某天,产品叫我算下某个项目的代码行数,我一愣,这怎么统计?总不可能一个文件一个文件算吧?后面我找了下,git是可以统计提交到仓库的所有的代码的,不过有个问题,就是假如有些文件我不想算进去怎么办?之后我再查了下,可以只统计指定文件类型的代码的。
在指定项目文件夹里,打开git命令窗口,执行下面的命令(直接复制)
git log --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END {
printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
或者
git ls-files | xargs cat | wc -l
上面两个命令只统计行数,没有细分到文件,下面这个命令是会把每个文件都列出来,并统计每个文件的行数。
git ls-files | xargs wc -l
find . "(" -name "*.java" -or -name "*.xml" -or -name "*.yml" -or -name "*.properties" ")" -print | xargs wc -l
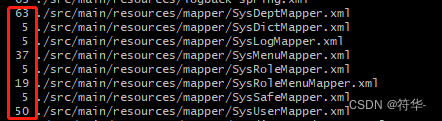
这个命令会打印出文件和对应的行数。
git log --author="username" --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END {
printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
git log --since=2022-12-06 --until==2022-12-07 --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END {
printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
--since:起始时间,--until:终止时间
git log --since =2022-12-06 --until==2022-12-07 --author="username" --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END {
printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
还有其他命令,可以参考下 这篇文章 ,比较全。
Git可以统计代码行数,但是如果我不想要空行和注释行也算进去怎么办?我找了下,好像没有命令可以忽略空行或注释行,既然Git不行,那我们就自己用代码实现统计。
要统计总代码量,得遍历这个项目下的全部文件,然后读取文件内容,遍历每一行的内容,如果是空行或者注释行就忽略。
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class 统计代码行数 {
private static long 空行数 = 0;
private static long 注释行数 = 0;
private static long 代码行数 = 0;
private static long 总行数 = 0;
public static void main(String[] args) {
// 这里只统计 \src\main 文件夹里的文件,其他文件像 .idea、test 这些文件夹里的就不算进去了
循环文件夹("D:\\Java\\workspace\\AssetsJava","\\src\\main\\");
System.out.println("空行:" + 空行数);
System.out.println("注释行:" + 注释行数);
System.out.println("代码行:" + 代码行数);
System.out.println("总行:" + 总行数);
}
private static void 循环文件夹(String 项目路径,String 只统计指定文件夹) {
File f = new File(项目路径);
if (!f.exists()){
System.out.println("项目路径不存在!");
return;
}
File[] childs = f.listFiles(); // 获取这个项目下的文件、文件夹
for (int i = 0; i < childs.length; i++) {
File child = childs[i];
if (!child.isDirectory()) { // 当前文件不是文件夹,就读取
if (child.getParent().contains(只统计指定文件夹)){ // java文件、xml文件、配置文件 只统计main文件夹下的
if (child.getName().matches(".*\\.java$") || child.getName().endsWith(".yml") ||
child.getName().endsWith(".properties") || child.getName().endsWith(".xml")) {
long 单个文件代码行数 = 统计代码行数(child);
System.out.println(单个文件代码行数+"\t\t"+child.getName());
}
}else if ("pom.xml".equals(child.getName())){
long 单个文件代码行数 = 统计代码行数(child);
System.out.println(单个文件代码行数+"\t\t"+child.getName());
}
}else { // 当前文件是文件夹,继续递归
循环文件夹(child.getPath(),只统计指定文件夹);
}
}
}
private static long 统计代码行数(File file){
long 单个文件代码行数 = 0;
BufferedReader br = null;
try{
br = new BufferedReader(new FileReader(file));
String line = "";
boolean flag = false; // 用于标记xml多行注释,为true表示当前行在多行注释中,一直到最后一行注释
while ((line = br.readLine()) != null){
总行数++;
String 内容 = line.trim(); // 每一行的内容,去掉空格
if (flag){
注释行数++;
// 当多行注释结尾是 --> 说明多行注释结束,重新标记为false,表示当前不在统计多行注释
if (内容.endsWith("-->")) flag = false;
}else {
if (内容.length() == 0){
空行数++;
}else if (内容.startsWith("//") || 内容.startsWith("/**") || 内容.startsWith("*") ||
内容.startsWith("*/") || 内容.startsWith("/*") || 内容.startsWith("#")){
注释行数++;
}else if(内容.startsWith("<!--")){
注释行数++;
// 当前行属于xml的注释,且结尾不是 --> 时,表示是多行注释,设置标记为true
if (!内容.endsWith("-->")) flag = true;
}else {
代码行数++;
单个文件代码行数++;
}
}
}
}catch (Exception e){
e.printStackTrace();
}finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return 单个文件代码行数;
}
}


最后的总行数,是和用Git统计的总行数对得上的。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur