概述
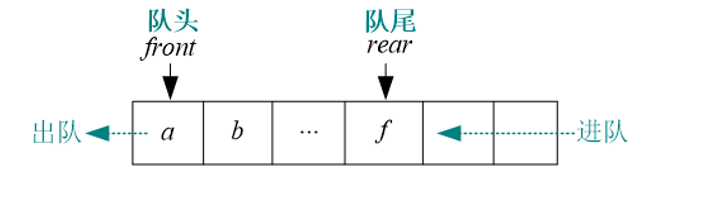
1.先进先出的线性序列,称为队列,队列也是一种线性表,只不过它是操作受限的线性表,只能在两端操作。一端进,一端出。进的一端称为队尾,出的一端称为队头,队列可以用顺序存储也可以用链式存储。
2.队列的顺序存储形式,可以用一段连续的空间存储数据元素,用两个整型变量记录队头和队尾元素的下标。
3初始化
(1)
base为数组的基地址,front,base分别代表指向队头和队尾的"指针"(数组下标),构造空队列只需要申请一块内存给基地址,并且将队头指针与队尾指针赋值为0.

(2)
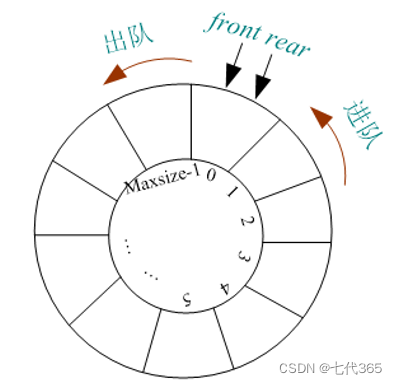
因为该队列为循环队列所以
typedef struct SqQueue
{
int* base;
int front, rear;
}SqQueue;
//构造空队列
bool InitQueue(SqQueue& Q)
{
Q.base = new int[Maxsize];
if (Q.base == NULL)
{
return false;
}
Q.front = Q.rear = 0;
return true;
}
4入队
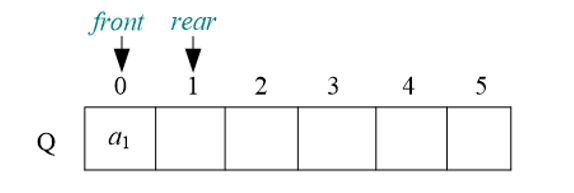
(1)将队尾指向的位置赋值,并且赋值后将队尾的位置后移
(2)在入队时难免会出现以下情况

队列的空间未利用完,但是却造成了元素的溢出(又称"假溢出"),所以要利用循环队列,这样就不会有这样的顾虑

入队的操作为
Q.base[Q.rear]=e; 将元素e放入Q.rear指向的空间
Q.rear=(Q.rear+1)%Maxsize rear指针向后移动一个单位
至于为什么要加对(Q.rear+1)取模,这是因为rear指针会一直增加到比队列容量大的数字,对其取模就是为了使其缩小,指向真正的位置例如 容量大小为5 队尾指向9 取模队尾指向的是4,说明队尾指正已经走过了一个圈
tips:在入队前要判断队列是否为空怎们办

如图此时队尾指向的是循环队列的最后一个空间,这个空间并没有存放任何数据,判断队列是否为满只要将队尾指针+1看看其是否与队头相等,此处为什么要取模?
例如队列空间大小为10,队尾指向第10个空间,下标为9,对其加1等于10,取模等于0,此时队头也是指向0的所以需要取模
有例如如果一开始队头指向的是1,队尾指向的是0,那么队尾加1,取模后为1,那么此时对也满
//入队
bool Push(SqQueue& Q, int e)
{
if ((Q.rear + 1) % Maxsize == Q.front)
{
cout << "队满" << endl;
return false;
}
Q.base[Q.rear] = e;
Q.rear = (Q.rear + 1) % Maxsize;
return true;
}5出队
出队前判断队列是否为空
当尾指针与头指针指向一起时队空,注意与队满的区别
出队的操作
e=Q.base[Q.front];
Q.front=[Q.front+1]%Maxsize;
将头指针向着元素增长方向移动一个单元,原来的头指针指向的元素并没有真正的删除,只是逻辑上的删除,后序如果要用到这个空间,会用新的元素将其覆盖掉
至于为什么要用取模和上述的入队是一致的

