文章目录
Java利用stream流,判断列表中对象的某个字段的值是否与其它对象重复;尤其是在批量导入的时候,进行数据的重复性校验时;
通过toMap、groupBy可以实现判断一个字段的重复性,还可以判断对象中某几个字段拼接后内容的重复性;
实例:校验学员学号stuNumber的重复性
[
{
"classUuid":"685806c0-4b1e-495f-b3fa-b02f089b7421",
"stuUuid":"2c1e85df-2464-4b77-81f5-5f958519c1d8",
"stuNumber":"1231",
"stuName":"测试学员1",
"fee":"100"
},
{
"classUuid":"685806c0-4b1e-495f-b3fa-b02f089b7421",
"stuUuid":"b0632666-8334-4618-b4d1-a6c856b0e522",
"stuNumber":"1232",
"stuName":"测试学员2",
"fee":"100"
},
{
"classUuid":"685806c0-4b1e-495f-b3fa-b02f089b7421",
"stuUuid":"742ce0e3-d1e4-4694-a5bb-68ed7e44b7fc",
"stuNumber":"1232",
"stuName":"测试学员3",
"fee":"100"
}
]
上面的列表中的数据,stuNumber为学员学号,应该是唯一存在的;但是测试学员2和测试学员3的学号重复,均为1232;因此,列表中有不符合要求的重复字段数据;
转为map,键为要比较的字段,值为该键存在的次数(使用"merge"操作:Integer::sum)
然后利用过滤,获取值大于1的数据
如果数据存在,则表明重复
filter中存放的是留下的元素需满足的条件
//import java.util.Map.Entry;
/** 验证列表中是否存在相同的学员学号 */
private void checkIfStuNumDuplicate(List<ClassStuCreateParam> params) throws ServiceException {
List<String> list =
params.stream()
.map(ClassStuCreateParam::getStuNumber)
.collect(Collectors.toMap(e -> e, e -> 1, Integer::sum))
.entrySet()
.stream()
.filter(entry -> entry.getValue() > 1)
.map(Entry::getKey)
.collect(Collectors.toList());
if (CollectionUtils.isNotEmpty(list)) {
LOGGER.warn("stuNumber duplicate: [{}]", list);
throw new ServiceException(
OrgErrorConst.DUPLICATE_STU_NUMBER,
String.format("%s:%s", OrgErrorConst.DUPLICATE_STU_NUMBER_MSG, String.join(",", list)));
}
}
注:
toMap的第三个参数Integer::sum表示当键重复时,值所需做的操作,就是将旧值和新值进行相加求和;
其它实例:【遇到重复键的时候,用新值替换旧值】
Map<String, String> courseMap =
params.stream()
.collect(
Collectors.toMap(
ClassCreateParam::getCourseUuid,
ClassCreateParam::getCourseName,
(oldValue, newValue) -> newValue));
【保留旧值,就是将上面代码的->符号后的newValue替换为oldValue】
// 获取学号列表
List<String> stuNumList =
classStuCreateParams.stream()
.map(ClassStuCreateParam::getStuNumber)
.filter(Objects::nonNull)
.collect(Collectors.toList());
if (CollectionUtils.isNotEmpty(stuNumList)) {
Map<String, List<Integer>> stuIdIndexMap =
IntStream.range(0, stuNumList.size())
.boxed()
.collect(Collectors.groupingBy(stuNumList::get));
List<String> numErr =
stuIdIndexMap.values().stream()
.map(
integers -> {
List<Integer> stuErrNum = new ArrayList<>();
if (integers.size() > 1) {
for (Integer base : integers) {
Integer baseNum = base + 3;
stuErrNum.add(baseNum);
}
String err = stuErrNum.toString();
err = err.substring(1, err.length() - 1);
return ("第" + err + "行学号填写重复");
} else {
return "";
}
})
.filter(StringUtils::isNotBlank)
.collect(Collectors.toList());
errList.addAll(numErr);
}

/**
* 方法作用:筛选出列表中的重复的元素
*
* @param orgData 初始字符串列表
* @return List 列表中的重复数据
*/
