本文主要分析 CDC 业务场景中任务级顺序保证,技术选型为:debezium、kafka、flink,其构成了顺序保证中至关重要的每一环,应该充分考虑、分析各组件的对于顺序的支持。
首先 debezium 作为采集组件,其分别为 schema topic 和 data topic 提供了不同的时间字段,如下图 schema topic 中提供了事件时间,data topic 中提供了事件时间和采集时间,为后续数据处理提供了依据。


Kafka 作为一款性能优秀的消息队列,在分布式事务中有着广泛地应用,其为了做到水平扩展,达到提高并发的目的,将一个 topic 分布到多个 broker(服务器)上,即一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。Kafka 在发送消息时,producer 可以知道相关 topic 的集群信息,从而将消息按照不同的策略发送到不同的分区。常见的分区策略有很多种(常用包括轮询、随机、按分区权重、就近原则、按消息键分区等策略)。各个分区中的消息比较独立,很难有一种高效的方法来判断不同分区的顺序。
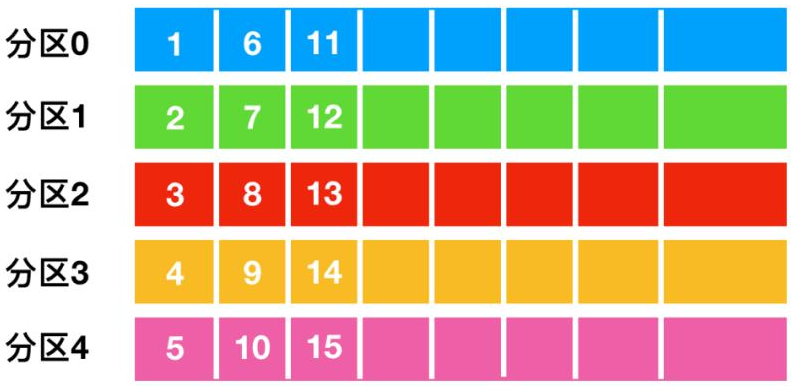
Flink 程序本质上是分布式并行程序。在程序执行期间,一个流有一个或多个流分区(Stream Partition),每个算子有一个或多个算子子任务(Operator Subtask),每个子任务彼此独立,并在不同的线程、节点或容器中运行。
Flink 算子之间可以通过一对一(直传)模式或重新分发模式传输数据:
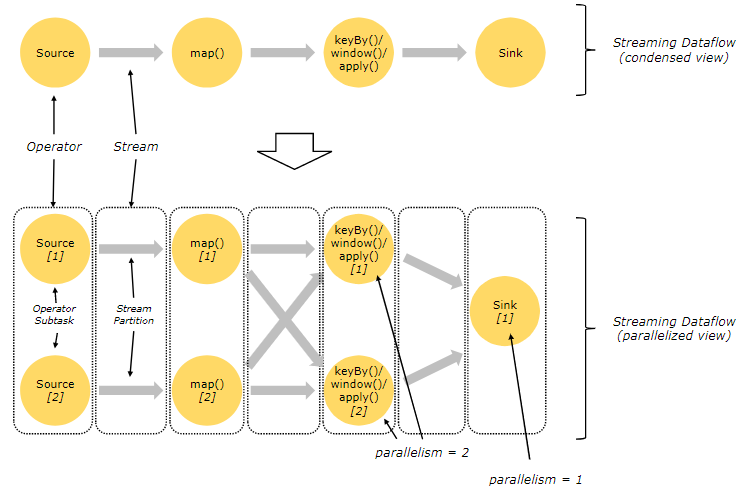
一对一模式(例如上图 condensed view 中的 Source 和 map() 算子之间)可以保留元素的分区和顺序信息。这意味着 map() 算子的输入的数据以及其顺序与 Source 算子的输出的数据和顺序完全相同,即同一分区的数据只会进入到下游算子的同一分区。
重新分发模式(例如上图 parallelized view 中的 map() 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间)会更改数据所在的流分区。当你在程序中选择使用:keyBy()(通过散列键重新分区)、broadcast()(广播)或 rebalance()(随机重新分发)会把数据发送到不同的目标子任务。如上图所示的 keyBy/window 和 Sink 算子之间数据的重新分发时,不同键(key)的聚合结果到达 Sink 的顺序是不确定的。
综上,顺序保证中有两大难点:kafka 多分区、flink 多并行度。
用 flink 处理来自 kafka 的数据时,将为每一个 topic(schema topic、data topic)创建一个 consumer,对应转换为一条流(schema stream、data stream),每一个流单独处理,互不影响。但流内数据依然存在上述的 kafka 多分区、flink 多并行度导致的乱序问题。
解决乱序问题,首先想到的是排序,但是对于一个无界数据数据流无法进行排序,由此引入窗口的概念,将有界数据流切分为一个个有界的窗口,在窗口内便于执行排序操作。
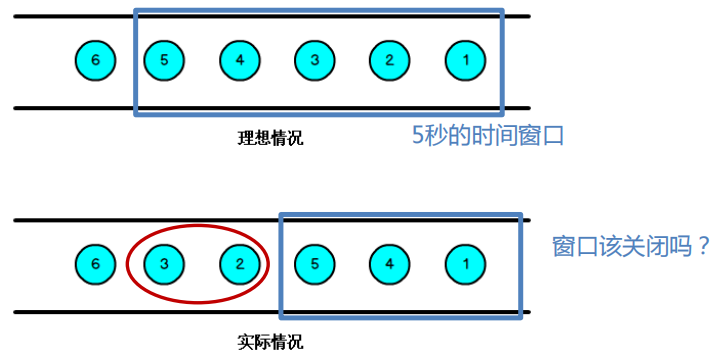
当一个窗口到了关闭时间,不应该立刻触发窗口计算,而是等待一段时间,而是等迟到的数据来了再关闭窗口。数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据都已经到达了,并在该窗口内按照事件时间处理该窗口内的数据即可保证数据处理顺序。watermark 本质上是带有特殊标记的时间戳,必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退。
注意:watermark 的设置是开发者在实时性与准确性之间的权衡
如果 watermark 设置的延迟太大,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果(增量聚合)。
如果 watermark 到达得太小,则可能收到错误结果,不过 Flink 可以通过侧输出流、允许的延迟(allowed lateness)来解决这个问题。
上面提到对于对于流处理并行任务来说顺序保证中的两大难点:kafka 多分区、流处理多并行度。flink 中给出了一个同时解决这两个问题的解决方案,watermark 是一个流层面全局的概念,即一个流中维护一个全局的 watermark,保证流中多并行任务之间的顺序,以下图为例:
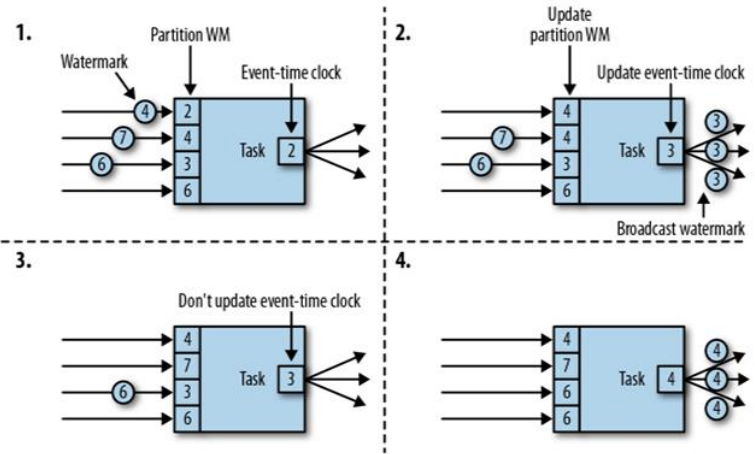
流中并行度为 4,partition WM 代表单个并行子任务的 watermark,Event-Time clock 代表该流中全局 watermark。
由此可见全局 watermark 的值取决于并行子任务 watermark 的最小值,因此为减小各分区之间的 watermark 差值,建议 kafka 分区策略使用轮询策略。
另外 flink 会根据 kafka 分区数取模 flink 并行度的方式(kafka partitions % flink parallelism)调整各子任务具体处理哪一分区的数据。有三种可能的情况:
kafka partitions = flink parallelism:这种情况是最理想的,因为每个消费者负责一个分区。如果消息在分区之间是平衡的,那么工作将均匀分布在 flink 并行任务之间;
kafka partitions < flink parallelism:一些 flink 并行任务处于空闲状态,不会收到任何消息(flink 中提供了定期空闲状态检查机制);
kafka partitions > flink parallelism:在这种情况下,某些任务将处理多个分区,造成分区数据实际上以串行执行。
建议使用第一种 kafka 分区与 flink 并行度分配方式,将 flink 并行度设置为 kafka 分区相同。
上述流内乱序引入 window+watermark 之后即可解决,但是数据处理为达到任务级别的顺序要求,不能只解决流内乱序,因为 schema stream 和 data stream 并非完全相互独立,如下:
假设某表的原始结构为:CREATE TABLE tab1(uid bigint(20), name varchar(50))),下图中 alter 代表:ALTER TABLE tab1 CHANGE COLUMN name uname varchar(50)。
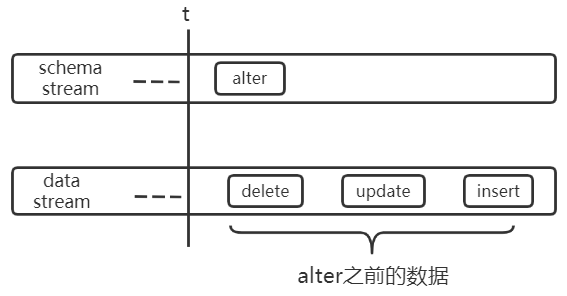
unknow column name
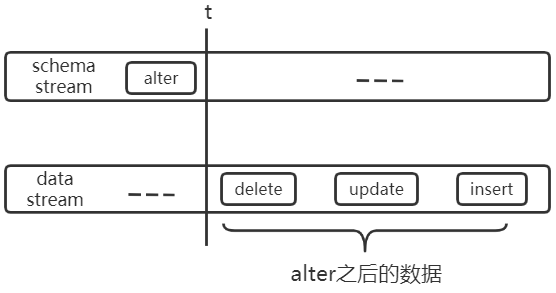
unknow column uname
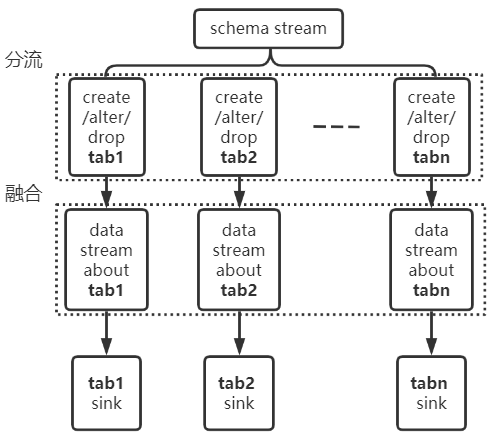
以上两个实例说明了多流之间可能出现乱序的情况,为了保证任务级顺序,需要在多流之间进行分流与融合的操作,如下:将关于 tab1 的 schema 流切分出来,将其与 tab1 的 data 流进行融合。保证其流内顺序,即可解决上述问题。
关注公众号 HEY DATA,添加作者微信,一起讨论更多。

我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl
如何在Rake任务中运行Capybara功能?例如:访问('http://google.com')谢谢! 最佳答案 在任务中尝试这样的事情:require'capybara'require'capybara/dsl'Capybara.current_driver=:seleniumBrowser=Class.new{includeCapybara::DSL}page=Browser.new.pagepage.visit("http://www.google.com")puts(page.html)
我试图在每次运行时以随机顺序将一个名称数组拆分为多个数组。我知道如何拆分它们:name_array=["bob","john","rob","nate","nelly","michael"]array=name_array.each_slice(2).to_a=>[["bob","john"],["rob","nate"],["nelly","michael"]]但是,如果我希望它每次都以随机顺序吐出它们怎么办? 最佳答案 在做同样的事情之前,打乱数组。(Array#shuffle)name_array.shuffle.each_s
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n