在C语言中,数据类型是指用于存储数据的一组属性,包括数据的范围、精度、占用内存空间大小等等。C语言中的数据类型分为两大类:基本数据类型和派生数据类型
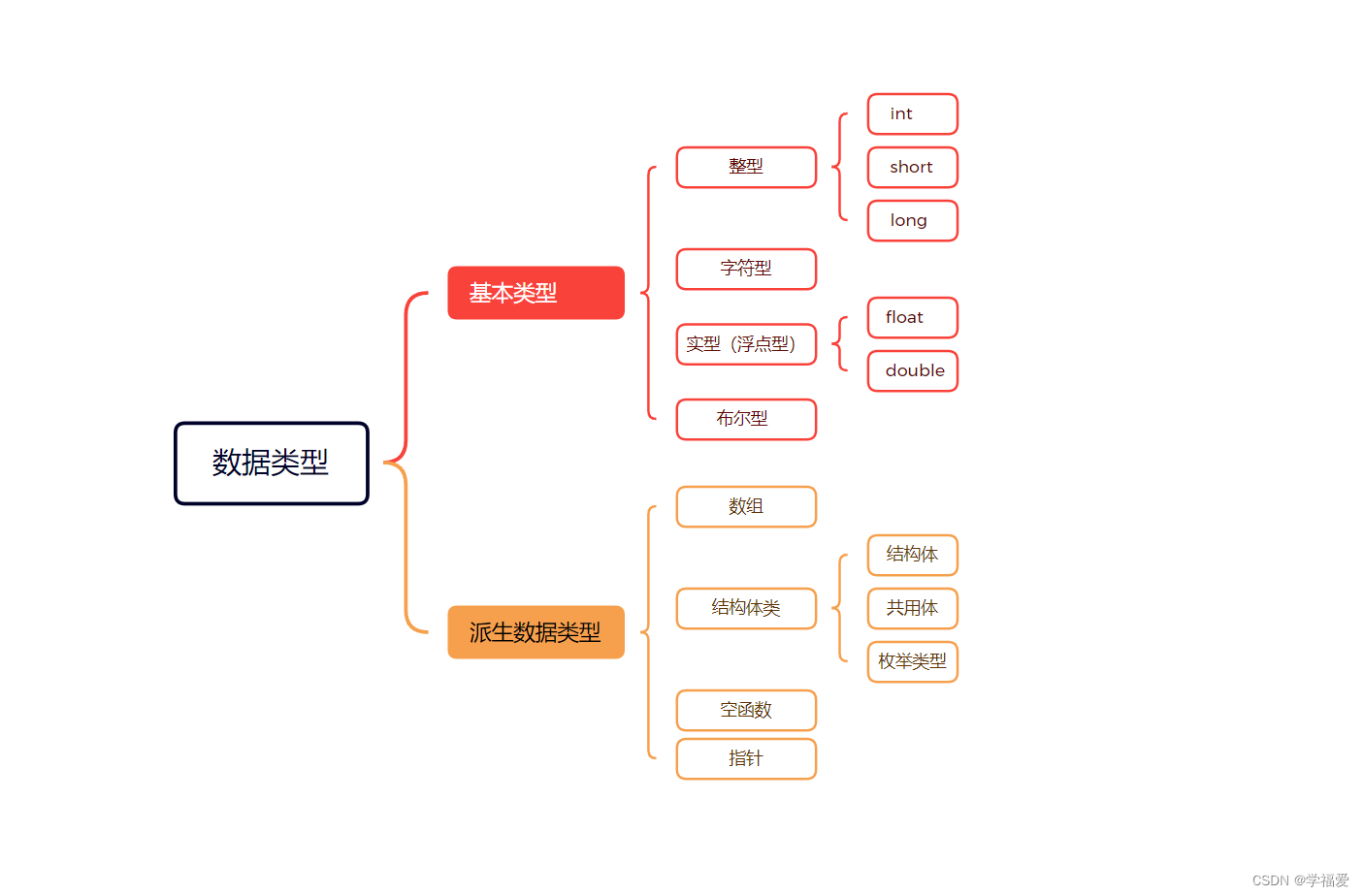
C语言为我们提供了许多种的数据类型,那为什么会有那么多种数据类型呢?举个浅显的例子,你盖房子,总不可能都只用一种型号的砖吧,有些砖需要用来砌墙,有些砖需要用来铺地,如果都只用一种型号的砖,将会造成很多不必要的浪费,而且也不美观 C语言提供众多的数据类型也是一样的, 简单一点的整数数据用Int表示,要求更为精细的用实数浮点型来表示,再到后面甚至是数组,结构体,一切都是为了提高程序的空间利用率,以及效率,正是c语言提供了如此众多的数据类型,才使我们的程序编写更加便利
提起房子,创建变量可以想象成在内存中申请一个房子给你所需要的数值住,而房子的大小就用字节大小来表示,如:Int a=1;就可以想象成在内存中申请一个名为为a的int型的房子,其四个字节大小的房子中住在“1”。
另外,为了便利您接下来的阅读,请让我向你介绍C语言中一个比较重要的运算符:sizeof()。
sizeof()用于获取数据类型或变量在内存中占用的字节数。它是一个单目运算符而不是函数,其返回值是一个无符号值。
一般有两种使用方式
1.sizeof(数据类型)\计算出数据类型在内存中的字节大小
#include<stdio.h>代码示例
int main()
{printf("%d",sizeof(int));以有符号十进制整数形式输出数据类型Int在内存中的字节大小
return 0;
}
代码运行结果

输出结果为:4,这里的返回的数字是一个字节数
2…sizeof(变量)\计算变量在内存中的字节大小
#include<stdio.h>
int main()\\代码示例
{int a=100;
printf("%d",sizeof(a));\\以有符号十进制整数形式输出变量a在内存中的字节大小
return 0;
}
代码运行结果

输出结果为:4,用前文的话来讲因为变量a的“房子”大小为4字节