private List<String> getDuplicateData(List<String> orgData) {
if (CollectionUtils.isEmpty(orgData)) {
return Collections.emptyList();
}
Map<String, Long> resMap =
orgData.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
return orgData.stream().filter(data -> resMap.get(data) > 1).collect(Collectors.toList());
}
说到重复性,其实第一个想到的是集合的特性–互异性;
如下所示,courseCodes 是原有的list数据,courseCodeSet 是去重后的数据;
通过CollectionUtils.subtract求两个Collection的差集,可以知道重复的元素是什么;
如果想单纯的判断courseCodes 中是否有重复的,可以直接比较’list’和’set’的大小
// 相同编码的课程不能导入
List<String> courseCodes =
teachMergeParams.stream()
.map(CourseCreateParam::getCourseCode)
.collect(Collectors.toList());
// 校验表单中是否有重复的
Set<String> courseCodeSet = teachMergeParams.stream().map(CourseCreateParam::getCourseCode).collect(Collectors.toSet());
Collection<String> duplicateCourses = CollectionUtils.subtract(courseCodes, courseCodeSet);
方法有很多,灵活使用。
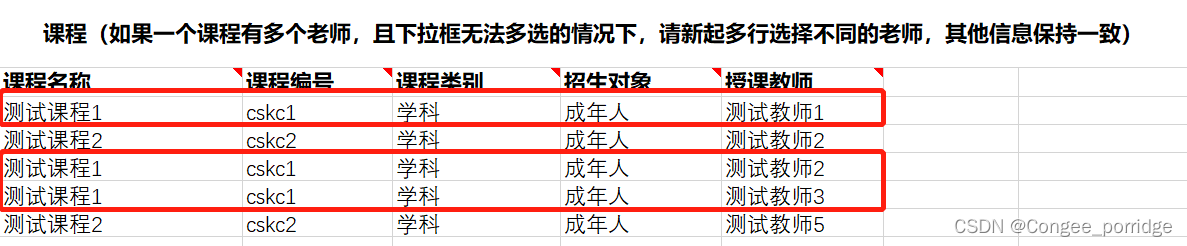
这里其实就是测试课程1有三个教师,分别为测试教师1、测试教师2、测试教师3
测试课程2有两个教师,分别为测试教师2、测试教师5
入参:
[
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师1_teac1"],
"teacherWorks":[]
},
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2_teac2"],
"teacherWorks":[]
},
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2_teac2"],
"teacherWorks":[]
},
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师3_teac3"],
"teacherWorks":[]
},
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师5_teac5"],
"teacherWorks":[]
}
]
函数:
private List<CourseExcelParam> handleAddBatchNotByMacro(List<CourseExcelParam> params) {
// 处理一个课程对应多个老师的list
List<CourseExcelParam> teachMergeParams = new ArrayList<>();
params.parallelStream()
.collect(
Collectors.groupingBy(
p -> (p.getCourseCode() + p.getCourseName()), Collectors.toList()))
.forEach(
(id, transFer) -> {
transFer.stream()
.reduce(CourseExcelParam::merge)
.ifPresent(
course -> {
if (CollectionUtils.size(transFer) == 1) {
course.setTeacherWorks(
course.getTeacherNames().stream()
.map(tw -> tw.split("_")[1])
.collect(Collectors.toList()));
course.setTeacherNames(
course.getTeacherNames().stream()
.map(tw -> tw.split("_")[0])
.collect(Collectors.toList()));
}
Map<String, String> teacherMap =
getTeacherWorkAndUuidMap(course.getTeacherWorks());
course.setTeacherUuids(new ArrayList<>(teacherMap.values()));
teachMergeParams.add(course);
});
});
return teachMergeParams;
}
merge:reduce规约操作要执行的函数
注:当传给reduce的stream流里面只有一个元素时,要额外处理
if (CollectionUtils.size(transFer) == 1);
具体情况具体分析
/**
* merge操作里要实现把同一课程的教师工号放到一个列表里
*
* @param dto
* @return
*/
public CourseExcelParam merge(CourseExcelParam dto) {
List<String> targetWorks = new ArrayList<>();
List<String> targetNames = new ArrayList<>();
if (CollectionUtils.isEmpty(this.teacherWorks)) {
