同一个消费组里的消费者不能消费同一个分区,不同消费组的消费组可以消费同一个分区
(即同一个消费组里面的消费者只能在一个分区中)
用过 Kafka 的同学用过都知道,每个 Topic 一般会有很多个 partitions。为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会启动一个或多个streams去分别消费 Topic 里面的数据。我们又知道,Kafka 存在 Consumer Group 的概念,也就是 group.id 一样的 Consumer,这些 Consumer 属于同一个Consumer Group,组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。那么问题来了,同一个 Consumer Group 里面的 Consumer 是如何知道该消费哪些分区里面的数据呢?
在 Kafka 内部存在两种默认的分区分配策略:Range(轮循分配) 和 RoundRobin(范围策略)。当以下事件发生时,Kafka 将会进行一次分区分配:
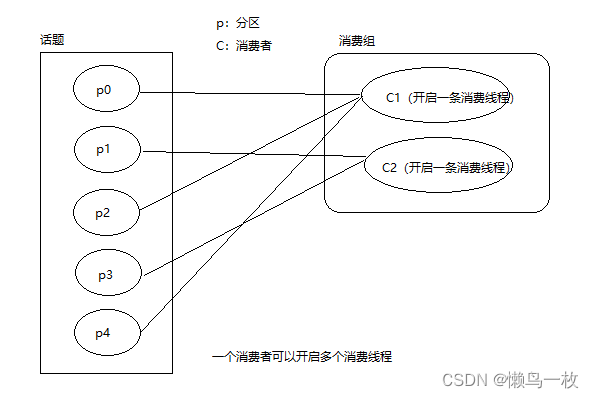
这个分区分配策略简单来说就是列出所有的分区,然后和消费线程之间进行循环的分配即可。
如果你需要使用该分配策略,你需要满足所有的消费线程都是消费相同的topic,且每个消费者之间的消费线程数是一样的。
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。在我们的例子里面,排完序的分区将会是0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是C1-0, C2-0, C2-1。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程, 10 / 3 = 3,而且除不尽,那么消费者线程 C1-0 将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C2-1 将消费 7, 8, 9 分区
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6, 7 分区
C2-1 将消费 8, 9, 10 分区
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3分区
C2-0 将消费 T1主题的 4, 5, 6 分区以及 T2主题的 4, 5, 6分区
C2-1 将消费 T1主题的 7, 8, 9 分区以及 T2主题的 7, 8, 9分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了2个分区,这就是Range strategy的一个很明显的弊端。
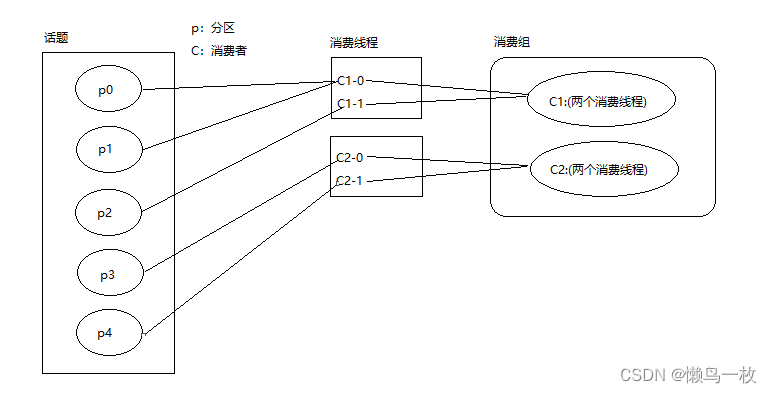
述简单来说就是分区总数/消费线程数,如果有余,则表明有的消费线程之间分配的分区不均匀,那么这个多出来的分区会给前几个消费线程处理。
比如上述5个分区,2个comsumer,4个消费线程,则5/4=1,这个表明如果4个消费线程均分5个分区还会多出一个分区,
那么这个多出的额外分区就会给前面的消费线程处理,所以它会把第一个分区先给到c1-0消费线程消费。
也可以这样的认为分配:
5/4余1,则分配规则为2,1,1,1,对应的消费线程为C1-0,C1-1,C2-0,C2-1
如果是6个分区的话:
6/4余2,则分配规则为2,2,1,1,对应的消费线程为C1-0,C1-1,C2-0,C2-1
使用RoundRobin策略有两个前提条件必须满足:
同一个Consumer Group里面的所有消费者的num.streams必须相等;每个消费者订阅的主题必须相同。
所以这里假设前面提到的2个消费者的num.streams = 2。RoundRobin策略的工作原理:将所有主题的分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按照 hashCode 进行排序,这里文字可能说不清,看下面的代码应该会明白:
val allTopicPartitions = ctx.partitionsForTopic.flatMap { case(topic, partitions) =>
info("Consumer %s rebalancing the following partitions for topic %s: %s"
.format(ctx.consumerId, topic, partitions))
partitions.map(partition => {
TopicAndPartition(topic, partition)
})
}.toSeq.sortWith((topicPartition1, topicPartition2) => {
/*
* Randomize the order by taking the hashcode to reduce the likelihood of all partitions of a given topic ending
* up on one consumer (if it has a high enough stream count).
*/
topicPartition1.toString.hashCode < topicPartition2.toString.hashCode
})
最后按照round-robin风格将分区分别分配给不同的消费者线程。
在我们的例子里面,加入按照 hashCode 排序完的topic-partitions组依次为T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9,我们的消费者线程排序为C1-0, C1-1, C2-0, C2-1,最后分区分配的结果为:
C1-0 将消费 T1-5, T1-2, T1-6 分区;
C1-1 将消费 T1-3, T1-1, T1-9 分区;
C2-0 将消费 T1-0, T1-4 分区;
C2-1 将消费 T1-8, T1-7 分区;
多个主题的分区分配和单个主题类似,这里就不在介绍了。
根据上面的详细介绍相信大家已经对Kafka的分区分配策略原理很清楚了。不过遗憾的是,目前我们还不能自定义分区分配策略,只能通过partition.assignment.strategy参数选择 range 或 roundrobin。partition.assignment.strategy参数默认的值是range。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
通过rubykoans.com,我在about_array_assignment.rb中遇到了这两段代码你怎么知道第一个是非并行赋值,第二个是一个变量的并行赋值?在我看来,除了命名差异之外,代码几乎完全相同。4deftest_non_parallel_assignment5names=["John","Smith"]6assert_equal["John","Smith"],names7end45deftest_parallel_assignment_with_one_variable46first_name,=["John","Smith"]47assert_equal'John
rpartition和partition有什么区别?我已经阅读了文档,但我认为它们是一样的。只是那些出现在后来的ruby版本中吗? 最佳答案 以下示例将有助于识别差异:"abccba".partition("b")#=>["a","b","ccba"]"abccba".rpartition("b")#=>["abcc","b","a"]所以区别在于rpartition搜索最右边的匹配项,而不是最左边的匹配项。 关于Rubyrpartition与分区?,我们在StackOverflow
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
假设您在Ruby中执行此操作:ar=[1,2]x,y=ar然后,x==1和y==2。是否有一种方法可以在我自己的类中定义,从而产生相同的效果?例如rb=AllYourCode.newx,y=rb到目前为止,对于这样的赋值,我所能做的就是使x==rb和y=nil。Python有这样一个特性:>>>classFoo:...def__iter__(self):...returniter([1,2])...>>>x,y=Foo()>>>x1>>>y2 最佳答案 是的。定义#to_ary。这将使您的对象被视为要分配的数组。irb>o=Obje
我正在使用Dragonfly在Rails3.1应用程序上处理图像。我正在努力通过url将图像分配给模型。我有一个很好的表格:{:multipart=>true}do|f|%>RemovePicture?Dragonfly的文档指出:Dragonfly提供了一个直接从url分配的访问器:@album.cover_image_url='http://some.url/file.jpg'但是当我在控制台中尝试时:=>#ruby-1.9.2-p290>picture.image_url="http://i.imgur.com/QQiMz.jpg"=>"http://i.imgur.com/QQ
使用Paperclip,我想从这样的URL抓取图像:require'open-uri'user.photo=open(url)问题是我最后得到一个像“open-uri20110915-4852-1o7k5uw”这样的文件名。有什么方法可以更改user.photo上的文件名?作为一个额外的变化,Paperclip将我的文件存储在S3上,所以如果我可以在初始分配中设置我想要的文件名就更好了,这样图像就会上传到正确的S3key。像这样:user.photo=open(url),:filename=>URI.parse(url).path 最佳答案
这是我理想中想要的。用户做:a="hello"输出为Youjustallocated"a"!=>"Hello"顺序无关紧要,只要我能实现该消息即可。 最佳答案 不,没有直接的方法可以做到这一点,因为在执行代码之前,Ruby字节码编译器会丢弃局部变量名。YARV(MRI1.9.2中使用的RubyVM)提供的关于局部变量的唯一指令是getlocal和setlocal,它们都对整数索引进行操作,而不是变量名。以下是1.9.2源代码中insns.def的摘录:/****************************************
我已经有很多两个值数组,例如下面的例子ary=[[1,2],[2,3],[1,3],[4,5],[5,6],[4,7],[7,8],[4,8]]我想把它们分组到[1,2,3],[4,5],[5,6],[4,7,8]因为意思是1和2有关系,2和3有关系,1和3有关系,所以1,2,3都有关系我如何通过ruby库或任何算法来做到这一点? 最佳答案 这是基本Bron–Kerboschalgorithm的Ruby实现:classGraphdefinitialize(edges)@edges=edgesenddeffind_maximum_