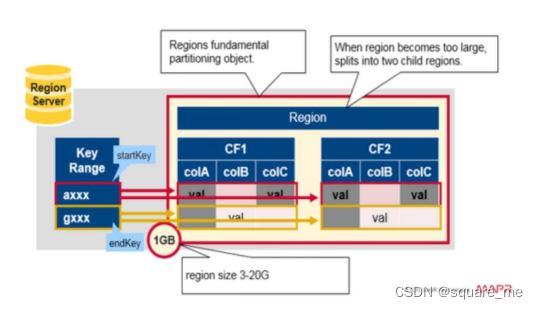
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
当1个region中的某个Store下所有StoreFile的总大小超过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该Region就会进行拆分。
initialSize的默认值为2*hbase.hregion.memstore.flush.size(128M),
R为当前Region Server中属于该Table的Region个数。
hbase.hregion.max.filesize 默认10G 如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size(2*128M)分裂,否则按照hbase.hregion.max.filesize(10G)分裂。
具体的切分策略为:
通常较少的region数量可使群集运行的更加平稳,官方指出每个RegionServer大约100个regions的时候效果最好,理由如下:
HBase的一个特性MSLAB,它有助于防止堆内存的碎片化,减轻垃圾回收Full GC的问题,默认是开启的。但是每个MemStore需要2MB(一个列簇对应一个写缓存memstore)。所以如果每个region有2个family列簇,总有1000个region,就算不存储数据也要3.95G内存空间。
如果很多region,它们中Memstore也过多,内存大小触发Region Server级别限制导致flush,就会对用户请求产生较大的影响,可能阻塞该Region Server上的更新操作。
HMaster要花大量的时间来分配和移动Region,且过多Region会增加ZooKeeper的负担。
从HBase读入数据进行处理的mapreduce程序,过多Region会产生太多Map任务数量,默认情况下由涉及的region数量决定。
所以,如果一个HRegion中Memstore过多,而且大部分都频繁写入数据,每次flush的开销必然会很大,因此我们也建议在进行表设计的时候尽量减少ColumnFamily的个数。每个region都有自己的MemStore,当大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。
计算集群region数量的公式:
((RS Xmx) * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * (# column families))
假设一个RS有16GB内存,那么16384*0.4/128m 等于51个活跃的region。
如果写很重的场景下,可以适当调高hbase.regionserver.global.memstore.size,这样可以容纳更多的region数量。
建议分配合理的region数量,根据写请求量的情况,一般20-200个之间,可以提高集群稳定性,排除很多不确定的因素,提升读写性能。监控Region Server中所有Memstore的大小总和是否达到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认 40%的JVM内存使用量),超过可能会导致不良后果,如服务器反应迟钝或compact风暴。
HBase中数据一开始会写入memstore,满128MB(看配置)以后,会flush到disk上而成为storefile。当storefile数量超过触发因子时(可以配置),会启动compaction过程将它们合并为一个storefile。对集群的性能有一定影响。而当合并后的storefile大于max.filesize,会触发分割动作,将它切分成两个region。
当hbase.hregion.max.filesize比较小时,触发split的机率更大,系统的整体访问服务会出现不稳定现象。
当hbase.hregion.max.filesize比较大时,由于长期得不到split,因此同一个region内发生多次compaction的机会增加了。这样会降低系统的性能、稳定性,因此平均吞吐量会受到一些影响而下降。
hbase.hregion.max.filesize不宜过大或过小,经过实战,生产高并发运行下,最佳大小5-10GB!关闭某些重要场景的HBase表的major_compact!在非高峰期的时候再去调用major_compact,这样可以减少split的同时,显著提供集群的性能,吞吐量、非常有用。 一般情况下,单个region的大小建议控制在5GB以内,可以通过参数hbase.hregion.max.filesize来设置,单个regionserver下的regions个数控制在200个以内。regions过多会导致集群不堪重负、regionserver 频繁FullGC的情况,进而影响集群的稳定性甚至上层的应用服务。
注意:通过HBase的UI控制台都可以监控到region的数量&大小指标
对于数据体量比较大,regions确实比较多的情况,建议对集群进行扩容;对于因使用不当导致regions“过多”的情况,建议对regions进行合并操作,具体如下:
hbase> splitormerge_switch 'MERGE',true
