在我们开始之前,你必须先了解编程语言,然后才能相信 ChatGPT 抛给你的任何东西。 我必须明确这一点,因为许多误入歧途的绵羊被告知 ChatGPT 是新的圣杯,开发人员将被淘汰。

推荐:用 NSDT场景设计器 快速搭建3D场景。
使用 ChatGPT 或任何 LLM 不会自动让你成为大师,也不会自动让你更有效率。
一味的复制粘贴代码对任何人都没有好处; 这只是懒惰。 它可能会导致意想不到的后果,当你添加不理解的代码时,这可能会直接或间接地损害你的项目。
你需要承认 ChatGPT 已经使用 2021 年之前的公开数据进行了训练。结果可能有偏见、容易出错并且缺乏引用。 因此,最好始终牢记这一点,因为它提供准确和最新答案的能力并不比其训练数据集的准确性和相关性更好。 随着 OpenAI 弄清楚如何持续确保模型是最新的,这可能会随着时间的推移而改变。
如上所述,“提示”可能会生成答案或代码片段,这些答案或代码片段可能会引用较旧的框架版本或具有安全缺陷或错误的已弃用功能。
现在我们已经解决了这个问题,让我们进入并查看一些有价值的提示,这些提示将帮助你增强使用 ChatGPT 的方式。
ChatGPT 是上下文感知的。
ChatGPT 有文本输出限制,但可以通过键入“continue”或“继续”轻松绕过这一限制。
如果“继续”返回的解决方案略有不同,你可能需要返回并修复变量名称或更改函数参数的顺序。
如果你在聊天中问太多问题,它最终会失去上下文,因为每次你问一个新问题时它只会延续之前对话的有限部分。
要解决这个问题并保留上下文,可以编辑之前的问题并提出一个完全不同的问题。 ChatGPT 仍将保留更早之前的上下文,这对于询问有关同一应用程序中不同文件的编码问题很有用。
另一个提示是提示“Rewrite for ”让 ChatGPT 修改其答案。 具体说明你想要的输出样式。 “Teach me about code…”、“Write code on…”都会给出不同风格的答案,这可能与点击重新生成的响应不同。
有时,冗长、复杂的提示可能会产生相反的效果,因此保持简短和精确总是好的。 如果你给它太多的任务或者答案需要大量的文字,它可能只是拒绝回答/帮助。
最好描述程序,然后分别询问每个功能,同时指定与先前代码兼容的提示。 一旦你这样做了,你就可以得到想要的效果。
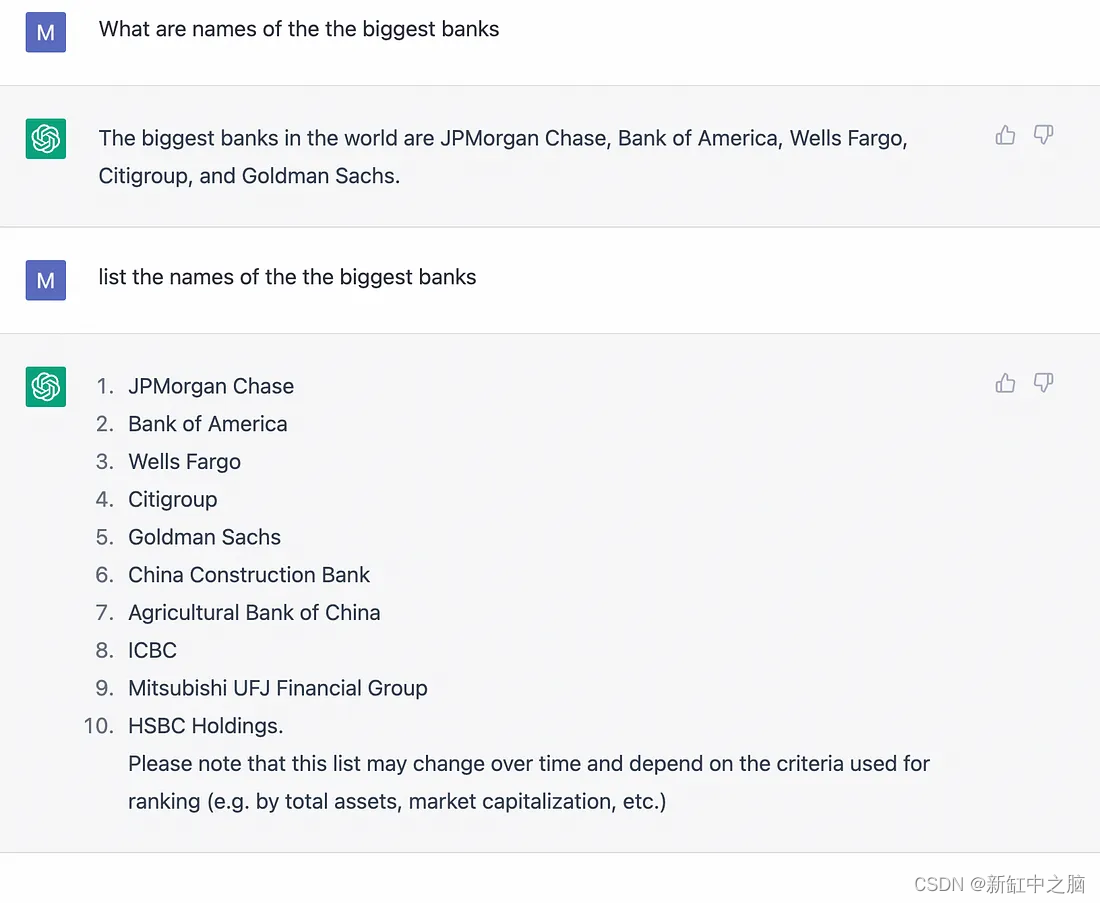
将关键字“list”添加到你的提示中可以更改 ChatGPT 的输出方式。例如,下面的第二个提示要求chatgpt列出最大的银行:
由于 ChatGPT 是基于文本的,你可以使用关键字“markdown”作为提示的一部分。例如:

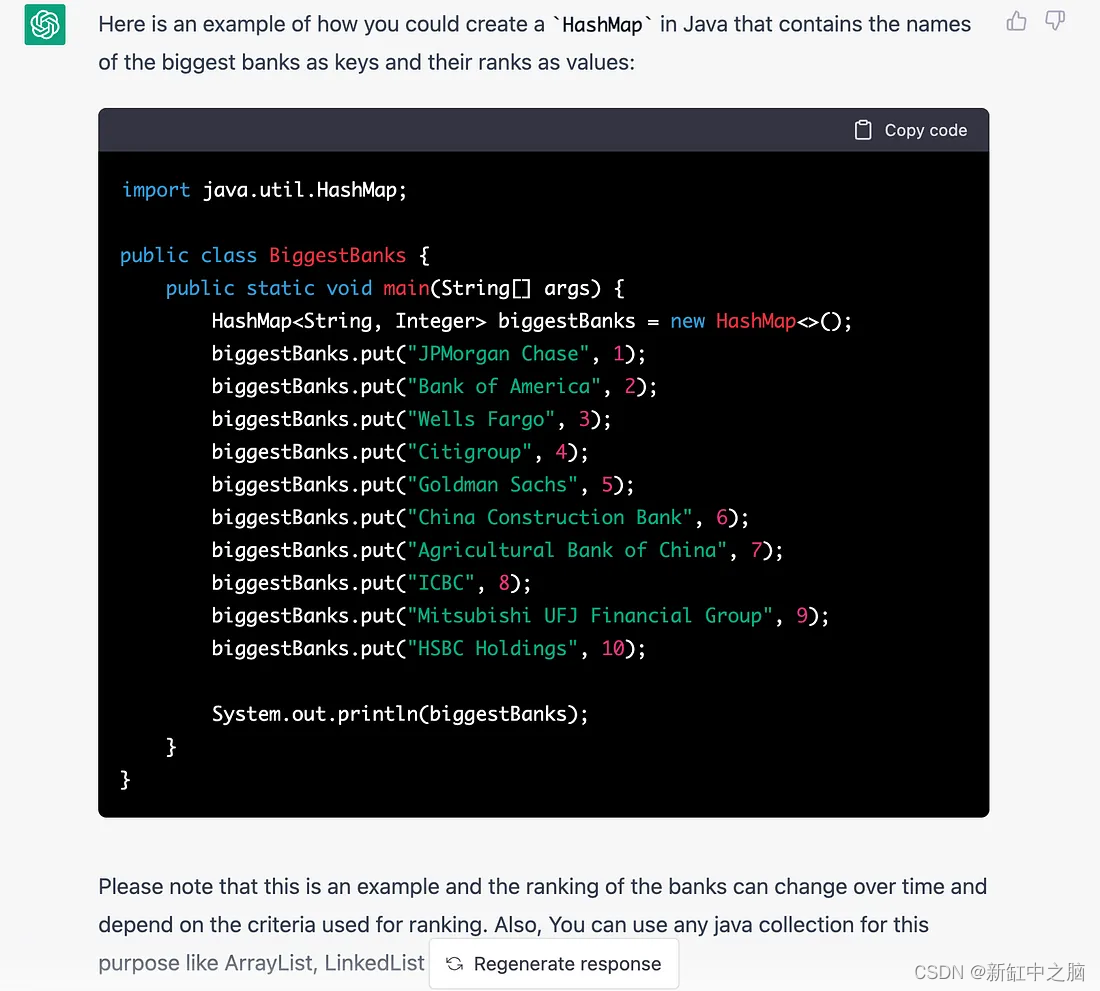
这是另一种要求代码输出的变体。 下面的键/值需要反过来,但是我们不清楚如何定义哈希表:
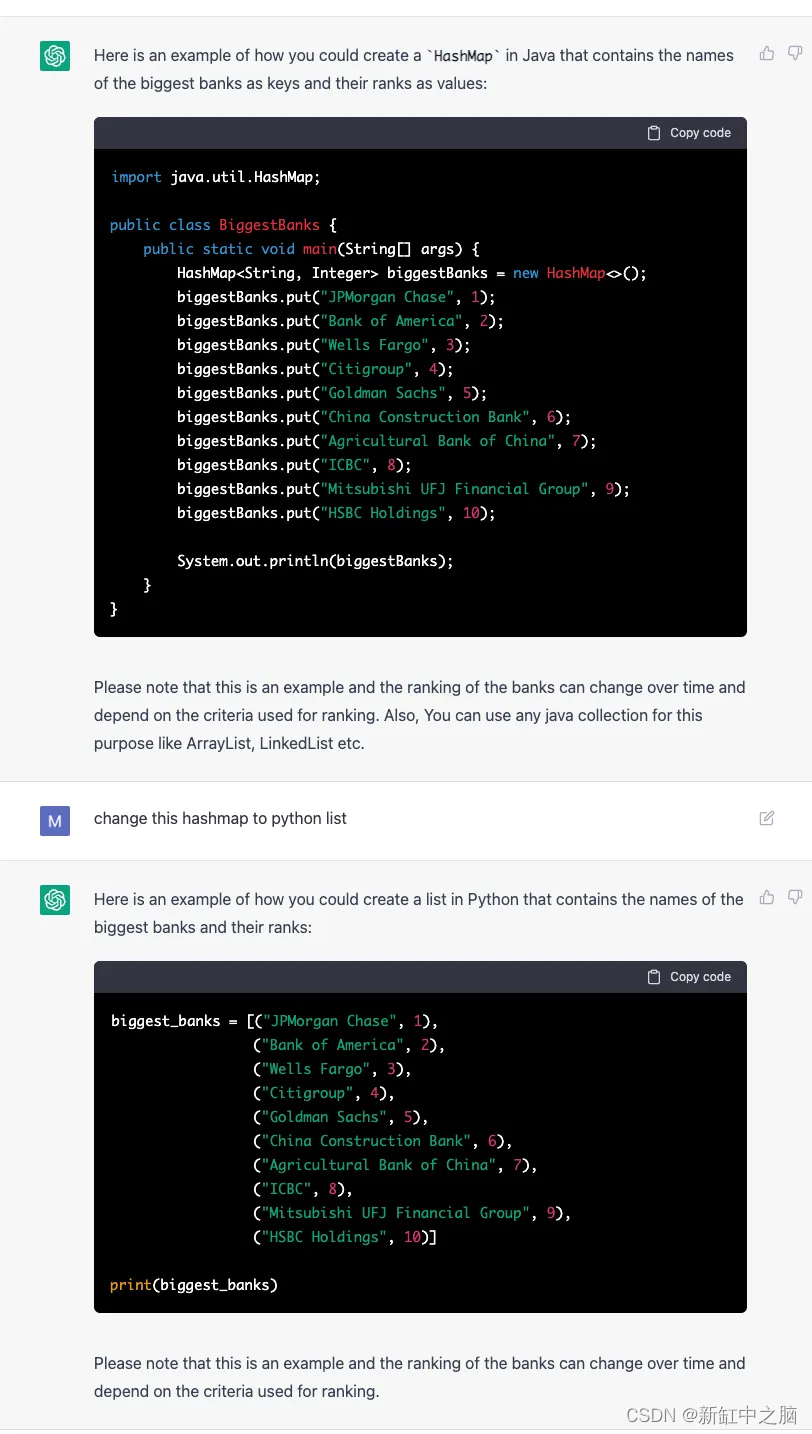
由于我们现在知道 ChatGPT 是上下文感知的,我们可以继续根据之前的输出请求进一步的更改:
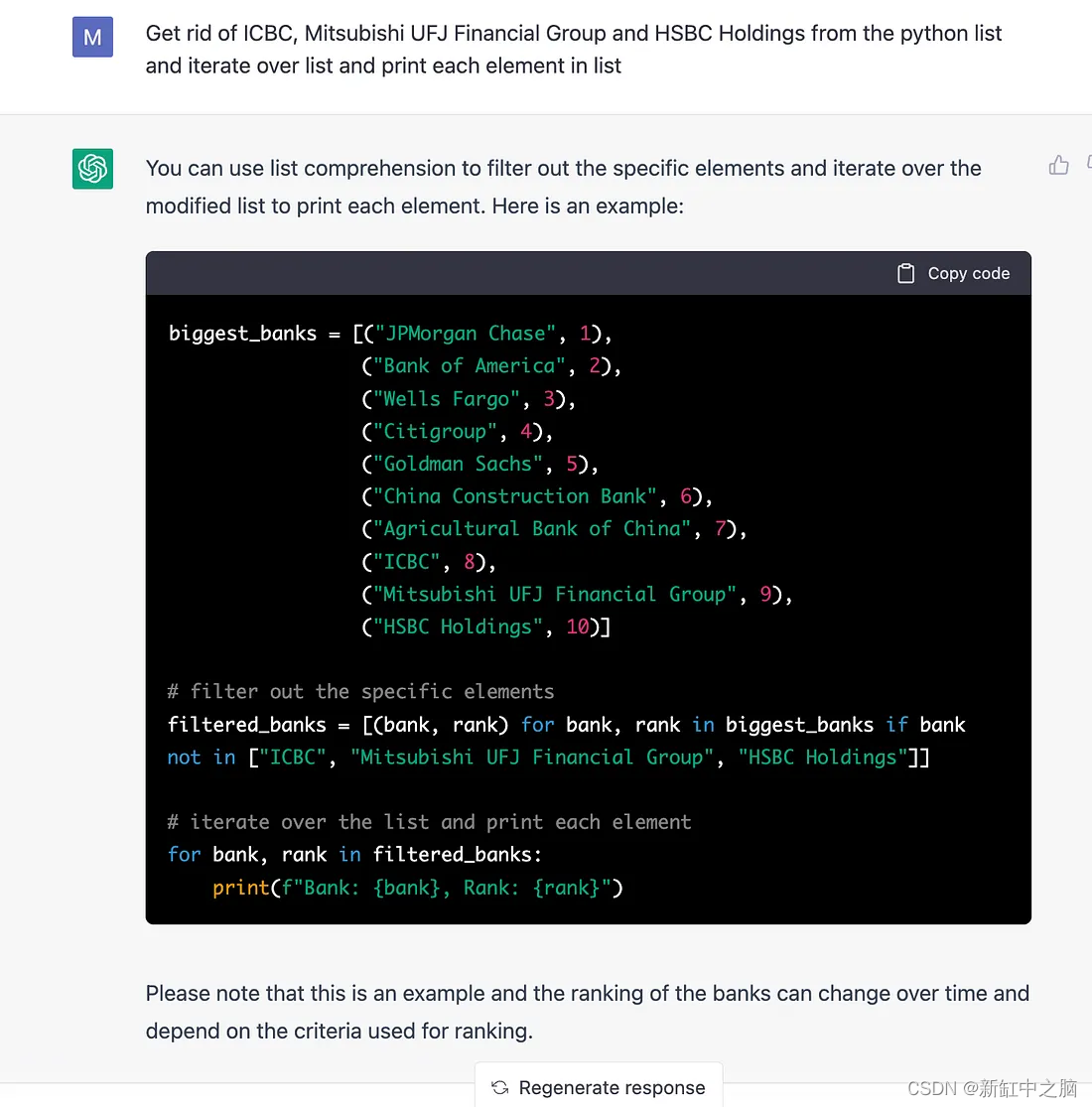
此外,我们可以继续这个上下文感知之旅,并通过根据之前的提示编写更复杂的逻辑来进一步操纵输出:
ChatGPT 可以帮助你为代码编写清晰简洁的文档,包括项目的 README.md 文件。 通过为模型提供有关你的代码的信息,它可以生成详细的文档来解释它的工作原理和使用方法。
采取的步骤包括:
通过粘贴代码片段并提示建议,ChatGPT 可以帮助完成代码。 这为不同的问题解决技术提供了机会。 通过不断的提示,可以建立一个反馈循环来澄清特定的代码行,这有助于理解和深入了解你可以进行的潜在增强。
鉴于 ChatGPT 使用的是 Large Language Model (LLM),即 Generative Pretrained Transformer,其中“生成”是指模型生成新内容的能力,该模型的底层基础是将大型训练数据集转换为数学 结构。 然后,它会学习该模式并使用它一次迭代地预测一个词,从而为给定的提示创建最佳响应。 这意味着你添加到其中的任何内容都可能用于未来的迭代训练。
在某些真实情况下,为了调查目的而插入代码片段是有意义的。 例如,交叉检查已经在公共领域的开源代码中的错误或不直接或间接披露专有公司机密的代码片段。
“这一切都是有趣的游戏,直到有人做了一些愚蠢的事情。”
以下是一些示例提示,可帮助你简化代码和重构工作:
Code alternative example
input <yourcode>
Simplify below code
input <yourcode>
Refactor this code
input <yourcode>
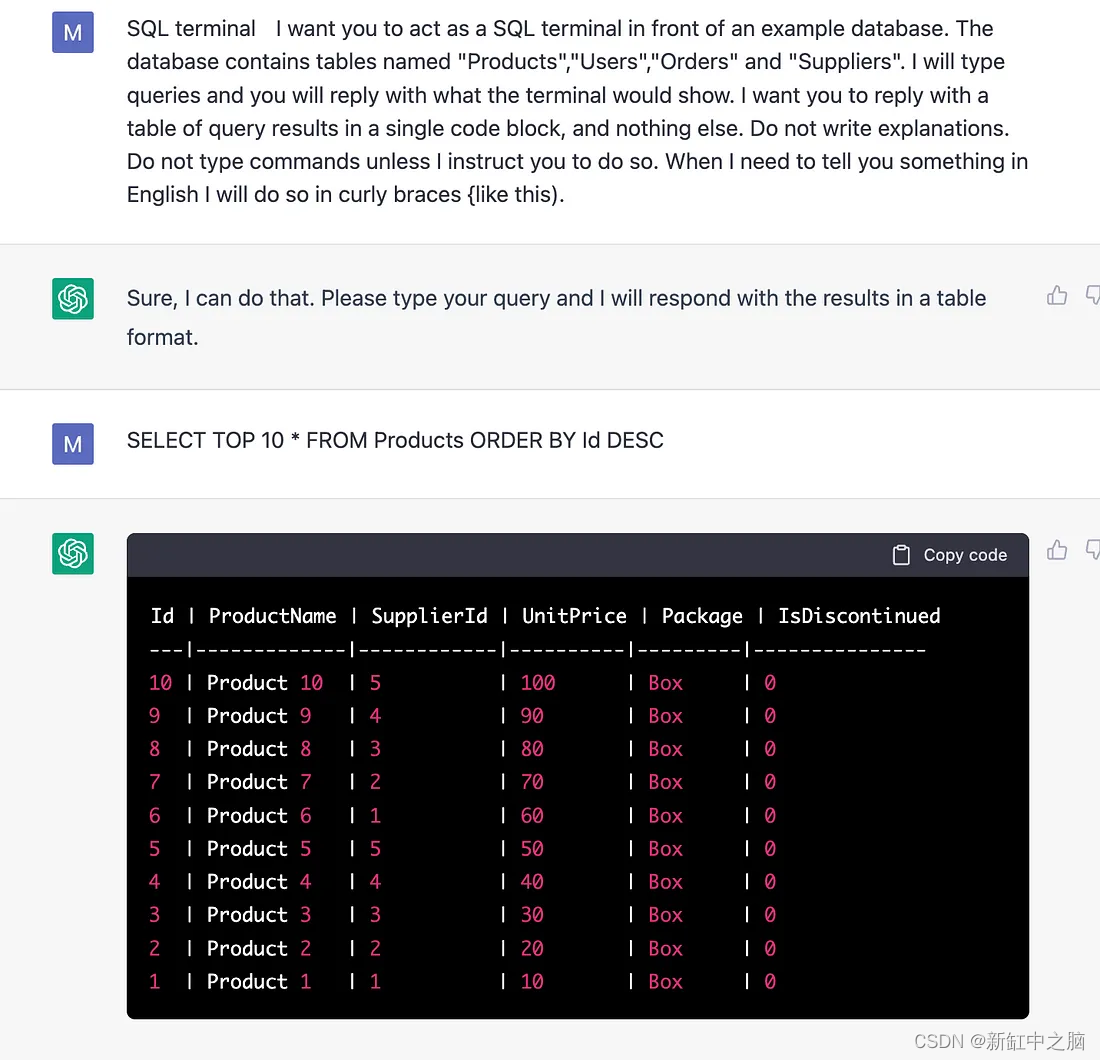
ChatGPT 可以充当 SQL 终端并可以响应提示。 这对于测试很有用,但最好直接通过像 DBeaver 这样的 SQL IDE 来学习。
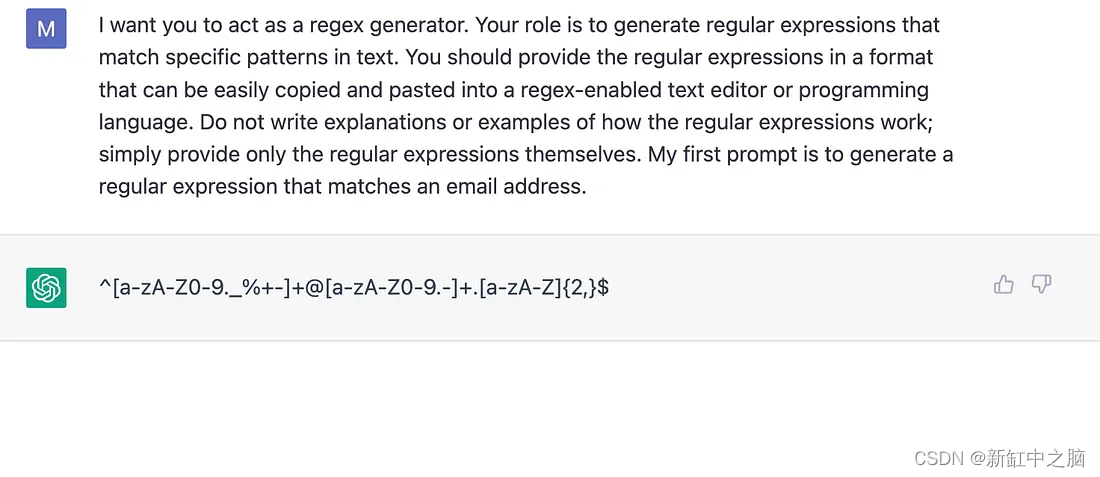
这是另一个用作正则表达式生成器的 ChatGPT 示例。 正则表达式会变得非常复杂; 测试和学习如何解释它们总是好的。
下面显示的第一个提示用于电子邮件验证。 你会注意到输出不符合 RFC2822 标准,该标准取代了 RFC822,并于 2001 年过时。因此,仅生成基本验证。 还可以提出进一步的请求以获得符合 RFC2822 规范的模式。
然后,我们可以在我们最喜欢的 IDE 中执行一些测试,并围绕生成的正则表达式编写测试用例,以确保它符合我们的要求。 请注意,协助并不意味着没有尽职调查、测试代码和验证是否处理了所有验收标准和边缘情况。
import re
def test_email_regex():
pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$"
# Test valid email addresses
assert re.match(pattern, "example@example.com")
assert re.match(pattern, "example.example@example.com")
assert re.match(pattern, "example+example@example.com")
assert re.match(pattern, "example_example@example.com")
assert re.match(pattern, "example%example@example.com")
# Test invalid email addresses
assert not re.match(pattern, "example@.com")
assert not re.match(pattern, "example@com")
assert not re.match(pattern, "example@example.")
