目录
--查看数据库
show databases;
--创建数据库
create database database_name;
--删除数据库
drop database database_name;
--选择数据库
use database_name;
--查看当前数据库
select database();
--查看当前数据库中的所有表
show tables;
--查看表结构
desc table_name;
--创建表格示例
create table if not exists `test_table`(
`id` int unsigned auto_increment comment '编号'
,`title` varchar(100) not null comment '标题'
, `author` varchar(100) not null comment '作者'
, `cdate` date comment '日期'
, primary key (`id`)
)engine=InnoDB default charset=utf8 comment='测试表格';
--if not exists `test_table`:如果 test_table 这张表不存在则新建
--auto_increment:从上一条数据自增 1
--comment:后面的字符串为注释
--not null:如果该字段无数据则默认为 null
--新增字段示例
alter table test_table add `position` varchar(100) not null comment '地区';
--写入数据
insert into test_table(
title
,author
,position
,cdate
)value('孔乙己', '鲁迅', '中国', '1919-4-1');
--批量写入
insert into test_table(
title
,author
,position
,cdate
)value('药', '鲁迅', '中国', '1919-4-25')
,('白夜行', '东野圭吾', '日本', '1998-8-1')
,('鲁宾逊漂流记', '笛福', '英国', '1719-4-25');
--删除表
drop table table_name;
--删除字段
alter table table_name drop column `字段名`;
--删除数据
drop from table_name where 条件;
--修改字段名示例
alter table test_table change `title` `book` varchar(100) not null comment '作品';
--更新数据示例
update test_table
set
book = '彷徨'
,cdate = '1926-8-1'
where id = 1;
--查询所有数据
select * from test_table;
--限制数量查询
select * from test_table
limit 3;
--查找指定字段数据
select
book
,author
from test_table;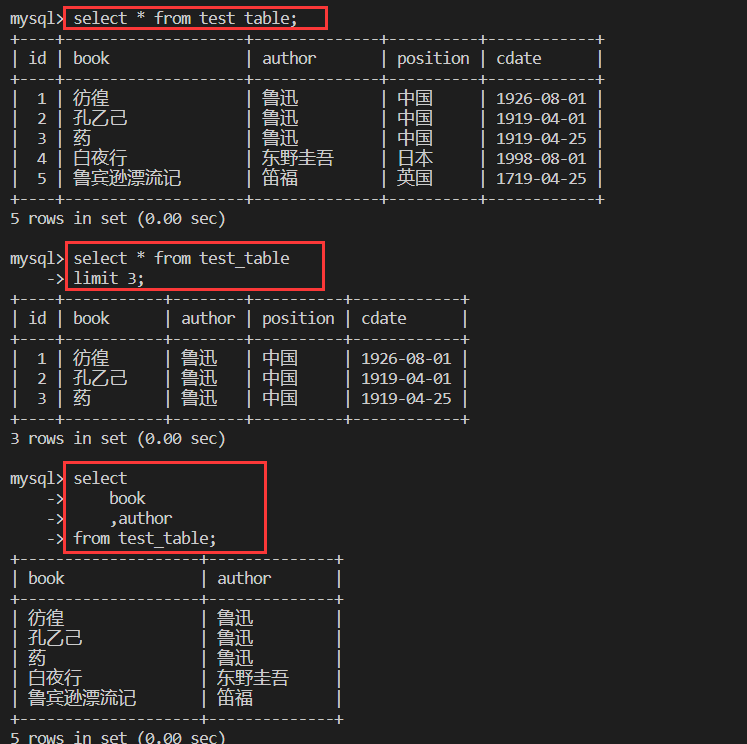
--多表查询示例
--新建另一个测试表格test_01
--test_01的字段是 id title author cdate
--test_01存储影视信息
select
test_table.book
,test_table.author
,test_01.title
,test_01.author
from test_table, test_01;
--条件查询
select *
from table1, table2, ...
where 条件;
select *
from table1, table2, ...