好了,在经过了对运算符sizeof()的理解后,让我们来取得所以基本数据类型的字节大小
#include<stdio.h>
int main()
{
printf("%d\n", sizeof(short));输出结果为2
printf("%d\n", sizeof(int));输出结果为4
printf("%d\n", sizeof(long));输出结果为4
printf("%d\n", sizeof(long long));输出结果为8
printf("%d\n", sizeof(float));输出结果为4
printf("%d\n", sizeof(double));输出结果为8
printf("%d\n", sizeof(char));输出结果为1
printf("%d\n", sizeof(unsigned short));输出结果为2fanghui
printf("%d\n", sizeof(unsigned int));输出结果为4
printf("%d\n", sizeof(unsigned long));输出结果为4
printf("%d\n", sizeof(unsigned long long));输出结果为8
printf("%d\n", sizeof(unsigned short));输出结果为2
printf("%d\n", sizeof(unsigned char));输出结果为1
return 0;
}
运行结果
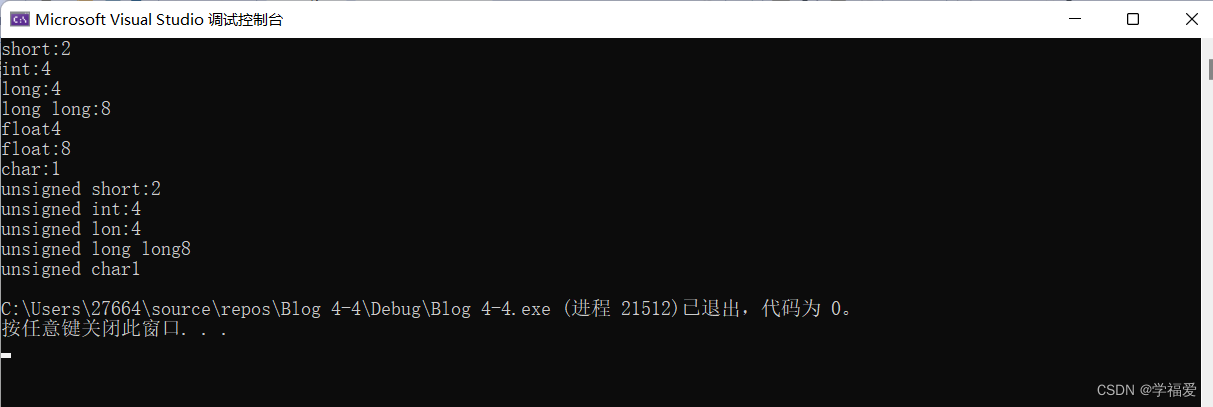
我们将要用这里的数据作为后面表格的数据来源
另外,sizeof()在后期数组的学习中会经常使用,所以最好对它有一个正确的理解
C语言中基本数据类型包括整型、浮点型、字符型和布尔型。其中,整型又可细分为有符号整型和无符号整型,有符号整型包括、short、int和long等类型(也可写为 、signed short 、signed int 、signed long但一般省略signed)无符号整型包括unsigned char、unsigned short、unsigned int和unsigned long四种类型;浮点型包括float和double两种类型;字符型包括char类型;布尔型包括_Bool类型。这些数据类型在C语言中均有特定的关键字表示,如int、char、float等。
