Linux一切皆文件:通过文件的方式来管理磁盘
linux一切皆文件,所以磁盘也表现为文件。每个硬盘文件命名方式和磁盘的类型有关。硬盘文件在内核中自动生成识别,并存放在/dev这个文件下面。
lvm:逻辑卷 让空间的大小动态化
硬盘类型不同,设备文件名也不同:
echo '- - -' > /sys/class/scsi_host/hostn/scan

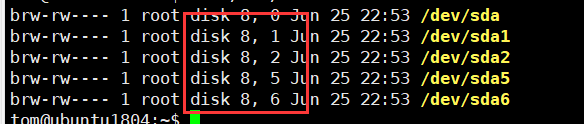
两个数字:第一个数字:表示设备的类型,第二个数字表示是第几个设备
设备文件属于特殊文件不能用传统的方式来进行拷贝。需要添加-a选项来保留属性。
/dev/null:属于字符设备文件
块设备的数据访问单位是以块为单位(比如一块512字节),字符设备的数据访问单位是以字符为单位。块设备通常具有缓存
创建设备文件: mknod 设备名 设备类型 主类型 设备编号
硬盘接口类型:
SATA: 一般的家用电脑的接口 服务器:SAS接口 (SATA和SAS兼容的)
SCSI:早期服务器用的接口
IDE: 早期家用电脑的接口(淘汰了,速度很慢)
USB: 全称:Universal Serial Bus,中文叫通用串行总线
M.2: 原名NGFF,即次世代外形标准。可以兼容多种通信协议,如sata、PCIe、USB等
支持Nvme协议硬盘速度是最快的
LFF:3.5寸(台式机里面的那种大小) L---大的意思
SFF:2.5寸,和笔记本的2.5寸硬盘不一样(现在流行小硬盘), s---小的意思
机械硬盘:HDD(Hard Disk Drive) 有物理盘片这些
固态硬盘:SSD(Solid State Drive) ,全是半导体芯片组成
磁头(head):和盘面的数量相等。
磁道(track):盘面是一圈一圈磁道组成,最外圈是0磁道
扇区(sector):每个磁道划分为很多小块,这个小块叫做扇区,扇区的大小固定的,是512个字节。扇区的空间大小:扇区数量*512
柱面(cylinder):盘面之间的所有0磁道就组成了0柱面,依次类推。柱面存放的数据容量:扇区数512字节=一个磁道的空间、刺刀空间磁头数(磁头数和盘面数一样的,有几个盘面就有几个磁头)
硬盘的三维 --- CHS:cylinder+head+sector 柱面+磁头+扇区
ZBR:区位记录磁盘扇区结构,扇区宽度一样,每一个磁道的扇区多少不一样(里面的扇区数量少于外面的)
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
我想使用PostgreSQL中的point类型。我已经完成了:railsgmodelTestpoint:point最终的迁移是:classCreateTests当我运行时:rakedb:migrate结果是:==CreateTests:migrating====================================================--create_table(:tests)rakeaborted!Anerrorhasoccurred,thisandalllatermigrationscanceled:undefinedmethod`point'for#/hom