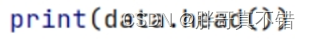说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
SARIMA是季节性自回归移动平均模型。对于周期性时间序列,首先需要去除周期性,去除的方式是在周期间隔上做一次ARIMA,此时可以得到一个非平稳非周期性的时间序列,然后在此基础之上再一次使用ARIMA进行分析。
本项目应用SARIMA算法进行建模、预测、分析,形成一个完整的项目实战内容。
2.数据获取
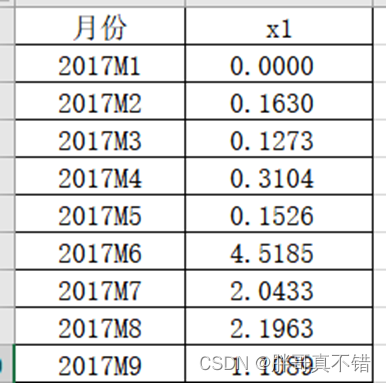
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有2个变量,数据中无缺失值,共65条数据。
关键代码:
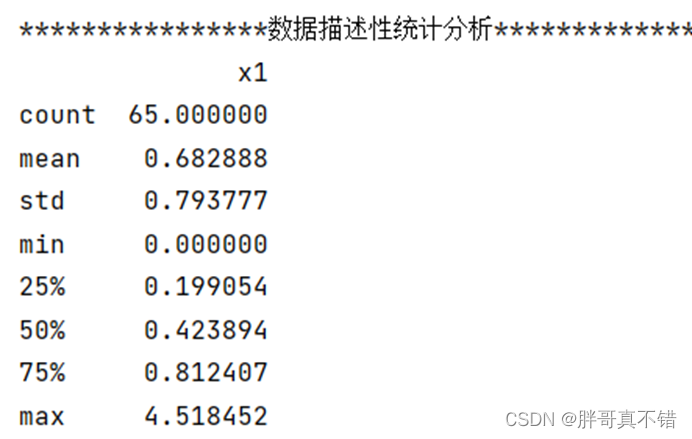
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:
4.探索性数据分析
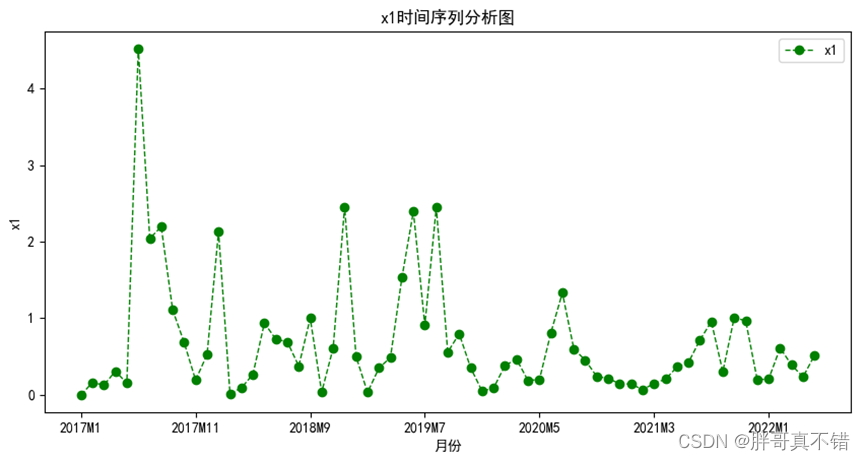
4.1 x1变量时间序列分析图
5.构建SARIMA时序模型
5.1 SARIMA模型关键点介绍
SARIMA结构参数有七个:(p,d,q) (P,D,Q,s)
p:代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做AR/Auto-Regressive项。
d:代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项。
q:代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/Moving Average项。
P: 周期性自回归阶数。
D: 周期性差分阶数。
Q: 周期性移动平均阶数。
s: 周期时间间隔。
5.2序列平稳性检验
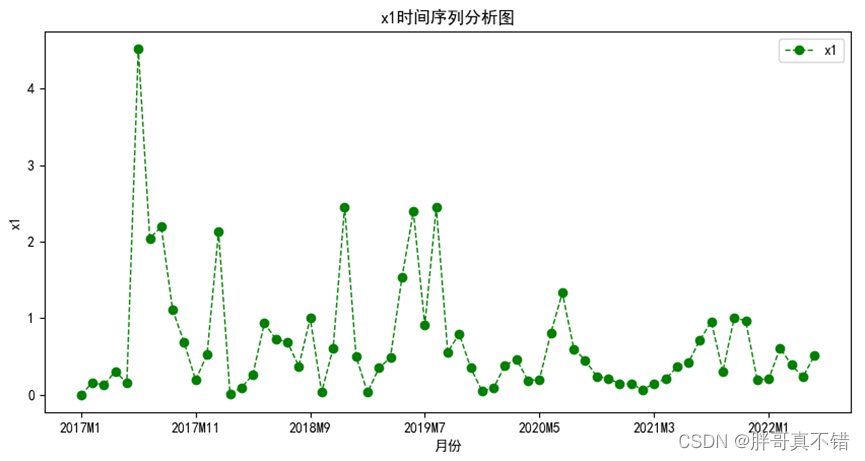
图5.2-1 原始序列的时序图
此图显示该序列2017年波动很大,2021年到2022年波动相对平稳,可以判断为弱平稳序列。
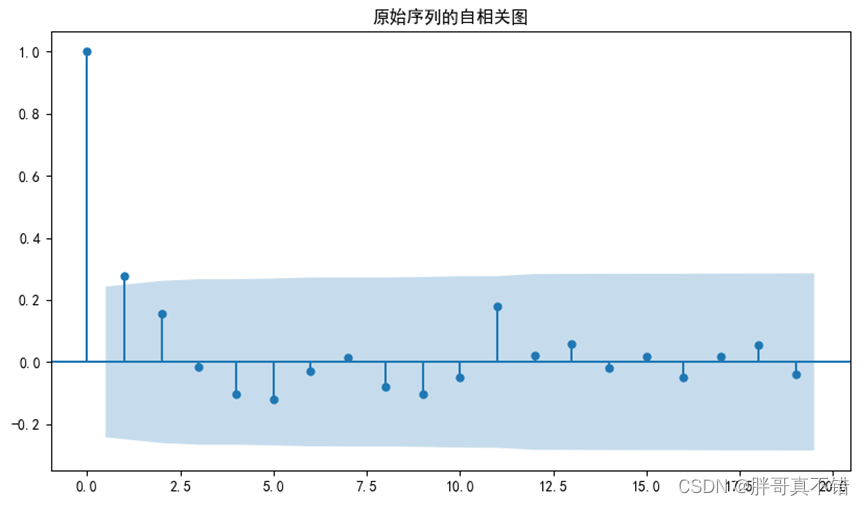
图5.2-2 原始序列的自相关图
此图的自相关图显示自相关系数整体在-0.2到0.2之间徘徊,说明序列间具有弱短期相关性。
表5.2-1 原始序列的单位根检验
此表单位根检验统计量对应的p值小于0.05,说明该序列为平稳序列。
5.3对原始序列进行一阶差分,并进行平稳性和白噪声检验
1)对一阶差分后的序列再次做平稳性判断。
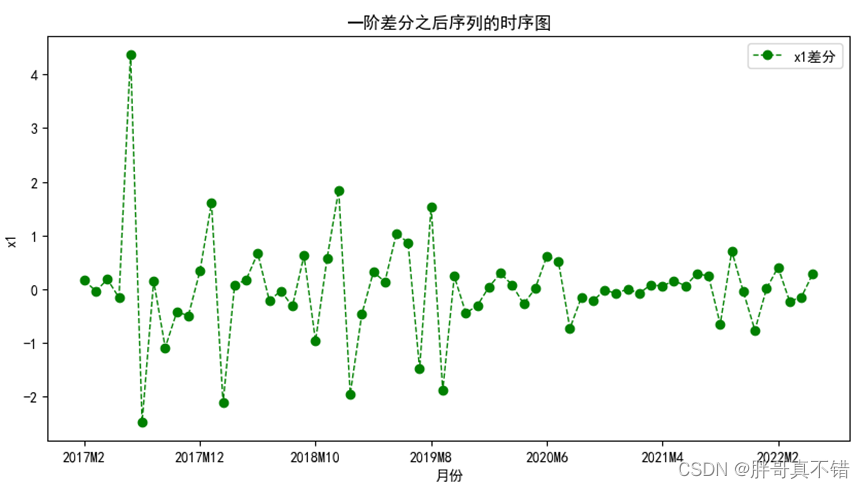
图5.3-1 一阶差分之后序列的时序图
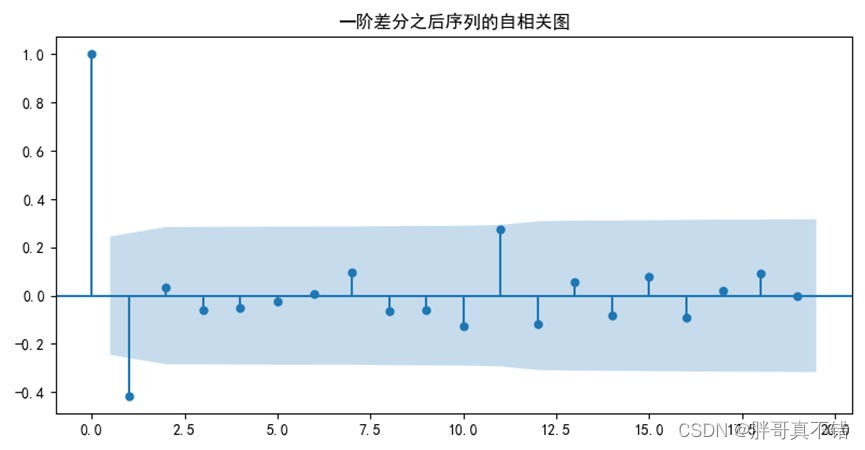
图5.3-2 一阶差分之后序列的自相关图
表5.3-1 一阶差分之后序列的单位根检验
结果显示,一阶差分之后序列的时序图在均值附近比较平稳地波动、自相关图有很强的短期相关性、单位根检验p值小于0.05,所以一阶差分之后的序列是平稳序列。
2)对一阶差分后的序列做白噪声检验
表5.3-2 一阶差分之后序列的白噪声检验
此表输出的p值远小于0.05,所以一阶差分之后的序列是平稳非白噪声序列。
5.4对一阶差分后的序列拟合SARIMA模型
下面进行模型定阶。模型定阶就是确定p、d、q、P、D、Q、s。
第一种方法:人为识别,根据下图进行模型定阶。
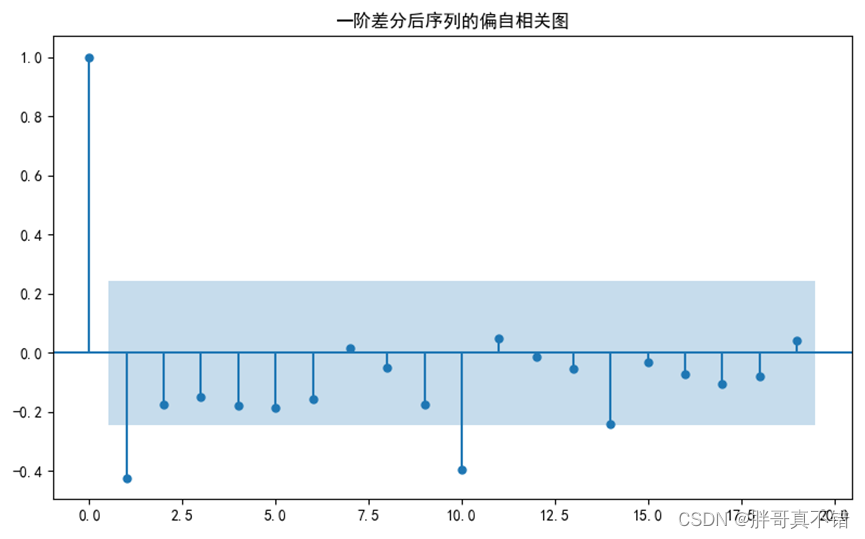
图5.4-1 一阶差分后序列的偏自相关图
一阶差分后自相关图显示出1阶截尾,偏自相关图显示出拖尾性,所以可以考虑用MA(1)模型拟合1阶差分后的序列,即对原始序列建立SARIMA(order=(0,1,1))模型。
第二种方法:相对最优模型识别(建议大家使用这种方式)。
计算SARIMA(order=(p,d,q), seasonal_order=(P,D,Q,s)),采用多种组合的方式,获取所有组合的BIC信息量,取其中BIC信息量达到最小的模型阶数。
计算完成BIC矩阵如下:
当p值为0、q值为0、P值为0、Q值为1、s值为12时,最小BIC值为143.5571。此时模型定阶完成。
用AR(0)模型拟合一阶差分后的序列,即对原始序列建立SARIMA(order=(0,0,0), seasonal_order=(0,1,1,12))模型。下面对一阶差分后的序列拟合SARIMA模型进行分析:
1.参数检验和参数估计见下表:
表5.4-1 模型参数
2.模型检验之残差检验:
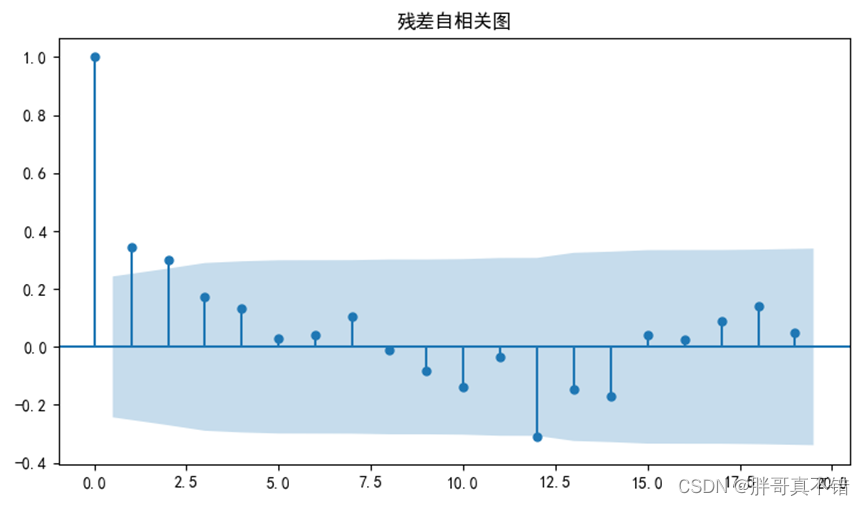
图5.4-2 残差自相关图
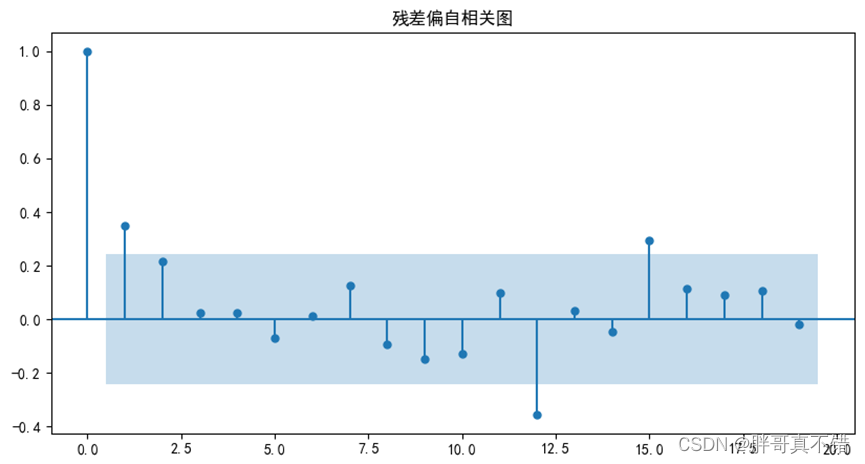
图5.4-3 残差偏自相关图
图5.4-4 残差偏自相关图
D-W检验:
DW值显著的接近于0或4时,则存在自相关性,而接近于2时,则不存在(一阶)自相关性。
D-W检验的结果为:1.3132。因此,模型预测的残差不存在自相关性性,这说明拟合的模型预测效果很好。
残差序列的白噪声检验结果为:([8.01950276]), ([0.00462763]),可以看出p值为0.00462, P<0.05。
5.5 SARIMA模型预测
应用SARIMA(order=(0,0,0), seasonal_order=(0,1,1,12))对项目数据做为期5个月的预测,结果如下表所示:
表5.5-1 预测未来5个月的数据
6.结论与展望
综上所述,本文采用了季节性自回归移动平均模型算法来构建时间序列分析模型,通过计算BIC信息量找到最优的参数值,最终证明了我们提出的模型效果很好。
本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss