Spark是一种快速、通用、可扩展的大数据分析引擎,PySpark是Spark为Python开发者提供的API。在有非常多可视化和机器学习算法需求的应用场景,使用PySpark比Spark-Scala可以更好地和python中丰富的库配合使用。
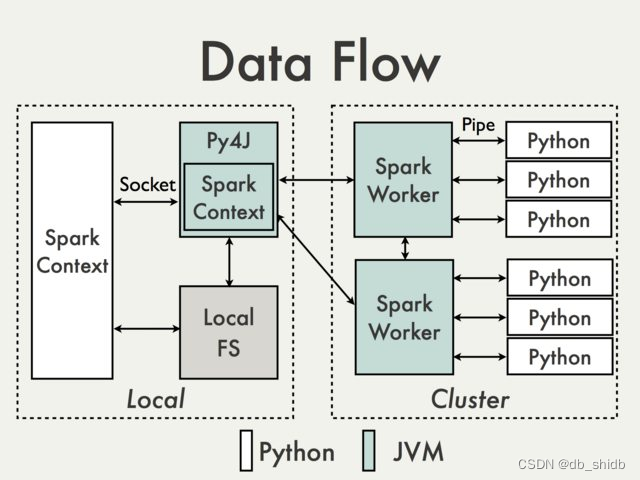
使用Python开发Spark需要使用到pyspark,pyspark是Spark为Python开发者提供的API。pyspark使用Py4J库,使得Python可以使用JVM对象。
操作系统 CentOS Linux release 7.8.2003 (Core)
Java 1.8.0_151
Python 3.6.13
Spark 2.4.0
Miniconda 4.5.4
pyspark 3.2.1
pyarrow 6.0.1
conda -V conda 4.5.4 创建好并进入pyspark_env的虚拟环境之后,我们需要安装两个Spark相关的库,pyspark和pyarrow。可以使用conda install安装或者也可使用pip,这里以使用pip安装为例:
pip3 install pyarrow pyspark
安装完毕之后可以使用conda list查看安装好的库
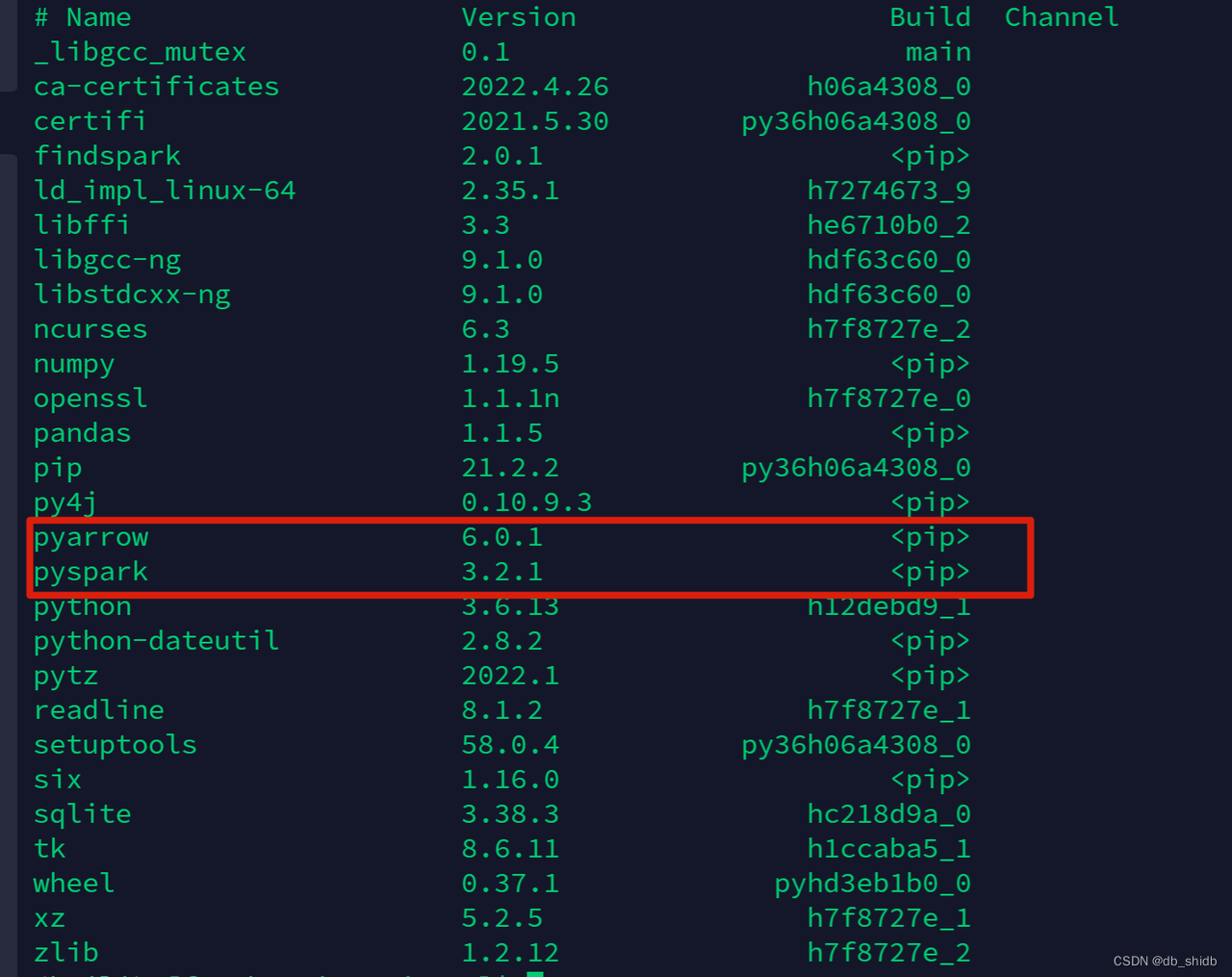
此,环境搭建中的conda部分已经完成。详细的操作可以参考Spark的最新文档,pyspark conda部署的部分是多版本通用的:Installation - PySpark 3.2.1 documentation
下载Spark
我们下载Spark已经编译好的压缩包,所有的历史版本可以在这个链接中找到:https://archive.apache.org/dist/spark/,
本文下载spark-2.4.0-bin-hadoop2.7.tgz
下载完成之后解压文件。完成之后可以进入目录运行bin/spark-shell进行测试
Standalone模式启动集群
Spark的集群模式总共分为四种
同样,在slave节点设置好环境变量之后运行
./sbin/start-slave.sh
下面的代码是Spark 运行Pandas UDF的例子。
def scalar_pandas_udf_example(spark):
import pandas as pd
from pyspark.sql.functions import col, pandas_udf
from pyspark.sql.types import LongType
def multiply_func(a, b):
return a * b
multiply = pandas_udf(multiply_func, returnType=LongType())
x = pd.Series([1, 2, 3])
print(multiply_func(x, x))
df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
df.select(multiply(col("x"), col("x"))).show()
if __name__ == "__main__":
spark = SparkSession \
.builder \
.master('local')\
.appName("UDFTest") \
.getOrCreate()
print("Running pandas_udf scalar example")
scalar_pandas_udf_example(spark)
spark.stop()
首先生成一个SparkSession对象,参数master->'local’指的是local模式运行,如果是集群的话这里local换成spark:\masterip:7077,appName->'UDFTest’定义了任务名称
spark = SparkSession \
.builder \
.master('local')\
.appName("UDFTest") \
.getOrCreate()
定义一个简单的函数
def multiply_func(a, b):
return a * b
生成UDF对象
multiply = pandas_udf(multiply_func, returnType=LongType())
生成一个pandas的数据
x = pd.Series([1, 2, 3])
创建一个Spark dataframe对象并让spark执行UDF
df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
df.select(multiply(col("x"), col("x"))).show()
该代码运行的结果为:
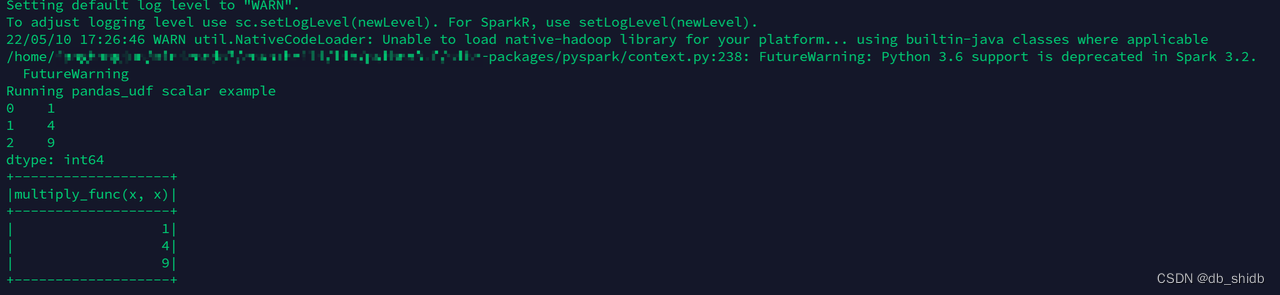
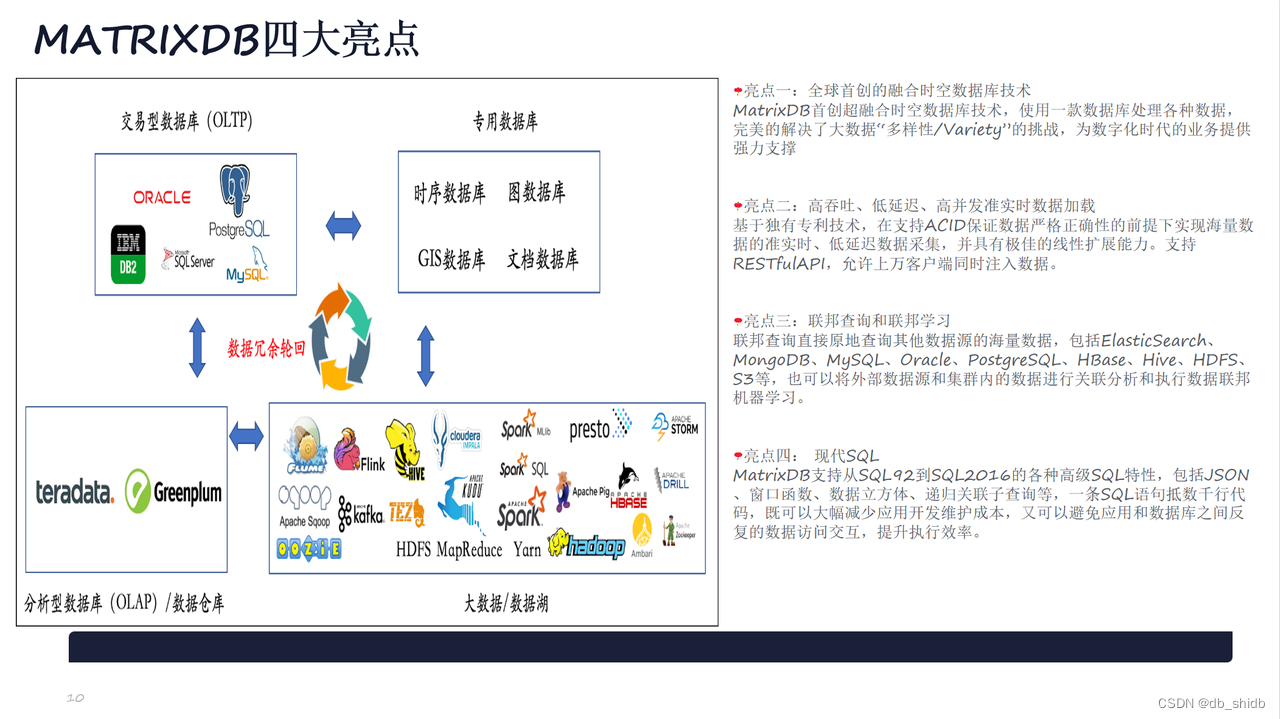
YMatrix
YMatrix是超融合数据库,将交易型数据库(OLTP)、分析型数据库(OLAP)和时序数据库能力融为一体的超融合型分布式数据库产品,具备严格分布式事务一致性、水平在线扩容、安全可靠、成熟稳定、兼容PostgreSQL/Greenplum协议和生态等重要特性。为万物互联的智能时代提供坚实、简洁的智能数据核心基础设施,为物联网应用、工业互联网、智能运维、智慧城市、实时数仓、智能家居、车联网等场景提供一站式高效解决方案,YMatrix为公司自主研发的国产数据库,公司拥有该产品全部知识产权。产品的架构如下。

