CSDN话题挑战赛第2期
参赛话题:学习笔记
🖥️ NodeJS专栏:Node.js从入门到精通
🖥️ 博主的前端之路:前端之行,任重道远(来自大三学长的万字自述)
🖥️ TypeScript知识总结:TypeScript从入门到精通(十万字超详细知识点总结)
🧑💼个人简介:大三学生,一个不甘平庸的平凡人🍬
👉 你的一键三连是我更新的最大动力❤️!
🏆分享博主自用牛客网🏆:一个非常全面的面试刷题求职网站,点击跳转🍬
文章目录
最近博主一直在牛客网刷题巩固基础知识,牛客网不仅具有公司真题、专项练习、面试题库、在线编程等功能,还具有非常强大的AI模拟面试功能,简直是求职者的福音!
牛客网里的题库非常全面的,无论你是前端还是后端,是想要备考还是准备面试又或者是想要提高自己,你都能在牛客网上找到适合自己的题,赶快点击链接去注册登录吧:点我进入牛客网
| 牛客网 | 牛客网 |
|---|---|
 |  |
本篇文章所有示例来自于牛客网题库/在线编程/JS篇,这些都是前端开发中常用的功能,借此记录一下刷题过程,巩固基础!
描述:
给定字符串 str,检查其是否以元音字母结尾
1、元音字母包括 a,e,i,o,u,以及对应的大写
2、包含返回 true,否则返回 false
示例:
输入:'gorilla'
输出:true
方案一: 运用数组进行判断
function endsWithVowel(str) {
const arr=['a','e','i','o','u']
return arr.includes(str[str.length-1].toLowerCase())
}
知识点:
方案二: 使用正则
function endsWithVowel(str) {
const reg=/[aeiou]$/gi
return reg.test(str)
}
知识点:
[aeiou]表示匹配一个字符,它可以是“a”、“e”、“i”、“o”、“u”之一。g,i是正则的一个修饰符,g表示全局匹配,i表示不区分大小写。$(美元符号)匹配结尾,在多行匹配中匹配行结尾。true 或 false。描述:
给定字符串 str,检查其是否包含 连续3个数字,请使用正则表达式实现。
1、如果包含,返回最先出现的 3 个数字的字符串
2、如果不包含,返回 false
示例:
输入:'9876543'
输出:'987'
方案:
function captureThreeNumbers(str) {
const reg=/\d{3}/g
if(reg.test(str)){
return str.match(reg)[0]
}
return false
}
知识点:
\d就是[0-9],表示是一位数字。{m} 等价于{m,m},表示出现m到m次,即m次。({m,n},表示出现m到n次。)g是正则的一个修饰符,表示全局匹配。true 或 false。描述:
将 rgb 颜色字符串转换为十六进制的形式,如 rgb(255, 255, 255) 转为 #ffffff
rgb 中每个 , 后面的空格数量不固定rgb 格式,返回原始输入示例:
输入:'rgb(255, 255, 255)'
输出:#ffffff
方案一:
function rgb2hex(sRGB) {
const reg = /^rgb\((\d+),\s*(\d+),\s*(\d+)\)$/;
const ret = sRGB.match(reg);
if (!ret) {
return sRGB;
} else {
var str = "#";
for (var i = 1; i <= 3; i++) {
var m = parseInt(ret[i]);
if (m >= 0 && m <= 255) {
str += m < 16 ? "0" + m.toString(16) : m.toString(16);
} else {
return sRGB;
}
}
return str;
}
}
知识点:
正则里
^表示开头;\代表转义(如不能直接输入(,需要输入\(对(进行转义);\d就是[0-9],表示是一位数字;+ 等价于{1,},表示出现至少一次;\s是[ \t\v\n\r\f],表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符;* 等价于{0,},表示出现任意次,有可能不出现。$代表结尾parseInt(string,radix) 解析一个字符串并返回指定基数(radix)的十进制整数,radix是2-36之间的整数,假如radix指定 0 或未指定,基数将会根据字符串的值进行推算。
rgb(a, b, c) 中的a、b、c都在0~255之间。
match() 方法检索返回一个字符串匹配正则表达式的结果(数组形式),如果正则表达式没有设置全局标志 (g),数组的0元素包含整个匹配,而第 1 到 n 元素包含了匹配中曾出现过的任一个子匹配。这相当于没有设置全局标志的 exec 方法。如果设置了全局标志(g),元素0到n中包含所有匹配。
var regexp = /rgb\((\d+),\s*(\d+),\s*(\d+)\)/g; // 加g全局匹配
var ret = "rgb(255, 250, 255)".match(regexp);