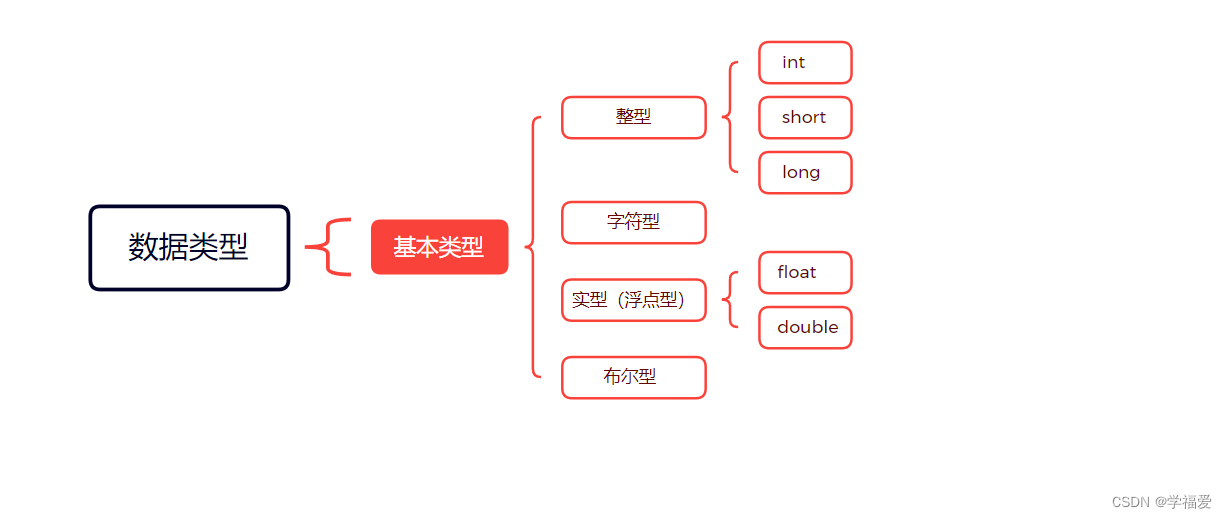
介绍:在C语言中,整型是一种数据类型,表示整数类型的数据。C语言中的整型可以分为有符号整型和无符号整型两种类型。有符号整型可以表示正数、负数和零,而无符号整型只能表示非负整数。
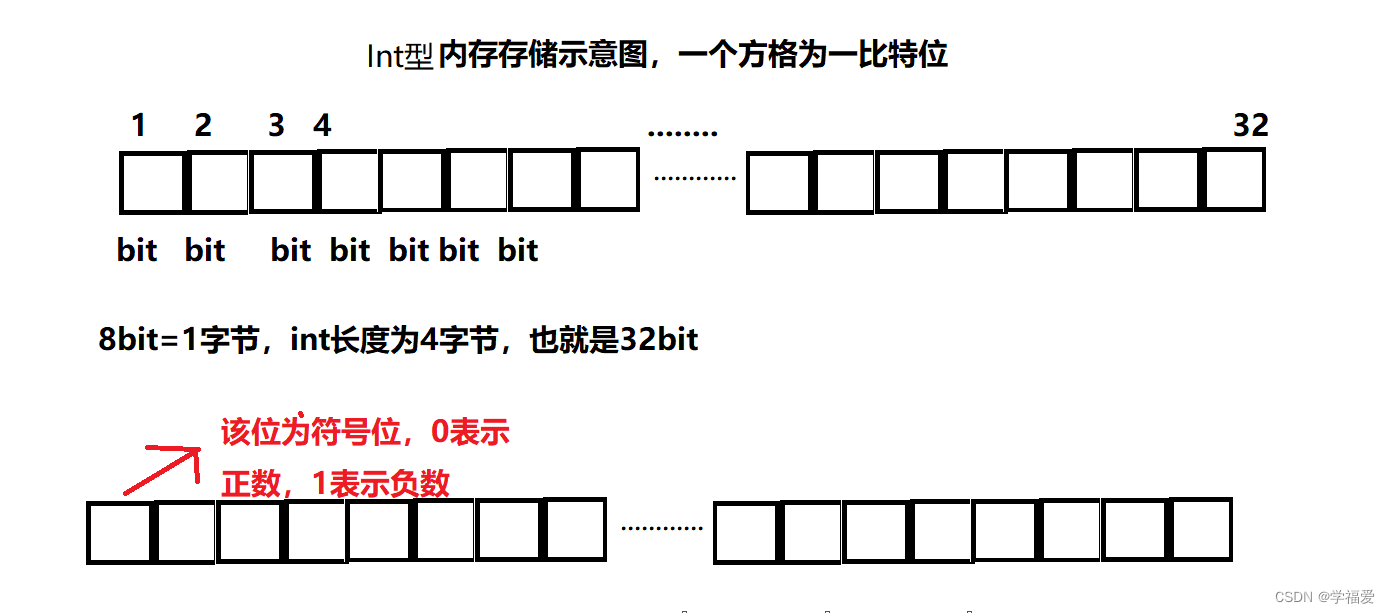
int,short,long,float等有符号整型通常使用补码表示法存储。补码表示法中,最高位表示符号位,0 表示正数,1 表示负数。例如,在 int 类型中,最高位被用来当成符号,因此最大值为01111111…111(31个1),最小值10000000…000(31个0)所以int类型的范围是从-2的31次方到2的31次方减1。其他的符号型也是同一道理
我们将整型的各项数值,以表格的形式,表现出来
| 整型类型名· | 字节大小 | 取值f范围 | 取值范围(十i进制) | 输出格式 | 精度 |
|---|---|---|---|---|---|
| int | 4 | -2^(32-1)~ 2^(32-1)-1 | 十进制(-2147483648~2147483647) | %d | 无小数位 |
| short | 2 | -2^(16-1)~ 2^(16-1)-1 | 十进制(-32768~32767) | %hd | 无小数位 |
| long | 4 | -2^(32-1) ~ 2^(31-1)-1 | 十进制(-2147483648 ~ 2147483647) | %ld | 无小数位 |
| long long | 8 | -2^(63-1) ~ 2^(63——1)-1 | 十进制(-9223372036854775808 ~ 9223372036854775807) | %lld | 无小数位 |
| unsigned int | 4 | 0~2^32-1 | 十进制(0~4294967295) | %u | 无小数位 |
| unsigned short | 2 | 0 ~ 2^16-1 | 0 ~ 65535 | %hu | 无小数位 |
| unsigned long | 4 | 0 ~ 2^32-1 | 0 ~ 4294967295 | %lu | 无小数位 |
| unsigned long long | 8 | 0 ~ 2^64-1 | 0 ~ 18446744073709551615 | %llu | 无 |
以上结果在大多数编译器内都是一样的,但某些编译器可能会有不一样的结果,这是由于不同编译器对C语言规定的不同理解造成的
列如,有的读者可能会有疑问,为什么int和long数据类型大小和取值范围都是一样的?long不应该比int更长吗?那是因为在C语言规定中long的定义是长度大于或等于int,所以说有一些编译器就设置long的长度和int一样都是四个字节,这也是符合规定的。
介绍:C语言中的浮点型数据类型表示有小数点的实数,包括单精度浮点型float和双精度浮点型double两种类型。
C语言的浮点型是没有signed和unsigned之分的,C语言中没有unsigned float数据类型是因为float数据类型的内存表示方式与signed int和unsigned int等整数类型不同。
在计算机中,整数类型采用的是二进制补码的表示方式。但是,浮点数的表示方式比整数复杂,需要使用IEEE 754标准来表示。由于标准的实现方式,
使用无符号的浮点数会导致数值溢出和舍入误差等问题。因此,在C语言中,只有signed float和double类型,而没有unsigned float和double类型。
我们将整型的各项数值,以表格的形式,表现出来
| 类型名· | 字节大小 | 取值范围 | 输出格式 | 精度 |
|---|---|---|---|---|
| float | 4 | 1.17549e-38 ~ 3.40282e+38 | %f | 6位小数 |
| double | 8 | 2.22507e-308 ~ 1.79769e+308 | %lf | 15位小数 |
补充知识,浮点型类型在内存中是以科学计数法的形式存储的,并且float和double 等浮点数可用%e来输出,输出结果为科学计数法
介绍:在C语言中,char是一种用于表示字符数据的基本数据类型。它通常占用1个字节的存储空间,即8位,用来表示ASCII码中的一个字符,但char类型也可由原来存储-128~127的整数,同时也存在unsigned char 可以存储0~255的整数
| 类型名· | 字节大小 | 取值f范围 | 输出格式 | 精度 |
|---|---|---|---|---|
| char | 1 | -128~127或 0~255 | %c | 无小数 |
1.char 用来存储字符
char c='a'如果要用char来存储字符,请在字符两侧用单引号引起来
我们创建了char c 这个变量,但c中的字符,在内存中并不是以字符形式存储,而是以Ascll码形式存储
下图为Ascll码表
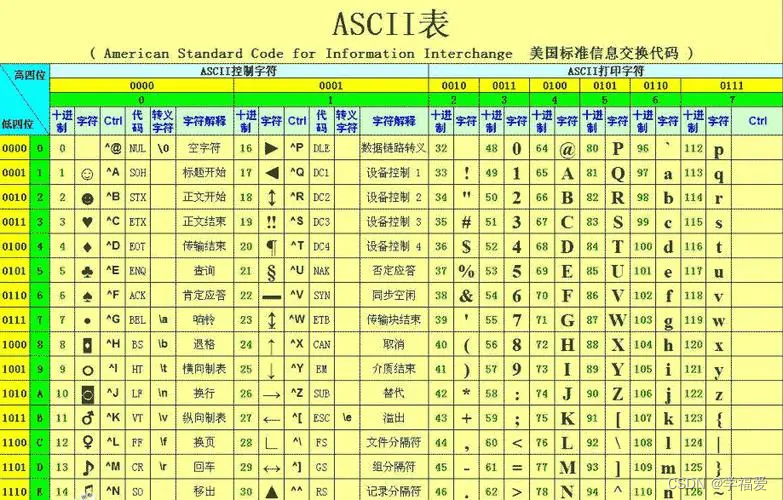
可以看出,C语言中字符其实也是一串二进制代码,我们必须要注意的是,在C语言中,字符型的数据也可以进行加减乘除的运算,但其实际进行计算的是Ascll码值
列如
# include<stdio.h>
int main()
{
char a = '9';初始化变量a为字符‘9’
printf("%d", a+1);计算a+1
return 0;
}
代码运行结果

输出结果为58,因为‘9’的ascll码值为57
2.char存储整数
char c=100;//初始化变量c为整数100
注意,当char存储整数时,取值范围为-128~127(unsigned为0~255)容易出现溢出建议不要用其存储整数
既然提到了字符,那肯定就不能不讲转义字符,C语言中的转义字符是一种特殊的字符序列,由反斜线(\)和后面紧跟着的一个或多个字符组成,用以表示一些不可打印的字符或控制命令
为什么会有转义字符?
C语言中引入转义字符是为了表示一些不可打印字符、特殊字符和控制字符,这些字符无法直接在代码中输入,需要使用转义字符来表示。例如,换行符是一个不可打印字符,可以使用转义字符"\n"来表示。另外,一些特殊字符如双引号和反斜杠,需要使用转义字符来转义,以避免它们被误解为代码中的特殊符号。
下面为一张转义字符表

C语言有4个国际标准,包括C89,C90,C11和C18,目前使用较为广泛使用的·标准是C90,而我们介绍的布尔型是C99标准之后才有的的,所以并不是所以的编译器都支持布尔型,不过作者在查阅资料时经常有资料将布尔型归入C语言数据类型中,所以特地拿出来讲一下,但不会做过多解释,初学者了解一下这个类型就可以了,有兴趣可以自己去学习。
在 C 语言中,布尔型数据类型是用来表示真或假的数据类型,也就是用来进行逻辑判断的数据类型。C语言中定义的布尔型数据类型是 _Bool,取值只有 true 和 false 两种,可以使用关键字 true 和 false 来进行初始化,也可以使用数字 1 和 0 分别表示 true 和 false。例如:
bool is_true = true;
bool is_false = false;
bool num_true = 1;
bool num_false = 0;
布尔型数据类型主要用于条件语句、循环语句和逻辑表达式中,比如 if 语句、while 循环、逻辑运算符等等。在条件判断中,为真的条件通常被表示为非零值,而为假的条件则被表示为 0。布尔型数据类型在编写逻辑控制流程时非常有用,可以使程序更加清晰和易于理解。
代码示例
#include <stdio.h>
#include <stdbool.h>
int main() {
bool what = true;
if (what) {
printf("yes\n");
} else {
printf("No\n");
}
return 0;
}
输出结果为Yes

在为这篇博客搜集资料的时候,意外发现了与%d功能十分相同的格式输出字符%i。关于%d是我们日常编程中经常使用的,用于输出有符号十整数的格式输出符,那至于%i,我相信有很多初学者是第1次见
先说一下百分号地和百分号的相同点吧
在printf()函数中,这两个的功能是完全相同的,都是输出有符号10进制整数
它们的区别主要在是scanf()函数上
当你使用%d时候,如果你实际输入的是8进制16进制的数,%d会忽略前面的八进制或者十六进制符号直接输入后面的数字
但是如果你使用%i,%i会读取前面的8进制和16进制符号,如果它读取到这些符号之后的实际输入也会转换成8进制和16进制,然后再转换为十进制
具体可以点击这里《简单易懂,C语言中%d和%i的区别》
C语言为我们提供了许多种数据类型,今天我们这篇博文主要详细介绍了c语言中的基本数据类型包括,整型浮点型字符型,以及简略的带过了布尔型,其中介绍了许多可能会有用的小知识,希望能加深大家对这些数据类型的印象,在开头的思维导图中,我还画出了派生类型,在之后的博文会逐步更新其中的内容
如果这篇博文对你有点帮助,请点个赞,水一下评论,(三连必回)后期我会定期更新博客,朋友们可以关注一下我,感谢老铁

我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s