hbase>splitormerge_switch 'SPLIT',true
hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'需要注意的是,该方式为相邻region进行两两合并,对于regions比较大的表,需要反复操作多次,两次merge时间间隔建议在10分钟,同时merge后可能会出现Region-In-Transition(hole,region之间有间隙的问题)出现的话,修复下即可。
单个Region过大
在预分region的同时rowkey设计不合理,往往会将数据写入到某个region或者某几个region的情况,导致单个region有几十GB+以上的情况,对集群的稳定性和性能会有影响,此时有两种优化方案:其一是重新设计下rowkey,重入数据,当然代价会比较大;另外一种方案是对现存的比较大的region进行split,可以通过60010管理页面将选中的region name放入split框中,点击split即可;对于预分时考虑不周,未有数据写入的region,可以进行merge操作;
进入HMaster 的页面,然后找到相应的 Table,接着可以看到有如下界面: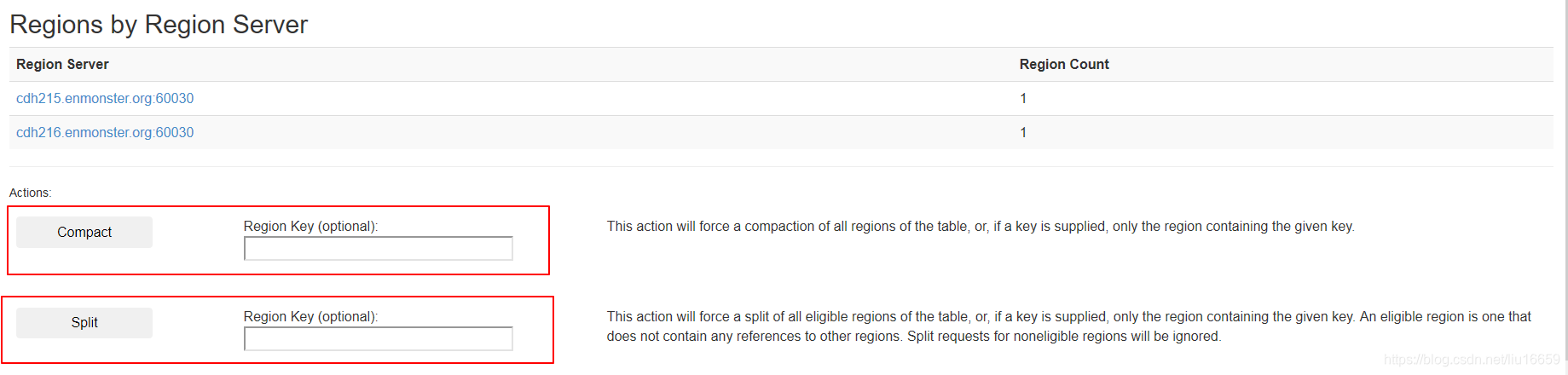
在这个界面上,可以看到有相应的 Actions,Compact 和 Split两个操作。我们针对不同的region进行这个操作就ok了。
RIT问题处理
Regions In Transition问题在集群运维过程中比较常见,处理起来一般会比较累。出现问题后一般是先执行 hbase hbck分析下是什么问题,大多时候可以通过 hbase hbck -repair 进行修复。通过管理页面也可以看到有哪些表出现了RIT问题,针对这些表逐个进行修复。常用的修复命令如下
1.hbase hbck 检查输出所以ERROR信息,每个ERROR都会说明错误信息。
2.hbase hbck -fixTableOrphans 先修复tableinfo缺失问题,根据内存cache或者hdfs table 目录结构,重新生成tableinfo文件。
3.hbase hbck -fixHdfsOrphans 修复regioninfo缺失问题,根据region目录下的hfile重新生成regioninfo文件。
4.hbase hbck -fixHdfsOverlaps 修复region重叠问题,merge重叠的region为一个region目录,并从新生成一个regioninfo。
5.hbase hbck -fixHdfsHoles 修复region缺失,利用缺失的rowkey范围边界,生成新的region目录以及regioninfo填补这个空洞。
6.hbase hbck -fixMeta 修复meta表信息,利用regioninfo信息,重新生成对应meta row填写到meta表中,并为其填写默认的分配regionserver。
7.hbase hbck -fixAssignments 把这些offline的region触发上线,当region开始重新open 上线的时候,会被重新分配到真实的RegionServer上 , 并更新meta表上对应的行信息。
还可以采用预分区来避免Region split问题
为什么要预分区
默认情况下创建的表是只有1个Region的
在数据写入时,所有数据都会写入这个默认的Region
随着数据量的不断增加,此Region已经不能承受不断增长的数据量,会进行Split,分裂成2个Region。
在这个过程中,会产生两个问题:
1、数据往一个Region上写,会有写热点问题。
2、Region split会消耗宝贵的集群IO资源。
由此我们可以在建表的时候,创建多个空Region,并确定每个Region的起始和终止Rowkey,这样只要我们设计的Rowkey能均匀的命中各个Region。Region分裂的几率也会大大降低。
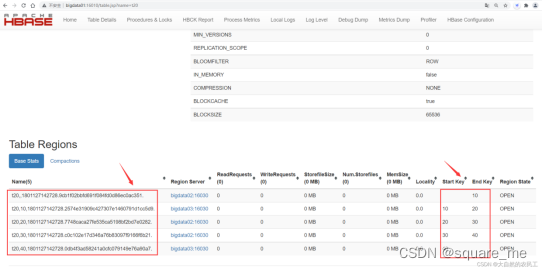
到HBase的界面中查看这个表的region信息
http://bigdata01:16010/
热点现象的产生
HBase 中的行是按照 Rowkey 的字典顺序排序的,这种设计优化了 scan 操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于 scan。
然而糟糕的 Rowkey 设计是热点的源头。 热点发生在大量的 client 直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。
大量访问会使热点 region 所在的单个机器超出自身承受能力,引起性能下降甚至 region 不可用,这也会影响同一个 RegionServer 上的其他 region,由于主机无法服务其他 region 的请求,这样就造成数据热点现象。 (这一点其实和数据倾斜类似)
所以我们在向 HBase 中插入数据的时候,应优化 RowKey 的设计,使数据被写入集群的多个 region,而不是一个。尽量均衡地把记录分散到不同的 Region 中去,平衡每个 Region 的压力。
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun