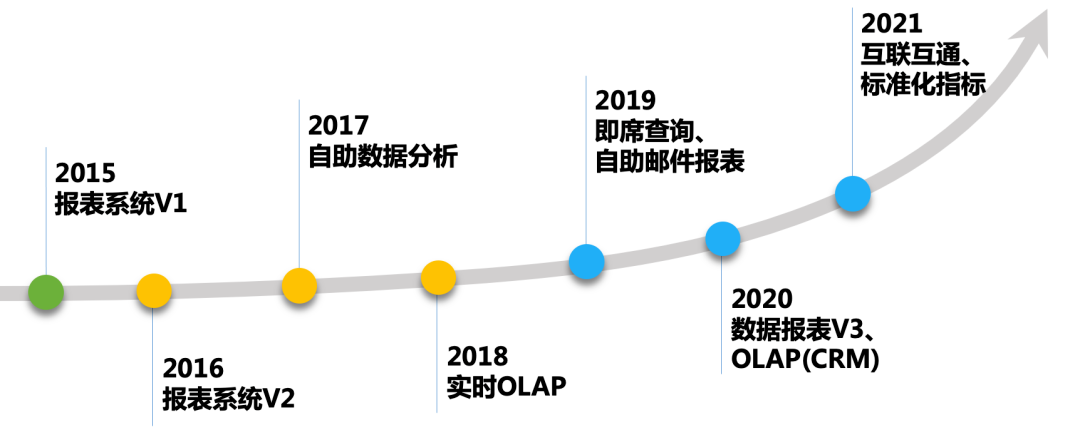
 BI 平台建设时间线如上图,根据实际业务需要上线相应模块,总体大致分为三个阶段:
BI 平台建设时间线如上图,根据实际业务需要上线相应模块,总体大致分为三个阶段: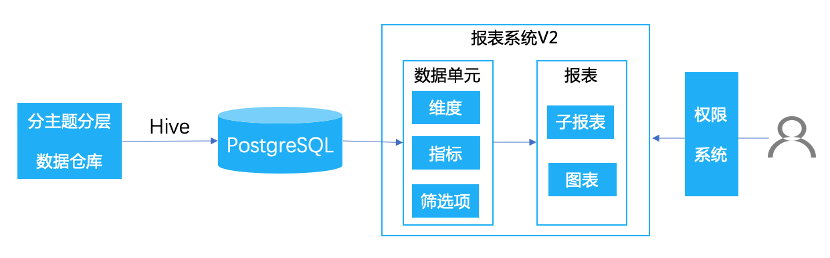
 ②整体架构结合实际痛点分析出有以下必要的诉求点:
②整体架构结合实际痛点分析出有以下必要的诉求点: Apache Kudu 是介于 Hadoop 和 Hbase 之间的,既能满足高吞吐量的数据分析需求又能满足快速的数据随机读写需求。基于 Impala 和 Kudu 的系统架构图如下:
Apache Kudu 是介于 Hadoop 和 Hbase 之间的,既能满足高吞吐量的数据分析需求又能满足快速的数据随机读写需求。基于 Impala 和 Kudu 的系统架构图如下: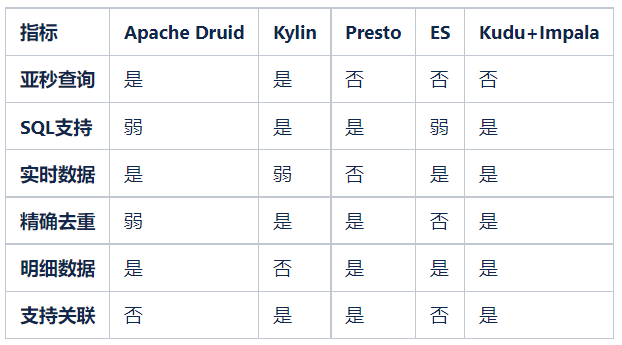
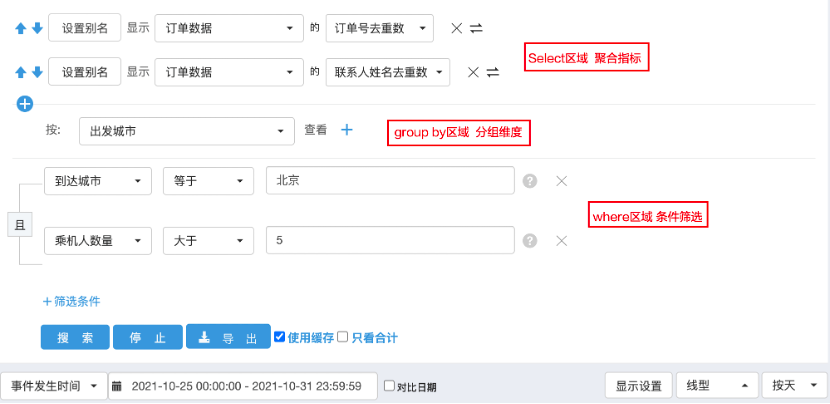
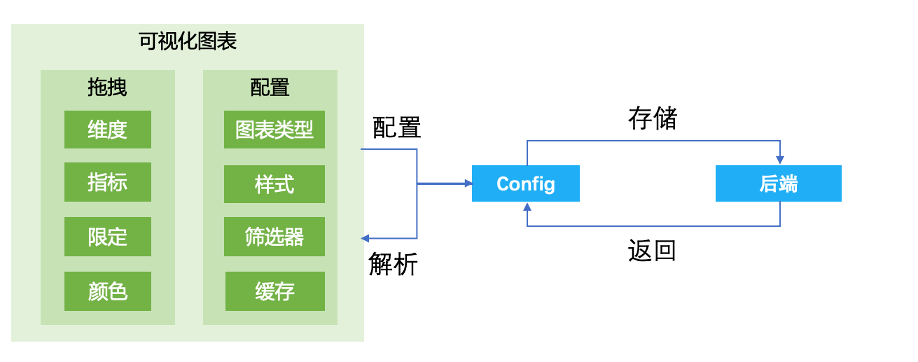 针对可视化图表,由前端实现拖拽效果,用户在前端的所有拖拽和配置信息构建成一个 Json 形式的 Config 中,传到后端存储;打开可视化图表时前端获取 Json 形式的 Config ,解析后渲染展示。
针对可视化图表,由前端实现拖拽效果,用户在前端的所有拖拽和配置信息构建成一个 Json 形式的 Config 中,传到后端存储;打开可视化图表时前端获取 Json 形式的 Config ,解析后渲染展示。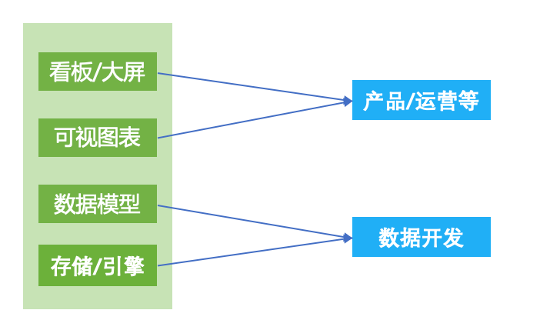 自由拖拽实际上是降低了图表配置门槛,提升了配置效率。原报表系统 V2 配置步骤繁杂,大部分还是由数据开发同学配置的,开发工期长。为提升整体效率,首先将此模块抽象成四部分,存储/引擎、数据模型、可视化图表、看板/大屏,上一节已详细介绍过。其次明确分工,数据开发同学主要做的事情是,根据需求场景将数据引入到合适的存储/引擎中,根据需求内容抽象合理的数据模型,剩下的配置可视化图表和看板皆由产品、运营等自助拖拽完成。③业务自主管理
自由拖拽实际上是降低了图表配置门槛,提升了配置效率。原报表系统 V2 配置步骤繁杂,大部分还是由数据开发同学配置的,开发工期长。为提升整体效率,首先将此模块抽象成四部分,存储/引擎、数据模型、可视化图表、看板/大屏,上一节已详细介绍过。其次明确分工,数据开发同学主要做的事情是,根据需求场景将数据引入到合适的存储/引擎中,根据需求内容抽象合理的数据模型,剩下的配置可视化图表和看板皆由产品、运营等自助拖拽完成。③业务自主管理 各业务整合后面对的用户涉及全司全业务,各业务对报表在组织和权限管理方面差异很大,希望能够独立自主管理,因此我们加入了 BU 的概念,按 BU 从逻辑上完全隔离开,包括导入后的存储和引擎、数据模型、可视化图表、数据看板,以及在权限系统中所有相关的资源。④亮点功能作为数据报表系统,除了常规的功能例如看板/大屏、上卷下钻、同环比等之外,还重点支持了以下几个重要的功能点。
各业务整合后面对的用户涉及全司全业务,各业务对报表在组织和权限管理方面差异很大,希望能够独立自主管理,因此我们加入了 BU 的概念,按 BU 从逻辑上完全隔离开,包括导入后的存储和引擎、数据模型、可视化图表、数据看板,以及在权限系统中所有相关的资源。④亮点功能作为数据报表系统,除了常规的功能例如看板/大屏、上卷下钻、同环比等之外,还重点支持了以下几个重要的功能点。
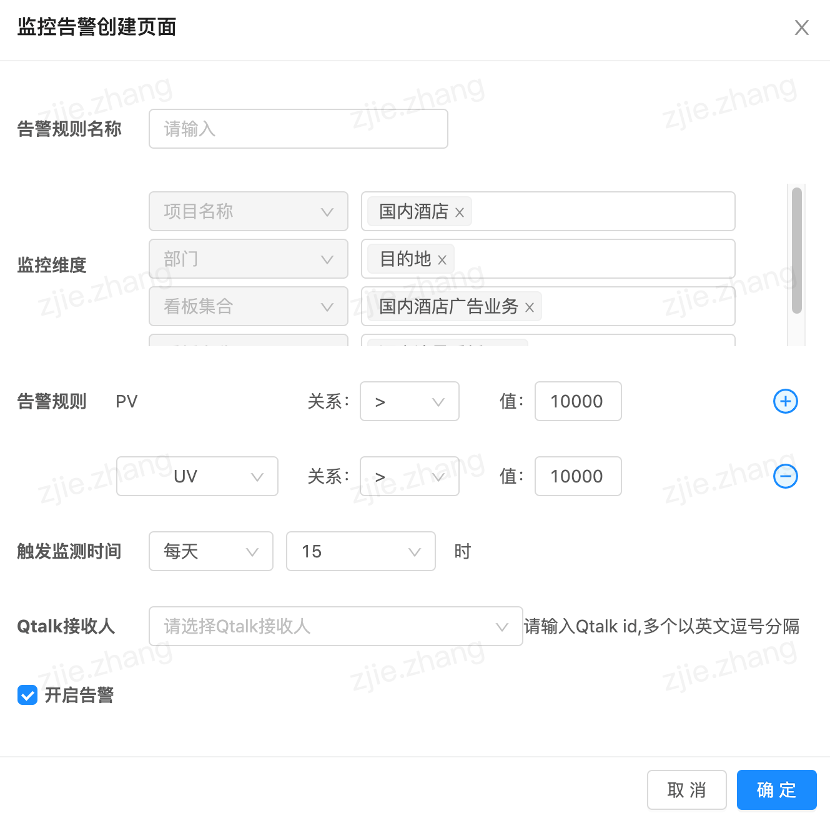
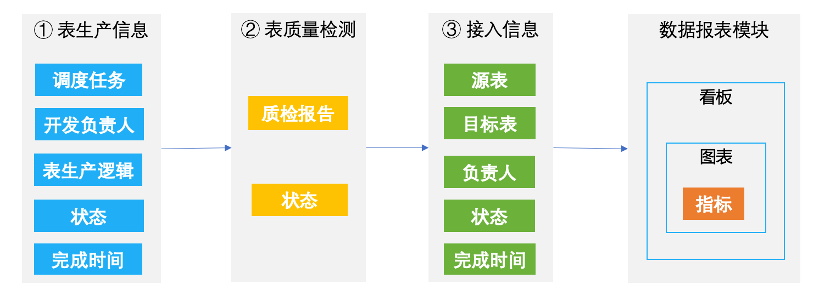
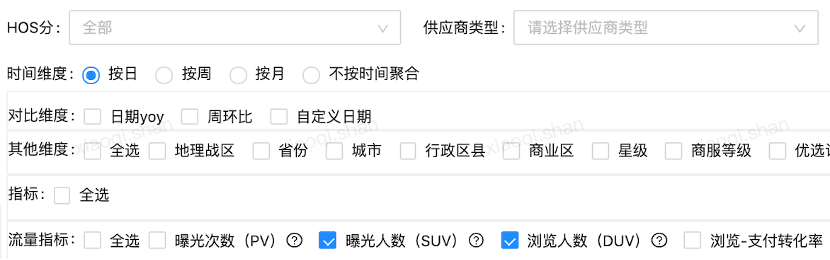 具体形式如上所示(截取了部分),针对酒店用户任意勾选二十多个维度、近百个指标,要求 3 秒内出结果展示图表。通过对需求的详细分析归纳,得出以下技术挑战点:
具体形式如上所示(截取了部分),针对酒店用户任意勾选二十多个维度、近百个指标,要求 3 秒内出结果展示图表。通过对需求的详细分析归纳,得出以下技术挑战点: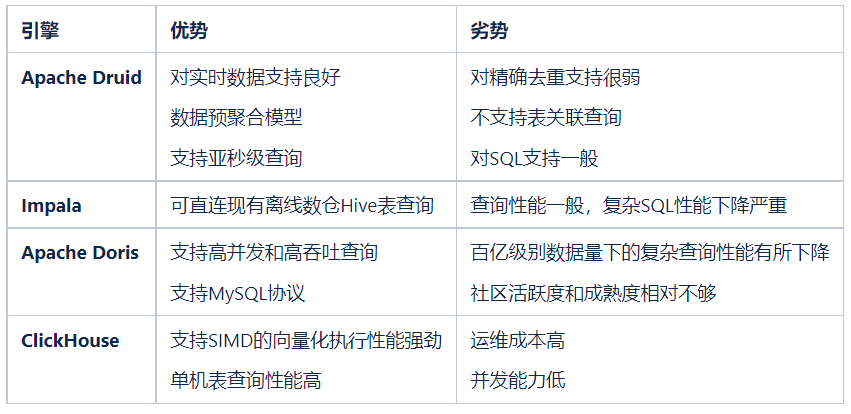 引擎选型调研 ES、Presto、Kylin 在前面对比过结论是不适用当前场景,本次选型主要对比了在用的 Apache Druid、Impala 和新增的 Apache Doris、ClickHouse。
引擎选型调研 ES、Presto、Kylin 在前面对比过结论是不适用当前场景,本次选型主要对比了在用的 Apache Druid、Impala 和新增的 Apache Doris、ClickHouse。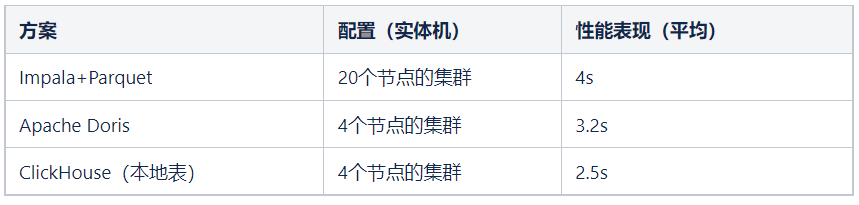 通过直观的性能对比结果,ClickHouse 的查询性能表现很好,另外实际测试发现随着查询指标数量的增多对 ClickHouse 的性能影响也并不是很大,再结合我们的实际场景需求(主宽表查询,带小表 Join )、硬件条件、开发成本以及业界经验综合对比,ClickHouse 成为了不错的选择。③架构设计
通过直观的性能对比结果,ClickHouse 的查询性能表现很好,另外实际测试发现随着查询指标数量的增多对 ClickHouse 的性能影响也并不是很大,再结合我们的实际场景需求(主宽表查询,带小表 Join )、硬件条件、开发成本以及业界经验综合对比,ClickHouse 成为了不错的选择。③架构设计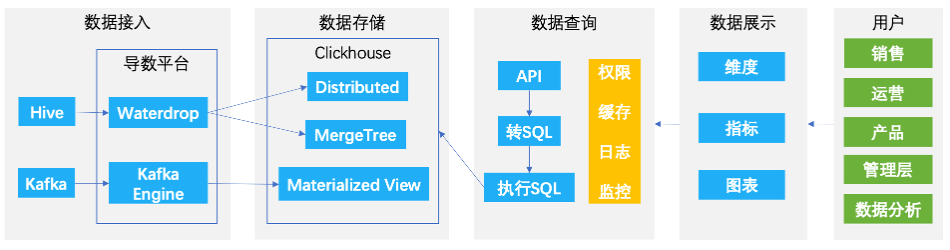
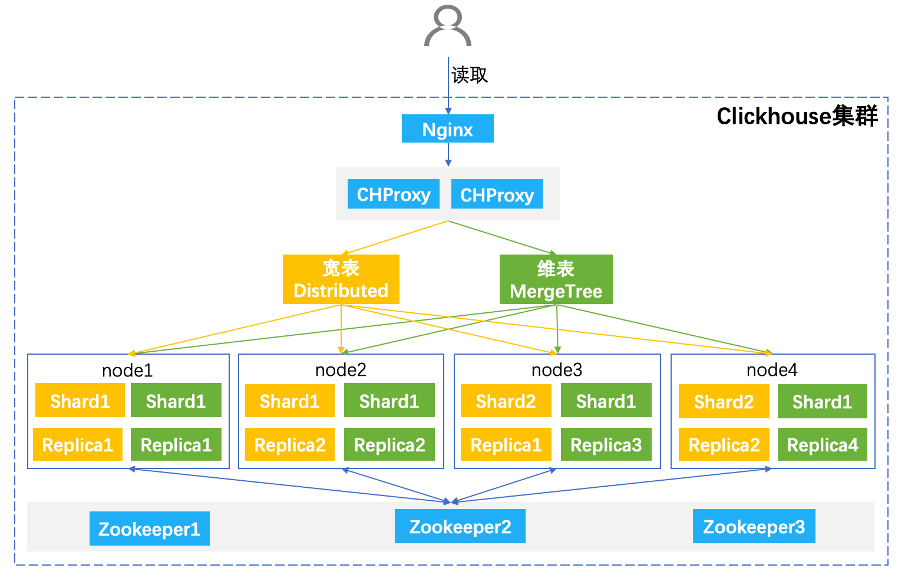 整个集群部署如上图,访问入口由 Nginx 做负载均衡, CHProxy 代理用于管理集群用户、限制并发、设置请求超时等,而集群的大部分分布式功能,则需要通过 ZooKeeper 来完成。结合 CRM 项目本身诉求以及性能要求设计了两种表,整体原则是充分利用 ClickHouse 的单机计算性能强的优势。第一种分布式表,通常用来存储指标数据和关联用的维度字段(如日期及酒店维度字段加到订单流量数据),这种表通常数据量很大( TB 甚至 PB 级别),需要用多台机器分散存储。分布式表需要设置 Sharding Key 来决定,由于涉及到查询优化,Sharding Key 最好是对应场景中出现频率最高的查询维度(比如日期),这样能够保证 Group By 的时候同一组维度数据一定在同一台物理机上,然后通过修改配置 distributed_group_by_no_merge=1 将所有的聚合转成本地操作,避免了额外的网络开销,提升查询性能。第二种单机表,通常用来存储非静态的维表,这类维表包含随时间更新的维度(比如酒店星级,HOS 分等),需要在查询的时候取维表数据和主表进行 Join 操作。通过设置一表多备的方式,我们让每一台机器都持有全量且一致的维表数据,这样在Join的时候就可以将 Shuffle Join 优化成 Local Join (因为每一个 Join Key 对应的右表全量数据一定都在本地)来提升查询的整体性能。
整个集群部署如上图,访问入口由 Nginx 做负载均衡, CHProxy 代理用于管理集群用户、限制并发、设置请求超时等,而集群的大部分分布式功能,则需要通过 ZooKeeper 来完成。结合 CRM 项目本身诉求以及性能要求设计了两种表,整体原则是充分利用 ClickHouse 的单机计算性能强的优势。第一种分布式表,通常用来存储指标数据和关联用的维度字段(如日期及酒店维度字段加到订单流量数据),这种表通常数据量很大( TB 甚至 PB 级别),需要用多台机器分散存储。分布式表需要设置 Sharding Key 来决定,由于涉及到查询优化,Sharding Key 最好是对应场景中出现频率最高的查询维度(比如日期),这样能够保证 Group By 的时候同一组维度数据一定在同一台物理机上,然后通过修改配置 distributed_group_by_no_merge=1 将所有的聚合转成本地操作,避免了额外的网络开销,提升查询性能。第二种单机表,通常用来存储非静态的维表,这类维表包含随时间更新的维度(比如酒店星级,HOS 分等),需要在查询的时候取维表数据和主表进行 Join 操作。