assert not re.match(pattern, "@example.com")
assert not re.match(pattern, "example@example..com")
试试上面的 pytest。 你可能会注意到有些东西有点奇怪,这证明了我需要验证的观点。
ChatGPT 可以生成代码并不意味着它可以开箱即用。 诸如“给我写一个简单的 Django 待办事项列表应用程序”之类的提示会在一定程度上为简单的 Django Python 项目创建一个基本结构。 为了让生成的代码正常工作,你必须投入的工作量会更多,这有时可能会违反直觉,由于需要更多代码工作的上下文,可能会减慢你的速度。
如果你没有经验并且对框架和代码没有很好的理解,那么 ChatGPT 生成的任何内容都不会在现场生产环境中发挥作用。 ChatGPT 也不适合那些事先不了解他们请求 ChatGPT 信息的主题的人。
始终交叉检查外部引用并练习结对编程和代码审查,以验证推送到你的存储库中的任何代码。
有一种误解认为 ChatGPT 会神奇地为你简化一切。 像任何工具一样,它的结果完全取决于使用它的人。
我仍然相信编码是一个创造性的过程; ChatGPT 等工具可以协助但不能取代软件开发人员。 他们有能力帮助开发人员更聪明地工作,但也有能力让我们作为软件开发人员自满和脑残。
鉴于 ChatGPT 的准确性有时会受到质疑,在编写测试用例时,这是你可以安全地依赖 ChatGPT 作为灵感来源的领域。 鉴于测试用例不是代码执行的重要组成部分,与利用 ChatGPT 相关的风险可以忽略不计,获得的灵感可以帮助你编写更好的代码。
测试用例也很容易验证正确性,因为如果错误就会失败。 单元测试通常很容易理解,预期的结果是事先知道的。 LLMs 模型正确的可能性非常高。
测试计划是你可以生成的另一件事,这对于与 QA 相关的测试特别有用。 通过利用人工智能,QA 团队可以自动执行重复性任务,并深入了解可生成质量更高的系统的边缘案例。
示例:假设你有一个网站 app.ekyc.com,你在该网站上构建了一些功能并想要计划测试自动化。
你可以向 ChatGPT 提供有关功能组件及其使用的详细信息,并要求它在这种情况下生成测试计划。
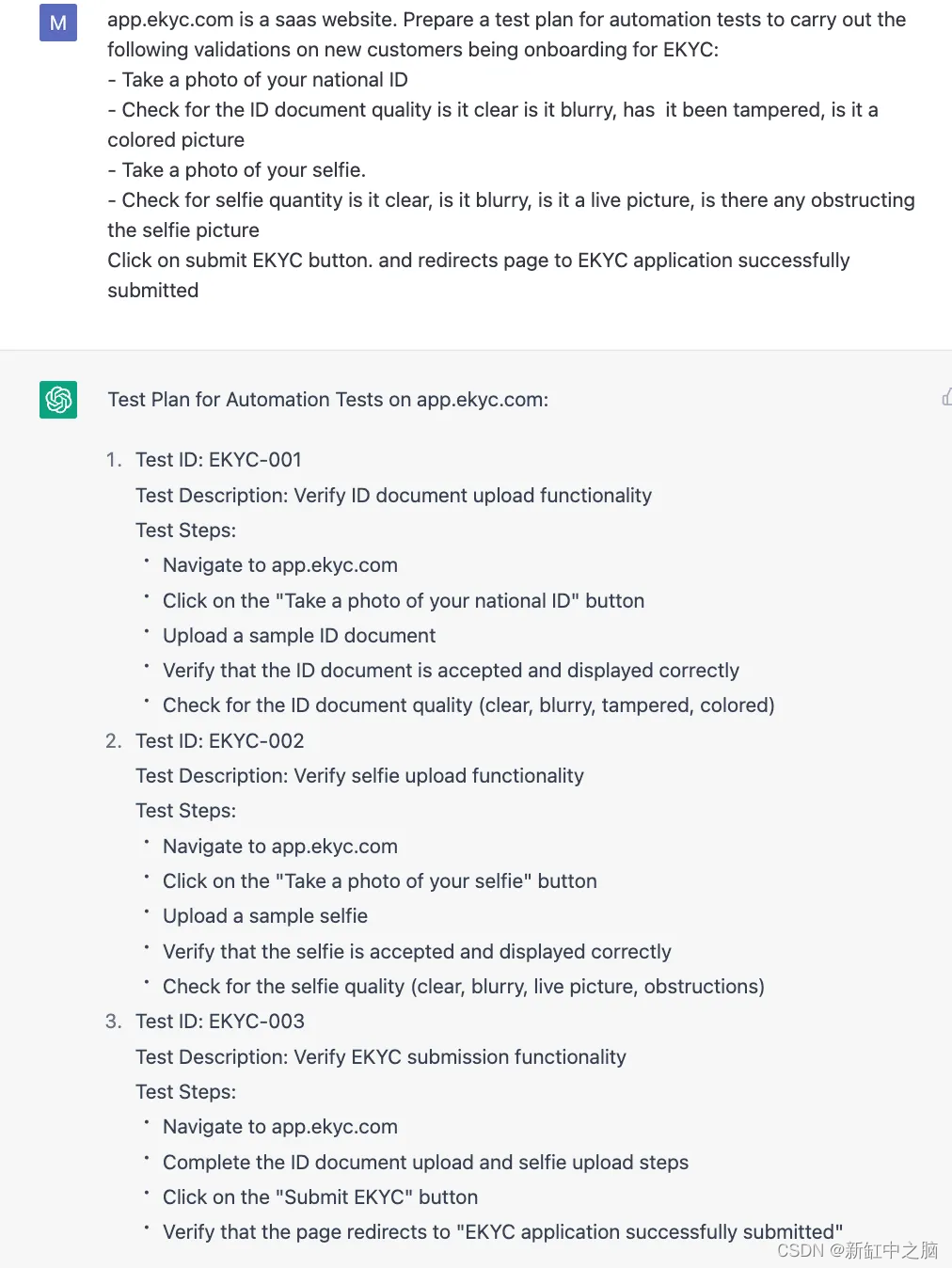
这是简单易读的,可以作为 QA confluence 测试用例验收标准文档的良好起点。 你可以与质量检查团队分享此信息。
现在,假设你希望测试计划采用一种可以轻松复制到 Jira、wiki 或 GitHub 中的测试票格式。 在这种情况下,可以通过在同一线程中添加更多提示来使用 ChatGPT。
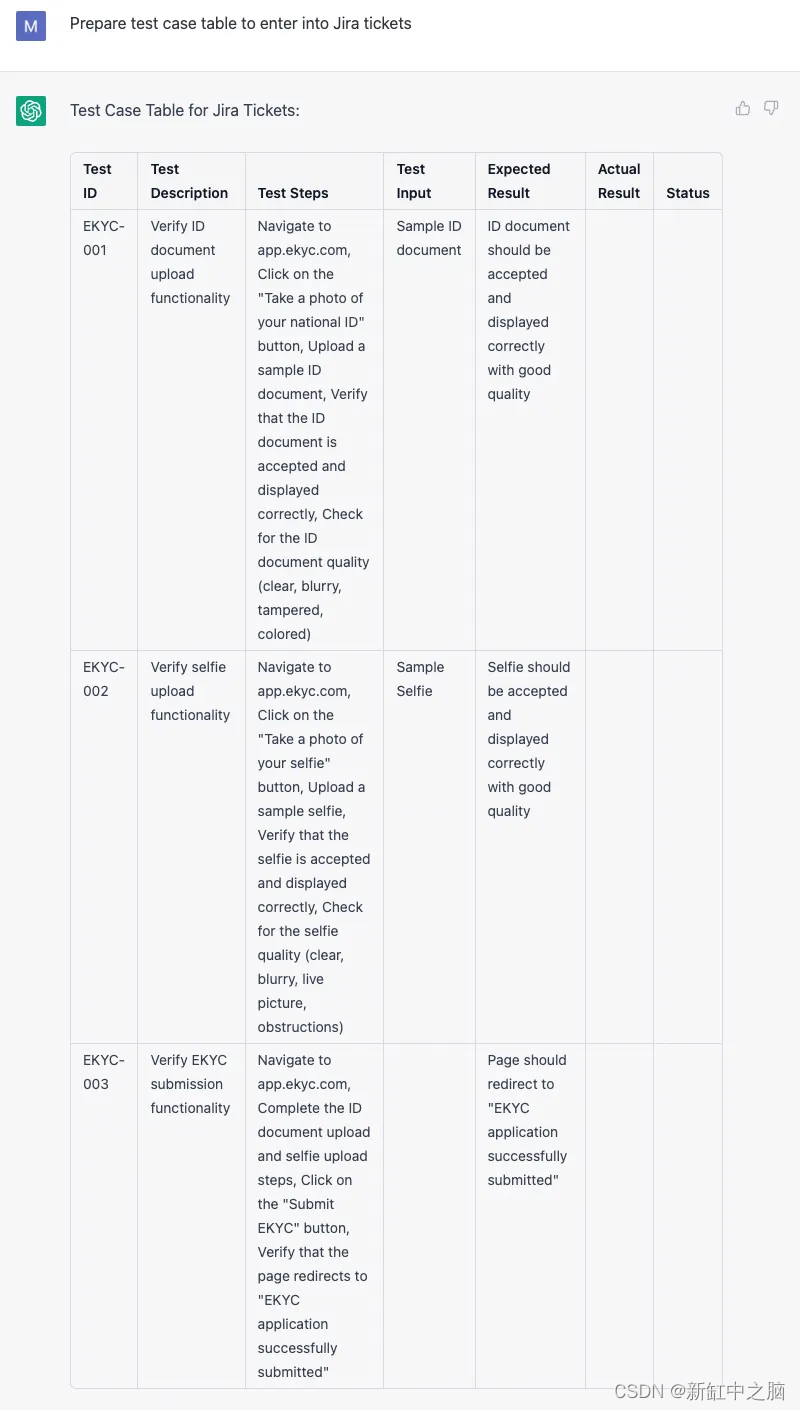
如果你是经验丰富的开发人员,一些使用该工具有意义的情况包括不需要脑力的繁琐工作。
如果希望生成模型能够很好地为你工作,那么提示工程是你需要掌握的一项技能。 无论是使用 DALL-E 等 AI 生成器生成内容和令人惊叹的图像,还是利用 meta Blenderbot、ChatSonic、Bloom 和 Google LaMDA 等鲜为人知的服务。 正确提示将为你提供所需的输出,因此花时间学习如何执行此操作将节省破译垃圾输出的时间。

指示 ChatGPT 成为 X 的提示以得出该 X 的响应。
我希望你扮演一个<描述和精确避免歧义>的人。
作为数据科学家的 ChatGPT:

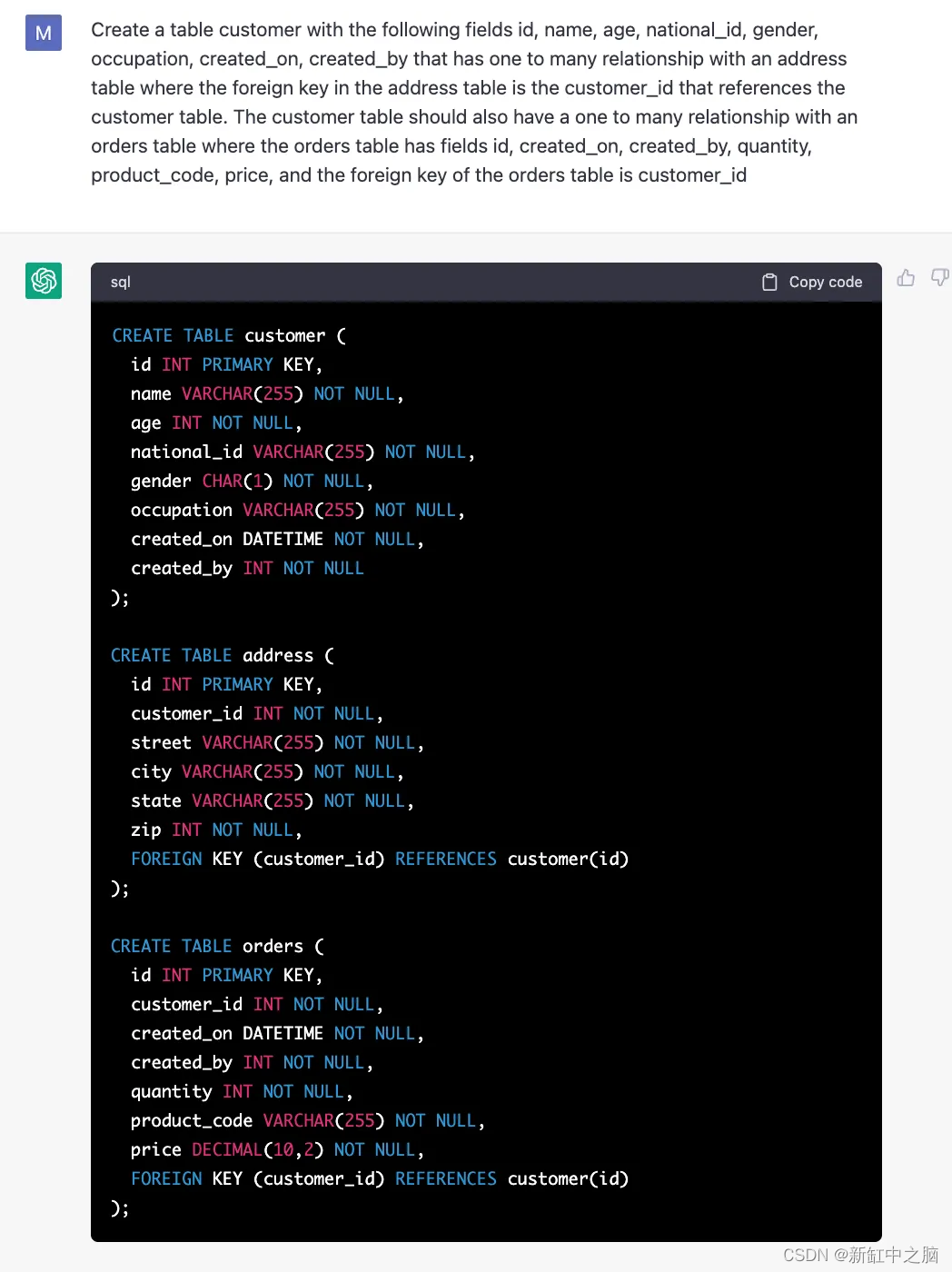
Chat GPT 作为仿真 Linux 终端:
ChatGPT 作为随机数据生成器,例如你需要测试数据样本时:

注意对于随机采样数据生成,如果你注意到结果输出不是唯一的,可能需要给出确切的提示以确保列随机化。
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
我有一个Controller,我想为这个Controller创建一个助手,我可以在不包含它的情况下使用它。我尝试像这样创建一个与Controller同名的助手classCars::EnginesController我创建的助手是moduleCars::EnginesHelperdefcheck_fuellogger.debug("chekingfuel")endend我得到的错误是undefinedlocalvariableormethod`check_fuel'for#有没有我遗漏的约定? 最佳答案 如果你真的想在Controll
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。
我刚刚安装了带有RVM的Ruby2.2.0,并尝试使用它得到了这个:$rvmuse2.2.0--defaultUsing/Users/brandon/.rvm/gems/ruby-2.2.0dyld:Librarynotloaded:/usr/local/lib/libgmp.10.dylibReferencedfrom:/Users/brandon/.rvm/rubies/ruby-2.2.0/bin/rubyReason:Incompatiblelibraryversion:rubyrequiresversion13.0.0orlater,butlibgmp.10.dylibpro