where 条件1 --选定表格后,选择数据前继续筛选
having 条件2; --数据全部计算完之后进行筛选
--起别名示例
select
a.id
,a.book
,a.author
from test_table a;
--按字段数据去重查询示例
select distinct
a.author
from test_table as a;
--模糊查询1示例
select *
from test_table
where author like '%鲁%'; -- % 可匹配任意字符,一个或多个,也可不匹配
--模糊查询2示例
select *
from test_table
where cdate between '1900-1-1' and '2000-1-1';
--模糊查询3示例
select *
from test_table
where author in ('鲁迅', '陈独秀', '李大钊');
--关联:将两张表拼接
--两张表的字段名可以不不相同,但字段数量字段类型要相同
--union distinct
select
id
,book
,author
from test_table
union
select
id
,title
,author
from test_01;
--排序
--默认是从小排到大,加上desc是从大到小
--每个字段后面的参数只代表这个字段的排序法则
select *
from test_table
order by cdate desc, id; --优先排序出版时间逆序,再根据编号正序排序
--聚合
--count(0) 统计数据条数
--min max avg 分别用于找最大值、最小值、平均数
select
count(0)
,min(cdate)
,max(cdate)
,avg(cdate)
from test_table;
--分组
select
book
,author
,count(0)
from test_table
group by book, author;
--用 group by 去重比 distinct 效率高
--分组统计
select
coalesce(字段1, 'total')
,coalesce(字段2, 'total')
from 表名
where 条件
group by 字段1, 字段2
with rollup;
连接查询
可同时关联两张表或多张表
内连接
join默认为内连接 inner join
内连接:保留两个关联表的交集
select
a.*
,b.*
from test_table as a
join test_01 as b
on a.id = b.id
and a.author = '鲁迅';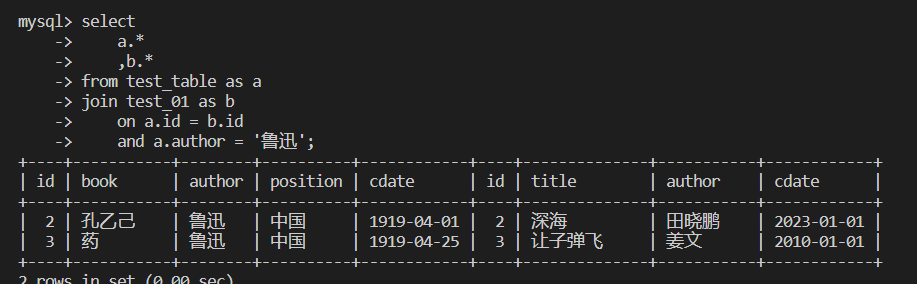
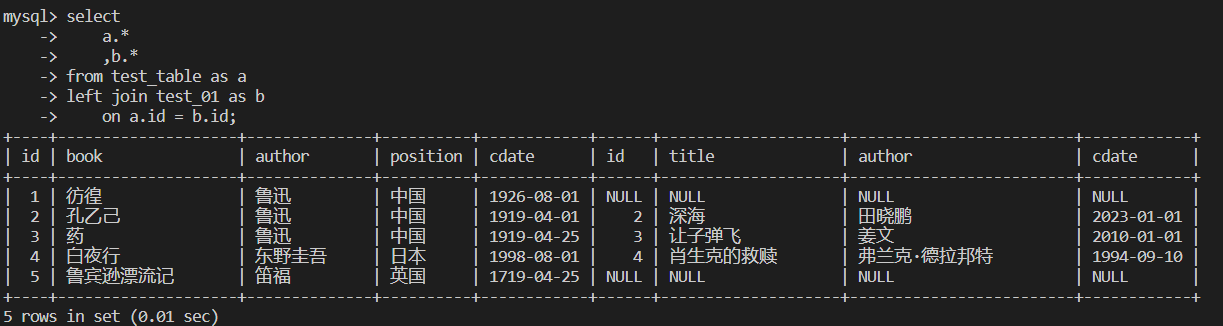
左连接
左连接 left join
保留主表的全部数据和关联表的交集数据
select
a.*
,b.*
from test_table as a
left join test_01 as b
on a.id = b.id;
右连接
右连接 right join
通过调换字段顺序可以将右连接改为左连接
select
a.*
,b.*
from test_01 as a
right join test_table as b
on a.id = b.id;
自关联
create table if not exists `city` (
`id` int not null comment '编号',
`name` varchar(100) comment '城市名称',
`pid` varchar(4) comment '父id',
primary key (`id`)
)engine=InnoDB default charset=utf8 comment='城市表格';
insert into city(id,name,pid) values
