小型嵌入式系统中的内存资源(SRAM)一般都比较有限,LwIP的运行平台一般都是资源受限的MCU。基于此为了能够更加高效的运行,LwIP设计了基于内存池、内存堆的内存管理以及在处理数据包时的pbuf数据结构。
本篇的主要目的是介绍基于内存堆的内存管理原理。
内存堆内存管理的特点:
按需分配,需要多少内存就分配多少内存(存在最小分配内存限制)
内存易碎片化
内存回收时一般会进行头部和尾部拼接,尽量减少内存碎片的产生
分配时间相对不确定
内存堆本质上是一大块连续内存(可以理解为数组),当需要内存时就从这个数组中按照特定算法切分一块所需大小的内存块(包含管理此块内存的内存块管理结构),将这块内存的地址提供出去(可以认为分蛋糕,需要吃多少就切多少,这样就不存在浪费);剩余内存仍然存放在内存堆中以便继续分配。
在LwIP中动态内存堆有三个实现方式:
使用标准c库malloc(需要定义MEM_LIBC_MALLOC=1)
使用多个不同尺寸的内存池作为堆内存进行分配(需要定义MEM_USE_POOLS=1和MEMP_USE_CUSTOM_POOLS=1)
使用轻量级的堆内存分配方案,即本篇要介绍的实现方式
mem.h
mem.c
在正式介绍之前,我们需要理解几个宏定义和内存堆相关的数据结构
动态内存堆分配方案中为了管理已经分配出来的内存块,每个内存块的头部都会包含一个内存块管理结构
/**
* The heap is made up as a list of structs of this type.
* This does not have to be aligned since for getting its size,
* we only use the macro SIZEOF_STRUCT_MEM, which automatically aligns.
*/
struct mem {
/** index (-> ram[next]) of the next struct */
mem_size_t next;
/** index (-> ram[prev]) of the previous struct */
mem_size_t prev;
/** 1: this area is used; 0: this area is unused */
u8_t used;
};其中mem_size_t的定义如下
#if MEM_SIZE > 64000L
typedef u32_t mem_size_t;
#define MEM_SIZE_F U32_F
#else
typedef u16_t mem_size_t;
#define MEM_SIZE_F U16_F
#endif /* MEM_SIZE > 64000 */
#endif根据MEM_SIZE是否大于64000字节,决定mem_size_t是u32_t还是u16_t类型。
struct mem内存块各字段含义如下:
next:下一个内存块的位置(注意此处是数组下标,并不是地址)
prev:上一个内存块的位置
used:表明此内存块是否已经使用(分配)
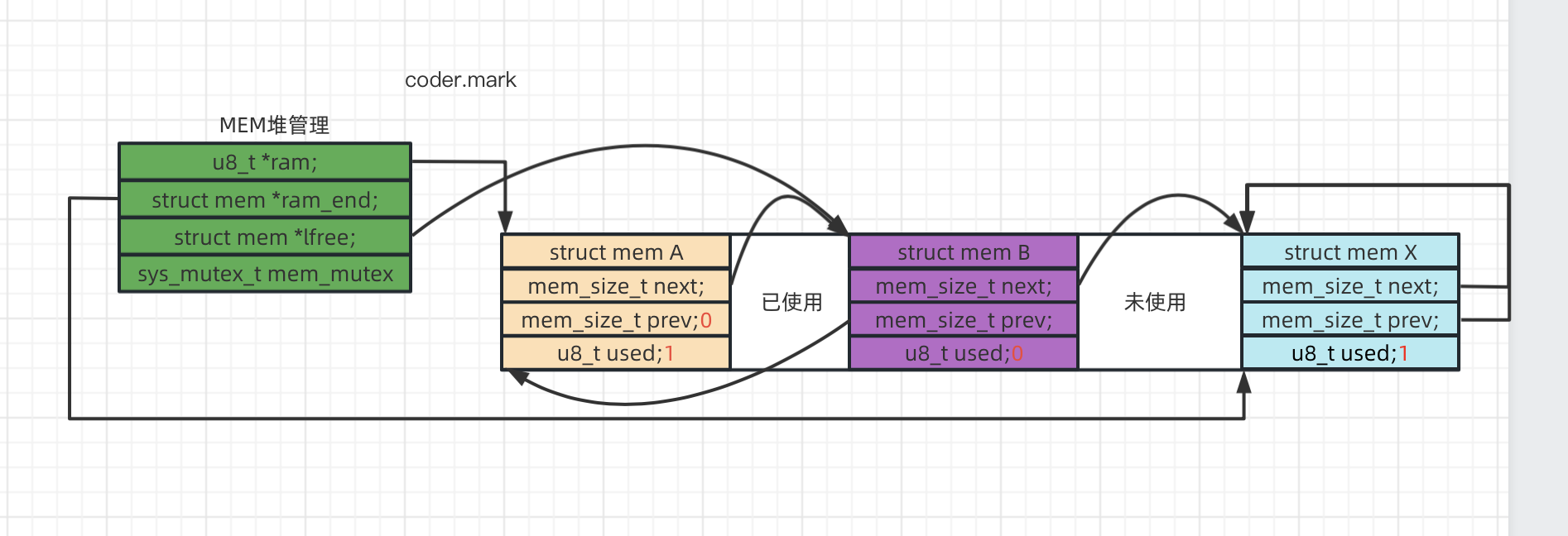
为了帮助大家更好的理解,大家可以按照下图所示从整体上理解内存堆中的内存块

内存堆示意图
上图中struct mem A和X都是内存块管理结构,紧跟着struct mem A的是A实际管理的内存区域,注意A当前管理的内存块是未使用的。
struct mem X是最后一个内存管理结构(作为tailer标志,作为内存堆中的最后一个内存管理块),其next/prev都是指向自身位置,并且是标记为已经使用的。
为了更好的管理内存堆,在LwIP中还额外定义了几个全局变量方便管理内存堆,其定义如下
/** pointer to the heap (ram_heap): for alignment, ram is now a pointer instead of an array */
static u8_t *ram;
/** the last entry, always unused! */
static struct mem *ram_end;
/** pointer to the lowest free block, this is used for faster search */
static struct mem *lfree;
/** concurrent access protection */
#if !NO_SYS
static sys_mutex_t mem_mutex;
#endifram指向整个对齐后的内存堆首地址(开发者提供的内存空间的首地址未必是4字节对齐,所以需要进行对齐后作为内存堆的首地址)
ram_end指向内存堆的末尾地址(结合上图就是指向struct mem X的位置,因为struct mem X是作为一个占位符,本身不管理实际内存数据)
lfree指向内存堆中可用内存块的第一个
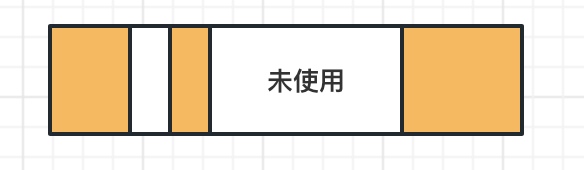
上图中黄色的块代表已经使用的内存,白色的块代表未使用的内存;可以看到白色的和黄色的内存块是会出现随机交叉的情况的(经过多次内存分配释放后会出现内存空间碎片化的情况),此处的lfree就是指向上图的中第一个白色的数据块
mem_mutex是在rtos中通过互斥锁保护内存操作的
/** All allocated blocks will be MIN_SIZE bytes big, at least!
* MIN_SIZE can be overridden to suit your needs. Smaller values save space,
* larger values could prevent too small blocks to fragment the RAM too much. */
#ifndef MIN_SIZE
#define MIN_SIZE 12
#endif /* MIN_SIZE */
/* some alignment macros: we define them here for better source code layout */
#define MIN_SIZE_ALIGNED LWIP_MEM_ALIGN_SIZE(MIN_SIZE)
#define SIZEOF_STRUCT_MEM LWIP_MEM_ALIGN_SIZE(sizeof(struct mem))
#define MEM_SIZE_ALIGNED LWIP_MEM_ALIGN_SIZE(MEM_SIZE)
/** If you want to relocate the heap to external memory, simply define
* LWIP_RAM_HEAP_POINTER as a void-pointer to that location.
* If so, make sure the memory at that location is big enough (see below on
* how that space is calculated). */
#ifndef LWIP_RAM_HEAP_POINTER
/** the heap. we need one struct mem at the end and some room for alignment */
LWIP_DECLARE_MEMORY_ALIGNED(ram_heap, MEM_SIZE_ALIGNED + (2U*SIZEOF_STRUCT_MEM));
#define LWIP_RAM_HEAP_POINTER ram_heap
#endif /* LWIP_RAM_HEAP_POINTER */MIN_SIZE:表示内存块最小管理的内存空间不能小于此值
MIN_SIZE_ALIGNED:表示MIN_SIZE四字节对齐的值
SIZEOF_STRUCT_MEM:表示结构体struct mem大小对齐后的值
MEM_SIZE:定义了内存堆最大可以分配的大小
MEM_SIZE_ALIGNED:表示MEM_SIZE四字节对齐后的值
LWIP_RAM_HEAP_POINTER:用户可以定义内存堆的首地址;如果未定义,是使用LwIP定义的ram_heap数组作为内存堆,数组大小为MEM_SIZE_ALIGNED + (2U*SIZEOF_STRUCT_MEM);
这边的这个数组大小是有讲究的,再次看下内存堆示意图,其中一个SIZEOF_STRUCT_MEM是sstruct mem X需要的空间,另外一个SIZEOF_STRUCT_MEM作为内存首地址对齐需求而预留的。
基于上面的分析我们可以知道一个最小的内存块的大小为SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED字节(包括内存块管理结构和其管理的最小内存块)。
#if MEM_OVERFLOW_CHECK
#define MEM_SANITY_OFFSET MEM_SANITY_REGION_BEFORE_ALIGNED
#define MEM_SANITY_OVERHEAD (MEM_SANITY_REGION_BEFORE_ALIGNED + MEM_SANITY_REGION_AFTER_ALIGNED)
#else
#define MEM_SANITY_OFFSET 0
#define MEM_SANITY_OVERHEAD 0
#endifMEM_SANITY_OFFSET用于对内存块的完整性进行检查(定义MEM_OVERFLOW_CHECK时才使能)
由于各种原因(野指针、非法指针操作),内存块中的数据可能会被意外改写,通过在内存块中加入一小块区域检查其值是否被意外改写来判断内存块是否被破坏
从内存堆中分配内存之前必须先对内存堆进行初始化
/**
* Zero the heap and initialize start, end and lowest-free
*/
void
mem_init(void)
{
struct mem *mem;
LWIP_ASSERT("Sanity check alignment",
(SIZEOF_STRUCT_MEM & (MEM_ALIGNMENT-1)) == 0); //①
/* align the heap */
ram = (u8_t *)LWIP_MEM_ALIGN(LWIP_RAM_HEAP_POINTER); //②
/* initialize the start of the heap */
mem = (struct mem *)(void *)ram;
mem->next = MEM_SIZE_ALIGNED;
mem->prev = 0;
mem->used = 0; //③
/* initialize the end of the heap */
ram_end = (struct mem *)(void *)&ram[MEM_SIZE_ALIGNED];
ram_end->used = 1;
ram_end->next = MEM_SIZE_ALIGNED;
ram_end->prev = MEM_SIZE_ALIGNED; //④
/* initialize the lowest-free pointer to the start of the heap */
lfree = (struct mem *)(void *)ram; //⑤
MEM_STATS_AVAIL(avail, MEM_SIZE_ALIGNED); //⑥
if (sys_mutex_new(&mem_mutex) != ERR_OK) { //⑦
LWIP_ASSERT("failed to create mem_mutex", 0);
}
}mem_init负责内存堆的初始化。
①检查SIZEOF_STRUCT_MEM的值是否4字节对齐
②将全局ram指针设置为对齐后的内存堆的内存首地址,注意这边通过宏LWIP_MEM_ALIGN对LWIP_RAM_HEAP_POINTER地址对齐,因为LWIP_RAM_HEAP_POINTER有可能是开发者定义的值,未必是对齐的地址值;
③从内存堆的首地址处切割出一个新的内存块A,将第一个内存块A进行各个字段初始化,其next的值设置为MEM_SIZE_ALIGNED(就是设置为struct mem X在数组中的位置),prev设置为0,说明struct mem A是第一个内存管理块,并且used设置为0,说明是未使用的内存块区域;也就是说struct mem A管理的内存空间有MEM_SIZE_ALIGNED - SIZEOF_STRUCT_MEM字节大小。
④将ram_end指向数组ram[MEM_SIZE_ALIGNED]的地址,也就是struct mem X的地址,并且其prev/next的值是自身在数组中的相对位置,表明其是内存堆中的最后一个位置(used设置为1)
⑤lfee指向第一个内存块的位置,也就是struct mem A
⑥LwIP中对各个模块都有特定的debug字段,此处avail字段记录的内存堆中的可用内存
⑦初始化互斥锁
初始化后的内存堆如下图所示

初始化后的内存堆
注意观察上图中各个字段的连线关系,也就是说初始状态下,只有一个空闲内存块,其管理的内存大小为MEM_SIZE_ALIGNED - SIZEOF_STRUCT_MEM。
/**
* Allocate a block of memory with a minimum of 'size' bytes.
*
* @param size is the minimum size of the requested block in bytes.
* @return pointer to allocated memory or NULL if no free memory was found.
*
* Note that the returned value will always be aligned (as defined by MEM_ALIGNMENT).
*/
void *
mem_malloc(mem_size_t size)
{
mem_size_t ptr, ptr2;
struct mem *mem, *mem2;
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
u8_t local_mem_free_count = 0;
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
LWIP_MEM_ALLOC_DECL_PROTECT();
if (size == 0) {
return NULL;
}
/* Expand the size of the allocated memory region so that we can
adjust for alignment. */
size = LWIP_MEM_ALIGN_SIZE(size);
if (size < MIN_SIZE_ALIGNED) {
/* every data block must be at least MIN_SIZE_ALIGNED long */
size = MIN_SIZE_ALIGNED;
} //①
if (size > MEM_SIZE_ALIGNED) { //②
return NULL;
}
/* protect the heap from concurrent access */
sys_mutex_lock(&mem_mutex); //③
LWIP_MEM_ALLOC_PROTECT();
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
/* run as long as a mem_free disturbed mem_malloc or mem_trim */
do {
local_mem_free_count = 0;
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
/* Scan through the heap searching for a free block that is big enough,
* beginning with the lowest free block.
*/
for (ptr = (mem_size_t)((u8_t *)lfree - ram); ptr < MEM_SIZE_ALIGNED - size;
ptr = ((struct mem *)(void *)&ram[ptr])->next) { //④
mem = (struct mem *)(void *)&ram[ptr];
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_free_count = 0;
LWIP_MEM_ALLOC_UNPROTECT();
/* allow mem_free or mem_trim to run */
LWIP_MEM_ALLOC_PROTECT();
if (mem_free_count != 0) {
/* If mem_free or mem_trim have run, we have to restart since they
could have altered our current struct mem. */
local_mem_free_count = 1;
break;
}
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
if ((!mem->used) &&
(mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size) { //⑤
/* mem is not used and at least perfect fit is possible:
* mem->next - (ptr + SIZEOF_STRUCT_MEM) gives us the 'user data size' of mem */
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >= (size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED)) { //⑥
/* (in addition to the above, we test if another struct mem (SIZEOF_STRUCT_MEM) containing
* at least MIN_SIZE_ALIGNED of data also fits in the 'user data space' of 'mem')
* -> split large block, create empty remainder,
* remainder must be large enough to contain MIN_SIZE_ALIGNED data: if
* mem->next - (ptr + (2*SIZEOF_STRUCT_MEM)) == size,
* struct mem would fit in but no data between mem2 and mem2->next
* @todo we could leave out MIN_SIZE_ALIGNED. We would create an empty
* region that couldn't hold data, but when mem->next gets freed,
* the 2 regions would be combined, resulting in more free memory
*/
ptr2 = ptr + SIZEOF_STRUCT_MEM + size; //⑦
/* create mem2 struct */
mem2 = (struct mem *)(void *)&ram[ptr2];
mem2->used = 0;
mem2->next = mem->next;
mem2->prev = ptr;
/* and insert it between mem and mem->next */
mem->next = ptr2;
mem->used = 1;
if (mem2->next != MEM_SIZE_ALIGNED) {
((struct mem *)(void *)&ram[mem2->next])->prev = ptr2;
}
MEM_STATS_INC_USED(used, (size + SIZEOF_STRUCT_MEM));
} else {
/* (a mem2 struct does no fit into the user data space of mem and mem->next will always
* be used at this point: if not we have 2 unused structs in a row, plug_holes should have
* take care of this).
* -> near fit or exact fit: do not split, no mem2 creation
* also can't move mem->next directly behind mem, since mem->next
* will always be used at this point!
*/
mem->used = 1;
MEM_STATS_INC_USED(used, mem->next - (mem_size_t)((u8_t *)mem - ram));
}
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_malloc_adjust_lfree:
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
if (mem == lfree) { //⑦
struct mem *cur = lfree;
/* Find next free block after mem and update lowest free pointer */
while (cur->used && cur != ram_end) {
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_free_count = 0;
LWIP_MEM_ALLOC_UNPROTECT();
/* prevent high interrupt latency... */
LWIP_MEM_ALLOC_PROTECT();
if (mem_free_count != 0) {
/* If mem_free or mem_trim have run, we have to restart since they
could have altered our current struct mem or lfree. */
goto mem_malloc_adjust_lfree;
}
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
cur = (struct mem *)(void *)&ram[cur->next];
}
lfree = cur;
LWIP_ASSERT("mem_malloc: !lfree->used", ((lfree == ram_end) || (!lfree->used)));
}
LWIP_MEM_ALLOC_UNPROTECT();
sys_mutex_unlock(&mem_mutex);
LWIP_ASSERT("mem_malloc: allocated memory not above ram_end.",
(mem_ptr_t)mem + SIZEOF_STRUCT_MEM + size <= (mem_ptr_t)ram_end);
LWIP_ASSERT("mem_malloc: allocated memory properly aligned.",
((mem_ptr_t)mem + SIZEOF_STRUCT_MEM) % MEM_ALIGNMENT == 0);
LWIP_ASSERT("mem_malloc: sanity check alignment",
(((mem_ptr_t)mem) & (MEM_ALIGNMENT-1)) == 0);
return (u8_t *)mem + SIZEOF_STRUCT_MEM; //⑧
}
}
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
/* if we got interrupted by a mem_free, try again */
} while (local_mem_free_count != 0);
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SERIOUS, ("mem_malloc: could not allocate %"S16_F" bytes\n", (s16_t)size));
MEM_STATS_INC(err);
LWIP_MEM_ALLOC_UNPROTECT();
sys_mutex_unlock(&mem_mutex);
return NULL;
}①首先对输入的size参数进行对齐并且对其大小进行限定,如果小于MIN_SIZE_ALIGNED,则设置为size为MIN_SIZE_ALIGNED(避免过多的小内存块)
②如果需要分配的内存大于MEM_SIZE_ALIGNED(最大可分配的内存),则直接返回NULL
③内存分配之前先上锁,防止多线程访问问题
④从lfree位置开始搜索未使用的内存块
for (ptr = (mem_size_t)((u8_t *)lfree - ram); ptr < MEM_SIZE_ALIGNED - size;
ptr = ((struct mem *)(void *)&ram[ptr])->next) {
}注意这边的ptr是索引号(即数组下标),lfree是指针,ram是内存堆的首地址,lfree - ram获取的是内存堆的空闲块在数组中的索引值;
⑤查找空闲的内存块并且其大小要满足
if ((!mem->used) &&
(mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size) {因为将一个内存块切割一个新的内存块出来,除了需要的内存size外,还要一个struct mem结构体用于管理剩余的块,所以这边判断条件中需要加入SIZEOF_STRUCT_MEM
⑥如果找到的空闲块足够大,分配需要的内存后还比最小内存块(SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED)还要大,就需要进行分割;否则直接将找到的空闲块设置为使用的,并将这边内存空间返回
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >= (size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED)) {
}⑦ptr2为切割后剩余内存块的数组索引号
mem2 = (struct mem *)(void *)&ram[ptr2];通过下标ptr2获取内存地址,mem2就是新分割后的内存块的首地址
mem2->used = 0;
mem2->next = mem->next;
mem2->prev = ptr;
/* and insert it between mem and mem->next */
mem->next = ptr2;
mem->used = 1;将mem2的next的值设置为mem->next;mem2->prev设置为ptr,mem->next设置为ptr2,并标记为使用的。
⑦更新lfree指针
⑧返回分配的内存指针(注意返回的地址需要偏移内存管理块的结构体大小(u8_t *)mem + SIZEOF_STRUCT_MEM;)
为了帮助大家理解这个分割过程,大家可以根据下图进行理解
上图中struct mem A是已经分配的内存,struct mem B是切割后空闲的内存块,lfree指针指向struct mem B,注意每个内存管理块的prev/next的赋值(已经分配的内存和未分配的内存都是统一管理的)
另外我们从上面的分割算法来看,其搜索可用内存块的算法就是遍历,找到足够大的就停止搜索,但未必是最匹配的,所以在切割完后特别容易产生较多的小内存块。
/**
* Put a struct mem back on the heap
*
* @param rmem is the data portion of a struct mem as returned by a previous
* call to mem_malloc()
*/
void
mem_free(void *rmem)
{
struct mem *mem;
LWIP_MEM_FREE_DECL_PROTECT();
if (rmem == NULL) { //①
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_TRACE | LWIP_DBG_LEVEL_SERIOUS, ("mem_free(p == NULL) was called.\n"));
return;
}
LWIP_ASSERT("mem_free: sanity check alignment", (((mem_ptr_t)rmem) & (MEM_ALIGNMENT-1)) == 0);
LWIP_ASSERT("mem_free: legal memory", (u8_t *)rmem >= (u8_t *)ram &&
(u8_t *)rmem < (u8_t *)ram_end);
if ((u8_t *)rmem < (u8_t *)ram || (u8_t *)rmem >= (u8_t *)ram_end) { //②
SYS_ARCH_DECL_PROTECT(lev);
LWIP_DEBUGF(MEM_DEBUG | LWIP_DBG_LEVEL_SEVERE, ("mem_free: illegal memory\n"));
/* protect mem stats from concurrent access */
SYS_ARCH_PROTECT(lev);
MEM_STATS_INC(illegal);
SYS_ARCH_UNPROTECT(lev);
return;
}
/* protect the heap from concurrent access */
LWIP_MEM_FREE_PROTECT();
/* Get the corresponding struct mem ... */
/* cast through void* to get rid of alignment warnings */
mem = (struct mem *)(void *)((u8_t *)rmem - SIZEOF_STRUCT_MEM); //③
/* ... which has to be in a used state ... */
LWIP_ASSERT("mem_free: mem->used", mem->used);
/* ... and is now unused. */
mem->used = 0;
if (mem < lfree) { //④
/* the newly freed struct is now the lowest */
lfree = mem;
}
MEM_STATS_DEC_USED(used, mem->next - (mem_size_t)(((u8_t *)mem - ram)));
/* finally, see if prev or next are free also */
plug_holes(mem); //⑤
#if LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT
mem_free_count = 1;
#endif /* LWIP_ALLOW_MEM_FREE_FROM_OTHER_CONTEXT */
LWIP_MEM_FREE_UNPROTECT();
}①②检查rmem指针的合法性
③根据rmem指针找到管理此内存块的struct mem的地址,并标记此内存块为未使用的
④如果当前未使用的内存块的地址比空闲块的指针还小,则将lfree指向这个新释放的内存块
⑤拼接当前内存块前后的空闲内存块(动态内存堆中容易出现内存碎片,故在释放时需要检查当前块前一个和后一个内存块是否是空闲块,如果是则进行拼接)
/**
* "Plug holes" by combining adjacent empty struct mems.
* After this function is through, there should not exist
* one empty struct mem pointing to another empty struct mem.
*
* @param mem this points to a struct mem which just has been freed
* @internal this function is only called by mem_free() and mem_trim()
*
* This assumes access to the heap is protected by the calling function
* already.
*/
static void
plug_holes(struct mem *mem)
{
struct mem *nmem;
struct mem *pmem;
LWIP_ASSERT("plug_holes: mem >= ram", (u8_t *)mem >= ram); //①
LWIP_ASSERT("plug_holes: mem < ram_end", (u8_t *)mem < (u8_t *)ram_end);
LWIP_ASSERT("plug_holes: mem->used == 0", mem->used == 0);
/* plug hole forward */
LWIP_ASSERT("plug_holes: mem->next <= MEM_SIZE_ALIGNED", mem->next <= MEM_SIZE_ALIGNED);
nmem = (struct mem *)(void *)&ram[mem->next]; //②-1
if (mem != nmem && nmem->used == 0 && (u8_t *)nmem != (u8_t *)ram_end) {
/* if mem->next is unused and not end of ram, combine mem and mem->next */
if (lfree == nmem) { //②-2
lfree = mem;
}
mem->next = nmem->next;
((struct mem *)(void *)&ram[nmem->next])->prev = (mem_size_t)((u8_t *)mem - ram);
}
/* plug hole backward */
pmem = (struct mem *)(void *)&ram[mem->prev]; //③-1
if (pmem != mem && pmem->used == 0) { //③-2
/* if mem->prev is unused, combine mem and mem->prev */
if (lfree == mem) { //③-3
lfree = pmem;
}
pmem->next = mem->next; //③-4
((struct mem *)(void *)&ram[mem->next])->prev = (mem_size_t)((u8_t *)pmem - ram);
}
}①检查mem地址的合法性
②-1检查当前块的后一个块是否是空闲块
②-2如果当前块的后一个块是空闲块则将当前的next设置为下一个块的next,下一个块的prev设置为当前块的索引值;如果lfree指向当前块的下一个块,则lfree需要指向当前块
③-1检查当前块的上一个块
③-2如果当前块的上一个块未使用,则进行拼接
③-3如果lfree指向当前块,则lfree需要指向当前块的上一个块
③-4设置上一个块的next的值为当前块的next,当前块的下一个块的prev设置为当前块的上一个块的下标值
至此,我们基本上对LwIP的内存堆实现算法进行了分析,总体上看还是比较简单的。
其每个内存块统一管理,在寻找一个新的空闲块时,需要遍历整个内存堆中的所有块,但为了尽量加快搜索速度,专门有个lfree指针定位当前空闲块中地址最低的一个块。
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生