Mapreduce引擎不同,Spark是基于内存的分布式计算引擎,其内置强大的内存管理机制,保证数据优先内存处理,并支持数据磁盘存储。本文将重点探讨Spark的内存管理是如何实现的,内容如下:Driver端提交任务,初始化运行环境(SparkContext等)ResoureManager申请资源(executors及内存资源)worker节点创建executor进程Executor向Driver注册,并等待其分配task任务SparkContext初始化,创建DAG,分配taskset到Executor上执行。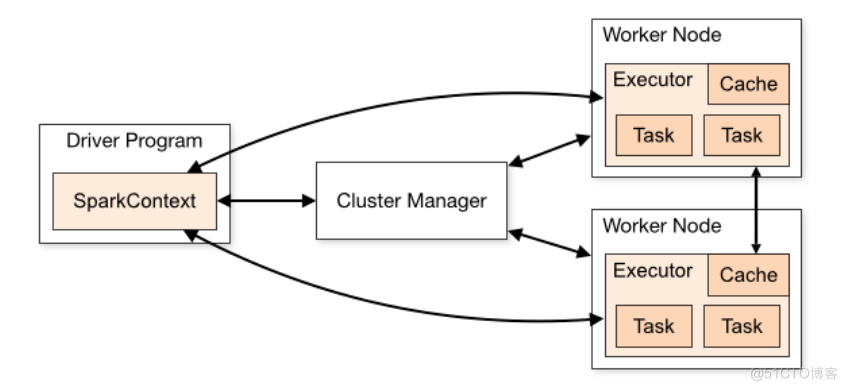 Spark在任务运行过程中,会启动
Spark在任务运行过程中,会启动Driver和Executor两个进程。其中Driver进程除了作为Spark提交任务的执行节点外,还负责申请Executor资源、注册Executor和提交Task等,完成整个任务的协调调度工作。而Executor进程负责在工作节点上执行具体的task任务,并与Driver保持通信,返回结果。由上可见,Spark的数据计算主要在Executor进程内完成,而Executor对于RDD的持久化存储以及Shuffle运行过程,均在Spark内存管理机制下统一进行,其内运行的task任务也共享Executor内存,因此本文主要围绕Executor的内存管理进行展开描述。Spark内存分为堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)。其中堆内内存基于JVM内存模型,而堆外内存则通过调用底层JDK Unsafe API。两种内存类型统一由Spark内存管理模块接口实现。def acquireStorageMemory(...): Boolean //申请存储内存
def acquireExecutionMemory(...): Long //申请执行内存
def releaseStorageMemory(...): Unit //释放执行内存
def releaseStorageMemory(...): Unit //释放存储内存JVM进程,其内部基于JVM的内存管理模型。Spark在其之上封装了统一的内存管理接口MemoryManager,通过对JVM堆空间进行合理的规划(逻辑上),完成对象实例内存空间的申请和释放。保证满足Spark运行机制的前提下,最大化利用内存空间。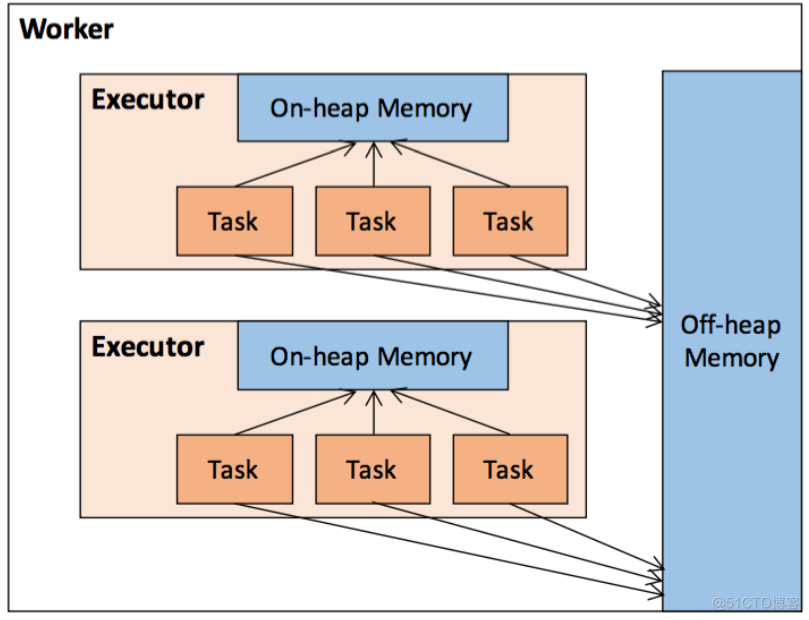
Spark中堆内内存参数有:
1. 这里涉及到的JVM堆空间概念,简单描述就是在程序中,关于对象实例|数组的创建、使用和释放的内存,都会在JVM中的一块被称作为"JVM堆"内存区域内进行管理分配。2. Spark程序在创建对象后,JVM会在堆内内存中分配一定大小的空间,创建Class对象并返回对象引用,Spark保存对象引用,同时记录占用的内存信息。
-executor-memory-executor-memory或-spark-executor-memory。通常是任务提交时在参数中进行定义,且与-executor-cores等相关配置一起被提交至ResourceManager中进行Executor的资源申请。在Worker节点创建一定数目的Executor,每个Executor被分配-executor-memory大小的堆内内存。Executor的堆内内存被所有的Task线程任务共享,多线程在内存中进行数据交换。Spark堆内内存主要分为Storage(存储内存)、Execution(执行内存)和Other(其他) 几部分。1.6在堆内内存的基础上引入了堆外内存,进一步优化了Spark内存的使用率。其实如果你有过Java相关编程经历的话,相信对堆外内存的使用并不陌生。其底层调用Spark在2.x之后,摒弃了之前版本的基于C的JDK Unsafe类方法,通过指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等。
Tachyon,采用Java中常见的基于JDK Unsafe API来对堆外内存进行管理。此模式不在JVM中申请内存,而是直接操作系统内存,减少了JVM中内存空间切换的开销,降低了GC回收占用的消耗,实现对内存的精确管控。堆外内存默认情况下是不开启的,需要在配置中将spark.memory.offHeap.enabled设为True,同时配置spark.memory.offHeap.size参数设置堆大小。对于堆外内存的划分,仅包含Execution(执行内存)和Storage(存储内存)两块区域,且被所有task线程任务共享。
静态管理(Static Memory Manager)模式,Execution内存和Storage内存的分配占比全部是静态的,其值为系统预先设置的默认参数。在Spark1.6后,为了考虑内存管理的动态灵活性,Spark的内存管理改为统一管理(Unified Memory Manager)模式,支持Storage和Execution内存动态占用。至于静态管理方式任然被保留,可通过spark.memory.useLegacyMode参数启用。 堆内内存空间整体被分为
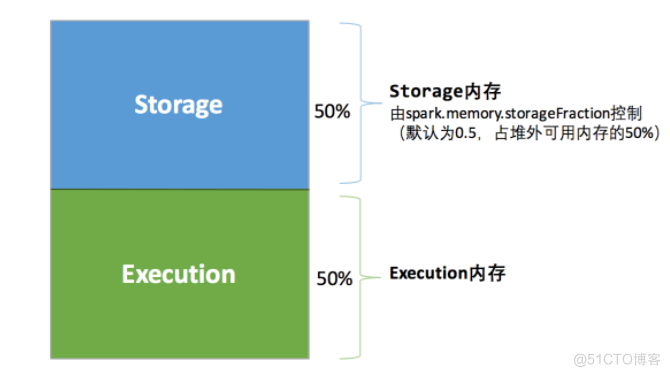
堆内内存空间整体被分为Storage(存储内存)、Execution(执行内存)、Other(其他内存)三部分,默认按照6:2:2的比率划分。其中Storage内存区域参数: spark.storage.memoryFraction(默认为0.6),Execution内存区域参数: spark.shuffle.memoryFraction(默认为0.2)。Other内存区域主要用来存储用户定义的数据结构、Spark内部元数据,占系统内存的20%。在Storage内存区域中,10%的大小被用作Reserved预留空间,防止内存溢出情况,由参数: spark.shuffle.safetyFraction(默认0.1)控制。90%的空间当作可用的Storage内存,这里是Executor进行RDD数据缓存和broadcast数据的内存区域,参数和Reserved一致。还有一部分Unroll区域,这一块主要存储Unroll过程的数据,占用20%的可用Storage空间。Execution内存区域中,20%的大小被用作Reserved预留空间,防止OOM和其他内存不够的情况,由参数:
Unroll过程:
RDD在缓存到内存之前,partition中record对象实例在堆内other内存区域中的不连续空间中存储。RDD的缓存过程中, 不连续存储空间内的partition被转换为连续存储空间的Block对象,并在Storage内存区域存储,此过程被称作为Unroll(展开)。
spark.shuffle.safetyFraction(默认0.2)控制。80%的空间当作可用的Execution内存,缓存shuffle过程的中间数据,参数: spark.shuffle.safetyFraction(默认0.8)。计算公式
可用的存储内存 =
systemMaxMemory
* spark.storage.memoryFraction
* spark.storage.safetyFraction
可用的执行内存 =
systemMaxMemory
* spark.shuffle.memoryFraction
* spark.shuffle.safetyFraction
 相较于堆内内存,堆外内存的分配较为简单。堆外内存默认为
相较于堆内内存,堆外内存的分配较为简单。堆外内存默认为384M,由系统参数spark.yarn.executor.memoryOverhead设定。整体内存分为Storage和Execution两部分,此部分分配和堆内内存一致,由参数: spark.memory.storageFaction决定。堆外内存一般存储序列化后的二进制数据(字节流),在存储空间中是一段连续的内存区域,其大小可精确计算,故此时无需设置预留空间。3. 总结youlong525内存失衡等问题,Spark在1.6之后使用了一种新的内存管理模式—Unified Memory Manager(统一内存管理)。在新模式下,移除了旧模式下的Executor内存静态占比分配,启用了内存动态占比机制,并将Storage和Execution划分为统一共享内存区域。1. 堆内内存 堆内内存整体划分为
堆内内存整体划分为Usable Memory(可用内存)和Reversed Memory(预留内存)两大部分。其中预留内存作为OOM等异常情况的内存使用区域,默认被分配300M的空间。可用内存可进一步分为(Unified Memory)统一内存和Other内存其他两部分,默认占比为6:4。统一内存中的Storage(存储内存)和Execution(执行内存)以及Other内存,其参数及使用范围均与静态内存模式一致,不再重复赘述。只是此时的Storage、Execution之间启用了动态内存占用机制。2. 堆外内存
动态内存占用机制
- 设置内存的初始值,即Execution和Storage均需设定各自的内存区域范围(默认参数0.5)
- 若存在一方内存不足,另一方内存空余时,可占用对方内存空间
- 双方内存均不足时,需落盘处理
- Execution内存被占用时,Storage需将此部分转存硬盘并归还空间
- Storage内存被占用时,Execution无需归还
 和静态管理模式分配一致,堆外内存默认值为384M。整体分为Storage和Execution两部分,且启用
和静态管理模式分配一致,堆外内存默认值为384M。整体分为Storage和Execution两部分,且启用动态内存占用机制,其中默认的初始化占比值均为0.5。计算公式