console.log("全局匹配结果:", ret); // 全局匹配结果: [ 'rgb(255, 250, 255)' ]
var regexp = /rgb\((\d+),\s*(\d+),\s*(\d+)\)/; // 不加g
var ret = "rgb(255, 250, 255)".match(regexp);
console.log("匹配结果:", ret);
// 匹配结果: [
// 'rgb(255, 250, 255)',
// '255',
// '250',
// '255',
// index: 0,
// input: 'rgb(255, 250, 255)',
// groups: undefined
// ]
思路:
先使用正则判断输入的内容是否符合rgb格式,是的话就for循环遍历到rgb中的三个数值字符串,通过parseInt将其转换成数值,再进一步判断其是否在0~255之间,是的话就继续操作,通过toString(16)转换成16进制字符串(需要注意的是,如果原数小于16,转换成16进制后就只有一位,这时就需要在它前面补0,因为案例要求的是十六进制表达式使用六位小写字母,每两位表示一个rgb中的一个数值)
方案二: 优雅永不过时!
function rgb2hex(sRGB) {
try {
return eval(sRGB);
} catch (err) {
// 出现错误了就直接返回sRGB
return sRGB;
}
}
// 定义一个rgb方法(因为sRGB字符串是rgb(a,b,c)格式的,当作JS代码执行时相当于是调用rgb函数)
function rgb(r, g, b) {
// 有一个数值不在0~255范围内就抛出错误
if (!num(r) || !num(g) || !num(b)) {
throw Error;
}
let rH = r.toString(16);
let gH = g.toString(16);
let bH = b.toString(16);
// 是一位时在前面补零补成两位
rH = rH.length == 1 ? "0" + rH : rH;
gH = gH.length == 1 ? "0" + gH : gH;
bH = bH.length == 1 ? "0" + bH : bH;
return "#" + rH + gH + bH;
}
// 判断数值范围是否在0~255之间
function num(num) {
return parseInt(num) >= 0 && parseInt(num) <= 255;
}
知识点:
JavaScript 代码进行执行。这种方法比较巧妙,也比较简单直观。
描述:
css 中经常有类似 background-image 这种通过 - 连接的字符,通过 javascript 设置样式的时候需要将这种样式转换成 backgroundImage 驼峰格式,请完成此转换功能
- 为分隔符,将第二个起的非空单词首字母转为大写-webkit-border-image 转换后的结果为 webkitBorderImage示例:
输入:'font-size'
输出:fontSize
方案:
function cssStyle2DomStyle(sName) {
let str = "";
// 通过-分割字符串,获得分割后的数组
const arr = sName.split("-");
// 如果数组第一位为空,则将其删除
if (arr[0] === "") {
arr.shift();
}
for (let i = 0; i < arr.length; i++) {
if (i === 0) {
str += arr[i];
} else {
str += arr[i][0].toUpperCase() + arr[i].slice(1);
}
}
return str;
}
知识点:
split() 方法使用指定的分隔符字符串将一个String对象分割成子字符串数组,以一个指定的分割字串来决定每个拆分的位置。
const arr = "a-b-c".split("-");
console.log(arr); // [ 'a', 'b', 'c' ]
shift() 方法会删除数组的第一个元素并返回删除的这个元素,该方法会改变原数组。
toUpperCase() 方法将字符串转换成大写形式并返回。
slice(a,b) 方法截取字符串,从下标a截取到下标b(包括下标为a的元素不包括下标b的元素),如果不指定a代表从索引 0 开始,不指定b则代表截取到最后(包含最后一个元素)。a为负值时则表示从原数组中的倒数第几个元素开始提取。
描述:
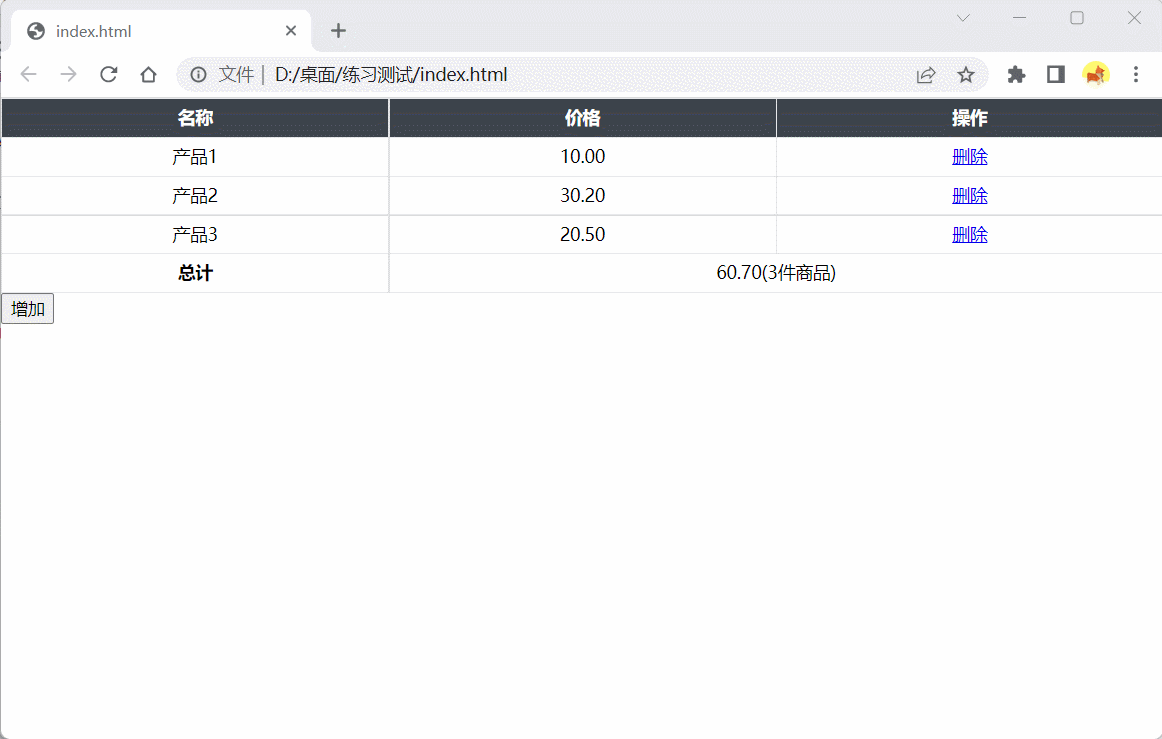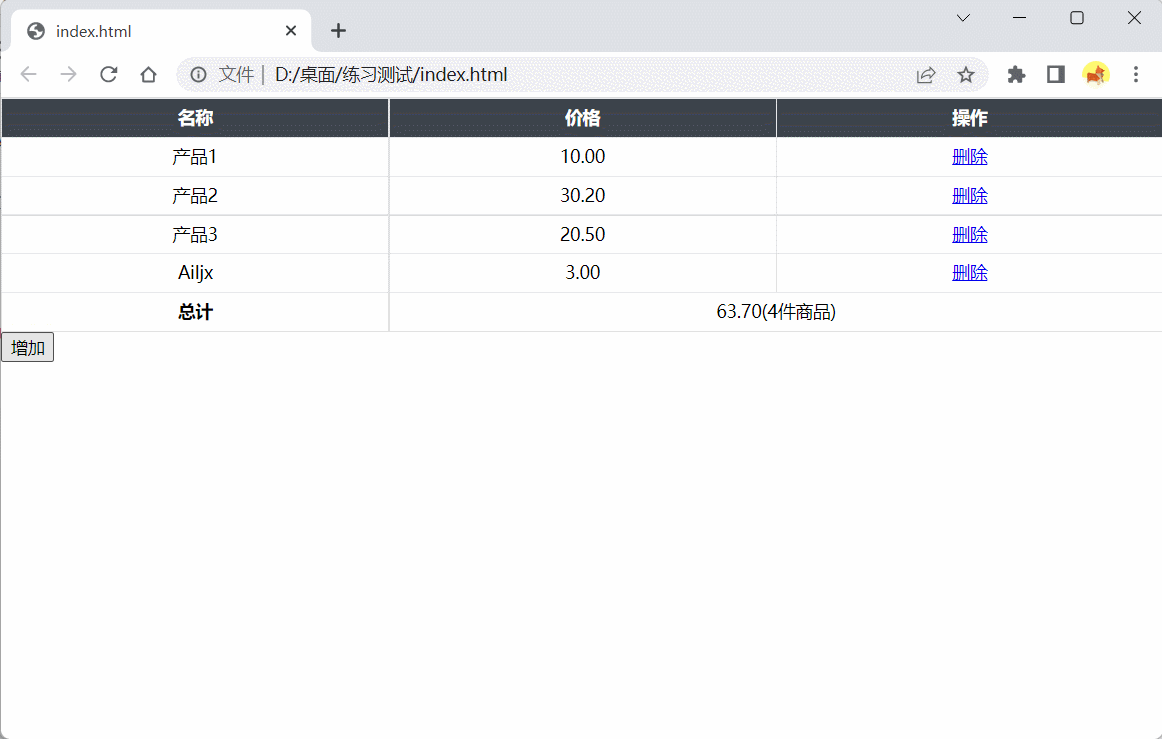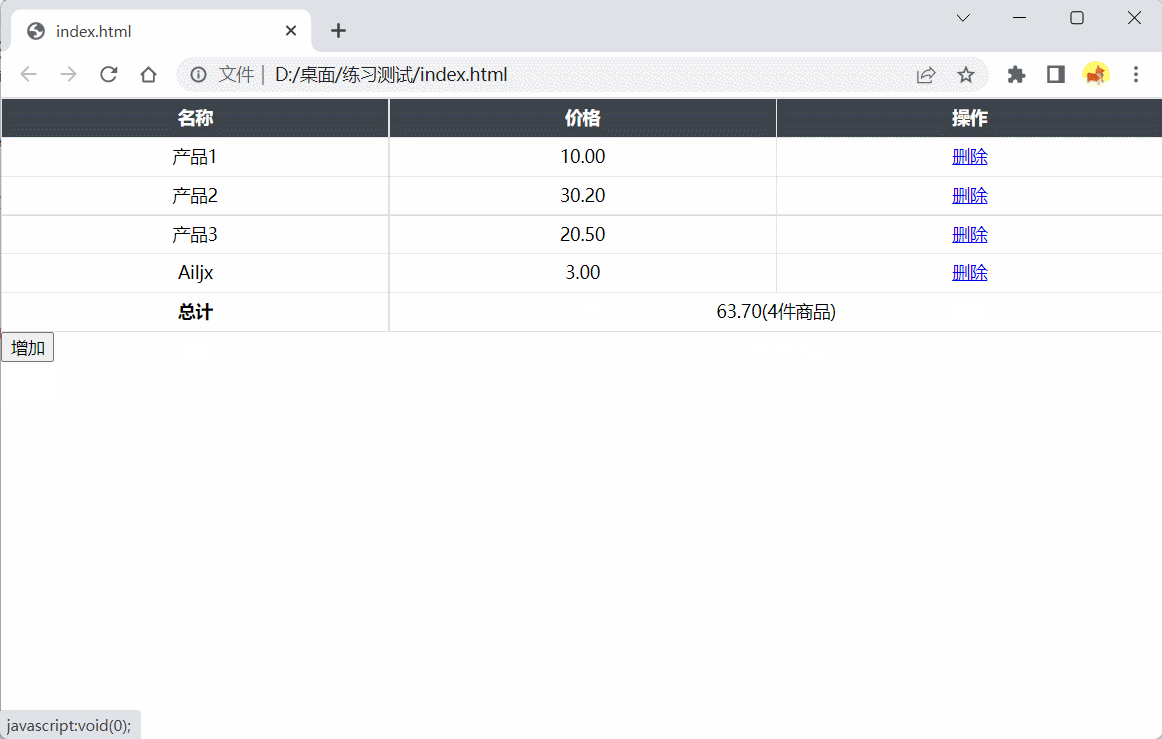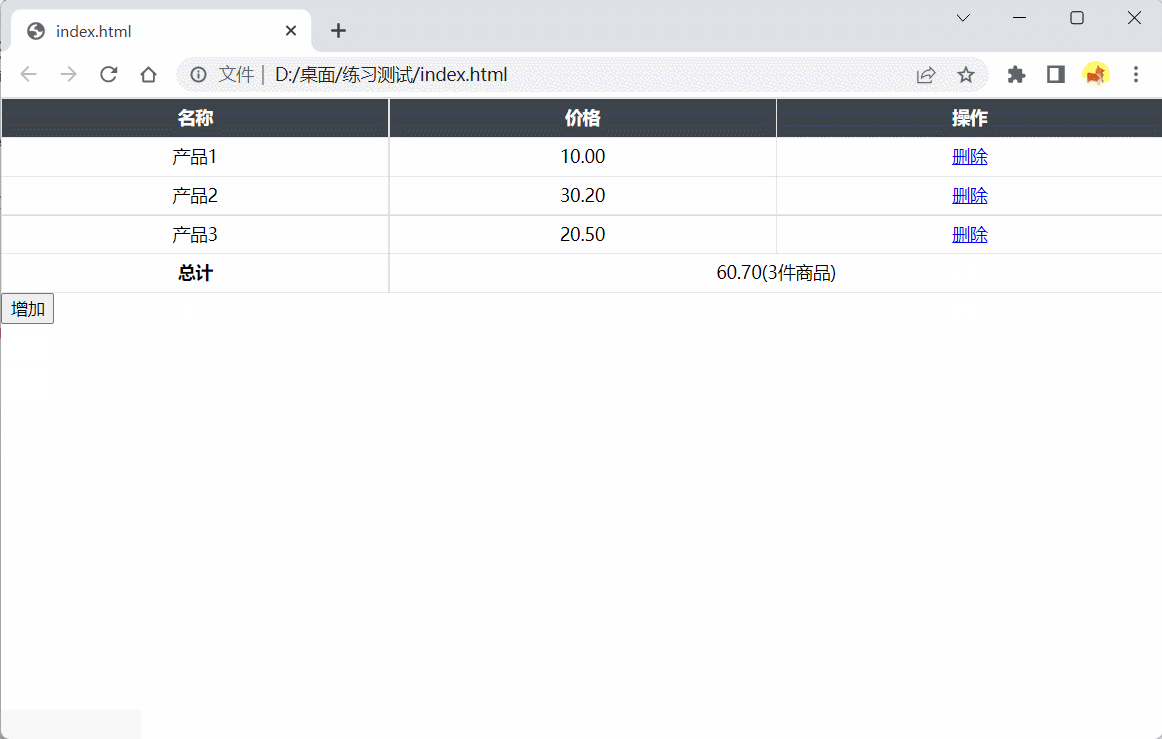
HTML模块为一个简化版的购物车,tbody为商品列表,tfoot为统计信息,系统会随机在列表中生成一些初始商品信息
1、请完成add函数,在列表后面显示items商品信息。参数items为{name: String, price: Number}组成的数组
