📒博客首页:Sonesang的博客
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
❤️ :热爱Java与算法学习,期待一起交流!
🙏作者水平很有限,如果发现错误,求告知,多谢!
🌺有问题可私信交流!!!
目录
hello大家好啊,蓝桥杯还有十天不到就要开赛啦,今天蓝桥杯省赛的省赛冲刺营结课了,最后一讲学长分析了历年考点,并且进行了押题,现在我们就来看一下学长押了哪些内容吧
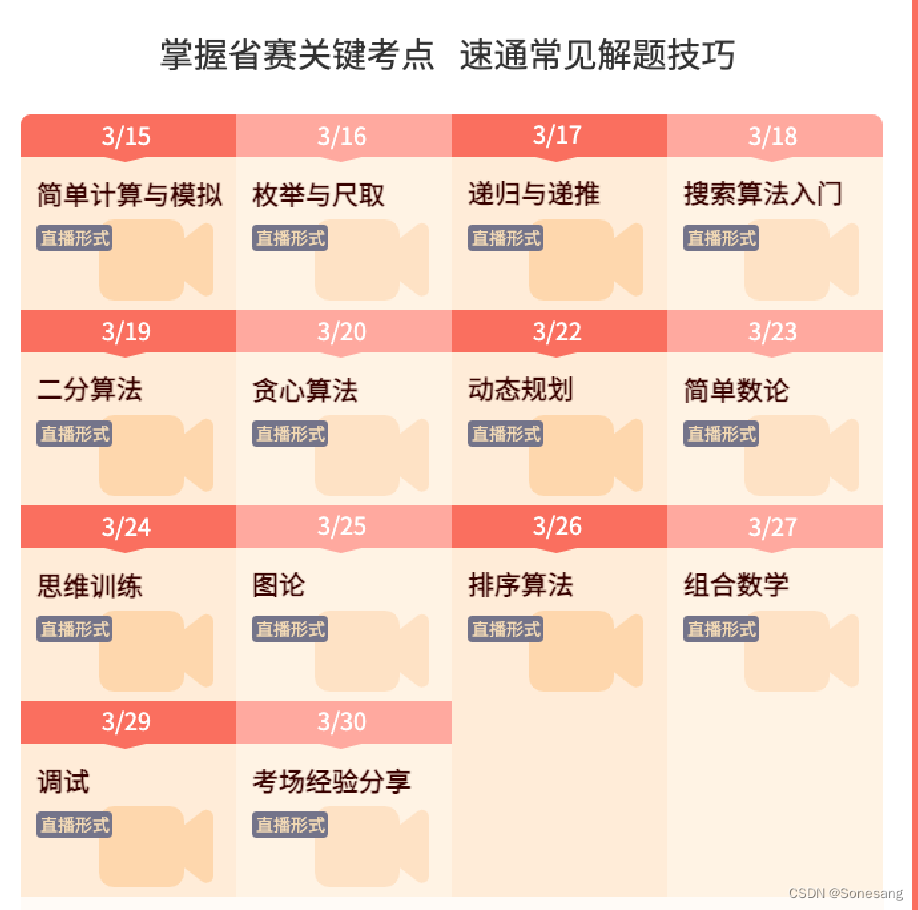
这是学长冲刺班的知识点,我们可以对应的去看一下进行复习
速度:比赛只有4小时,平时做练习题时不要慢悠悠
刷题量:提高编码熟练度、建模能力
知识点:必考和常考的知识点
- 速度:比赛只有4小时,平时做练习题时不要慢悠悠
- 刷题量:提高编码熟练度、建模能力
- 知识点:必考和常考的知识点
| 知识点 | 题目 |
| 杂题 | 2017油漆面积,2018付账问题、2019最大降雨量、2019外卖店优先级、2020蛇形填数、2020成绩分析、2020回文日期、2022裁纸刀 |
| 基本数据结构 | 二叉树(2019完全二叉树的值) |
| 基础算法 | 枚举(2018打印图形、2021卡片)、差分(2018三体攻击)、倍增 |
|
| 二分法(2017分巧克力、2022青蛙过河)、前缀和(2022求和) |
| 搜索 | DFS(2017迷宫、2017方格分割、2017正则问题)、BFS(2017跳蚱蜢、2018全球变暖、2019迷宫) |
| 高级数据结构 | 并查集(2019修改数组、2020七段码、2022推导部分和)、线段树(2022选数异或、2022最长不下降子序列、2022扫描游戏) |
| 动态规划 | 线性DP(2017字母组串,2017最大公共子串、2017包子凑数、2020字串排序、2021砝码称重、2021括号序列、2022选数异或) |
|
| 状态压缩DP(2019糖果、2021回路计数)、树形DP(2021左孩子右兄弟)、单调优化(2021分果果) |
| 数学
| 简单数学:2018分数,2018星期一,2018乘积尾零、2018第几个幸运数、2019平方和、2019数列求值、2020门牌制作、2020平面分割 |
|
| 数论:余数(2018倍数问题)、GCD(2017包子凑数,2020既约分数)、质因数分解(2021货物摆放)、素数(2022数的拆分)、逆元(2022爬树的甲壳虫) |
|
| 组合数学:burnside引理(2017魔方状态)、卢卡斯定理(2019组合数问题)、博弈论(2021异或数列、2022灭鼠先锋 |
|
| 其他:快速幂(2019RSA解密) |
|
| 几何:叉积、面积(2020荒岛探测)、2021直线、2022扫描游戏 |
| 字符串 | 简单字符串处理(2018航班时间、2020子串分值) |
| 图论 | 最短路BFS(2019迷宫)、最短路Floyd(2021路径) |
|
|
| 大学A组 | 大学B组 | 大学C组 | 研究生组 | 分数 |
| 结果填空 | A B | 裁纸刀1 灭鼠先锋4 | 九进制转十进制1 顺子日期1 | 排列字母1 特殊时间2 | 裁纸刀1 灭鼠先锋4 | 5 5 |
| 程 序 设 计 | C D E F G H I J | 求和2 选数异或3 爬树的甲壳虫4 青蛙过河3 最长不下降子序列5 扫描游戏5 数的拆分4 推导部分和4 | 刷题统计2 修剪灌木2 X进制减法3 统计子矩阵3 积木画4 扫雷4 李白打酒加强版4 砍竹子4 | 纸张尺寸2 求和2 数位排序2 选数异或3 消除游戏4 重新排序4 技能升级4 重复的数4 | 质因数个数2 选数异或3 GCD 2 爬树的甲壳虫4 全排列的价值4 扫描游戏5 数的拆分4 重复的数4 | 10 10 15 15 20 20 25 25 |
| 难度 |
| 35 | 28 | 28 | 33 |
|
|
|
| 大学A组 | 大学B组 | 大学C组 | 研究生组 | 分数 |
| 结果填空 | A B | 裁纸刀1 寻找整数2 | 星期计算1 山1 | 排列字母1 特殊时间2 | 排列字母1 灭鼠先锋4 | 5 5 |
| 程 序 设 计 | C D E F G H I J | 求和2 GCD 2 蜂巢4 全排列的价值4 青蛙过河3 因数平方和4 最优清零方案5 推导部分和4 | 字符统计2 最少刷题数3 求阶乘3 最大子矩阵4 数组切分4 回忆迷宫4 红绿灯4 拉箱子4 | 纸张尺寸2 求和2 矩形拼接3 选数异或3 GCD 2 青蛙过河3 因数平方和4 最长不下降子序列5 | 质因数个数2 数位排序2 蜂巢4 爬树的甲壳虫4 重新排序4 技能升级4 最优清零方案5 推导部分和4 | 10 10 15 15 20 20 25 25 |
| 难度 |
| 31 | 30 | 27 | 34 |
|
|
|
| 大学A组 | 大学B组 | 大学C组 | 研究生组 | 分数 |
| 结果填空 | A B | 裁纸刀1 寻找整数2 | 排列字母1 寻找整数2 | 排列字母1 特殊时间2 | 裁纸刀1 寻找整数2 | 5 5 |
| 程 序 设 计 | C D E F G H I J | 质因数个数2 矩形拼接3 消除游戏4 重新排序4 全排列的价值4 最长不下降子序列5 最优清零方案5 数的拆分4 | 纸张尺寸2 数位排序2 蜂巢4 消除游戏4 全排列的价值4 技能升级4 最长不下降子序列5 最优清零方案5 | 纸张尺寸2 数位排序2 矩形拼接3 GCD 2 蜂巢 4 重新排序4 青蛙过河3 因数平方和4 | 质因数个数2 矩形拼接3 消除游戏4 爬树的甲壳虫4 技能升级4 因数平方和4 扫描游戏5 数的拆分4 | 10 10 15 15 20 20 25 25 |
| 难度 |
| 34 | 33 | 27 | 33 |
|
递归
递归+思维
递归求全排列
递推
动态规划
动态规划01背包问题
二叉树
二分查找
分治思想
黄金分割与斐波那契
计算机组成原理基本单位转换(bit/B/KB/MB/GB/TB/PB)
记忆型递归
简单计算
简单枚举
进制转换
经典dp
矩阵运算
快速排序
枚举
枚举+DFS排列组合
枚举+set去重+数学公式推导
枚举+技巧
枚举+判断
枚举+判断,数学推理减少未知数
枚举+优化(hashmap存储)
枚举+最大公约数
枚举加字符串查找
排序+set去重+map映射
排序+遍历
排序+二分
排序+奇偶性判断
前缀和+组合数学
全排列
全排列
全排列+dfs求矩阵中的连通块
全排列与字符串切割;
日期运算,细心,考虑闰年;字符串处理
时间与日期
树状数组
数学,等比数列,预处理
数学+分类讨论
数学+思维
数学+找规律
数学+最大公约数
数学思维+二分枚举
数学思维+栈
数学推理
数字分解,每位遍历
思维,归纳,找规律
思维+打表(或者通过举例)推导公式
DFS搜索、BFS搜索
素数的判断,三重暴力枚举
贪心
整数缩放,先放大后缩小(或者用String模拟)
字符处理
字符串+逆序对+前缀+后缀
字符串和数字之间转换
字符串与整数相互转化
字符串子串
最大公约数
最小生成树
最短路径(floyd,迪杰斯+求最大公约和最小公倍)
思维题,不需要算法和数据结构,只需要逻辑、推理的题目,难度可难可易。考察思维能力和编码能力,只能通过大量做题来提高。
BFS搜索和DFS搜索,也就是暴力搜索。是非常基本的算法,是基础中的基础。
动态规划。线性DP,以及一些DP应用:背包、LIS、LCS。
简单数学数论:模、幂、素数、因式分解、大数分解定理、GCD、LCM等。
简单图论:最短路(单源,多源,有无负权值)、最小生成树。
简单字符串处理、输入输出。
基本算法:排序、排列、二分、倍增、差分与前缀和、贪心。
基本数据结构:队列、栈、链表、树等
如果时间不够的话,dp可以跳,dp不会完全不影响省一,图论只看个floyd就可以(时间不够的话)
如果文章对你有所帮助,还望能给点三连支持一下,非常感谢!!! 
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(