可用的存储&执行内存 =
(systemMaxMemory -ReservedMemory)
* spark.memoryFraction
* spark.storage.storageFraction
(启用内存动态分配机制,己方内存不足时可占用对方)Driver端提交程序,并向Yarn申请ApplicationAppMaster向Yarn ResourceManager申请资源(Container)var executorMemory = 1024
val MEMORY_OVERHEAD_FACTOR = 0.10
val MEMORY_OVERHEAD_MIN = 384
// Executo堆外内存
val executorMemoryOverhead =
sparkConf.getInt("spark.yarn.executor
.memoryOverhead",
math.max((MEMORY_OVERHEAD_FACTOR
* executorMemory).toInt
, MEMORY_OVERHEAD_MIN))
// Executor总分配内存
val executorMem= args.executorMemory
+ executorMemoryOverhead -executor-memory=5g。spark-submit
--master yarn-cluster
--name test
--executor-memory 5g
--driver-memory 5gmemoryMem=args.executorMemory(5120) + executorMemoryOverhead(512) = 5632M然而事实上查看
Yarn UI上的内存却不是这个数值?这是因为Yarn默认开启了资源规整化。1. Yarn的资源规整化Yarn会根据最小可申请资源数、最大可申请资源数和规整化因子综合判断当前申请的资源数,从而合理规整化应用程序资源。程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值
公式: ceil(a/b)*b
(a是程序申请资源,b为规整化因子)yarn.scheduler.minimum-allocation-mb:
最小可申请内存量,默认是1024
yarn.scheduler.minimum-allocation-vcores:
最小可申请CPU数,默认是1
yarn.scheduler.maximum-allocation-mb:
最大可申请内存量,默认是8096
yarn.scheduler.maximum-allocation-vcores:
最大可申请CPU数,默认是45632,不是规整因子(1024)的整数倍,因此需要重新计算:memoryMem= ceil(5632/1024)*1024=6144M2. Yarn模式的Driver内存分配差异Yarn Client 和 Cluster 两种方式提交,Executor和Driver的内存分配情况也是不同的。Yarn中的ApplicationMaster都启用一个
Container来运行;Client模式下的Container默认有1G内存,1个cpu核,Cluster模式的配置则由driver-memory和driver-cpu来指定,也就是说Client模式下的driver是默认的内存值;Cluster模式下的dirver则是自定义的配置。3. 总结Apache Yarn作为分布式资源管理器,有自己内存管理优化机制。当在Yarn部署Spark程序时,需要同时考虑两者的内存处理机制,这是生产应用中最容易忽视的一个知识点。
- cluster模式(driver-memory:5g):ceil(a/b)*b可得driver内存为6144M
- client模式(driver-memory:5g):ceil(a/b)*b可得driver内存为5120M
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这是我在ActiveAdmin中的自定义页面ActiveAdmin.register_page"Settings"doaction_itemdolink_to('Importprojects','settings/importprojects')endcontentdopara"Text"endcontrollerdodefimportprojectssystem"rakedataspider:import_projects_ninja"para"OK"endendend我想做的是,当我单击“导入项目”按钮时,我想在Controller中执行rake任务。但是我无法访问该方法。可能是什
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源