通过设置一表多备的方式,我们让每一台机器都持有全量且一致的维表数据,这样在Join的时候就可以将 Shuffle Join 优化成 Local Join (因为每一个 Join Key 对应的右表全量数据一定都在本地)来提升查询的整体性能。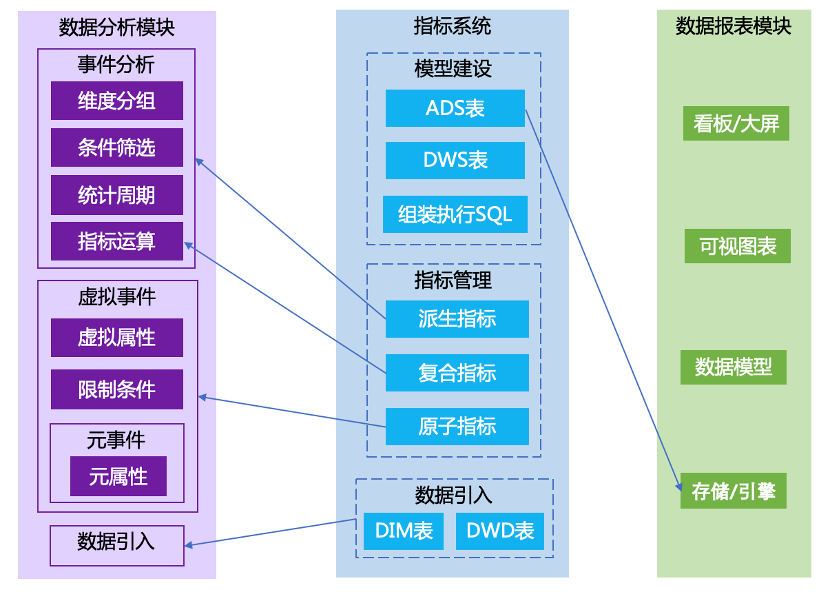 ①数据分析场景数据分析模块引入指标系统管理的 DIM 表、DWD 表明细数据,获取指标系统构建的原子指标、复合指标、派生指标信息,用户在进行事件分析时可自由选择来自指标系统的标准化指标,实际查询相应底层的明细表进行分析,使用效果如下图所示。
①数据分析场景数据分析模块引入指标系统管理的 DIM 表、DWD 表明细数据,获取指标系统构建的原子指标、复合指标、派生指标信息,用户在进行事件分析时可自由选择来自指标系统的标准化指标,实际查询相应底层的明细表进行分析,使用效果如下图所示。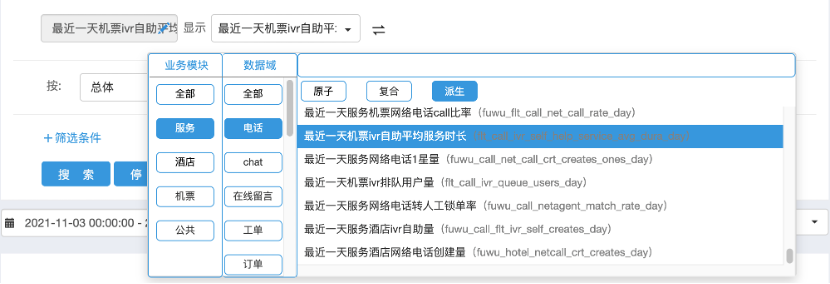 ②数据报表场景指标系统产出的标准化ADS表,通过导数平台导入数据报表模块,然后根据指标系统里定义的维度指标自动生成数据模型,基于此可实现自由拖拽可视化报表配置看板,相反在看板的图表里可以查看底表和指标的来源信息,使用效果如下图所示。
②数据报表场景指标系统产出的标准化ADS表,通过导数平台导入数据报表模块,然后根据指标系统里定义的维度指标自动生成数据模型,基于此可实现自由拖拽可视化报表配置看板,相反在看板的图表里可以查看底表和指标的来源信息,使用效果如下图所示。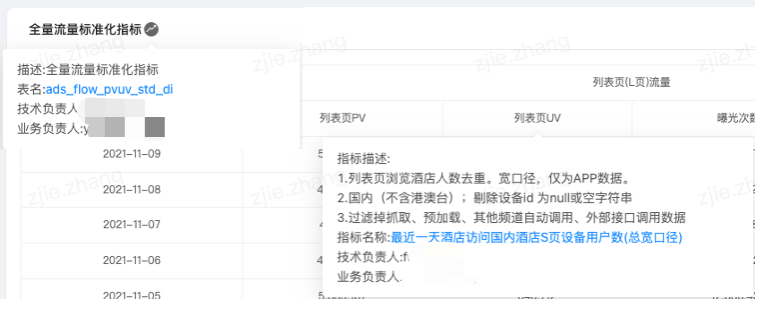
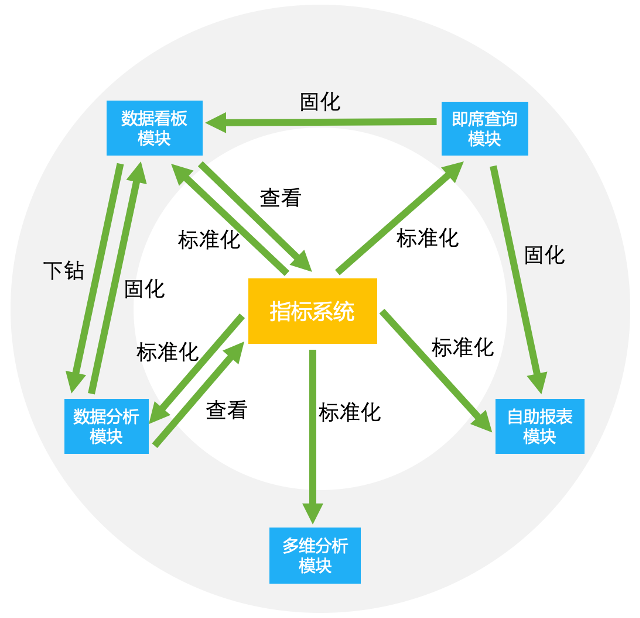
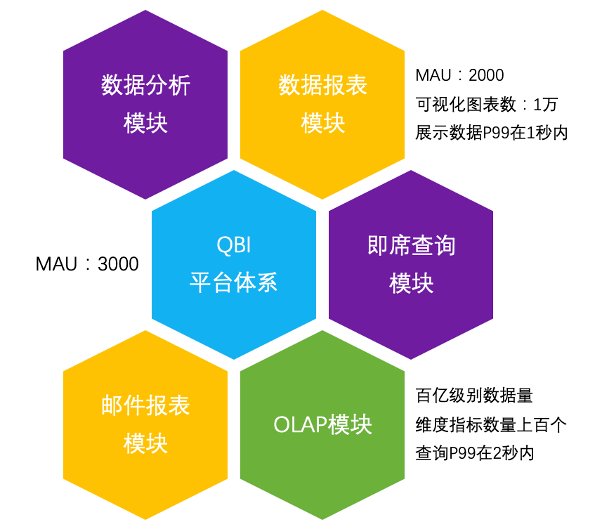 QBI 目前服务于 Qunar 全司十几条业务线,整体 MAU 三千,现已形成较为完善的产品矩阵,包括以下场景:
QBI 目前服务于 Qunar 全司十几条业务线,整体 MAU 三千,现已形成较为完善的产品矩阵,包括以下场景:这是针对我无法破坏的现有公共(public)API,但我确实希望对其进行扩展。目前,该方法采用字符串或符号或任何其他在作为第一个参数传递给send时有意义的内容我想添加发送字符串、符号等列表的功能。我可以只使用is_a吗?数组,但还有其他发送列表的方法,这不是很像ruby。我将调用列表中的map,所以第一个倾向是使用respond_to?:map。但是字符串也会响应:map,所以这行不通。 最佳答案 如何将它们全部视为数组?String的行为与仅包含String的Array相同:deffoo(obj,arg)[*arg].eac
我想先按字符串对数组进行排序,然后再按数字对数组进行排序。我该怎么做? 最佳答案 解决棘手排序的一般技巧是使用#sort_by,该block返回具有主要和次要排序顺序的数组(如果需要,还可以返回第三等)a=['foo','bar','1','2','10']b=a.sort_bydo|s|ifs=~/^\d+$/[2,$&.to_i]else[1,s]endendpb#=>["bar","foo","1","2","10"]之所以可行,是因为Ruby定义了数组比较的方式。比较由Array#定义方法:Arraysarecompared
为什么需要NFT市场?NFTMarketplace允许用户购买、出售、交易、查看或创建自己的NFT,就像他们需要一个市场来购买物理或数字世界中的大多数产品一样。几乎每个人都可以进入NFT市场,但要做到这一点,用户必须满足以下要求:一个NFT市场用户账户,允许您在给定平台上购买NFT。你需要一个与区块链兼容的加密钱包来购买NFT。NFTMarketplace非常重要,因为它连接了买卖双方,并为用户提供了多种工具来快速创建自己的NFT。艺术家可以在市场上列出要出售的NFT,买家可以通过投标过程探索市场并购买物品。NFT市场开发过程解释创建NFT市场是一个耗时的过程,需要编程知识和理解。那么搭建NF
在Ruby中是否有一种平台无关的方式将EOF符号写入字符串。在*nix中,我认为符号是^D,但在Windows中是^Z,这就是我问的原因。 最佳答案 EOF不是一个字符,它是一个状态。终端使用控制字符来表示此状态(C-d)。没有这样的事情是“读一个EOF字符”,写一个也是一样的。如果您正在写入文件,请在完成后将其关闭。看这个mailinglistpost:ItsoundslikeyouarethinkingofEOFasanin-bandbutspecialcharactervaluethatmarkstheendoffile.It
我正在使用Ruby1.8.7。我有以下哈希数组。我需要先按boolean值排序,但这些结果也必须按原始顺序排序。我基本上需要将所有真正的哈希转移到数组的顶部,但保持原始顺序。如有任何帮助,我们将不胜感激!array=[{:id=>1,:accepts=>false},{:id=>2,:accepts=>false},{:id=>3,:accepts=>true},{:id=>4,:accepts=>false},{:id=>5,:accepts=>true}]sorted=array.sortdo|x,y|ifx[:accepts]==y[:accepts]0elsifx[:accep
我正在使用RubyonRails3.0.9,我想验证一个只能包含字符(不是特殊字符-不区分大小写)、空格和数字的字符串。在我的验证码中我有:validates:name,:presence=>true,:format=>{:with=>regex}#HereIshouldsetthe'regex'我应该如何声明正则表达式? 最佳答案 有几种方法可以做到这一点。如果你只想允许ASCII单词字符(没有像Ê这样的重音字符或来自其他字母表的字母,如Ӕ或ל),使用这个:/^[a-zA-Z\d\s]*$/如果您只想为Ruby1.8.7允许来自其
我在使用Ruby中的gsub方法时尝试使用一个字符串。问题是我有一个动态字符串数组,我需要遍历它以搜索原始文本并替换为。例如,如果我有以下原始字符串(这是我正在使用的一些示例文本,希望它能正常工作)并且有一组我想要搜索和替换的项目。提前感谢您的帮助! 最佳答案 这是您要找的吗?ruby-1.9.2-p0>arr=["Thisissomesampletext","textfile"]=>["Thisissomesampletext","textfile"]ruby-1.9.2-p0>arr=arr.map{|s|s.gsub(/tex
近年来,随着信息化时代的到来,三维全景拼接以视频监控领域为代表的智能硬件公司迅速崛起,随后全国各地在视频监控领域进行了大量的建设。但随着摄像头数量的增加,视频监控画面离散、庞杂、关联性差等诸多问题日渐凸显。如何优化现有视频技术,助力管理者或使用者有效、直观、准确地掌控现场实时动态,成为我国信息化前行路上面临的新课题。视频融合技术平台解决方案北京智汇云舟科技有限公司成立于2012年,专注于创新性的“视频孪生(实时实景数字孪生)”技术研发与应用。公司依托自研三维地理信息引擎(3DGIS),融合建筑信息模型(BIM)、视频监控(Video)、人工智能(AI)及物联网(IOT)等多种技术,并在此基础上
我正在开发一个只适用于JRuby平台的gem。如何在我的.gemspec中指定它? 最佳答案 你可以简单地输入gemspecspec.platform='java'表示它仅适用于JRuby。具体设置平台可以看一下:RubygemSpecificationReference 关于ruby-如何指定gem仅是JRuby平台?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/189366
对于类似Travian的在线策略游戏,我有一些(我认为)非常棒的想法。有些内容我还没有想通,还有一些我还不知道的挑战。这是一个相当大的项目,对于(还)不是熟练的Web开发人员的人来说可能太重了。我还是想试一试,但我在选择平台时遇到了麻烦。世界上的“规模”最近被抛得一团糟,我看到RubyonRails因规模不佳而受到抨击,所以我来这里是为了得到一些答案。我喜欢RubyonRails,无论是Ruby还是Rails。我当然不是这方面的专家,但我喜欢使用它。我之前也使用过Python+Django,也使用过PHP(我不喜欢它。)理想情况下,假设每个服务器有7000名玩家,大概每秒要处理大量数据