2、请完成bind函数,点击每一行的删除按钮(包括通过add增加的行),从列表中删除对应行
3、请注意同步更新统计信息,价格保留小数点后两位
4、列表和统计信息格式请与HTML示例保持一致
5、不要直接手动修改HTML中的代码
6、不要使用第三方库
方案:
HTML:
<table id="jsTrolley">
<thead><tr><th>名称</th><th>价格</th><th>操作</th></tr></thead>
<tbody>
<tr><td>产品1</td><td>10.00</td><td><a href="javascript:void(0);">删除</a></td></tr>
<tr><td>产品2</td><td>30.20</td><td><a href="javascript:void(0);">删除</a></td></tr>
<tr><td>产品3</td><td>20.50</td><td><a href="javascript:void(0);">删除</a></td></tr>
</tbody>
<tfoot><tr><th>总计</th><td colspan="2">60.70(3件商品)</td></tr></tfoot>
</table>
<!-- 测试 -->
<button onclick="add([{name: 'Ailjx', price: 3}])">增加</button>
CSS:
body,
html {
padding: 0;
margin: 0;
font-size: 14px;
color: #000000;
}
table {
border-collapse: collapse;
width: 100%;
table-layout: fixed;
}
thead {
background: #3d444c;
color: #ffffff;
}
td,
th {
border: 1px solid #e1e1e1;
padding: 0;
height: 30px;
line-height: 30px;
text-align: center;
}
JavaScript:
function add(items) {
let tbody = document.getElementsByTagName('tbody')[0];
items.forEach((item) => {
// 创建tr节点
let tr = document.createElement('tr');
tr.innerHTML = `<td>${item.name}</td><td>${item.price.toFixed(2)}</td><td><a href="javascript:void(0);">删除</a></td>`;
// 将创建的tr添加到tbody中
tbody.appendChild(tr);
})
// 调用更改统计价格和数量的函数
changePrice();
}
function bind() {
let tbody = document.getElementsByTagName('tbody')[0];
// 给tbody添加点击事件
tbody.onclick = function (e) {
let target = e.target
// 如果点击的是删除按钮
if (target.innerText == "删除") {
// Element.remove() 方法,把对象从它所属的 DOM 树中删除。
target.parentNode.parentNode.remove();
// 调用更改统计价格和数量的函数
changePrice();
}
}
}
// 更改统计价格和数量的函数
function changePrice() {
let tbody = document.getElementsByTagName('tbody')[0];
let tftext = document.getElementsByTagName('tfoot')[0].children[0].children[1];
let total = 0;
// 统计总价
for (let i = 0; i < tbody.children.length; i++) {
// parseFloat() 函数解析一个参数(必要时先转换为字符串)并返回一个浮点数。
total += parseFloat(tbody.children[i].children[1].innerText);
};
// toFixed(digits) 方法使用定点表示法来格式化一个数值。参数digits表示小数点后数字的个数
// Element.childElementCount 只读属性返回一个无符号长整型数字,表示给定元素的子元素数。
tftext.innerText = `${total.toFixed(2)}(${tbody.childElementCount}件商品)`;
}
效果演示:
这篇文章的所有内容都出自于牛客网的JS篇题库:
牛客网的JS题库非常贴合实际的,在写的过程中自己查漏补缺,收获了很多,强烈将牛客网推荐给大家!
如果本篇文章对你有所帮助,还请客官一件四连!❤️
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg