多目标优化问题可以描述如下: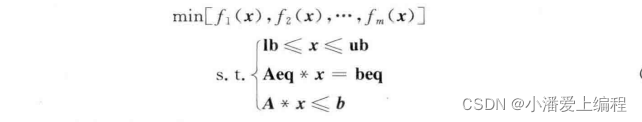
其中,f(x) 为待优化的目标函数;x 为 待优化的变量;lb 和 ub 分别为变量 x 的下限和上限约束;Aeq * x = beq 为变量 x 的线性等式约束;A * x <= b 为变量 x 的线性不等式约束。

在上图所示的优化问题中,目标函数 f1 和 f2 是相互矛盾的。因为 A1 < B1 且 A2 > B2,也就是说,某一个目标函数的提高需要以另一个目标函数的降低作为代价,称这样的解 A 和解 B 是非劣解,或者说是 Pareto 最优解。多目标优化算法的目的就是要寻找这些 Pareto 最优解。
目前的多目标优化算法有很多,Kalyanmoy Deb 的带精英策略的快速非支配排序遗传算法(nondominated sorting genetic algorithm II,NSGA- II)无疑是其中应用最为广泛也是最为成功的一种。MATLAB R2009a 版本提供的函数 gamultiobj 所采用的算法就是基于 NSGA - II 改进的一种多目标优化算法(a variant of NSGA - II)。本案例将以函数 gamultiobj 为基础,对基于遗传算法的多目标优化算法进行详细分析,并介绍函数gamultiobj的使用。
1、支配(dominnate)与非劣(non - inferior)
在多目标优化问题中,如果个体 p 至少有一个目标比个体 q 的好,而且个体 p 的所有目标都不比个体 q 的差,那么称个体 p 支配个体 q(p dominates q),或者称个体 q 受个体 p 支配(qis dominated by p),也可以说,个体 p 非劣于个体 q(p is non - inferior to q)。
2、序值(rank)和前端(front)
如果 p 支配 q,那么 p 的序值比 q 的低。如果 p 和 q 互不支配,或者说, p 和 q 相互非劣,那么 p 和 q 有相同的序值。序值为 1 的个体属于第一前端,序值为 2 的个体属于第二前端,依次类推。显然,在当前种群中,第一前端是完全不受支配的,第二前端受第一前端中个体的支配。这样,通过排序,可以将种群中的个体分到不同的前端。
3、拥挤距离(crowding distance)
拥挤距离用来计算某前端中的某个体与该前端中其他个体之间的距离,用以表征个体间的拥挤程度。显然,拥挤距离的值越大,个体间就越不拥挤,种群的多样性就越好。需要指出的是,只有处于同一前端的个体间才需要计算拥挤距离,不同前端之间的个体计算拥挤距离是没有意义的。
4、最优前端个体系数(ParetoFraction)
最优前端个体系数定义为最优前端中的个体在种群中所占的比例,即最优前端个体数 = min { ParetoFraction * 种群大小,前端中现存的个体数目 },其取值范围为 0~1。需要指出的是,ParetoFraction 的概念是函数 gamultiobj 所特有的,在 NSGA - II 中是没有的,这也是为什么称函数 gamultiobj 是一种多目标优化算法的原因。
待优化的多目标问题表述如下:

这里将使用函数 gamultiobj 求解以上多目标优化问题。同函数 ga 的调用一样,函数 gamultiobj 的调用方式也有两种:GUI 方式和命令行方式。
通过以下两种方式可以调出函数 gamultiobj 的 GUI 界面:
(1)在 MATLAB主界面上依次单击 APPS→Optimization,在弹出的 Optimization Tool 对话框的 Solver 中选择 “gamultiobj - Multiobjective optimization using Genetic Algorithm” 。
(2)在 Command Window 中输入:optimtool('gamultiobj') 命令
可以看到,函数 gamultiobj 的 GUI 界面与函数 ga 的 GUI 界面大致相同,仅在以下几个方面存在区别:
(1)前者比后者多了 Distance measure function 和 Pareto front population fraction 两个参数。
(2)前者比后者少了参数 Elite count,这是因为函数 gamultiobj 的精英是自动保留的;前者比后者少了 Scaling function,这是因为函数 gamultiobj 的选择是基于序值和拥挤距离的,故不再需要 Scaling 的处理;函数 gamultiobj 没有非线性约束。
(3)绘图函数不同及下列设置的默认值不同;种群大小(Population size)、选择函数(Selection function)、交叉函数(Crossover function)最大进化代数(Generations)停止代数(Stall generations)适应度函数值偏差(Function tolerance)。
gamultiobj 的命令行调用格式为:
[x, fval] = gamultiobj(fitnessfcn, nvars, A, b, Aeq, beq, lb, ub, options)
其中,x 为函数 gamultiobj 得到的 Pareto 解集;fval 为 x 对应的目标函数值;fitnessfcn 为目标函数句柄,同函数 ga 一样,需要编写一个描述目标函数的 M 文件;nvars 为变量数目;A、b、Aeq、beq 为线性约束,可以表示为 A * x <= B,Aeq * x = beq;lb,ub为上、下限约束,可以表述为 lb <= x <= ub,当没有约束时,用 “ [ ] ” 表示即可;options 中需要对多目标优化算法进行一些设置,即
options = gaoptimset('Param1', value1, 'Param2', value2, ... );其中,Param1,Param2 等是需要设定的参数,如最优前端个体系数、拥挤距离计算函数、约束条件、终止条件等;valuel,value2 等是 Param 的具体值。Param 有专门的表述方式,如最优前端个体系数对应于 ParetoFraction,拥挤距离计算函数对应于 DistanceMeasureFcn 等。
(1)使用函数 gamultiobj 求解多目标优化问题的第一步是编写目标函数的M文件。对于以上问题,函数名为my_first_multi,目标函数代码如下:
function f = my_first_multi(x)
f(1) = x(1)^4 - 10*x(1)^2+x(1)*x(2) + x(2)^4 - (x(1)^2)*(x(2)^2);
f(2) = x(2)^4 - (x(1)^2)*(x(2)^2) + x(1)^4 + x(1)*x(2);(2)使用命令行方式调用 gamultiobj 函数,代码如下:
clear
clc
fitnessfcn = @my_first_multi; % Function handle to the fitness function
nvars = 2; % Number of decision variables
lb = [-5,-5]; % Lower bound
ub = [5,5]; % Upper bound
A = []; b = []; % No linear inequality constraints
Aeq = []; beq = []; % No linear equality constraints
options = gaoptimset('ParetoFraction',0.3,'PopulationSize',100,'Generations',200,'StallGenLimit',200,'TolFun',1e-100,'PlotFcns',@gaplotpareto);
[x,fval] = gamultiobj(fitnessfcn,nvars, A,b,Aeq,beq,lb,ub,options);其中,fitnessfcn 即(1)中定义的目标函数 M 文件,设置的最优前端个体系数 ParetoFrac -tion 为 0.3,种群大小 PopulationSize 为 100,最大进化代数 Generations 为 200,停止代数StallGenLimit 也为 200,适应度函数值偏差 TolFun 为 le - 100,绘制 Pareto 前端。当然,也可以通过 GUI 方式调用函数 gamultiobj,其方法与函数 ga 的调用相同。
可以看到,在基于遗传算法的多目标优化算法的运行过程中,自动绘制了第一前端中个体的分布情况,且分布随着算法进化一代而更新一次。当迭代停止后,得到如下图所示的第一前端个体分布图。

同时, Worksapce 中返回了函数 gamultiobj 得到的 Pareto 解集 x 及与 x 对应的目标函数值。需要说明的是,由于算法的初始种群是随机产生的,因此每次运行的结果不一样。
从上图可以看到,第一前端的 Pareto 最优解分布均匀。返回的 Pareto 最优解个数为 30 个,而种群大小为 100,可见,ParetoFraction 为 0.3 的设置发挥了作用。另外,个体被限制在了 [ -5,5 ] 的上下限范围内。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来