最近写了几个简单的spark structured streaming 的代码实例。 目的是熟悉spark 开发环境搭建, spark 代码开发流程。
开发环境:
系统:win 11
java : 1.8
scala:2.13
工具:idea 2022.2 ,maven 3, git 2.37
spark : 3.3.2
一, 使用 spark 结构化流读取文件数据,并做单词统计。
代码:
package org.example;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.OutputMode;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.streaming.StreamingQueryException;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import java.util.concurrent.TimeoutException;
public class Main {
/*
例子:从文件中读取流, 被定义模式,生成dataset ,使用sql api 进行分析。
*/
public static void main(String[] args) throws TimeoutException, StreamingQueryException {
System.out.println("Hello world!");
SparkSession spark = SparkSession.builder().appName("spark streaming").config("spark.master", "local")
.config("spark.sql.warehouse.dir", "file:///app/")
.getOrCreate();
spark.sparkContext().setLogLevel("ERROR");
StructType schema =
new StructType().add("empId", DataTypes.StringType).add("empName", DataTypes.StringType)
.add("department", DataTypes.StringType);
Dataset<Row> rawData = spark.readStream().option("header", false).format("csv").schema(schema)
.csv("D:/za/spark_data/*.csv");
rawData.createOrReplaceTempView("empData");
Dataset<Row> result = spark.sql("select count(*), department from empData group by department");
StreamingQuery query = result.writeStream().outputMode("complete").format("console").start(); // 每次触发,全表输出
query.awaitTermination();
}
}输出:
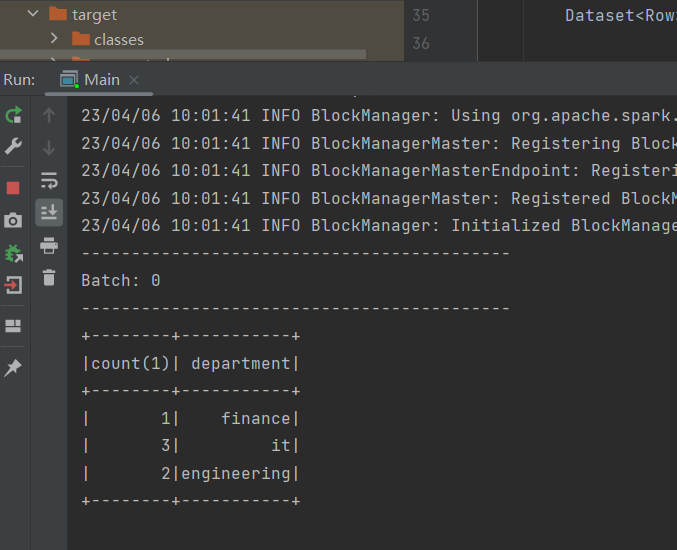
二, 使用 spark 结构化流读取socket流,做单词统计,使用Java编程
代码:
package org.example;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.streaming.StreamingQueryException;
import java.util.Arrays;
import java.util.concurrent.TimeoutException;
public class SocketStreaming_wordcount {
/*
* 从socket 读取字符流,并做word count分析
*
* */
public static void main(String[] args) throws TimeoutException, StreamingQueryException {
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredNetworkWordCount")
.config("spark.master", "local")
.getOrCreate();
// dataframe 表示 socket 字符流
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// 把一行字符串切分为 单词
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// 对单词分组计数
Dataset<Row> wordCounts = words.groupBy("value").count();
// 开始查询并打印输出到console
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();
}
}输出:
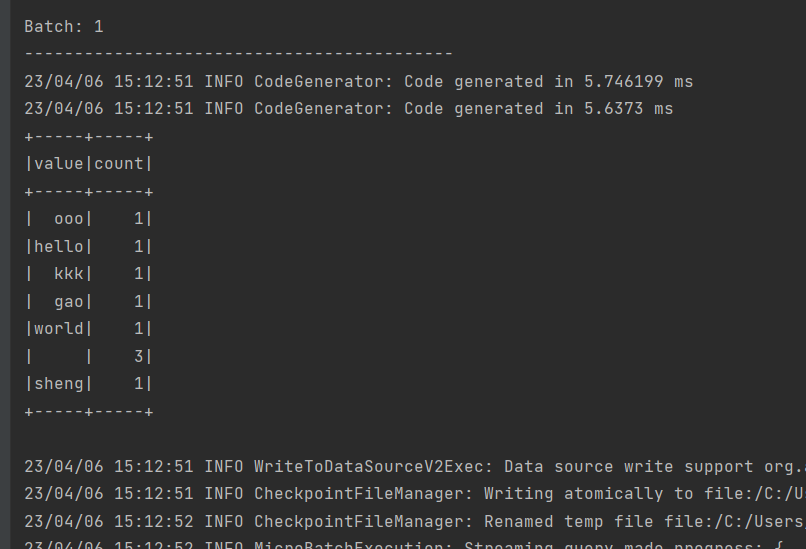
二, 使用 spark 结构化流读取socket流,做单词统计,使用scala 编程
代码:
package org.example
import org.apache.spark.sql.SparkSession
object Main {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("streaming_socket_scala")
.config("spark.master", "local")
.getOrCreate()
import spark.implicits._
// 创建datafram 象征从网络socket 接收流
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// 切分一行成单词
val words = lines.as[String].flatMap(_.split(" "))
// 进行单词统计
val wordCounts = words.groupBy("value").count()
// 开始查询并输出
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
}
}输出:
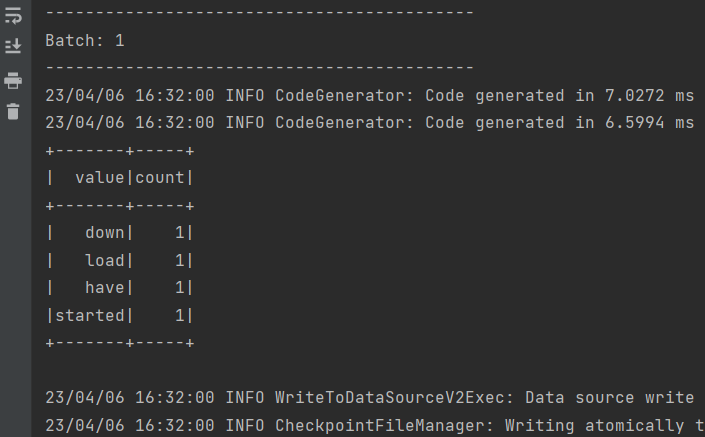
功能比较简单,代码比较简单,可以在网络上找到很多。 但是也是一个完整的spark结构流代码开发流程。权当熟悉下开发流程。
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json