前言:因为我要做选修课的关于ai的项目,所以整个代码其实是摘录自hwtl0703598这个csdn博客主的python人脸识别源码,不过也在调试的过程过发现了那位博客主的一些代码的问题,并改善了,我会在整篇文章后端指出改正,基本上是可以配好环境后直接使用。
简要概述之LBPH是什么?
LBPH(Local Binary PatternsHistograms)局部二进制编码直方图,建立在LBPH基础之上的人脸识别法基本思想如下:首先以每个像素为中心,判断与周围像素灰度值大小关系,对其进行二进制编码,从而获得整幅图像的LBP编码图像;再将LBP图像分为个区域,获取每个区域的LBP编码直方图,继而得到整幅图像的LBP编码直方图,通过比较不同人脸图像LBP编码直方图达到人脸识别的目的,其优点是不会受到光照、缩放、旋转和平移的影响。
PS:OpenCV提供了三种人脸识别的方法,分别是LBPH方法、EigenFishfaces方法、Fisherfaces方法。
为什么要使用LBPH而不是其他?
LBPH:将检测到的人脸分为小单元, 并将其与模型中的对应单元进行比较, 对每个区域的匹配值产生一个直方图。 由于这种方法的灵活性, LBPH是唯一允许模型样本人脸和检测到的人脸在形状、 大小上可以不同的人脸识别算法。
人脸识别的步骤
准备工作:
人脸录入流程:
- step1:利用opencv的VideoCapture函数打开摄像头并获取视频流。
- step2:获取视频流的每一帧的图像,将图像转成灰度图,在图像上利用opencv人脸检测器去检测人脸,并在人脸上画个框,保存框里面的人脸的图像到自己选定的图像文件夹,保存200张左右,实际是训练越多,识别的成功率也越高。
- step3:最后保存完200张图像,程序自动结束,释放摄像头缓存并关闭窗口。
PS:每张人脸需要转成灰度图,图像灰度化的目的是为了简化矩阵,提高运算速度,这里是提高识别效率。
人脸录入完整代码
import cv2
cap = cv2.VideoCapture(0)
face_detector = cv2.CascadeClassifier('D:/opencv\sources/data/haarcascades/haarcascade_frontalface_default.xml')
face_id = input('User data input,Look at the camera and wait ...')
count = 0
while cap.isOpened():
ret, frame = cap.read()
if ret is True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
break
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + w), (255, 0, 0))
count += 1
cv2.imwrite("D:/opencv_test/" + str(face_id) + '.' + str(count) + '.jpg', gray[y:y + h, x:x + w])
cv2.imshow('image', frame)
k = cv2.waitKey(1)
if k == 27:
break
elif count >= 200:
break
cap.release()
cv2.destroyAllWindows()代码解析:
效果展示1

效果展示2

人脸数据集训练流程
- step1:给出保存好的人脸图像文件夹的路径,遍历该路径下所有的图片,通过os函数,导入图片的名字和图像进face_samples和ids两个list数组,图片通过numpy中的array函数转成数组。
- step2:调用LBPH人脸识别器,将图像数组和对应的图像名进行训练,并将结果保存到trainer/trainer.yml这个文件下。
人脸训练完整代码
import os
import cv2
import numpy as np
from PIL import Image
path = 'D:/opencv_test/'
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier('D:/opencv\sources/data/haarcascades/haarcascade_frontalface_default.xml')
def get_images_and_labels(path):
image_paths = [os.path.join(path, f) for f in os.listdir(path)]
face_samples = []
ids = []
for image_path in image_paths:
img = Image.open(image_path).convert('L')
img_np = np.array(img, 'uint8')
if os.path.split(image_path)[-1].split(".")[-1] != 'jpg':
continue
id = int(os.path.split(image_path)[-1].split(".")[0])
faces = detector.detectMultiScale(img_np)
for (x, y, w, h) in faces:
face_samples.append(img_np[y:y + h, x:x + w])
ids.append(id)
return face_samples, ids
faces, ids = get_images_and_labels(path)
recognizer.train(faces, np.array(ids))
recognizer.save('trainer/trainer.yml')
代码解析:
人脸识别流程:
人脸识别完整代码
import cv2
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml')
face_cascade = cv2.CascadeClassifier("D:/opencv\sources/data/haarcascades/haarcascade_frontalface_default.xml")
font = cv2.FONT_HERSHEY_SIMPLEX
idnum = 0
cam = cv2.VideoCapture(0)
cam.set(6, cv2.VideoWriter.fourcc('M', 'J', 'P', 'G'))
minW = 0.1 * cam.get(3)
minH = 0.1 * cam.get(4)
names = ['linluocheng','zhupengcheng']
while True:
ret, img = cam.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(int(minW), int(minH))
)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
idnum, confidence = recognizer.predict(gray[y:y + h, x:x + w])
if confidence < 80:
idum = names[idnum]
confidence = "{0}%".format(round(100 - confidence))
else:
idum = "unknown"
confidence = "{0}%".format(round(100 - confidence))
cv2.putText(img, str(idum), (x + 5, y - 5), font, 1, (0, 0, 255), 1)
cv2.putText(img, str(confidence), (x + 5, y + h - 5), font, 1, (0, 0, 0), 1)
cv2.imshow('camera', img)
k = cv2.waitKey(10)
if k == 27:
break
cam.release()
cv2.destroyAllWindows()
代码解析:
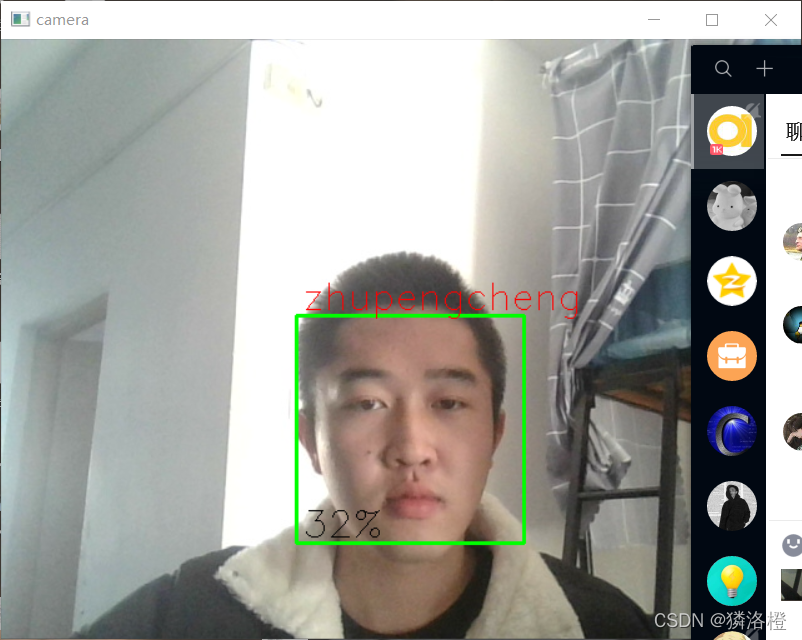
效果展示图 1

效果展示图2
1、这里的代码是我通过别人的代码稍作修改的,如果你碰到了问题去找其他的人的意见去修改,还是会出现问题,如果出现函数没有找到,不存在的问题,那就是opencv的版本问题,在更新迭代后各种函数会出现相应修改。
2、有人用这个博客的代码出了各种问题,原因是一个训练的流程不是很清楚,关键在于人脸录入的时候的输入名称,这里针对能运行程序,给出以下的流程。
step1(注意这里输入的是0,1,2,最好按照顺序输入):

step2:
人脸训练直接运行即可。
step3(在人脸识别代码中,会有一个类似的names列表,这个就是我们自定义的名字,在录入人脸的时候的序号,即对应这里的下标,然后取得对应的人脸标签):
 step3:
step3:
然后进行识别,最终识别完成。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.