大家好,我是Bryce。
这次和大家分享机器学习涉及到的内容——分类器性能评估,包括准确率、精确率、召回率、PR曲线、ROC曲线等。
准确率并不是一个很好的分类器性能指标,尤其是当处理的数据集存在偏差时(一些类比其他类多得多)。比如有9个苹果和1个香蕉,那我猜测10个都不是香蕉的准确率也高达90%。
在Python中,准确率指标可以使用cross_val_score()函数评估,同时使用K折交叉验证。具体形式如下,其中,cv=3表示3折。
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring='accuracy')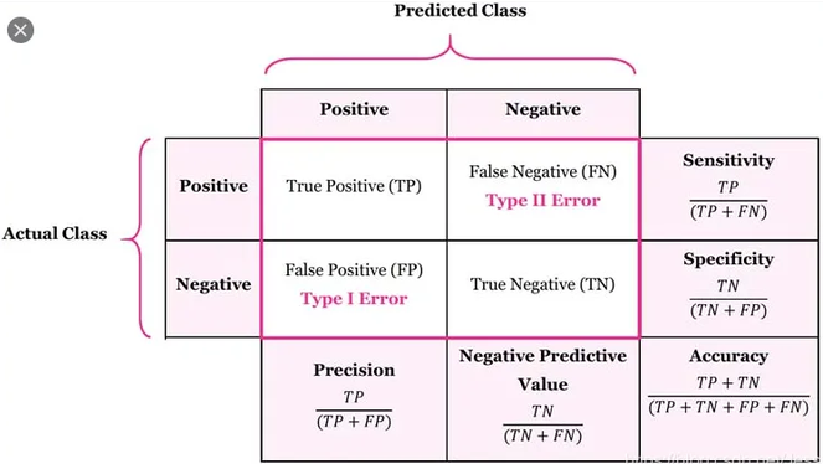
如上图所示,混淆矩阵每一行代表一个实际的结果,每一列代表一个预测的结果。分别有TP、FN、FP、TN四种结果,有Accuracy(准确率)、Precision(精确率)、Sensitivity(召回率或灵敏度)、Specificity(特异度)和Negative Predictive Value(反例预测率)5种衡量指标,它们的计算公式如上图。
还是以苹果、香蕉举例子(苹果为正例,香蕉为反例):
Accuracy(准确率):不管正负例,预测对的占多少。
Precision(精确率):找了这么多正例,找对了多少。
Sensitivity(召回率):有这么多正例,找出了多少。
在Python中计算混淆矩阵比较简单,如下:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train, y_train_pred)其中,y_train表示训练值,y_train_pred表示预测值。
衡量指标中用的比较多的是精确率和召回率,它们的值可以在计算出混淆矩阵后,按照上图公式计算,也可以直接调用对应的函数。
from sklearn.metrics import precision_score, recall_score
precision_score(y_train, y_train_pred)
recall_score(y_train, y_train_pred)其中,precision_score表示精确率,recall_score表示召回率。
F1值结合了精确率和召回率,是它们的调和平均。普通的平均值平等看待所有值,而调和平均会给小的值更大的权重。要想获得一个高的F1值,精确率和召回率要同时高。
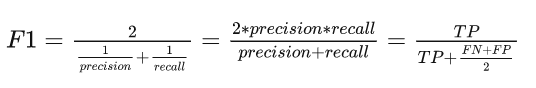
from sklearn.metrics import f1_score
f1_score(y_train, y_train_pred)精确率和召回率之间存在一种折中关系,提高精确率会降低召回率。到底需要较高的精确率还是较高的召回率,不能一概而论,具体场景具体分析。需要找得对就需要高的精确率,也就是想要的一定是好的;不想把想要的漏掉太多,就需要较高的召回率。
某模型的精确率、召回率与阈值的关系曲线如下,横坐标表示算法判断的阈值(大于阈值为正,否则为负):
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train, y_scores) # y_scores是决策分数,不是预测值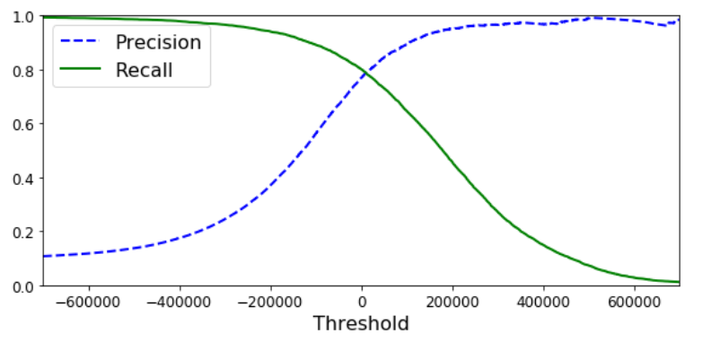
从图中就可以看出精确率和召回率之间的博弈关系。
仔细看我们会发现,召回率曲线比较平滑,而精确率曲线在性能较高时会有波动,这表示提高阈值,精确率并不一定会提高。
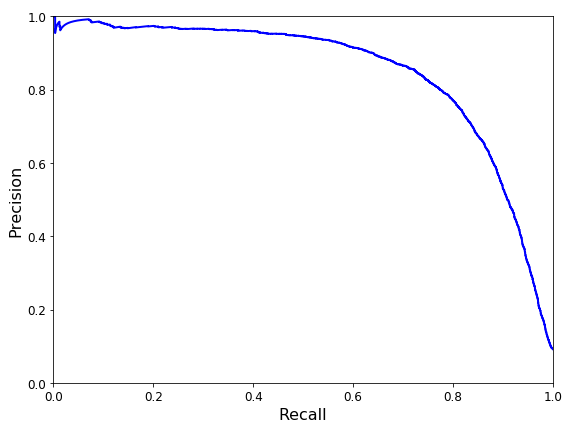
精确率和召回率之间的关系曲线(PR曲线)如下:
ROC曲线横坐标为FPR(伪正例率),纵坐标为TPR(真正例率,也即召回率),其中FPR=1-TNR,TNR就是特异性。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train, y_scores)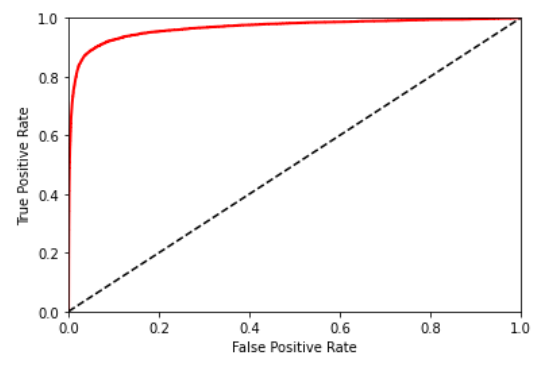
一个评估分类器好坏的方法是:计算ROC曲线下的面积,roc_auc_score()可实现。面积越大,性能越好,从图来看,就是更靠近左上角。(PR曲线应该尽可能的靠近右上角)
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train, y_scores)PR曲线还是ROC曲线?
当正例非常少或者你更关注伪正例(FP)而不是伪反例(FN)时,你应该选择PR曲线, 反之则是ROC曲线。
本文转载自微信公众号「且听数据说」,作者「Bryce」,可以通过以下二维码关注。

转载本文请联系「且听数据说」公众号。
点向量坐标矩阵的几何意义介绍旋转矩阵的几何含义之前,先介绍一下点向量坐标矩阵的几何含义点:在一维空间下就是一个标量,如同一条直线上,以任意某一个位置为0点,以一定的尺度间隔为1,2,3...,相反方向为-1,-2,-3...;如此就形成了一维坐标系,这时候任何一个点都可以用一个数值表示,如点p1=5,即即从原点出发沿着x轴正方向移动5个尺度;点p2=-3,负方向移动3个尺度; 在一维坐标系上过原点做垂直于一维坐标系的直线,则形成了二维坐标系,此时描述一个点需要两个数值来表示点p3=(3,2),即从原点出发沿着x轴正方向移动3个尺度,在此基础上沿着y轴正方向移动两个尺度的位置就是点p3。
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我在Ruby程序中有两个URI。一个肯定是绝对URI,另一个可能是绝对URI或相对URI。我想在第一个的上下文中将第二个转换为绝对URI,所以如果第一个是http://pupeno.com/blog第二个是/about,结果应该是http://pupeno.com/about.有什么想法吗? 最佳答案 Ruby的内置URI和Addressablegem,做这个简短的工作。我更喜欢Addressable,因为它功能更全面,但URI是内置的。require'uri'URI.join('http://pupeno.com/blog','/
我有一个Builder类,可让您添加到其中一个实例变量:classBuilderdefinitialize@lines=[]enddeflinesblock_given??yield(self):@linesenddefadd_line(text)@lines现在,我该如何改变它my_builder=Builder.newmy_builder.lines{|b|b.add_line"foo"b.add_line"bar"}pmy_builder.lines#=>["foo","bar"]进入这个?my_builder=Builder.newmy_builder.lines{add_li
在我的代码中,我使用自动加载进行惰性评估,这样我可以更快地加载程序并在需要时加载文件,我没有看到很多人使用它,但在Thin项目中我注意到自动加载已被广泛使用,反正只是想知道使用它是否有任何风险。 最佳答案 autoload是notthreadsafe并将在未来的Ruby版本中弃用。这是proofbyMatz(ruby的创造者)。 关于ruby-使用autoload与ruby中的require进行惰性评估?,我们在StackOverflow上找到一个类似的问题:
我在Ruby中遇到了一个关于Dir[]和File.join()的简单程序,blobs_dir='/path/to/dir'Dir[File.join(blobs_dir,"**","*")].eachdo|file|FileUtils.rm_rf(file)ifFile.symlink?(file)我有两个困惑:首先,File.join(@blobs_dir,"**","*")中的第二个和第三个参数是什么意思?其次,Dir[]在Ruby中有什么用?我只知道它等价于Dir.glob(),但是,我对Dir.glob()确实不是很清楚。 最佳答案
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。