bool Pop(SqQueue& Q, int& e)
{
if (Q.rear == Q.front)
{
cout << "队空" << endl;
return false;
}
e = Q.base[Q.front];
Q.front = (Q.front + 1) % Maxsize;
}
6.获取队头元素
判断队列是否为空
简单的数组取元素而已
int Get_front(SqQueue Q)
{
if (Q.rear == Q.front)
{
cout << "队空" << endl;
return -1;
}
return Q.base[Q.front];
}
7.获取队尾元素
判断队列是否为空
因为队尾一直指向最后一个元素的后一个位置,所以要去指正前面的空间,就是队尾元素
int Get_back(SqQueue Q)
{
if (Q.front == Q.rear)
{
cout << "队空" << endl;
return -1;
}
return Q.base[Q.rear - 1];
}8.获取队列元素个数
这两段的代码意思是一样的
因为队尾减队头可能会出现负数,所以需要加上容量大小后取模,这样才会得到真实的容量大小
例如队列大小6,队尾指向1,队头指向2,那么元素个数为(1-2+6)%6=5个
例如队列大小6,队尾指向5,队头指向0,那么元素个数为(5-0+6)%6=5个
int length(SqQueue Q)
{
return (Q.rear - Q.front + MaxSize) % MaxSize;
/*if (Q.rear - Q.front >= 0)
{
return Q.rear - Q.front;
}
else
{
return (Q.rear - Q.front + MaxSize);
}*/
}完整代码如下
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<algorithm>
using namespace std;
const int MaxSize = 100;
typedef struct SqQueue
{
int* base;
int front, rear;
}SqQueue;
bool InitQueue(SqQueue& Q)
{
Q.base = new int[MaxSize];
if (Q.base == NULL)
{
return false;
}
Q.front = Q.rear = 0;
return true;
}
bool Push(SqQueue& Q, int e)
{
if ((Q.rear + 1) % MaxSize == Q.front)
{
return false;
}
Q.base[Q.rear] = e;
Q.rear = (Q.rear + 1) % MaxSize;
return true;
}
bool Pop(SqQueue& Q, int& e)
{
if (Q.rear == Q.front)
{
return false;
}
e = Q.base[Q.front];
Q.front = (Q.front + 1) % MaxSize;
}
int Get_front(SqQueue Q)
{
if (Q.front == Q.rear)
{
return -1;
}
return Q.base[Q.front];
}
int Get_back(SqQueue Q)
{
if (Q.front == Q.rear)
{
return -1;
}
return Q.base[Q.rear - 1];
}
int length(SqQueue Q)
{
return (Q.rear - Q.front + MaxSize) % MaxSize;
/*if (Q.rear - Q.front >= 0)
{
return Q.rear - Q.front;
}
else
{
return (Q.rear - Q.front + MaxSize);
}*/
}
int main()
{
SqQueue S;
InitQueue(S);
int n = 0;
cout << "请输入有多少元素" << endl;
cin >> n;
cout << "依次输入元素" << endl;
while (n--)
{
int e;
cin >> e;
Push(S, e);
}
int L = length(S);
for (int i = 0; i < L; i++)
{
cout << "队尾:"<<Get_back(S) << " "<<"队头:"<<Get_front(S)<<"---";
int e = 0;
Pop(S, e);
cout << e <<" ";
cout << endl;
}
//cout << length(S);
cout << endl;
system("pause");
return EXIT_SUCCESS;
}
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我是Ruby的新手,有些闭包逻辑让我感到困惑。考虑这段代码:array=[]foriin(1..5)array[5,5,5,5,5]这对我来说很有意义,因为i被绑定(bind)在循环之外,所以每次循环都会捕获相同的变量。使用每个block可以解决这个问题对我来说也很有意义:array=[](1..5).each{|i|array[1,2,3,4,5]...因为现在每次通过时都单独声明i。但现在我迷路了:为什么我不能通过引入一个中间变量来修复它?array=[]foriin1..5j=iarray[5,5,5,5,5]因为j每次循环都是新的,我认为每次循环都会捕获不同的变量。例如,这绝对
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
假设我有一个没有特定顺序的随机数数组。假设这些是参加马拉松比赛的人的ID#,他们按照完成的顺序添加到数组中,例如:race1=[8,102,67,58,91,16,27]race2=[51,31,7,15,99,58,22]这是一个简化且有些做作的示例,但我认为它传达了基本思想。现在有几个问题:首先,我如何获得特定条目之前和之后的ID?假设我正在查看运行者58,我想知道谁在他之前和之后完成了比赛。race1,runner58:previousfinisher=67,nextfinisher=91race2,runner58:previousfinisher=99,nextfinishe
defreverse(ary)result=[]forresult[0,0]inaryendresultendassert_equal["baz","bar","foo"],reverse(["foo","bar","baz"])这行得通,我想了解原因。有什么解释吗? 最佳答案 如果我使用each而不是for/in重写它,它看起来像这样:defreverse(ary)result=[]#forresult[0,0]inaryary.eachdo|item|result[0,0]=itemendresultendforainb基本上就
在EloquentRuby(第21页,第一版,第六次打印)一书中,作者(RussOlsen)提倡使用each方法而不是for循环,这与我在其他地方读到的所有内容一致。但是作者还继续说,这样做的一个原因是for循环实际上调用了each方法,所以为什么不直接删掉中间人并使用each?所以我想知道这实际上是如何工作的。为了调查,我确实在github上的Ruby存储库上进行了搜索,但发现很难确定我在哪里/如何看到它的实际效果。重述问题:我如何证明Rubyfor循环实际上是使用each方法实现的? 最佳答案 您可以通过编写一个实现每个的类来展
我想从0到2循环@a:0,1,2,0,1,2。defset_aif@a==2@a=0else@a=@a+1endend也许有更好的方法? 最佳答案 (0..2).cycle(3){|x|putsx}#=>0,1,2,0,1,2,0,1,2item=[0,1,2].cycle.eachitem.next#=>0item.next#=>1item.next#=>2item.next#=>0... 关于ruby-循环遍历数组的元素,我们在StackOverflow上找到一个类似的问题: