前置工作:安装OpenBLAS; 安装Mpich (可参考首页博客)
官网下载压缩包到/opt目录
cd /opt && wget https://www.netlib.org/benchmark/hpl/hpl-2.3.tar.gz

解压到 /opt 目录
tar -xzf hpl-2.3.tar.gz
复制Make.Linux_PII_CBLAS并重命名
cd /opt/hpl-2.3 && cp setup/Make.Linux_PII_CBLAS Make.Linux
编辑Make.Linux
vim Make.Linux
修改如下内容:
ARCH = Linux
TOPdir = /opt/hpl-2.3 # hpl安装目录
MPdir = /opt/mpich # mpich安装目录
MPlib = $(MPdir)/lib/libmpi.so # mpi链接库
LAdir = /opt/OpenBLAS # openblas安装目录
LAlib = $(LAdir)/lib/libopenblas.so # openblas链接库
CC = /opt/mpich/bin/mpicc # compiler
CCFLAGS = $(HPL_DEFS) -fomit-frame-pointer -O3 -funroll-loops -lpthread
LINKER = /opt/mpich/bin/mpif77 # linker
以上路径根据个人安装时的目录修改
构建hpl
make arch=Linux
若build成功,则会在/opt/hpl-2.3/bin/Linux目录下生成HPL.dat和xhpl文件
测试hpl
cd /opt/hpl-2.3/bin/Linux
单节点测试
mpiexec -np 4 ./xhpl
多节点测试
需关闭各个节点的防火墙
systemctl stop firewalld
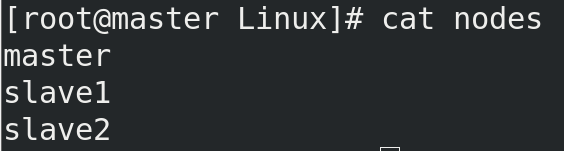
编辑节点文件,输入节点主机名或IP地址
vim nodes
eg:
修改HPL.dat
HPLinpack benchmark input file
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any)
6 device out (6=stdout,7=stderr,file)
1 # of problems sizes (N)
1200 Ns
1 # of NBs
232 NBs
0 PMAP process mapping (0=Row-,1=Column-major)
1 # of process grids (P x Q)
1 Ps
4 Qs
16.0 threshold
1 # of panel fact
0 PFACTs (0=left, 1=Crout, 2=Right)
1 # of recursive stopping criterium
2 NBMINs (>= 1)
1 # of panels in recursion
2 NDIVs
1 # of recursive panel fact.
0 RFACTs (0=left, 1=Crout, 2=Right)
1 # of broadcast
0 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
1 # of lookahead depth
1 DEPTHs (>=0)
2 SWAP (0=bin-exch,1=long,2=mix)
64 swapping threshold
0 L1 in (0=transposed,1=no-transposed) form
0 U in (0=transposed,1=no-transposed) form
1 Equilibration (0=no,1=yes)
8 memory alignment in double (> 0)
运行hpl
mpiexec -np 4 -machinefile ./nodes ./xhpl

HPL.dat配置项解释
HPLinpack benchmark input file # 文件头,说明
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any) # 如果使用文件保留输出结果,设定文件名
6 device out (6=stdout,7=stderr,file) # 输出方式选择(stdout,stderr或文件)
2 # of problems sizes (N) # 指出要计算的矩阵规格有几种
1960 2048 Ns # 每种规格分别的数值
2 # of NBs # 指出使用几种不同的分块大小
60 80 NBs # 分别指出每种大小的具体值
2 # of process grids (P x Q-l # 指出用几种进程组合方式
2 4 Ps # 每对PQ具体的值
2 1 Qs
16.0 threshold # 余数的阈值
1 # of panel fact # 用几种分解方法
1 PFACTs (0=left, 1=Crout, 2=Right) # 具体用哪种,0 left,1 crout,2 right
1 # of recursive stopping criterium # 几种停止递归的判断标准
4 NBMINs (>= 1) # 具体的标准数值(须不小于1)
1 # of panels in recursion # 递归中用几种分割法
2 NDIVs # 这里用一种NDIV值为2,即每次递归分成两块
1 # of recursive panel fact. # 用几种递归分解方法
2 RFACTs (0=left, 1=Crout, 2=Right) # 这里每种都用到(左,右,crout分解)
1 # of broadcast # 用几种广播方法
3 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) # 指定具体哪种(有1-ring,1-ring Modified,2-ring,2ring Modified,Long以及long-Modified)
1 # of lookahead depth # 用几种向前看的步数
1 DEPTHs (>=0) # 具体步数值(须大于等于0)
2 SWAP (0=bin-exch,1=long,2=mix) # 哪种交换算法(bin-exchange,long或者二者混合)
64 swapping threshold # 采用混合的交换算法时使用的阈值
0 L1 in (0=transposed,1=no-transposed) form # L1是否用转置形式
0 U in (0=transposed,1=no-transposed) form # U是否用转置形式表示
1 Equilibration (0=no,1=yes) # 是否采用平衡状态
8 memory alignment in double (> 0) # 指出程序运行时内存分配中的采用的对齐方式
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您