YMatrix不但对经典的Greenplum数据仓库场景进行了大幅增强,而且可以极佳的支持大规模时序数据处理、支持时空数据、结构化数据和半结构化数据,一套数据库解决各种数据类型,避免为了处理不同类型数据引入不同类型的产品。实现提高开发运维效率、提升系统性能、降低整体成本的目标。
PLPython
PL/Python过程语言允许用Python编写 PostgreSQL函数。Python有非常多成熟的库能够提供给我们做数据分析,如numpy、pandas等。
使用PLPython方便数据分析的算法实现,可以充分利用YMatrix分布式储存和算力。

上文中描述了如何使用Python开发Spark应用,让我们的算法能够使用Spark的分布式计算能力,整体的数据流程是从csv的数据文件中读取数据->Spark Arrow内存的数据类型中->Spark分布式计算输出结果。
相同的算法也可以通过PLPython,将数据转存到YMatrix查询计算实现
将数据导入YMatrix
使用Mxgate将csv中的数据导入数据库,在此之前需要新建表
vin text,
daq_time DATE,
status INT,
c_stat INT,
mode INT,
speed INT,
mileage INT,
t_volt INT,
t_current INT,
soc INT,
dcdc_stat INT,
isulate_r INT,
lng BIGINT,
lat BIGINT,
max_volt_bat_id INT,
max_volt_cell_id INT,
max_cell_volt INT,
min_volt_bat_id INT,
min_cell_volt_id INT,
min_cell_volt INT,
max_temp_sys_id INT,
max_temp_probe_id INT,
max_temp INT,
min_temp_sys_id INT,
min_temp_probe_id INT,
min_temp INT,
max_alarm_lvl INT,
genral_alarm INT,
cell_volt_list text,
cell_temp_list TEXT,
pdate date)
distributed BY (vin)
表格建好了之后导入数据
tail -n +1 data.csv | mxgate --source stdin --db-database test --db-master-host localhost.localdomain --db-master-port 5432 --db-user mxadmin --time-format raw --target suanfa_data --delimiter ','
编写PLPython函数调用算法
首先我们需要把算法代码上传到服务器上,在本例中路径为/home/mxadmin/plpython/
我们需要查询suanfa_data表中的所有数据,并将结果转化成pandas的Dataframe格式,传递给算法函数去做处理
sql = "SELECT * FROM suanfa_data;"
df = psql.frame_query(sql, cnxn)
create function suanfa_detector() returns void as $$
import sys
sys.path.append('/home/mxadmin/plpython/')
from src.analyzer import analyzer
import pyodbc
import pandas.io.sql as psql
sql_result = plpy.execute("SELECT * FROM suanfa_data;")
df = pd.DataFrame.from_records(sql_result)
result = analyzer(df)
plpy.notice(result)
$$ language plpython3u;
下面是算法函数,输入是我们suanfa_detector()中sql的查询结果转换成的dataframe对象,经过数据处理,最后输出结果的dataframe
Def analyzer(data: pandas.Dataframe)-> pandas.Dataframe:
data_wash(data)
sign_data_veh_state(data)
detect_two_alarm_tuples = detect_two_analyze(data)
return detect_two_alarm_tuples
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
“输出”是一个序列化的OpenStruct。定义标题try(:output).try(:data).try(:title)结束什么会更好?:) 最佳答案 或者只是这样:deftitleoutput.data.titlerescuenilend 关于ruby-on-rails-更好的替代方法try(:output).try(:data).try(:name)?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定