(1,'上海市',null),
(12,'闵行区',1),
(13,'浦东新区',1),
(2,'北京市',null),
(23,'朝阳区',2),
(24,'海淀区',2),
(25,'望京区',2),
(3,'广东省',null),
(31,'广州市',3),
(32,'东莞市',3),
(33,'珠海市',3),
(321,'莞城区',32);
select
a.ID,
a.name,
b.ID,
b.name,
c.ID,
c.name
from city a
left join city b
on a.ID = b.PID
left join city c
on b.ID = c.PID
where a.PID is null;
--代码格式
select distinct
字段
from 表名
join
where
group by
having
order by
limit start, count
--执行顺序
from 表名
join
where
group by
select distinct 字段
having
order by
limit start, count
常用默认函数
--当前日期
now()
--年
year(now())
--月
month(now())
--日
day(now())
--字段长度
length(字段) from table_name;
--设置返回值最小位数
select round(字段, 小数位数) from table_name;
--反转字符串
select reverse(字符串);
--截取字符串
select substring(字符串, start, length);
--判空 ifnull/nvl/coalesce
--如果对象为空,则用默认值代替
select ifnull(对象, 默认值)
条件判断
--条件判断
select
case when 条件1 then ...
when 条件2 then ...
else ...
end 新增字段
from table_name;
--示例
select
test_table.*
,case when author = '鲁迅' then '鲁迅文集'
when position = '日本' then '日本文学'
else '西方文学'
end '文化特色'
from test_table;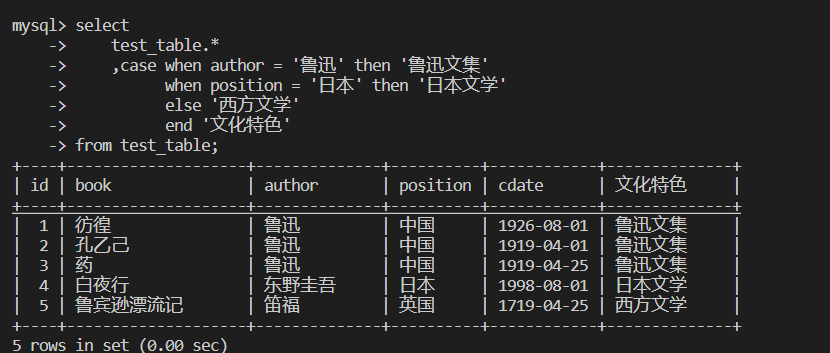
开窗函数
--开窗函数 partition by
--function(column) over(partition by 字段1, 字段2...) 新增字段
--function通常为聚合、排序函数
--分类统计不同作者、不同国家的人
select
*
,count(id) over(partition by author, position) num
from test_table;
--排序函数
--row_number() 排序名次累加,并列也累加 1 2 3 4 5 6 ...
--rank() 排序名次可并列,遇到并列则跳过该名次 1 2 2 4 4 6 ...
--dense_rank() 排序名次可并列,遇到并列不跳过名次 1 2 2 3 3 4 ...
select row_number() over(order by 字段) 新增字段;
select rank() over(order by 字段) 新增字段;
select dense_rank() over(order by 字段) 新增字段;
--查询写入
insert into select ......
--将查询到数据写入另一个表格中,要求写入的数据一一对应 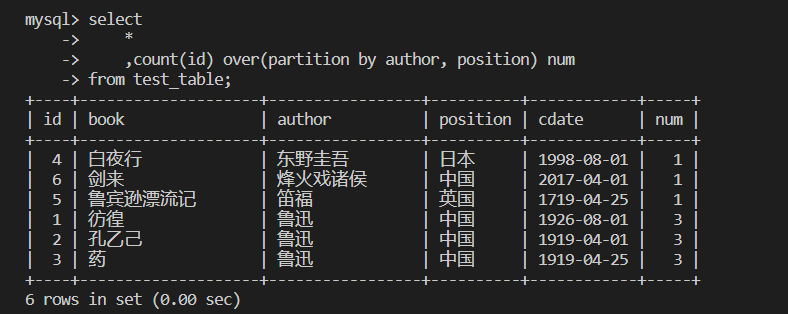
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit