因为期末了,要检查web大作业,虽然没有要求,但我想把项目部署一下,以免每次都要打开运行了,部署过踩了许多坑,这里总结一一下这次部署的流程吧。项目我个人进行前后端分离的全栈开发,有后台,后台部署的过程由于篇幅原因将在下一篇中讲解
首先,由于真实的项目基本上都部署在linux系统上,因此为了贴近真实,我们需要准备一台带有linux系统的虚拟机或者云服务器,由于虚拟机不能在自己的电脑关机了以后继续运行,因此这里推荐云服务器,目前用过阿里云,腾讯云两款云服务器部署项目,操作基本上都十分简单。
新用户可以在腾讯云和阿里云平台都有两周的免费云服务器可以领取,可便学习使用。
腾讯云赠送的云服务器2周

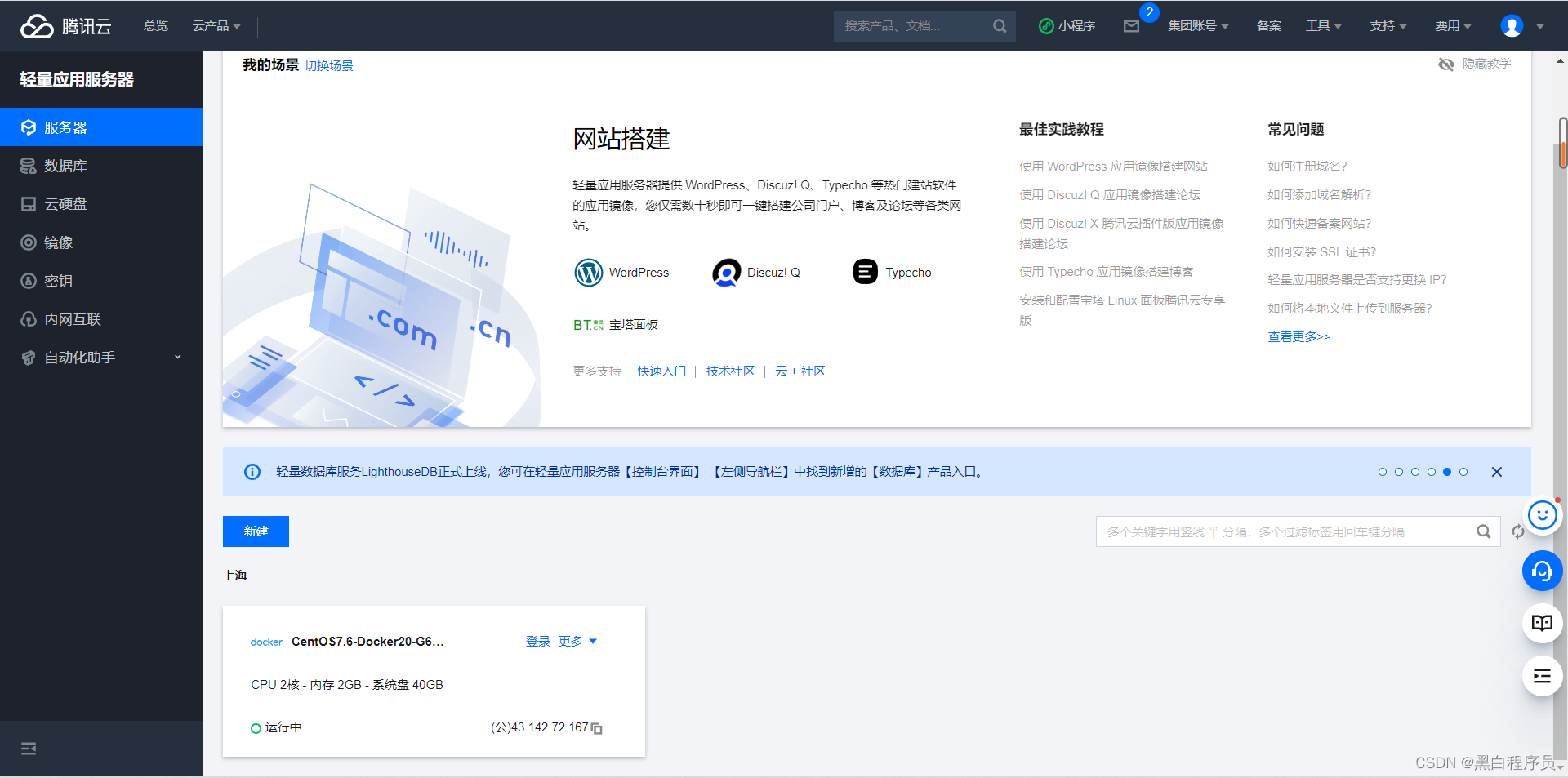
这样我们就有一个云服务器可以使用了
点击我们的服务器,点击重置密码

记住重置后的密码,重置后等待服务器重新启动。
服务器重新启动完毕之后,我们需要一个远程连接的软件
这里我使用的是Xshell7he和Xftp7,一个用来控制终端,一个用来传输文件。

准备好这两个软件之后,我们打开Xshell7
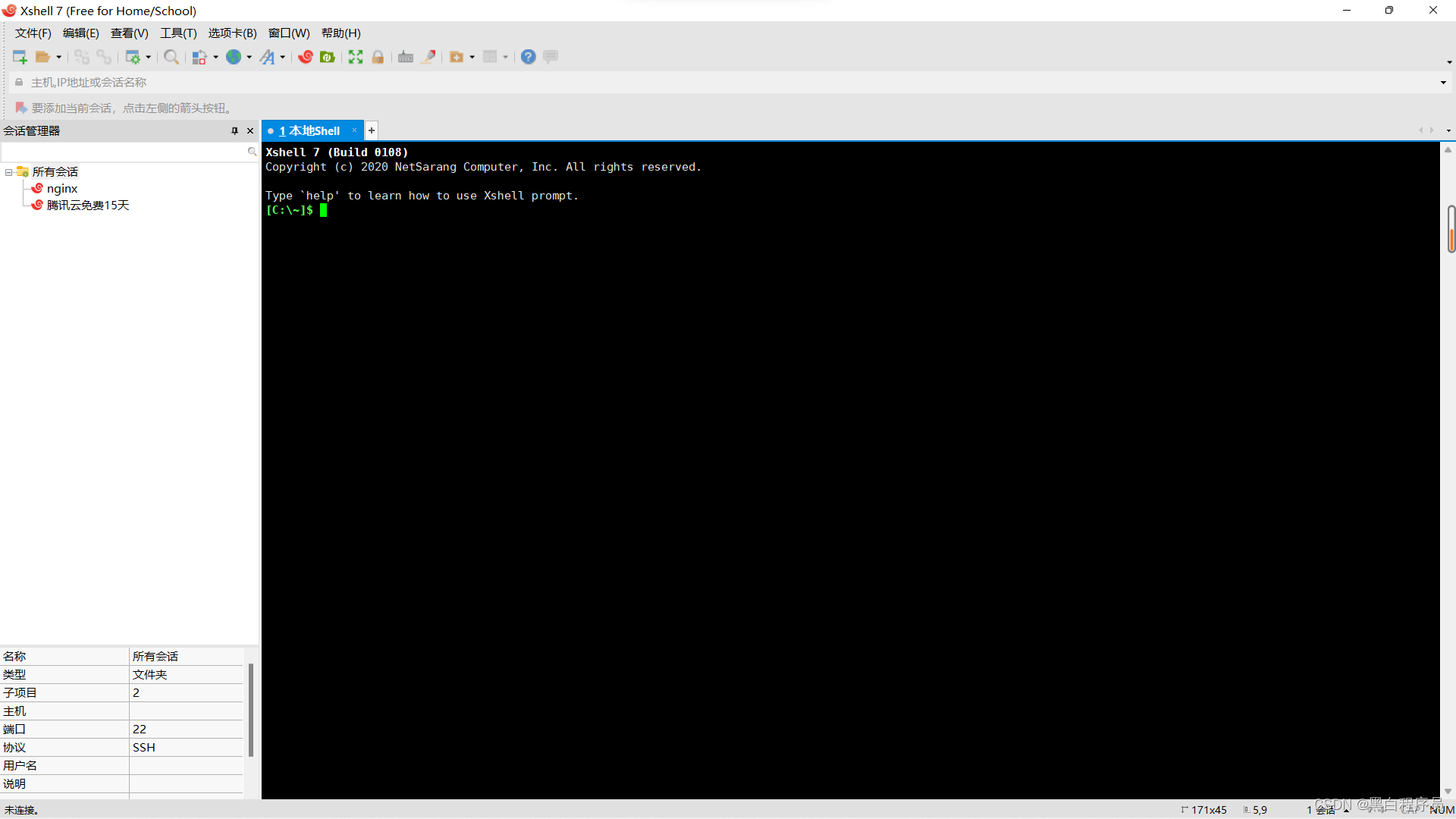
初始界面如下,默认情况下连接的是本地shell,也即是和dos窗口是同一个效果。
因为我们要远程连接云服务器,所以肯定不是用本地shell,我们选择新建
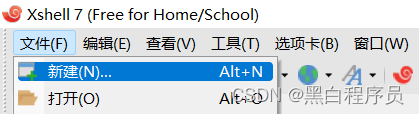
这里要输入的内容不多,在名称位置输入名称,以及在主机位置输入主机的公网IP即可,点击下一步
随后就会让我们输入用户名和密码,用户名就是root,密码就是之前重置过后的密码。
验证无误后,我们就进入了云服务器的终端,可以输入命令操控云服务器了

在终端输入npm run build会在项目目录下生成一个dist文件,这就是我们需要运行的的打包好的项目。
我们的项目是在nginx上部署的,因此需要在云服务器上下载安装一个nginx。现在提供两种方式安装。
我们进入宝塔官网
可以看到四个命令行脚本,我们选择对应云服务器系统的脚本就行了
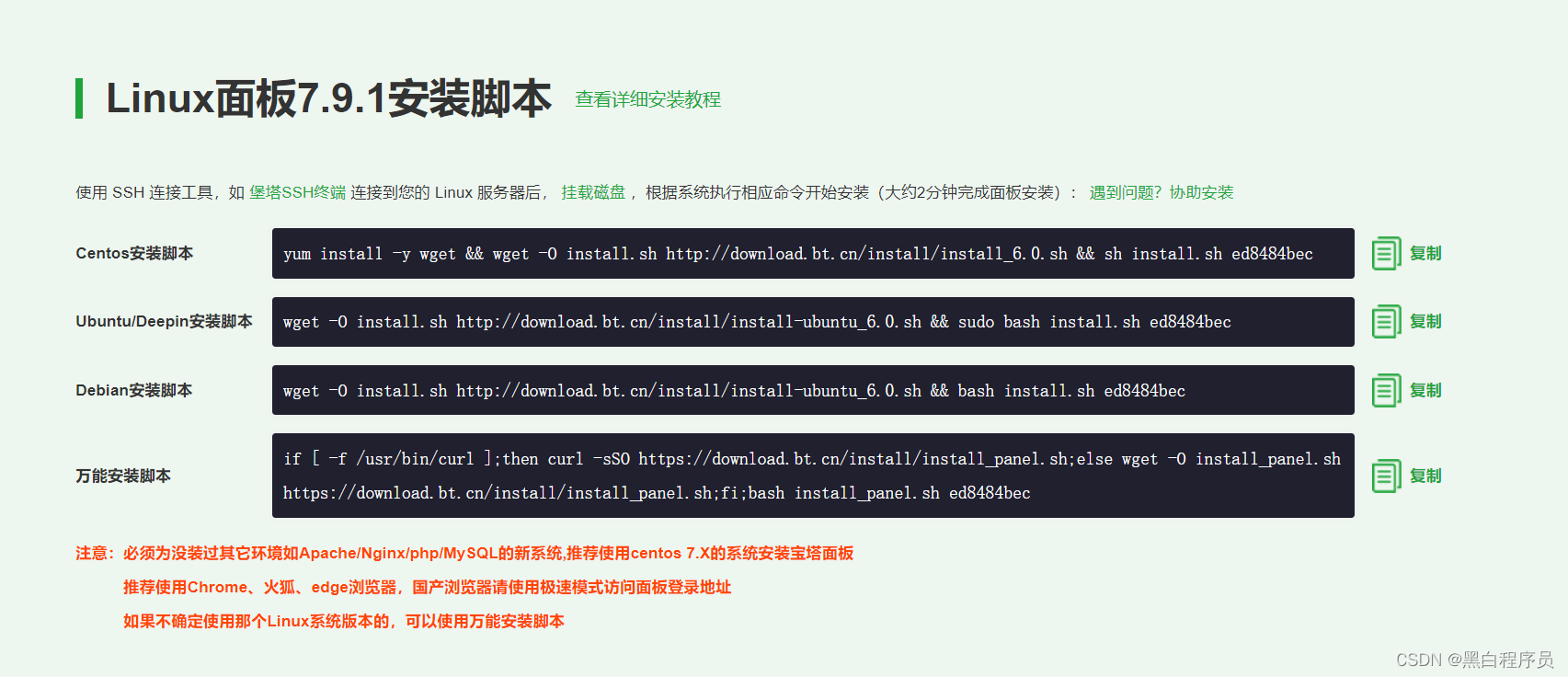
这里我使用的是centos7.6系统,因此使用的是第一个脚本
yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh ed8484bec
将这行脚本输入到命令行,我们就安装完毕了。

安装结束后,在打印的日志中会有一个网址,一个用户名和密码,我们需要记录下这个网址,和用户名密码,之后会用到
复制网址在浏览器中打开。输入用户名和密码,我们就来到了宝塔界面
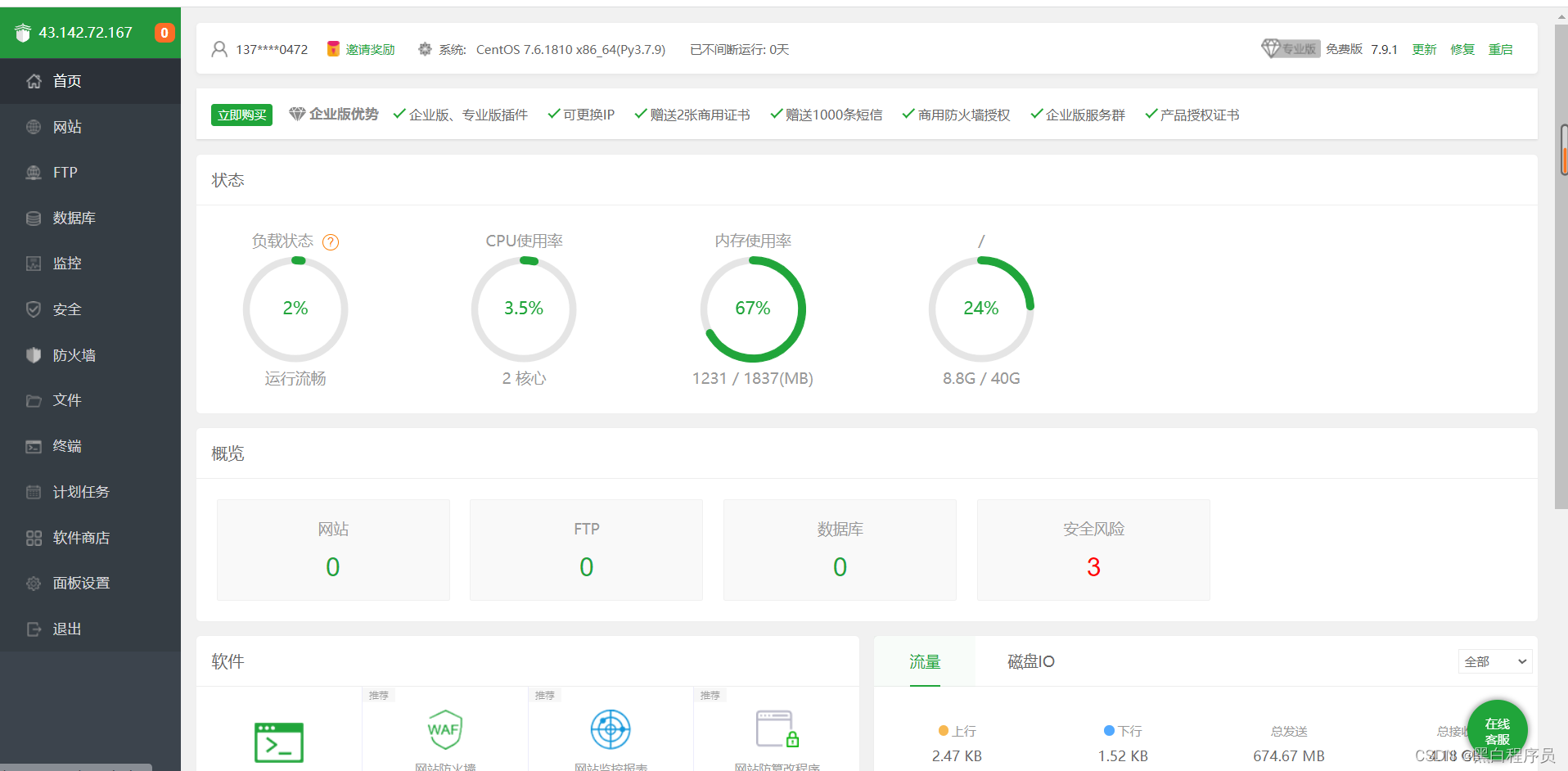
进入软件商店,我们就可以下载nginx了
下载完,我们回到Xshell,由于命令行看不太清楚,我们选择Xftp打开,就可以看见在/www/server/下就已经有了一个nginx了
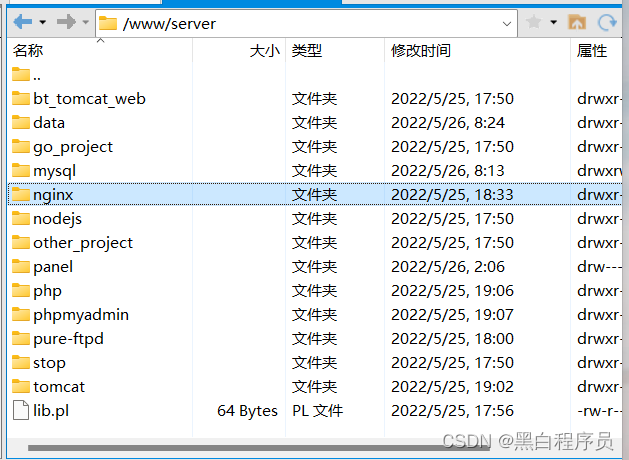
然后我们进入到nginx文件目录下

可以看到有很多文件。我们这次会用到的有conf,html和sbin三个文件
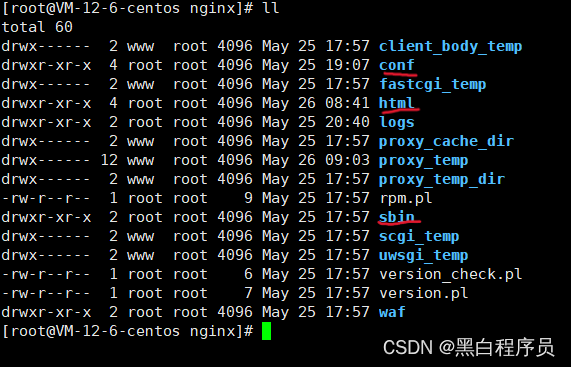
html是我们项目部署的文件

我们将打包好的dist文件拖动到下面的html下面。这是项目就部署完成了
然后我们要启动nginx服务器,我们需要在腾讯上把80端口放开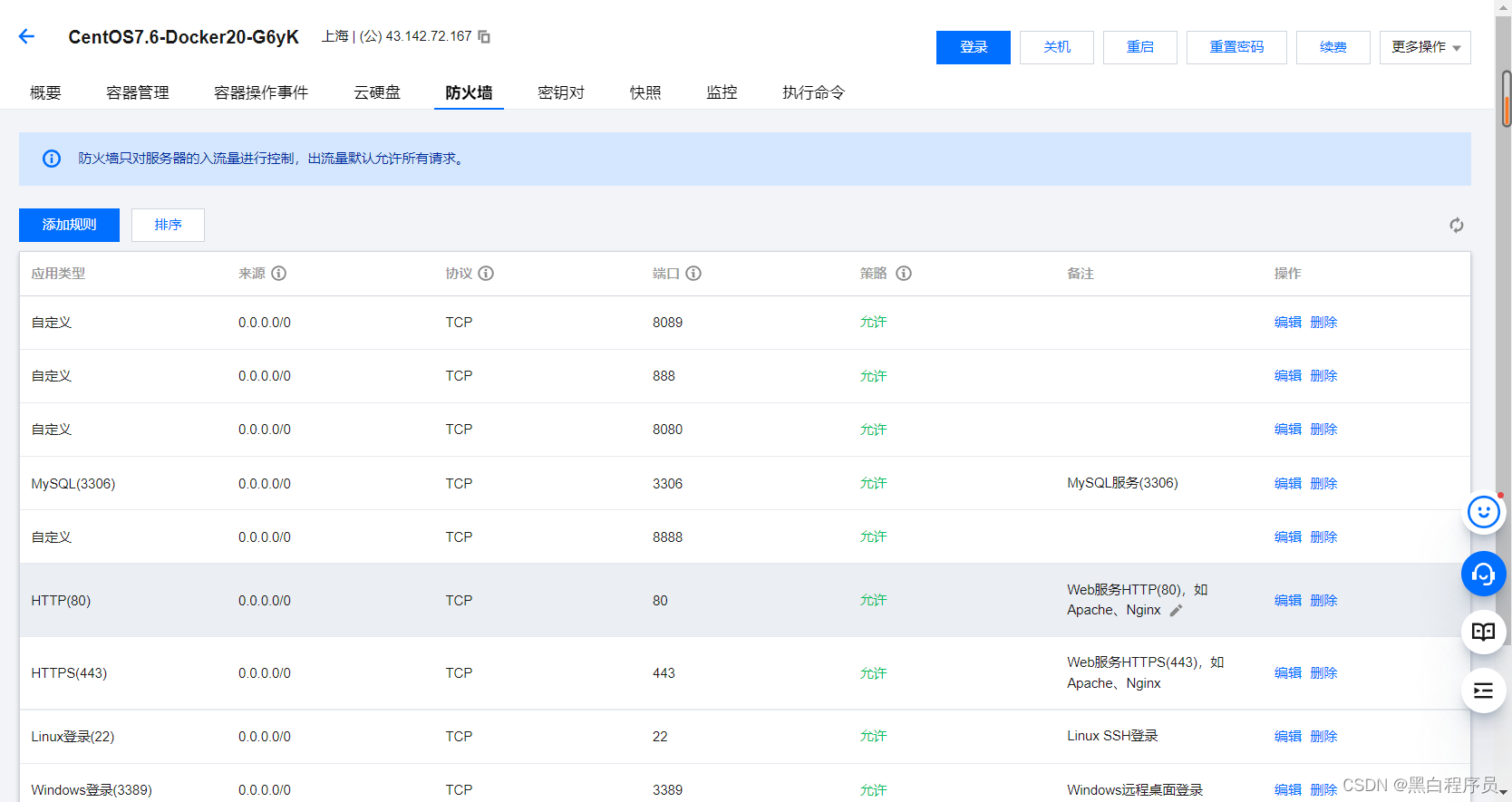
然后在宝塔面板上把80端口放开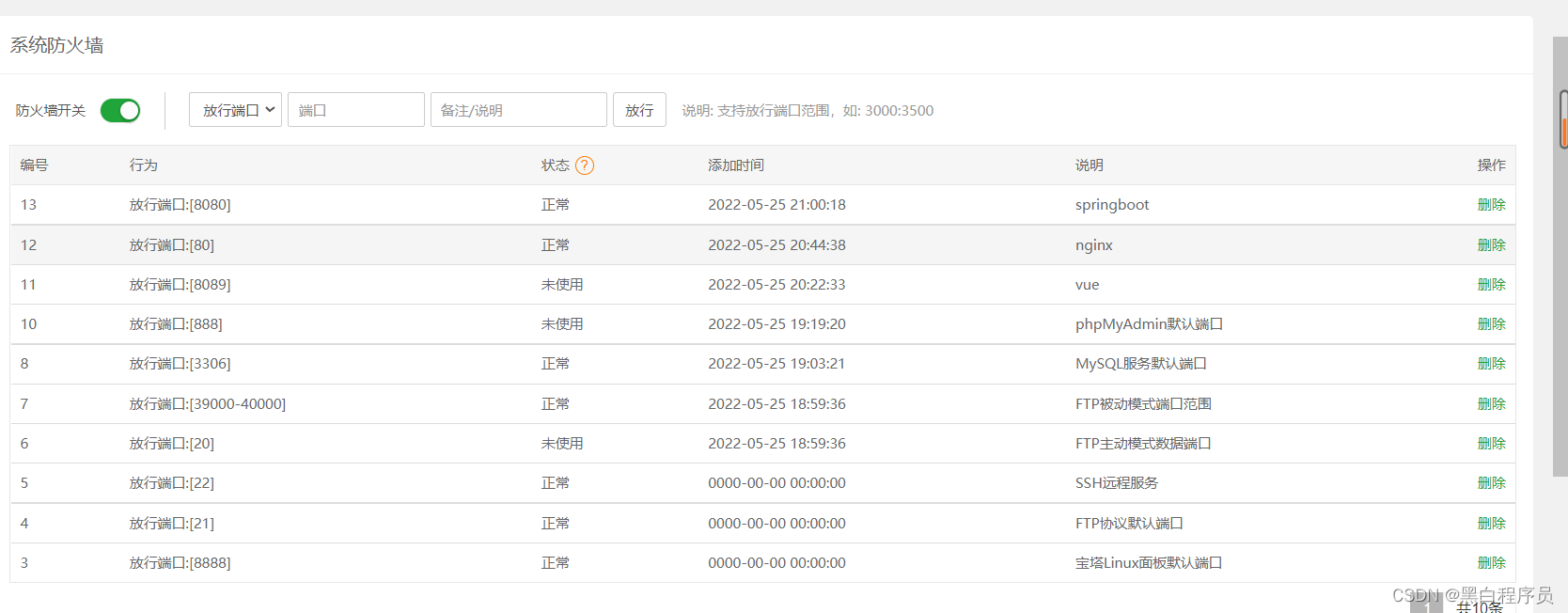 由于80是nginx默认的端口号,要想外网能够访问网站,启动之前我们要保证这个80端口号是放开状态的,在腾讯云和宝塔上都要放开。
由于80是nginx默认的端口号,要想外网能够访问网站,启动之前我们要保证这个80端口号是放开状态的,在腾讯云和宝塔上都要放开。
接下来我们进入到sbin目录下
nginx //启动nginx
nginx -s reload //重启nginx
nginx -s quit //等待完成相关工作后,停止nginx
nginx -s stop //强行停止nginx

我们这里启动nginx服务器
ps -ef | grep nginx //查看是否存在nginx进程命令
查看到我们的服务器中存在nginx进程

此时启动成功了,我们就可以通过公网ip+端口号访问了
宝塔面板和腾讯的防火墙必须全部放行80端口
查看80端口被哪个进程占用
lsof -i :8080
或者
lsof -i | grep 8080

kill -9 PID //PID为占用80端口的pid
可能是我们nginx配置出了问题,为了清晰,我就用Xftp进行演示,我们需要进入nginx下的conf目录,用记事本编辑。
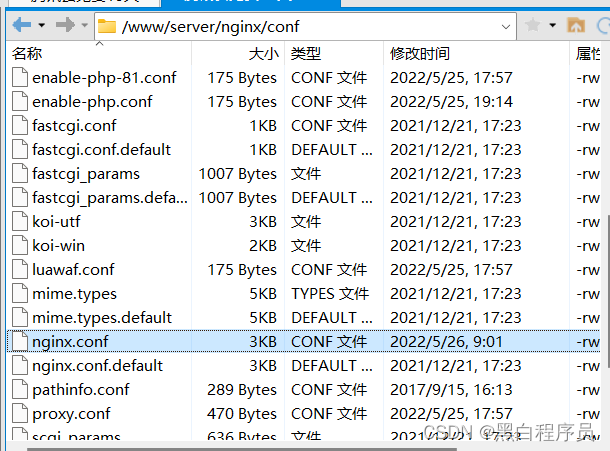
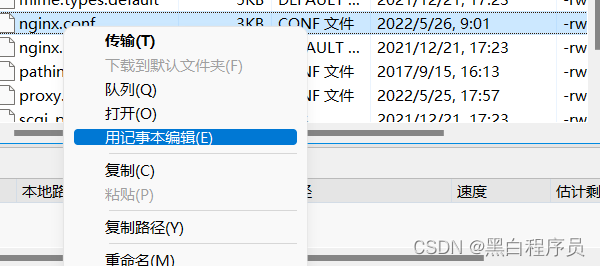
第一次下载nginx的时候,宝塔帮我在nginx.conf中做了一些修改,导致网页运行失败,此时,我们需要将nginx.conf.default的内容,复制一份,粘贴到nginx.conf中,恢复默认配置。
随后我们找到nginx.conf中的这块代码

由于我们的index文件是在dist中,因此把这里的location的根路径改一下

我们这样就完成了对vue的简单部署。
我们在开发环境中,vue为我们创建了一个proxy服务器可以解决跨域问题,而打包以后,proxy并没有一起打包,因此我们需要用nginx进行反向代理。如果项目是由服务端处理跨域问题,则可以不需要nginx进行反向代理
由于我的项目前后端都部署在同一个服务器上,因此通过nginx当作中转服务器,把前端项目(在nginx,80端口上运行),发送的请求转发给后端项目(在tomcat,8080端口上运行),具体进行的配置如下,正则为复制网上的代码,可以和vue.config.js中的proxy产生一个对应关系。

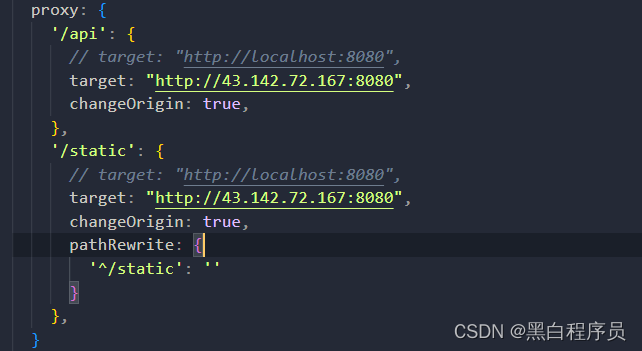
vue前端项目就在服务器上部署完毕咯,要想这个项目可以连接后端服务器,要将后端项目也部署,部署的方式会在下一篇博客中讲解。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除