this.teacherWorks =
this.getTeacherNames().stream().map(tw -> tw.split("_")[1]).collect(Collectors.toList());
this.teacherNames =
this.getTeacherNames().stream().map(tw -> tw.split("_")[0]).collect(Collectors.toList());
}
if (CollectionUtils.isNotEmpty(dto.getTeacherNames())) {
List<String> dtoWorks =
dto.getTeacherNames().stream().map(tw -> tw.split("_")[1]).collect(Collectors.toList());
List<String> dtoNames =
dto.getTeacherNames().stream().map(tw -> tw.split("_")[0]).collect(Collectors.toList());
targetWorks.addAll(this.teacherWorks);
targetWorks.addAll(dtoWorks);
targetNames.addAll(this.teacherNames);
targetNames.addAll(dtoNames);
this.teacherNames = targetNames;
this.teacherWorks = targetWorks;
}
return this;
}
最终得到的整合结果:
[
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师1","测试教师2","测试教师3"],
"teacherWorks":["teac1","teac2","teac3"]
},
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2","测试教师5"],
"teacherWorks":["teac2","teac5"]
}
]
此处,groupingBy在使用时,以p.getCourseCode() + p.getCourseName()为键,list为值;
形如下面的key-value:
"测试课程1cskc1":[
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师1"]
},
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2"]
},
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师3"]
},
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师5"]
}
],
"测试课程2cskc2":[
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2"]
},
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师5"]
}
]
课程名称不同,课程编号同时,则必定为"错误数据,可能就是课程编号输入重复的数据"课程名称相同,课程编号同时,指的就是同一个课程课程名称相同,课程编号不同时,指的就是同名的不同课程课程名称不同,课程编号不同时,指的也是不同课程再结合业务要求,一个课程配有多个教师时,是新起一行,除教师外,其它信息保持一致;所以他要处理的是同一课程的教师信息的合并操作;结合上述分析的四种情况,只有第2种情况符合要求;所以groupingBy在使用时,要以p.getCourseCode() + p.getCourseName()为键;
此外,第一种情况,也是需要处理的;处理的情景如下:
courseMergeParam = [
{
"courseName":"测试课程1",
"courseCode":"cskc1",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师1","测试教师2","测试教师3"],
"teacherWorks":["teac1","teac2","teac3"]
},
{
"courseName":"测试课程2",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2","测试教师5"],
"teacherWorks":["teac2","teac5"]
},
{
"courseName":"测试课程3",
"courseCode":"cskc2",
"courseType":"学科",
"courseObj":"成年人",
"teacherNames":["测试教师2","测试教师5"],
"teacherWorks":["teac2","teac5"]
}
]
测试课程2和测试课程3这两个课程,不同名但同课程编号;意味着课程编号填写重复。
此时,再针对courseMergeParam 做courseCode的重复性校验处理
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
我在Rails工作并有以下类(class):classPlayer当我运行时bundleexecrailsconsole然后尝试:a=Player.new("me",5.0,"UCLA")我回来了:=>#我不知道为什么Player对象不会在这里初始化。关于可能导致此问题的操作/解释的任何建议?谢谢,马里奥格 最佳答案 havenoideawhythePlayerobjectwouldn'tbeinitializedhere它没有初始化很简单,因为你还没有初始化它!您已经覆盖了ActiveRecord::Base初始化方法,但您没有调
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr