@interface HYSpeechVoiceDetectManager : NSObject
-(void)isHasVoiceRecodingAuthority:(authorityReturnBlock)hasAuthorityBlock;
+(void)isHasSpeechRecognizerAuthority:(authorityReturnBlock)hasAuthorityBlock;
- (void)setupTimer;
-(void)startTransfer;
-(void)endTransfer;-(void)isHasSpeechRecognizerAuthority{
if (@available(iOS 10.0, *)) {
SFSpeechRecognizerAuthorizationStatus authorizationStatus = [SFSpeechRecognizer authorizationStatus];
if (authorizationStatus == SFSpeechRecognizerAuthorizationStatusNotDetermined) {
[SFSpeechRecognizer requestAuthorization:^(SFSpeechRecognizerAuthorizationStatus status) {
}];
}else if(authorizationStatus == SFSpeechRecognizerAuthorizationStatusDenied || authorizationStatus == SFSpeechRecognizerAuthorizationStatusRestricted) {
} else{
}
}else{
}
}-(void)isHasVoiceRecodingAuthority:(authorityReturnBlock)hasAuthorityBlock{
if ([[[UIDevice currentDevice]systemVersion]floatValue] >= 7.0) {
AVAuthorizationStatus videoAuthStatus = [AVCaptureDevice authorizationStatusForMediaType:AVMediaTypeAudio];
if (videoAuthStatus == AVAuthorizationStatusNotDetermined) {
} else if(videoAuthStatus == AVAuthorizationStatusRestricted || videoAuthStatus == AVAuthorizationStatusDenied) {
} else{
}
}
}AVAudioEngine *bufferEngine = [[AVAudioEngine alloc]init];
AVAudioInputNode *buffeInputNode = [bufferEngine inputNode];
SFSpeechAudioBufferRecognitionRequest *bufferRequest = [[SFSpeechAudioBufferRecognitionRequest alloc]init];
AVAudioFormat *format =[buffeInputNode outputFormatForBus:0];
[buffeInputNode installTapOnBus:0 bufferSize:1024 format:format block:^(AVAudioPCMBuffer * _Nonnull buffer, AVAudioTime * _Nonnull when) {
[bufferRequest appendAudioPCMBuffer:buffer];
}];
[bufferEngine prepare];[self endTransfer];
NSDictionary *recordSettings = [[NSDictionary alloc] initWithObjectsAndKeys:
[NSNumber numberWithFloat: 14400.0], AVSampleRateKey,
[NSNumber numberWithInt: kAudioFormatAppleIMA4], AVFormatIDKey,
[NSNumber numberWithInt: 2], AVNumberOfChannelsKey,
[NSNumber numberWithInt: AVAudioQualityMax], AVEncoderAudioQualityKey,
nil];
NSString *monitorPath = [NSTemporaryDirectory() stringByAppendingPathComponent:@"monitor.caf"];
NSURL *monitorURL = [NSURL fileURLWithPath:monitorPath];
AVAudioRecorder *monitor = [[AVAudioRecorder alloc] initWithURL:_monitorURL settings:recordSettings error:NULL];
monitor.meteringEnabled = YES;
[monitor record];SFSpeechAudioBufferRecognitionRequest *bufferRequest = [[SFSpeechAudioBufferRecognitionRequest alloc]init];
SFSpeechRecognizer *bufferRec = [[SFSpeechRecognizer alloc]initWithLocale:[NSLocale localeWithLocaleIdentifier:@"zh_CN"]];
[bufferRec recognitionTaskWithRequest:bufferRequest resultHandler:^(SFSpeechRecognitionResult * _Nullable result, NSError * _Nullable error) {
if (error == nil) {
NSString *voiceTextCache = result.bestTranscription.formattedString;
}else{
}
}];-(void)endTransfer{
[bufferEngine stop];
[buffeInputNode removeTapOnBus:0];
bufferRequest = nil;
bufferTask = nil;
[monitor stop];
[monitor deleteRecording];
NSError *error = nil;
[[AVAudioSession sharedInstance] setActive:NO error:&error];
if (error != nil) {
return;
}
[[AVAudioSession sharedInstance] setCategory:AVAudioSessionCategoryPlayback error:nil];
if (error != nil) {
return;
}
[[AVAudioSession sharedInstance] setMode:AVAudioSessionModeDefault error:&error];
if (error != nil) {
return;
}
[[AVAudioSession sharedInstance] setActive:YES error:&error];
if (error != nil) {
return;
}
} 如上最终效果图中一共有32个波浪圆点,其中前6个和后6个属于固定静止的圆点,只有中间20个圆点属于随音量大小类似波浪上下浮动的长柱图。
如上最终效果图中一共有32个波浪圆点,其中前6个和后6个属于固定静止的圆点,只有中间20个圆点属于随音量大小类似波浪上下浮动的长柱图。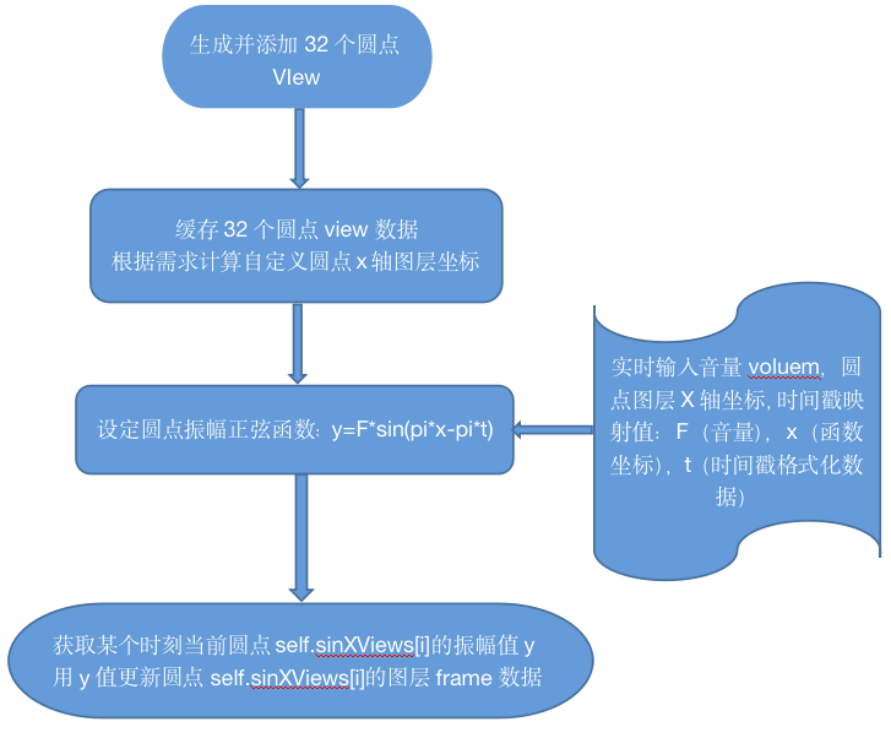 那么实时语音音量voluem数据是如何获取的?实际上前文中的监听器(AVAudioRecorder)就提供了语音音量数据的封装接口- (float)peakPowerForChannel:(NSUInteger)channelNumber,channelNumber为音频输入/输出的通道号,该函数返回的数据即为分贝数值,取值的范围是 -160~0 ,声音峰值越大,越接近0。当获取到实时语音音量voluem数据后进行相应的量化处理就能得到振幅y的映射值。相关代码可参考如下:
那么实时语音音量voluem数据是如何获取的?实际上前文中的监听器(AVAudioRecorder)就提供了语音音量数据的封装接口- (float)peakPowerForChannel:(NSUInteger)channelNumber,channelNumber为音频输入/输出的通道号,该函数返回的数据即为分贝数值,取值的范围是 -160~0 ,声音峰值越大,越接近0。当获取到实时语音音量voluem数据后进行相应的量化处理就能得到振幅y的映射值。相关代码可参考如下:AVAudioRecorder *monitor
[monitor updateMeters];
float power = [monitor peakPowerForChannel:0];self.sinXViews = [NSMutableArray new];
for (NSUInteger i = 0; i < sinaXNum+12; i++) {
UIView *sinView = [[UIView alloc]initWithFrame:CGRectMake(offsetX, offsetY, 3, 3)];
sinView.layer.cornerRadius = 1.5f;
sinView.layer.masksToBounds = YES;
[self.sinXViews addObject:sinView];
[self addSubview:sinView];
}-(double)fSinValueWithOriginX:(CGFloat)originX timeS:(NSTimeInterval)timeStamp voluem:(CGFloat)voluem{
CGFloat sinF ;
double sinX ;
double fSin = sinF *(4/(pow(sinX,4)+4))*sin(3.14*sinX-3.14*timeStamp);
return fabs(fSin);
}for (NSUInteger i = 0; i < self.sinXViews.count; i++) {
if (i > 5 && i < self.sinaXNum+6) {
UIView *sinView = (UIView *)self.sinXViews[i];
CGRect frame = sinView.frame;
double _viewHeight = [self fSinValueWithOriginX:frame.origin.x timeS:timeStamp voluem:Voluem];
double viewHeight ;
frame.size.height = viewHeight;
if (viewHeight == 0) {
return;
}
frame.origin.y = (self.frame.size.height-viewHeight)/2;
[sinView setFrame:frame];
}
}我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO