的问题引起, 重启 node02 的网络服务可以解决, systemctl restart network
# node02
[root@node02 sql]# systemctl restart network
查看数据是否能够导出
[root@node02 sql]# mysql -uroot -pDBa2020*
mysql> use mall;
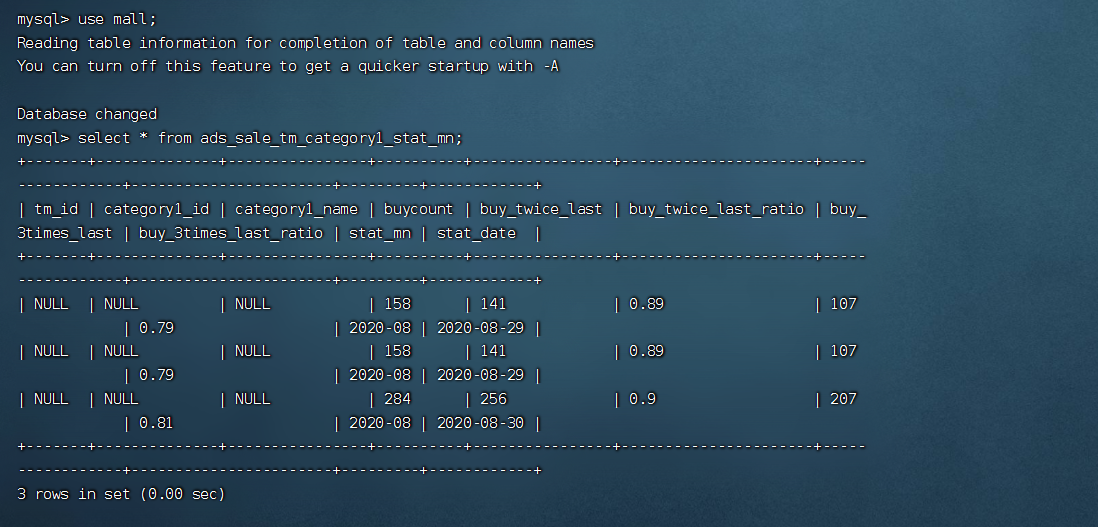
mysql> select * from ads_sale_tm_category1_stat_mn;
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
| tm_id | category1_id | category1_name | buycount | buy_twice_last | buy_twice_last_ratio | buy_3times_last | buy_3times_last_ratio | stat_mn | stat_date |
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
| NULL | NULL | NULL | 158 | 141 | 0.89 | 107 | 0.79 | 2020-08 | 2020-08-29 |
| NULL | NULL | NULL | 158 | 141 | 0.89 | 107 | 0.79 | 2020-08 | 2020-08-29 |
| NULL | NULL | NULL | 284 | 256 | 0.9 | 207 | 0.81 | 2020-08 | 2020-08-30 |
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
3 rows in set (0.00 sec)
mysql> exit;
Azkaban自动化调度, 生成数据
生成了300个订单, 200个用户, 300个商品,False不删除数据
# Azkaban自动化调度
# 生成数据
[root@node02 sql]# mysql -uroot -pDBa2020*
mysql> use mall;
mysql> CALL init_data('2020-08-30',300,200,300,FALSE);
Query OK, 0 rows affected (0.70 sec)
三个节点启动Azkaban
# 三个节点启动Azkaban
[root@node01 ~]# azkaban-executor-start.sh
[root@node02 ~]# azkaban-executor-start.sh
[root@node03 ~]# azkaban-executor-start.sh
[AzkabanExecutorServer] [Azkaban] Azkaban Executor Server started on port 12321
# azkaban出问题时,可以重启, 关闭命令如下
# 重启命令 azkaban-executor-shutdown.sh
启动Azkaban的web网页, 然后打开 https://192.168.192.178:8443/
# node03 启动Azkaban的web网页
# 准备mall_job.zip
[root@node03 shell]# cd /opt/app/azkaban/server/
[root@node03 server]# azkaban-web-start.sh
准备好mall_job.zip ,进入Azkaban的web网页,创建mall project, 上传 mall_job.zip
注意:
# https://192.168.192.178:8443/ # node03 注意这里是https
# Azkaban:
# 账号:admin
# 密码:admin
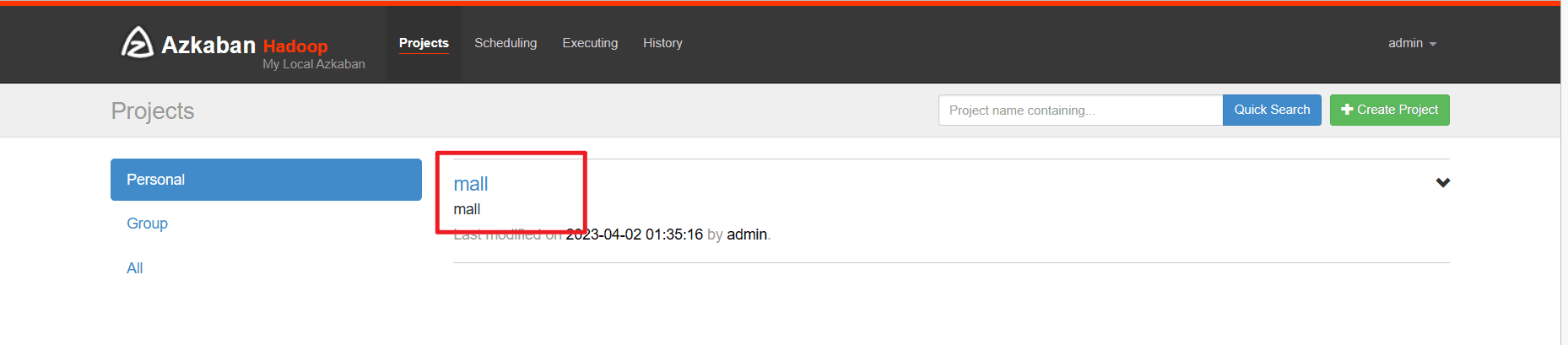
# 创建project mall
# 设置参数 dt 2020-08-30
# 设置参数 useExecutor node03
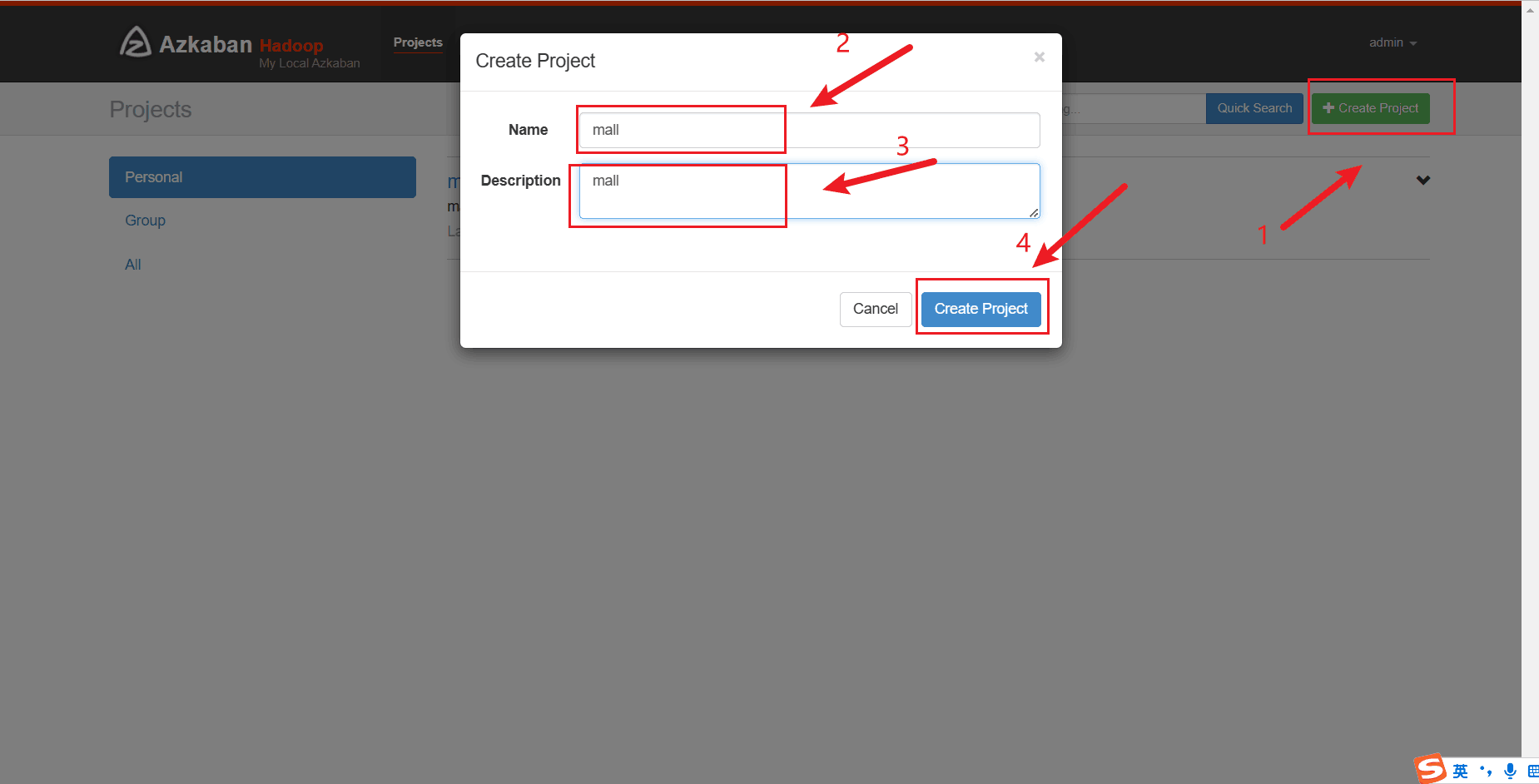
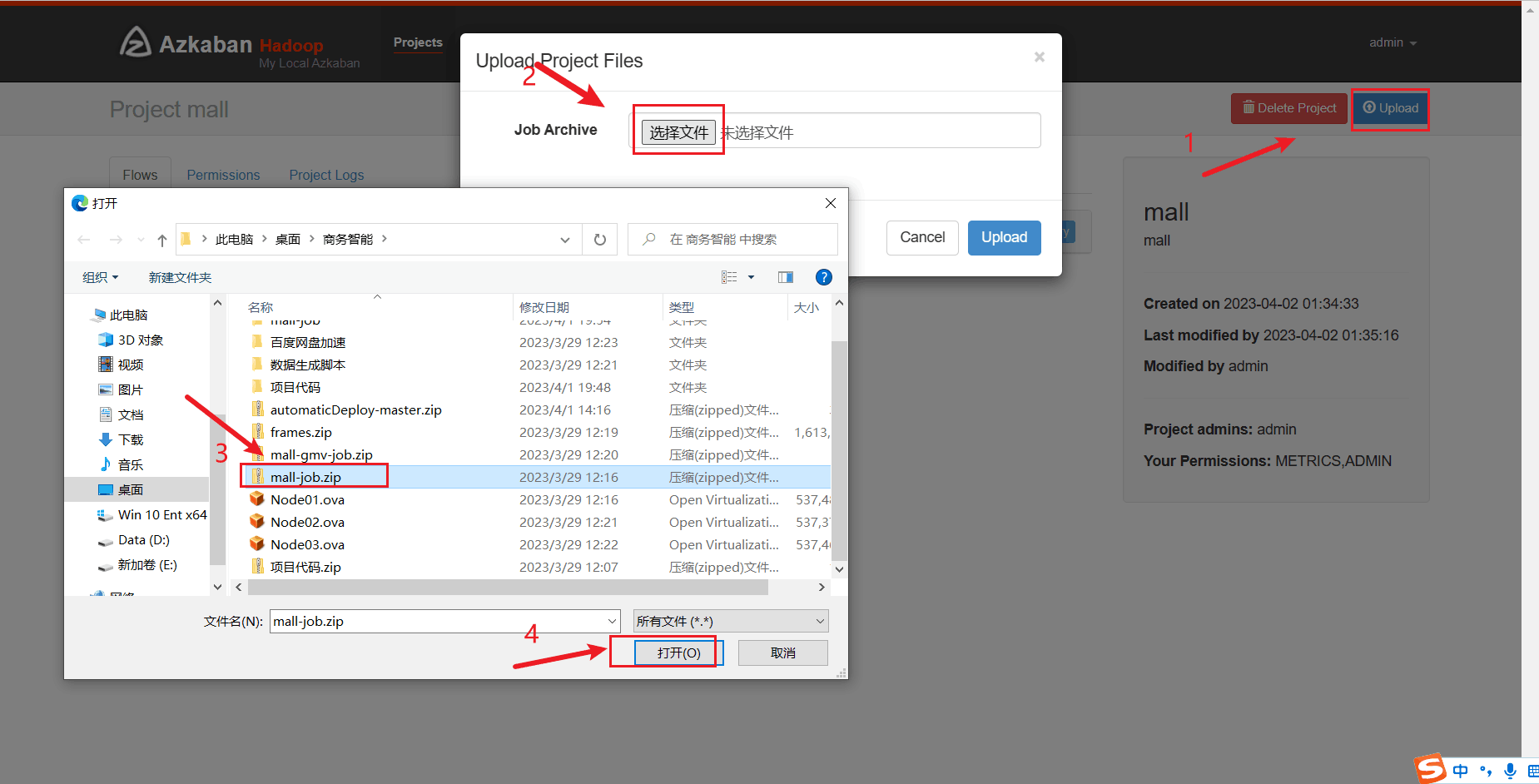
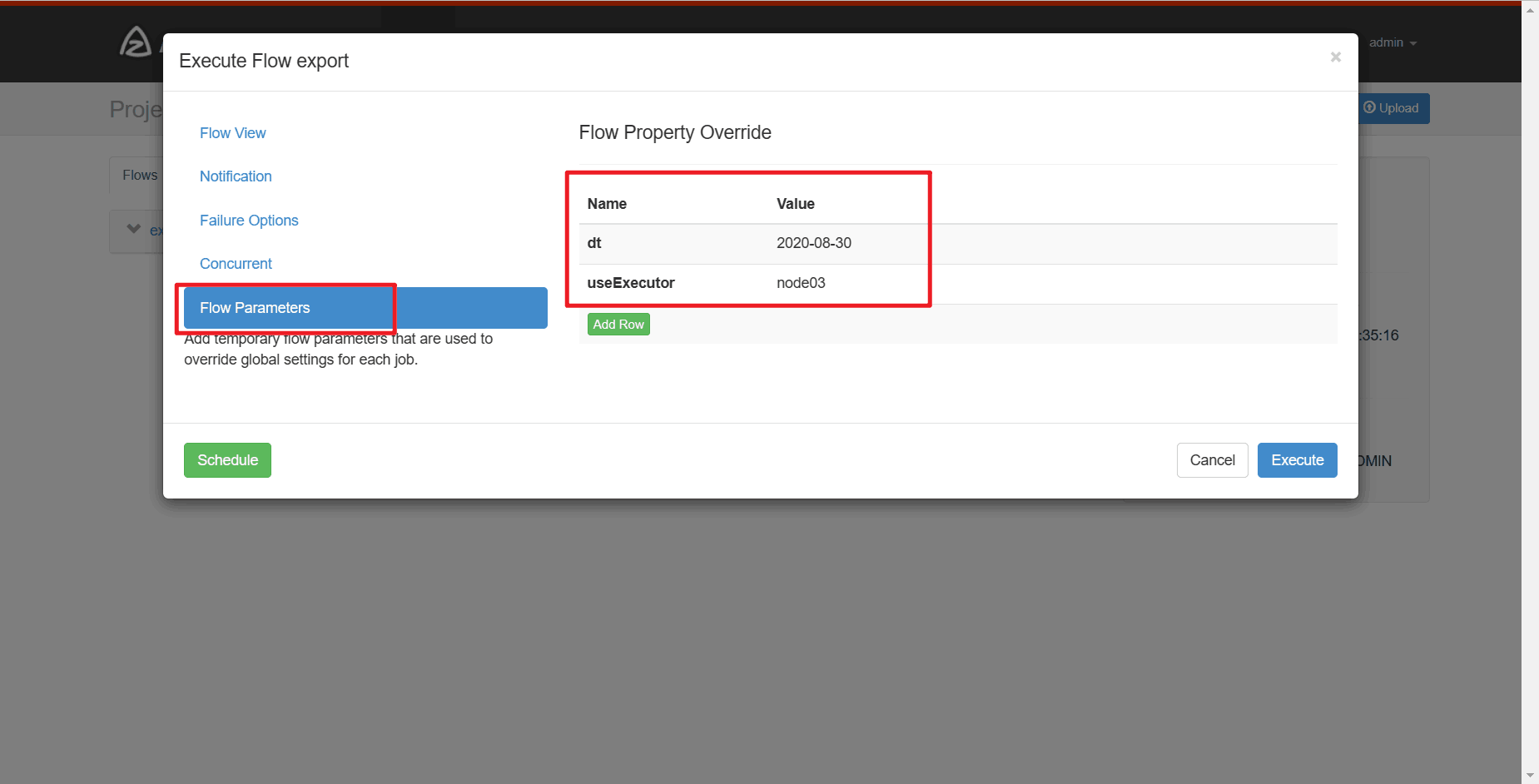
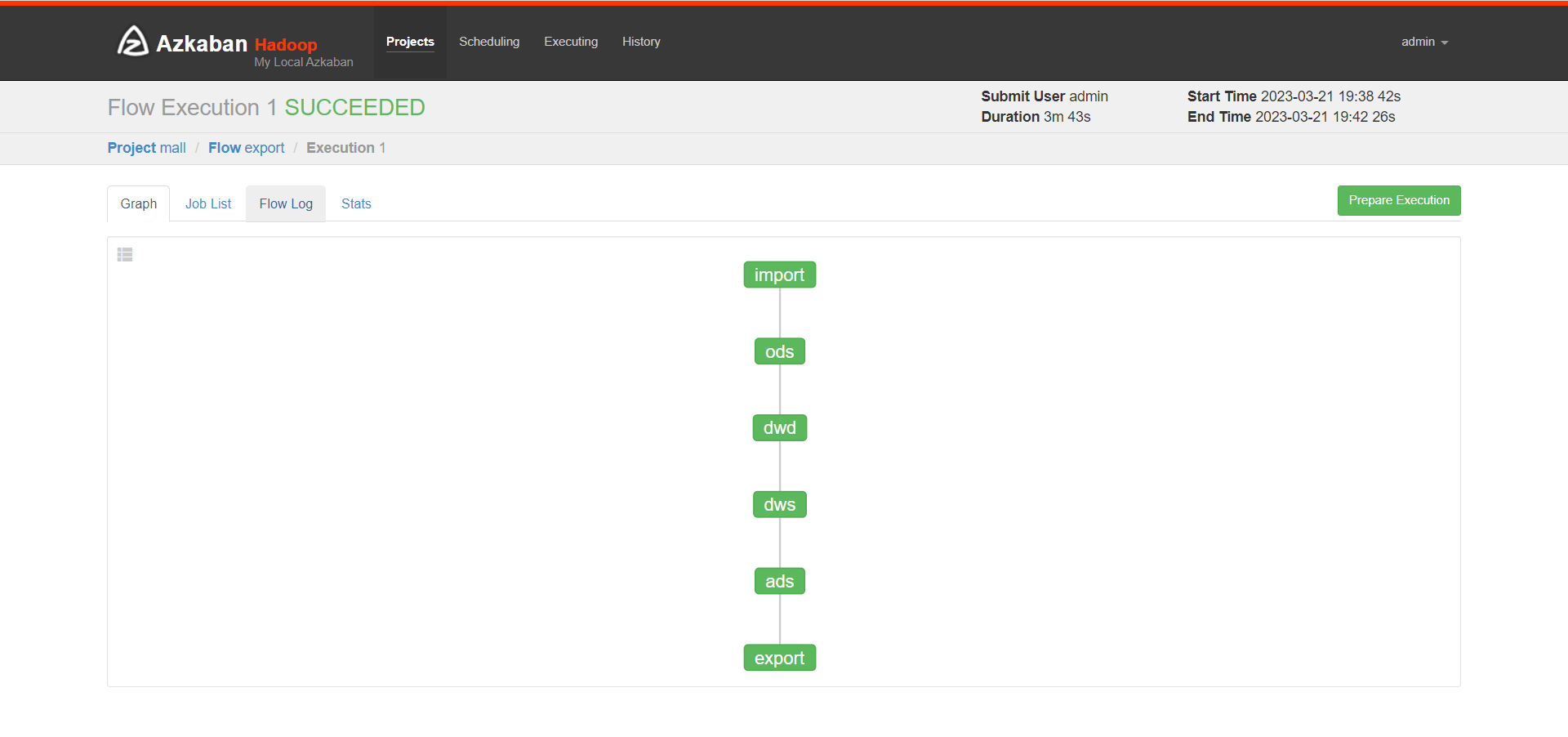
# 等自动化调度任务执行完后
# 到node02查看执行情况,新建一个node02连接终端
[root@node02 ~]# mysql -uroot -pDBa2020*
mysql> use mall;
mysql> select * from ads_sale_tm_category1_stat_mn;

# 更改虚拟机静态IP地址
# 更改host_ip.txt
cd /home/hadoop/automaticDeploy/
vim host_ip.txt
systemctl restart network
source /etc/profile
# 网络不通畅时,运行 systemctl restart network 重启网卡
# 修改虚拟机IP, vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
# http://192.168.192.176:50070/ # hadoop Web可视化网页 运行在node01上
# https://192.168.192.178:8443/ # Azkaban web可视化网页 运行在node03上 注意这里是https
# http://192.168.192.176:8088/ # hadoop 另一个可视化页面 运行在node01上
# Azkaban:
# 账号:admin 密码:admin
# 创建project mall
# 设置参数 dt 2020-08-30
# 设置参数 useExecutor node03
# !!!初始化(格式化)hadoop,最开始的时候执行一次就行,不要多次执行 !!!
# !!!如果是安好教程一步一步来的话,这里不要执行!!!
# !!!这里不要执行
[root@node01 hadoop]# hadoop namenode -format
# 初始化过从这里开始
# 启动hadoop集群
[root@node01 ~]# start-all.sh
# 启动Hive 的 hiveserver2
[root@node03 shell]# hive --service hiveserver2 &
# 启动Hive 的 metastore
[root@node03 shell]# hive --service metastore &
# 生成数据 生成过就不用生成了
[root@node02 sql]# mysql -uroot -pDBa2020*
mysql> use mall;
mysql> CALL init_data('2020-08-30',300,200,300,FALSE);
# 生成了300个订单, 200个用户, 300个商品,False不删除数据
# 准备好mall_job.zip
# 三个节点启动Azkaban
[root@node01 ~]# azkaban-executor-start.sh
[root@node02 ~]# azkaban-executor-start.sh
[root@node03 ~]# azkaban-executor-start.sh
[AzkabanExecutorServer] [Azkaban] Azkaban Executor Server started on port 12321
# azkaban出问题时,可以重启, 关闭命令如下
# 重启命令 azkaban-executor-shutdown.sh
# node03 启动Azkaban的web网页
[root@node03 shell]# cd /opt/app/azkaban/server/
[root@node03 server]# azkaban-web-start.sh
# https://192.168.192.178:8443/ # node03 注意这里是https
# Azkaban:
# 账号:admin
# 密码:admin
# 创建project mall
# 设置参数 dt 2020-08-30
# 设置参数 useExecutor node03
欢迎大家在搭建数据仓库的遇到的问题在评论区下方提出,也可以补充在下面
相应问题及解决方法:https://blog.csdn.net/qq_56870570/article/details/120182874
重启网络 systemctl restart network
systemctl restart network失败软件问题,请使用Virtual box
所提供的OVA镜像中是由两个网卡,网卡1:桥接网卡,网卡2:网络地址转换NAT
VMware中默认只有一个网卡,将OVA镜像文件导入后可能有问题
解决方法博客连接:在 Node02 和 Node03 上没有网络 使用 ping www.baidu.com也无法ping通 的解决方法
多次重新初始化hadoop namenode -format后,DataNode或NameNode没有启动
解决方法博客连接:不小心多次运行 hadoop namenode -format,DataNode或NameNode没有启动
作者:Oraer
都看到最后了,不点个赞+收藏吗?
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun