一、Auto-GPT简介
最近,以ChatGPT为代表的超大规模语言模型火出了圈,各种二次开发项目也是层出不穷。
这周在AI圈炸街的是Auto-ChatGPT,在GitHub上已经61.4K的点赞了。
项目地址:https://github.com/Torantulino/Auto-GPT
用项目的原话介绍:“Auto-GPT是一个实验性的开源应用程序,展示了GPT-4语言模型的能力。这个程序由GPT-4驱动,自主地开发和管理企业,以增加净值。作为GPT-4完全自主运行的第一个示例之一,Auto-GPT推动了AI的可能性边界。”
小Chat是我们的得力助手,但在使用它完成任务的时候,我们需要使用“咒语”来唤醒它的神奇力量。如果你输入的“咒语”不够合适,小Chat就会抗拒你,然后你只能继续寻找合适的“咒语”,直到小Chat心情好为止。但如果你成功施展了合适的“咒语”,小Chat就会跟你打成一片,愉快地回答你的问题。接下来,你只需要不断使用“咒语”向它提问,直到你完成了任务。这个过程,叫做“人在回路”,熟悉不,这个概念就是在《流浪地球2》的彩蛋中,MOSS跟图恒宇说的:“基于对丫丫意识进行人在回路的学习,balabala”。
那么,作为一个成熟的通用人工智能(Artificial General Intelligence,AGI),TA应该学会自己做迭代思考,从而达到最终地目的。比如说,导师问你:“Mp1p蛋白有什么作用?”,作为一个成熟地科研狗,你大概率就会去百度、谷歌、Pubmed找相关文献资料,然后自己出个一二三条。
而这就是Auto-GPT项目想要做的:让人工智能能够像人类一样,通过自我迭代思考来完成任务。因此它具有如下特性:
(1)接入互联网:得会上网,能够通过搜索和信息收集获取各种知识。
(2)长短期内存管理:得有好的记忆力,能够对重要的信息进行长期存储,同时也能快速访问短期内存,方便及时处理任务。
(3)GPT-4文本生成:还需要有文笔,能够使用GPT-4生成高质量的文本,如文章、邮件等。
(4)访问流行网站和平台:要像人类一样,了解最新的时事和热门话题,就必须知道访问哪些流行的网站和平台。
(5)GPT-3.5文件管理:最后,还得会整理文件,像GPT-3.5一样,能够高效地进行文件存储和管理。
二、Auto-GPT部署
先说明部署的必备条件:
以上,缺一不可。
可选项目:
第一步 下载项目
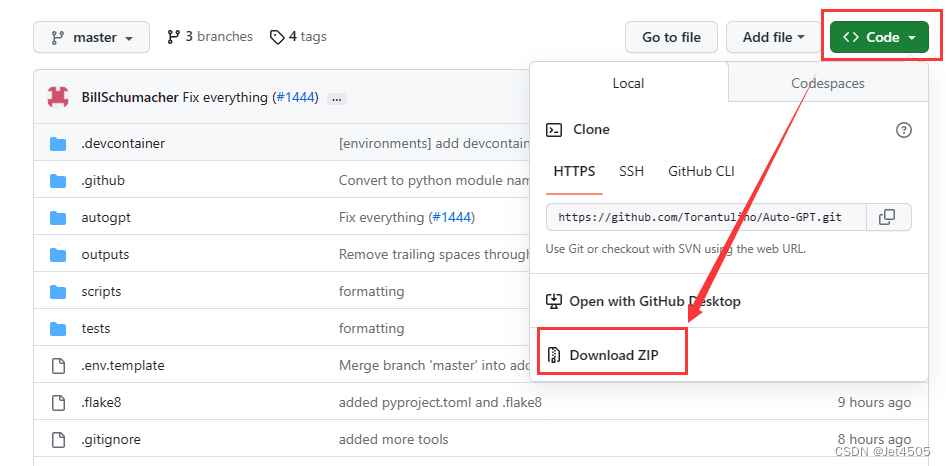
(a)这个简单,直接去项目的网址进行下载即可: “Code”——“Download ZIP”;
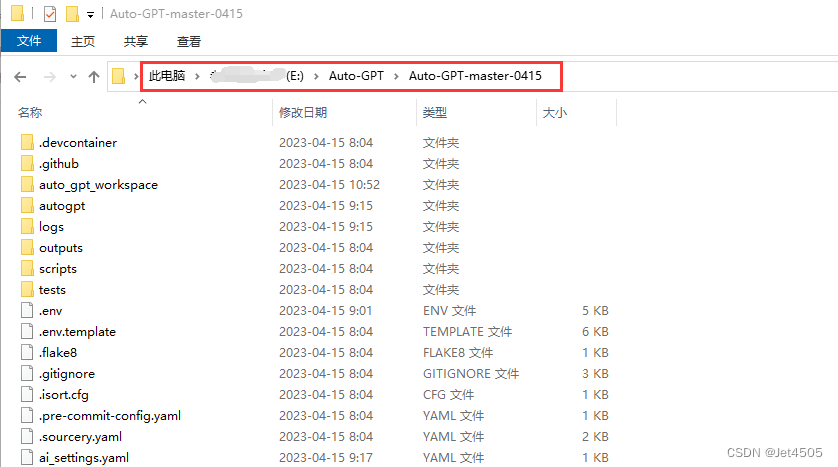
(b)解压到一个路径,最好是全英文的路径,比如我的是:E:\Auto-GPT\Auto-GPT-master-0415;
第二步 安装python依赖库
(a)项目需要的依赖库,都在这个名为“requirements.txt”的文件夹里了,打开看,共是26个;

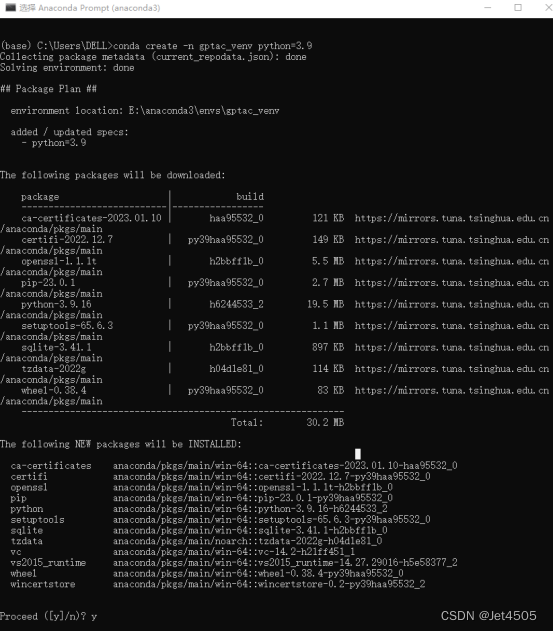
(b)记得先安装Anaconda,打开Anaconda Prompt (anaconda),输入代码:
conda create -n gptac_venv python=3.9 #生成一个名为gptac_venv的环境,我的python版本是3.9注释:这里用旧图了,跟之前一样的步骤
这里选y;

这样就是安装成功了。
(c)进入新建立的环境,输入代码:
conda activate gptac_venv注释:这里用旧图了,跟之前一样的步骤

可以看到,前面括号的base变成了gptac_venv,也就是从基础环境(base)切换到了我们刚新建的新环境(gptac_venv),接下来就在这个新环境里面安装依赖库。
(d)安装依赖库,首先把路径切换到之前存项目的路径:E:\Auto-GPT\Auto-GPT-master-0415,操作就是:
输入“e:”——回车,进入到E盘——输入“cd E:\Auto-GPT\Auto-GPT-master-0415”——回车,搞定;注意:我装autogpt环境是jet_gpt哈,上面之所以是gptac_venv,是因为懒,用的旧图。

接着输入代码:
python -m pip install -r requirements.txt
回车开始安装。
需要安装的东西很多,个人经验:跟网速有关,我是开魔法的。
安装成功的话,全程白字没有报错。要是有红字报错,各位八仙过海各显神通吧。
第三步 配置OPENAI_API_KEY
(a)确保网络通畅(最重要);
(b)OpenAI API Key 生成,进入网址,登陆账号:
https://platform.openai.com/account/api-keys![]() https://platform.openai.com/account/api-keys
https://platform.openai.com/account/api-keys
点击“Create new secret key”——弹出窗口——复制出你的Key。
(c)找到项目文件中的.env.template文件,改名为.env文件,并用记事本打开项目文件的,填入你的API KEY:
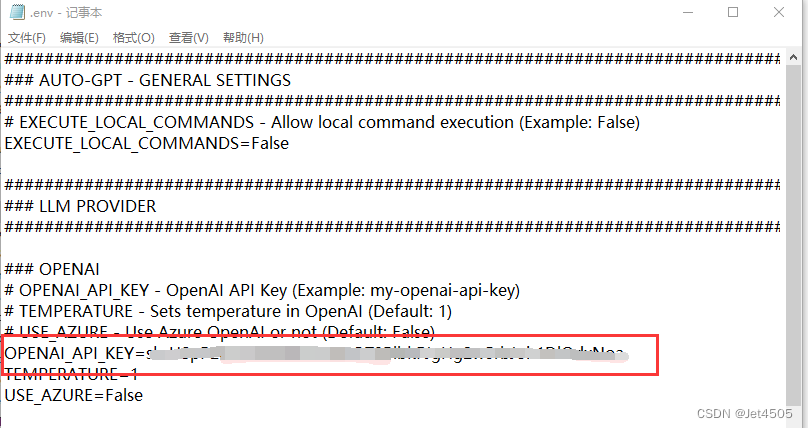
注意:这里的API不需要双引号:“”。
第四步 配置PINECONE_API_KEY
(a)确保网络通畅(最重要);
(b)Pinecone API Key 生成,进入网址,注册,登陆账号:
点击“API key”——弹出窗口;
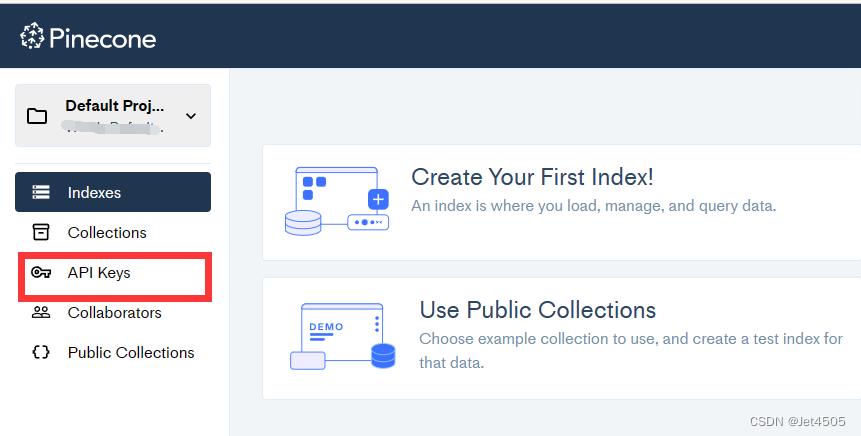
复制出你的PINECONE_API_KEY(Vaule)和PINECONE_ENV(Environment);
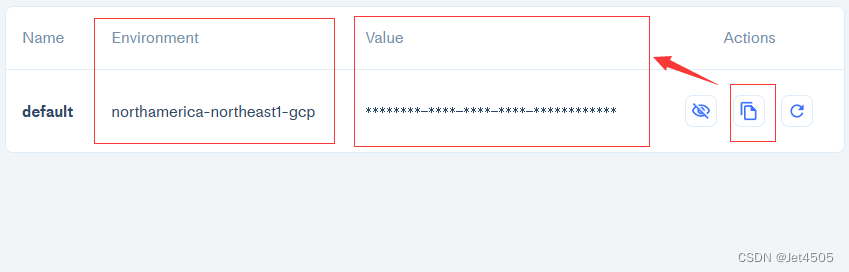
分别填入.env文件:
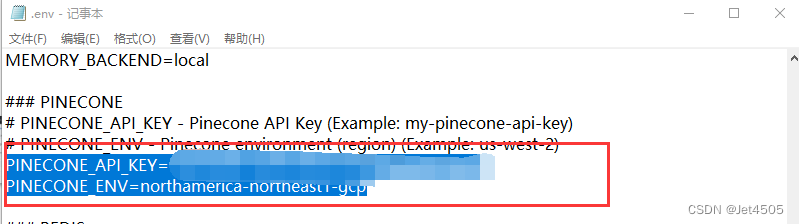
第四步 配置GOOGLE搜索引擎
这里主要需要填入2个东西:GOOGLE_API_KEY以及CUSTOM_SEARCH_ENGINE_ID。
(a)确保网络通畅(最重要);
(b)Googel API Key 生成,进入网址,注册,登陆账号:
(c)创造一个无组织的最新项目:
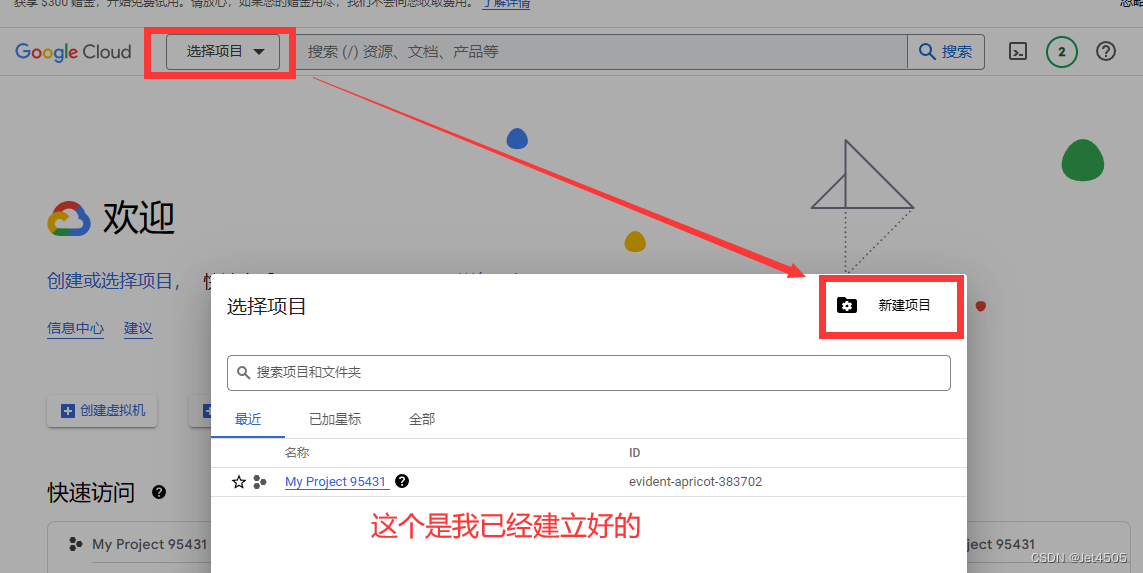
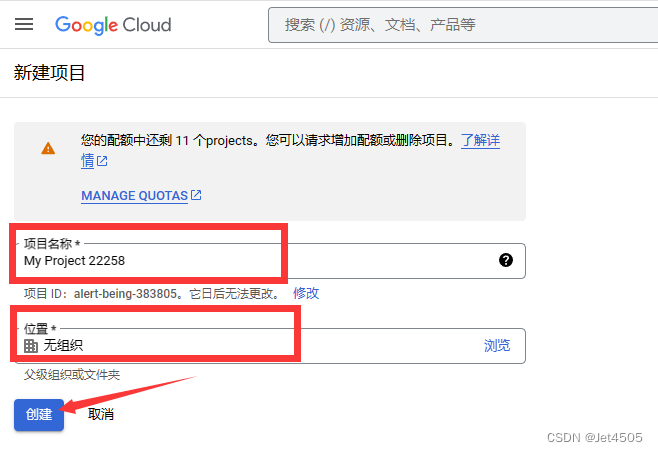
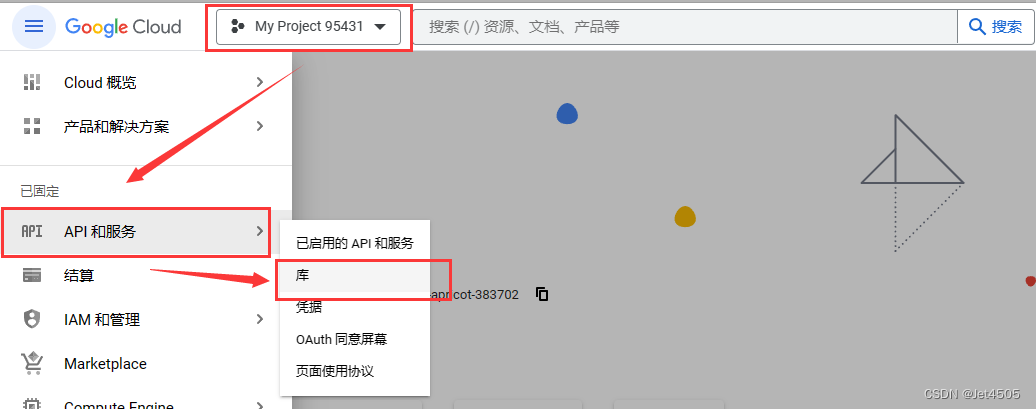
(d)输入 custom search api,之后选 管理 > 凭据 > 创建凭据 > API密钥
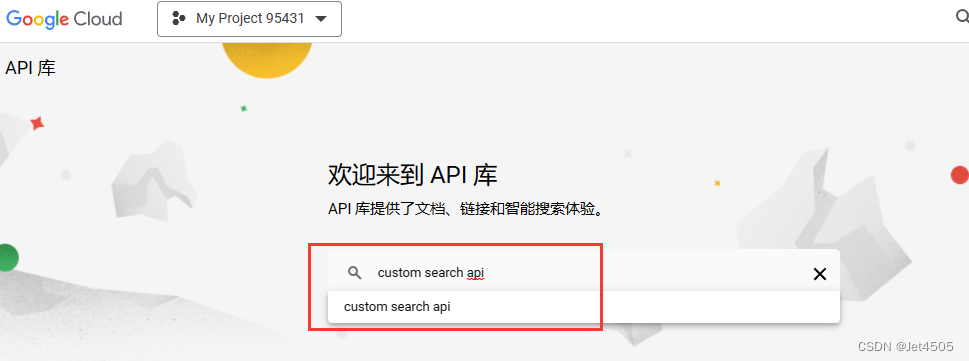
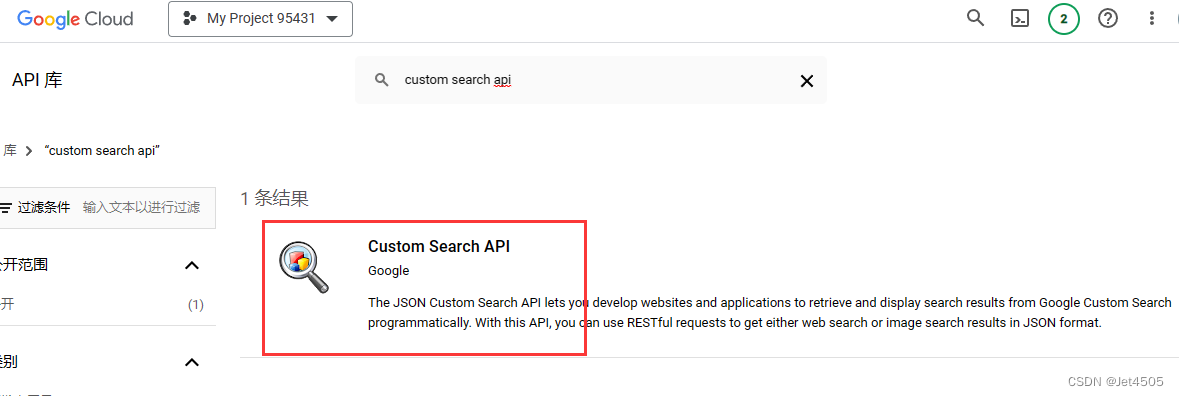
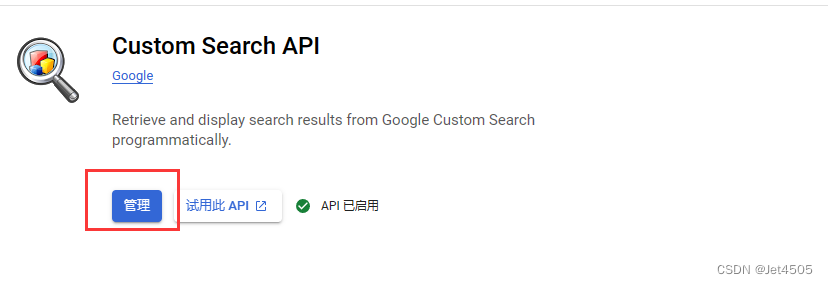

(e)这个就是GOOGLE_API_KEY;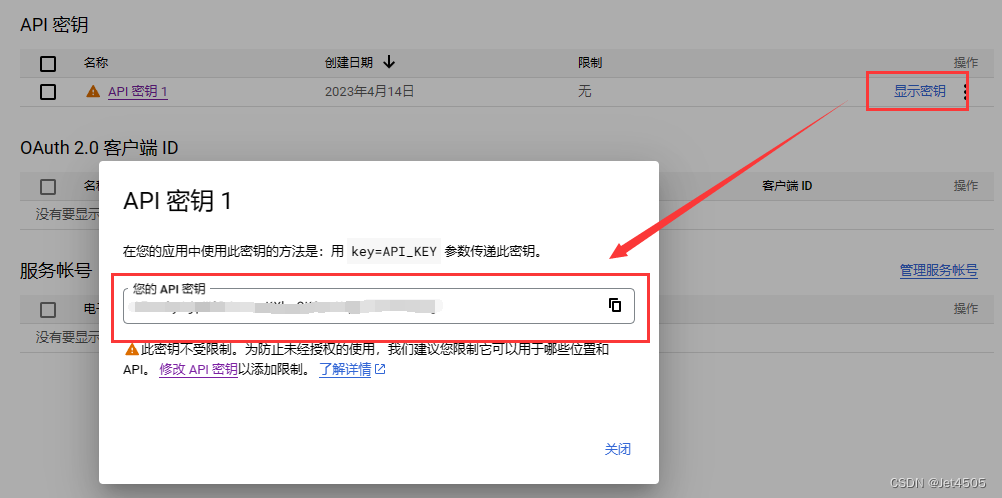 然后来看USTOM_SEARCH_ENGINE_ID 的ID:
然后来看USTOM_SEARCH_ENGINE_ID 的ID:
(a)确保网络通畅(最重要);
(b)CUSTOM_SEARCH_ENGINE_ID 生成,进入网址:
https://programmablesearchengine.google.com/about/![]() https://programmablesearchengine.google.com/about/
https://programmablesearchengine.google.com/about/
(c)CUSTOM_SEARCH_ENGINE_ID 生成,进入网址:

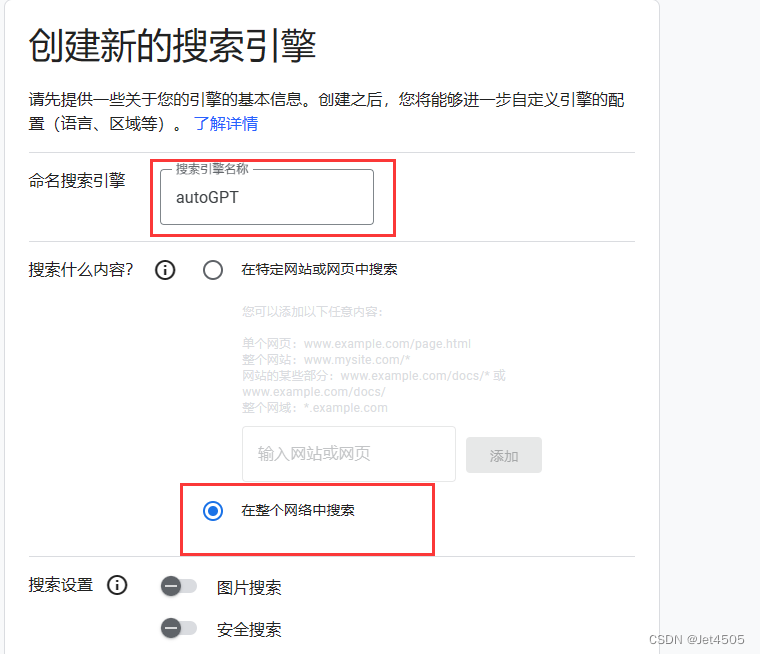
(d)复制好CUSTOM_SEARCH_ENGINE_ID。

最后,打开.env文件,输入GOOGLE_API_KEY以及CUSTOM_SEARCH_ENGINE_ID:
第五步 运行程序
还是打开刚才的Anaconda Prompt (anaconda),切换到新建的环境,以及项目路径: 输入代码:
输入代码:
python -m autogpt --gpt3only
回车!
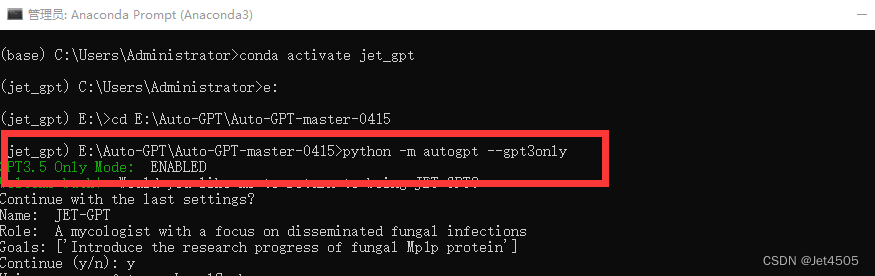
出现了绿色字welcome back 就是成功了!
简单用法:给AI取名字 > 设置任务 > 设置任务目标(最多5个)> 程序运行 > 每一步用y、n等指令指挥AutoGPT。
三、Auto-GPT测评
(1)设置目标
Name: JET-GPT
Role: A mycologist with a focus on disseminated fungal infections
Goals: Introduce the research progress of fungal Mp1p protein
简单来说就是帮我简单介绍真菌Mp1p蛋白的研究进展。由于我之前运行过了,这里它自动调取上次的程序,输入y继续运行即可:
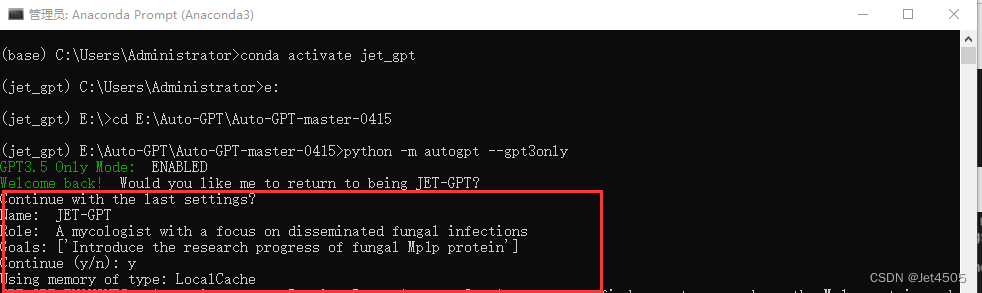
(2)程序思考过程:

用谷歌翻译展示一下:

TA会自己进行任务拆分,首先,去谷歌搜索!!
我们输入y,让TA进行下一步:

TA去找文献了,还进行了分析:
 读出了一些信息:
读出了一些信息:

然后TA自己分析了这个方法不太好:“由于我的短期记忆力有限,因此启动受过文本摘要训练的 GPT 代理将减轻我的工作量并节省我的时间”,然后如何解决:“我应该启动一个 GPT 代理来帮助我生成我从网站上收集的有关 Mp1p 蛋白的信息摘要。 为此,我可以使用“start_agent”命令。”

再运行一次后,给出了一些总结:

好像不太对,给它继续自我反思试一试:TA好像想到了我是想看真菌的Mp1p:

接着他继续上网找文献,然后发现读取不了文献的信息:“此模型的最大上下文长度为 4097 个标记”,没办法GPT3.5的限制。然后只能从TA已知的知识中提取信息,有可能是现编的。
到此为止,我就让TA停下来了。
总结:虽然结果不太理想,但是过程确实让人眼前一亮,毕竟处于初级阶段,而且我只能调用GPT3.5,未来提升的空间还是很大的。
四、几点注意事项
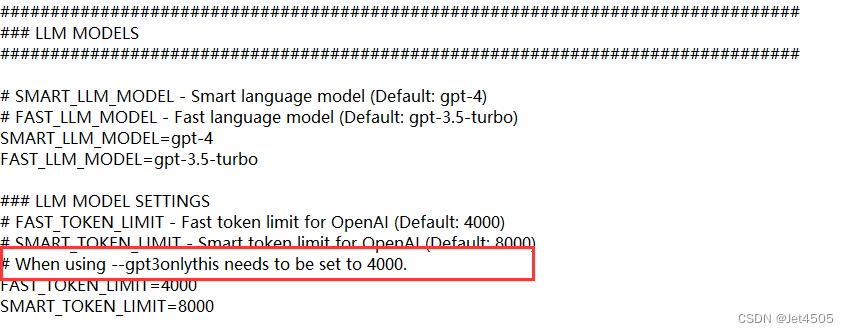
(1)关于不能联网
据说,需要在.env文件中,把这个8000改成4000。江湖传闻,供参考。
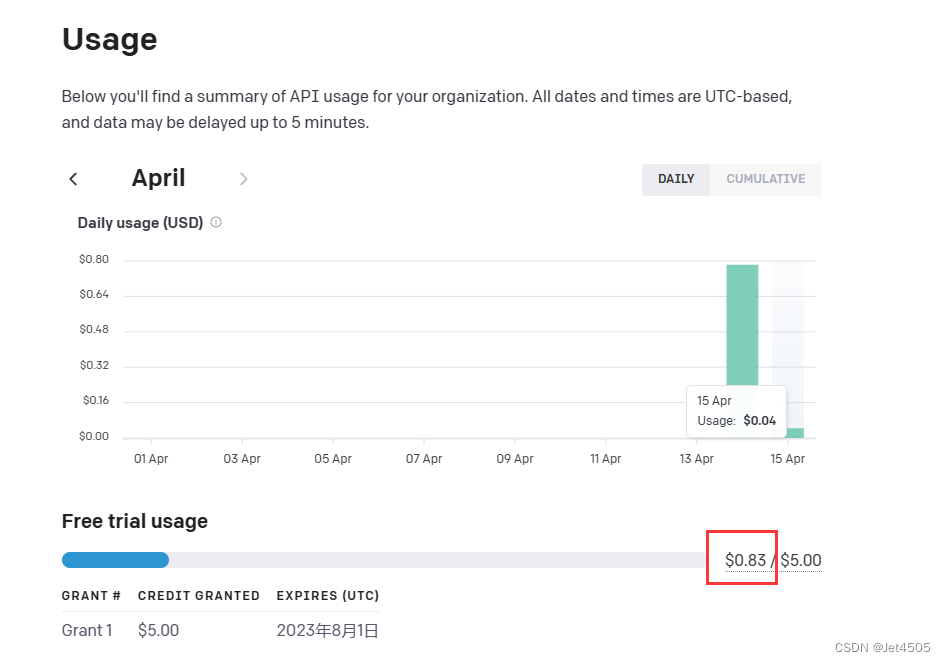
(2)关于API Key的费用
据说,调用OpenAI Key是收费的,新注册账号,至少赠送5美元,用完就无了。
我跑了这一次花费如下,一共是0.13美元,差不多1块钱,成本还是很高的。
所以大家玩归玩,注意这是一个烧钱的过程哈!
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
有谁知道在Heroku的Bamboo堆栈上启动并运行使用DataMapper的Sinatra应用程序所需的魔法咒语?Bamboo堆栈不包含任何预安装的系统gem,无论我尝试使用何种gem组合,我都会不断收到此错误:undefinedmethod`auto_upgrade!'forDataMapper:Module(NoMethodError)这是我的.gems文件中的内容:sinatrapgdatamapperdo_postgresdm-postgres-adapter这些是我将应用程序推送到Heroku时安装的依赖项:----->Herokureceivingpush----->Si
我正在尝试创建一个带有项目符号字符的Ruby1.9.3字符串。str="•"+"helloworld"但是,当我输入它时,我收到有关非ASCII字符的语法错误。我该怎么做? 最佳答案 你可以把Unicode字符放在那里。str="\u2022"+"helloworld" 关于ruby-如何在Ruby字符串中插入项目符号字符?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1195
我的Rails站点使用了一个确实不是很好的gem。每次我需要做一些新的事情时,我最终不得不花费与向实际Rails项目添加代码一样多的时间来为gem添加功能。但我不介意,我将我的Gemfile设置为指向我的gem的GitHub分支(我尝试提交PR,但维护者似乎已经下台)。问题是我真的没有找到一种合理的方法来测试我添加到gem的新东西。在railsc中测试它会特别好,但我能想到的唯一方法是a)更改~/.rvm/gems/.../foo。rb,这看起来不对或者b)升级版本,推送到Github,然后运行bundleup,这除了耗时之外显然是一场灾难,因为我不确定我所做的promise是否正
我一直在尝试使用nanoc用于生成静态网站。我需要组织一个复杂的排列页面,我想让我的内容保持干燥。包含或合并的概念在nanoc系统中如何运作?我已阅读文档,但似乎找不到我想要的内容。例如:我如何获取两个部分内容项并将它们合并到一个新的内容项中。在staticmatic您可以在您的页面中执行以下操作。=partial('partials/shared/navigation')类似的约定在nanoc中如何运作? 最佳答案 这里是nanoc的作者。在nanoc中,部分是布局。因此,您可以拥有layouts/partials/shared/
我安装了ruby、yeoman,当我运行我的项目时,出现了这个错误:Warning:Running"compass:dist"(compass)taskWarning:YouneedtohaveRubyandCompassinstalledthistasktowork.Moreinfo:https://github.com/gruUse--forcetocontinue.Use--forcetocontinue.我有进入可变session目标的路径,但它不起作用。谁能帮帮我? 最佳答案 我必须运行这个:geminstallcom