概念:Instance、Job、Metric、Metric Name、Metric Label、Metric Value、Metric Type(Counter、Gauge、Histogram、Summary)、DataType(Instant Vector、Range Vector、Scalar、String)、Operator、Function马老师说:“虽然阿里巴巴是全球最大的零售平台,但阿里不是零售公司,是一家数据公司”。Prometheus 也是一样,本质来说是一个基于数据的监控系统。
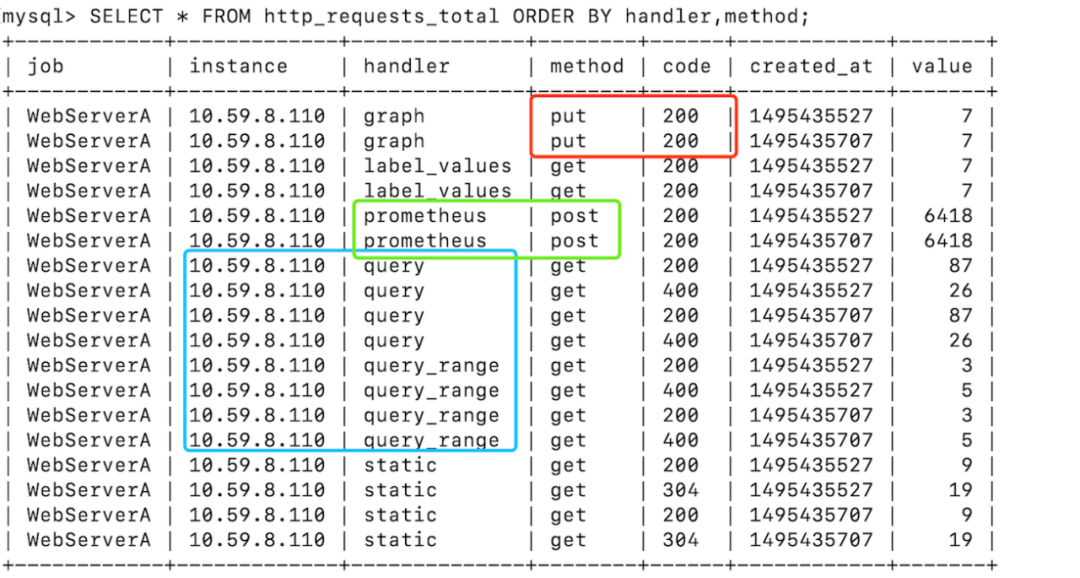 如果以SQL为例,演示常见的查询操作:查询 method=put 且 code=200 的请求量(红框)
如果以SQL为例,演示常见的查询操作:查询 method=put 且 code=200 的请求量(红框)SELECT * from http_requests_total WHERE code=”200” AND method=”put” AND created_at BETWEEN 1495435700 AND 1495435710;SELECT * from http_requests_total WHERE handler=”prometheus” AND method=”post” AND created_at BETWEEN 1495435700 AND 1495435710;SELECT * from http_requests_total WHERE handler=”query” AND instance=”10.59.8.110” AND created_at BETWEEN 1495435700 AND 1495435710;"labels": [{
"latency": "500"
}]
"samples":[{
"timestamp": 1473305798,
"value": 0.9
}]
^
│. . . . . . . . . . . . {="500"}
│. . . . . . . . . . . . {="300"}
│. . . . . . . . . . . {}
│. . . . . . . . . . . .
<-------- time ---------->
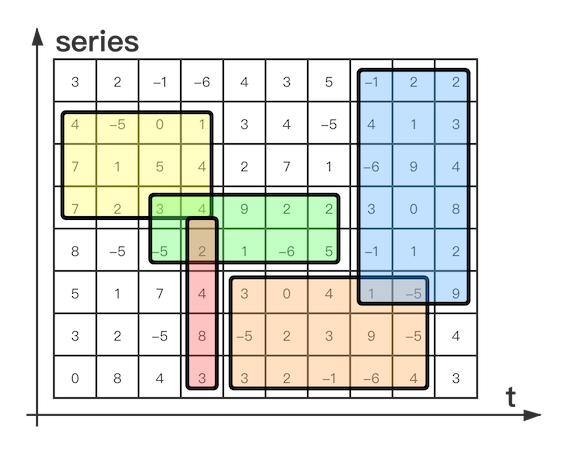
存储两部分数据。一部分是按照字典序的排列的所有标签键值对序列(series);另外一部分是时间线到数据文件的索引,按照时间窗口切割存储数据块记录的具体位置信息,因此在查询时可以快速跳过大量非查询窗口的记录数据Label Index
每对 label 为会以 index:label: 为 key,存储该标签所有值的列表,并通过引用指向 Series 该值的起始位置。Time Index
数据会以 index:timeseries:: 为 key,指向对应时间段的数据文件
 如此,Promtheus体系的能力不弱于监控界的“数据仓库”+“计算平台”。因此,在大数据的开始在业界得到应用,就能明白,这就是监控未来的方向。
如此,Promtheus体系的能力不弱于监控界的“数据仓库”+“计算平台”。因此,在大数据的开始在业界得到应用,就能明白,这就是监控未来的方向。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!
我们有一个带有广泛管理部分的应用程序。我们对功能有点满意(就像您一样),并且正在寻找一些快速简便的方法来监控“谁使用什么”。理想情况下,一个简单的gem将允许我们在每个用户的基础上跟踪Controller/操作,以构建使用的功能和未使用的功能的图片。任何你会推荐的..谢谢主场 最佳答案 我不知道有什么流行的gem或插件可以解决这个问题;过去,我在ApplicationController中将这种审计实现为before_filter:从内存中:classApplicationControllercurrent_user,:contro
我有一堆长时间运行的Ruby脚本,我想确保每30秒左右运行一次。我通常通过简单地启动命令rubyscript-name.rb我如何配置monit来管理这些脚本?更新:我试着关注thismethodtocreateawrapperscript然后它会启动ruby进程,但它似乎没有创建.pid文件并且键入“./wrapper-scriptstop”什么也没做:/我应该在ruby中编写pid还是使用包装脚本来创建monit所需的pid? 最佳答案 MonitWiki有很多配置示例:http://mmonit.com/wiki/Mo
我们想设置自动化作业(通过Jenkins)以在第三方API出现故障或他们部署了不兼容的API时发出警报。我说的是针对真实的HTTPAPI进行测试,而不是模拟,但是因为我们已经使用rspec编写了模拟,所以我不确定我们是否应该通过编写两个独立的睾丸来重复这项工作。有人有这方面的经验吗?(如果其他工具可以提供帮助,我不限于Ruby/Rspec) 最佳答案 你看过VCR了吗??使用它,您可以“记录您的测试套件的HTTP交互并在未来的测试运行期间重播它们以进行快速、确定性、准确的测试”。在测试来自外部API的预期响应时,我将它与RSpec一
我正在使用Sidekiqworker在用户首次登录后完成对Facebook的一些请求。通常该任务大约需要20秒左右。我想在同步完成后立即使用ajax请求将一些信息加载到页面上,但不确定使用Javascript检查作业完成情况的最佳方式。一种可能性是配置Sidekiqworker在完成其余工作后设置cookie。然后我可以使用setTimeout函数在调用加载函数之前继续检查cookie。但我不确定这是否是最好的方法。我可以改用Redis吗? 最佳答案 Paul,最初你必须看一下这个PubSubonRailstutorial!当异步事
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭7年前。Improvethisquestion使用哪个进行过程监控?为什么?
网络上是否有关于如何使用Monit监控delayed_job的示例??我能找到的所有东西都使用God,但我拒绝使用上帝,因为在Ruby中长时间运行的进程通常很糟糕。(上帝邮件列表中的最新帖子?GodMemoryUsageGrowsSteadily。)更新:delayed_job现在带有samplemonitconfig基于这个问题。 最佳答案 下面是我如何让它工作的。使用collectiveideaforkofdelayed_job除了积极维护之外,这个版本还有一个不错的script/delayed_job可以与monit一起使用的