人类生活在充满多样性的世界里。长久以来的研究发现,人类的脑与行为受到基因、环境和文化及其相互作用的塑造,然而这种影响发生的机制始终缺乏系统性探索与研究。近年来,前沿神经影像技术方法飞速进步,推动着多模态脑成像大数据集的产生和融合性探索,并让学界得以深入探究人脑宏观结构与功能连接组架构,为包括上述主题在内的许多有趣而重要的科学问题带来了新的启发和思路。
2022年12月20日,北京大学物理学院、IDG麦戈文脑科学研究所高家红团队在《Nature Neuroscience》在线发表了题为 “Increasing diversity in connectomics with the Chinese Human Connectome Project”的中国人脑连接组计划研究成果及其大数据资源的相关工作。该研究建立了一套全新的中国人脑影像开放资源,并揭示了中西方脑结构与功能组织信息在大尺度水平的系统性差异。
该成果及其大数据资源来自于高家红团队启动和初步完成的“中国人脑连接组计划”(Chinese Human Connectome Project, 简称CHCP)。CHCP旨在建立一套基于中国人群的大型多模态神经影像、行为与基因数据集。为方便对照和比较,CHCP与美国“人类脑连接组计划”(Human Connectome Project, 简称HCP)的研究规程保持高度一致:包括磁共振成像扫描、数据采集参数、功能脑成像的任务范式等;同时CHCP也采集了与HCP数据集可类比的行为与基因数据。目前基于CHCP与HCP大数据集的研究已初步发现在不同文化背景下的人群其脑结构、脑功能与脑连接等特征共性与个性并存。此外,基于两组大数据集的人群脑图谱均具有很高的可重复性,而跨文化对比则发现语言加工的相关脑机制差异最大。
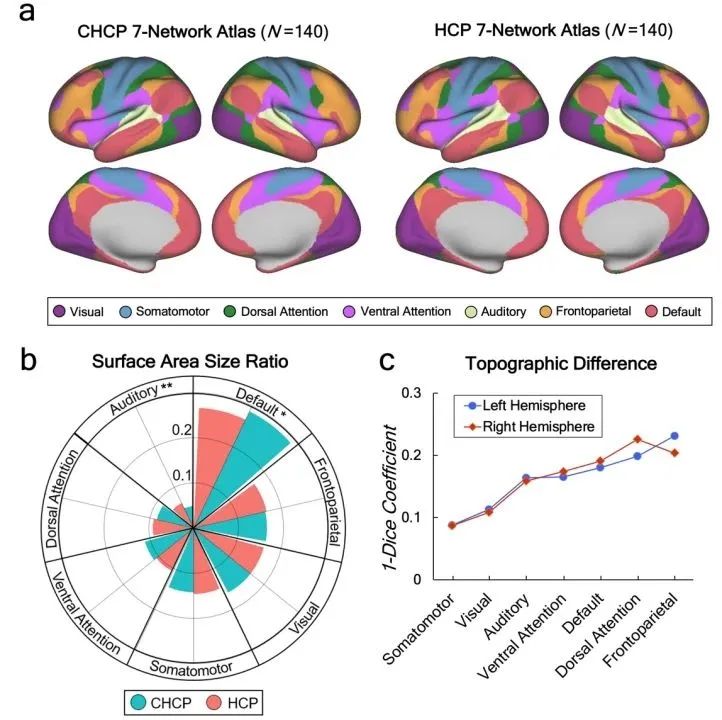
图1: 中西方大尺度脑功能图谱对照结果
目前CHCP大数据集已实现开放共享。CHCP中国人脑连接组计划研究成果及其数据资源的公布不仅对于促进基于中国人脑影像的脑-行为和脑图谱方面的科学研究具有宝贵意义,更重要的是填补了当前国际上缺少来自非西方群体(比如中国人群)对照的空白,为探索人类不同文化与族裔背景中的脑-行为关联起到了推动作用。基于CHCP和HCP中静息态功能磁共振影像数据建立的中西方大尺度7网络脑功能图谱结果发现中西方静息态脑功能图谱在参与高级认知加工的联合皮质区表现出较大的地形图差异性,而在初级感知觉皮质区的地形图差异性则相对较低 (图1所示)。进一步分析则表明,在七个经典认知任务态下CHCP和HCP的中西方脑功能激活差异主要体现在语言加工任务中, 而简单运动功能相关的脑激活图结果则表现出较低的中西方差异性(图2所示)。

图2:七个经典认知任务态下中西方脑功能激活图对照结果
论文的共同第一作者为北京大学前沿交叉学科研究院讲师葛鉴桥与北京理工大学前沿交叉科学研究院助理教授杨国元(原北京大学物理学院博士毕业生),北京大学高家红教授为通讯作者。昌平实验室、北京脑科学与类脑研究中心和北京师范大学等合作单位共同参与了项目研究。高家红实验室的研究工作受到国家发改委、国家科技部、国家自然科学基金委员会、北京市科学技术委员会和北京脑科学与类脑研究中心的科研经费资助与支持。
原文链接:
https://www.nature.com/articles/s41593-022-01215-1

研究组介绍
高家红
北京大学物理学院教授
北京大学磁共振成像研究中心主任
北京大学IDG麦戈文脑科学研究所PI
研究兴趣
实验室开展功能磁共振和脑磁图成像前沿技术研发及其在脑科学和神经精神疾病应用领域的研究工作。
来源:北大脑科学
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我正在尝试将一个资源属性的默认值设置为另一个属性的值。我正在为我正在构建的tomcat说明书定义一个资源,其中包含以下定义。我想要可以独立设置的“名称”和“服务名称”属性。当未设置服务名称时,我希望它默认为为“名称”提供的任何内容。以下不符合我的预期:attribute:name,:kind_of=>String,:required=>true,:name_attribute=>trueattribute:service_name,:kind_of=>String,:default=>:name注意第二行末尾的“:default=>:name”。当我在Recipe的新block中引用我
假设我们有两个资源:template'template1'doowner'root'group'root'endtemplate'template2'doowner'root'group'root'end我想在资源中重用代码。但是,如果我在配方中定义了一个过程,您会得到owner、group等的NoMethodError。为什么会这样?词法范围没有什么不同,是吗?因此,我必须使用self.instance_eval&common_cfg。common_cfg=Proc.new{owner'root'group'root'}template'template1'docommon_cfg.
当我尝试使用“套接字”库中的方法“read_nonblock”时出现以下错误IO::EAGAINWaitReadable:Resourcetemporarilyunavailable-readwouldblock但是当我通过终端上的IRB尝试时它工作正常如何让它读取缓冲区? 最佳答案 IgetthefollowingerrorwhenItrytousethemethod"read_nonblock"fromthe"socket"library当缓冲区中的数据未准备好时,这是预期的行为。由于异常IO::EAGAINWaitReadab
我很难给出正确的答案,所以我会在这里征求我的问题。我正在研究RESTFulAPI。自然地,我有多种资源,其中一些由父子关系组成,一些是独立资源。我有点困难的地方是弄清楚如何让那些将根据我的API构建客户端的人更容易。情况是这样的。假设我有一个“街道”资源。每条街道都有多个住宅。SoStreet:has_manytoHomes和Homes:belongs_toStreet。如果用户想要在特定的home资源上请求HTTPGET,以下应该可行:http://mymap/streets/5/homes/10这允许用户获取ID为10的房屋的信息。直截了当。我的问题是,我授予用户访问权限是否违反了
如果使用Marshal.dump写入文件,我有一个Ruby散列达到大约10兆字节。gzip压缩后约为500KB。在ruby中迭代和改变这个散列是非常快的(几分之一毫秒)。即使复制它也非常快。问题是我需要在RubyonRails进程之间共享此散列中的数据。为了使用Rails缓存(file_store或memcached)执行此操作,我需要先Marshal.dump文件,但这会在序列化文件时产生1000毫秒的延迟,在序列化文件时产生400毫秒的延迟。理想情况下,我希望能够在100毫秒内从每个进程保存和加载此哈希。一个想法是生成一个新的Ruby进程来保存这个散列,该散列为其他进程提供AP
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。有没有学习Ajax(jQuery)和Rails3的好资源?
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和