文章目录
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别:
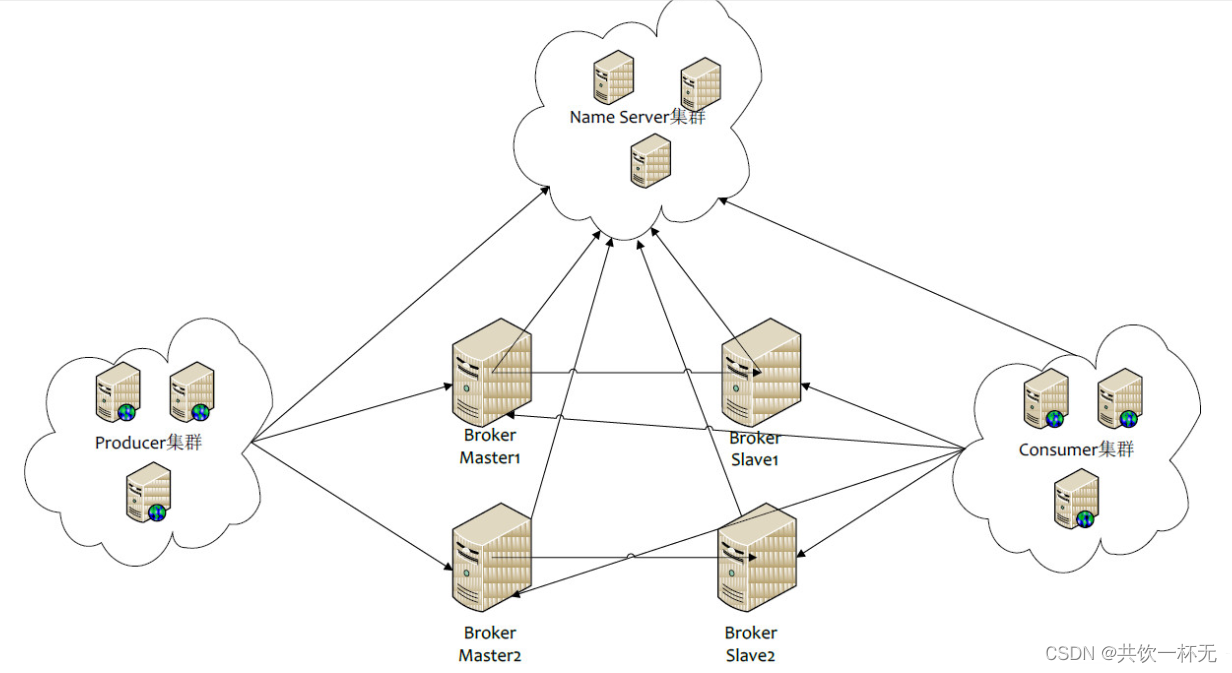
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave 读,当Master不可用或者繁忙的时候,Consumer会被自动切换到从Slave 读。
有了自动切换Consumer这种机制,当一个Master角色的机器出现故障后,Consumer仍然可以从Slave读取消息,不影响Consumer程序。这就达到了消费端的高可用性
如何达到发送端的高可用性呢?
在创建Topic的时候,把Topic的多个Message Queue创建在多个Broker组上(相同Broker名称,不同brokerId的机器组成一个Broker组),这样既可以在性能方面具有扩展性,也可以降低主节点故障对整体上带来的影响,而且当一个Broker组的Master不可用后,其他组的Master仍然可用,Producer仍然可以发送消息的。
RocketMQ目前还不支持把Slave自动转成Master,如果机器资源不足,需要把Slave转成Master。可以按照如下步骤操作:
对于一个消息队列集群来说,系统由很多机器组成,每个机器的角色、IP地址都不相同,而且这些信息是变动的(如在某些情况下,会有新的Producer或Consumer加入)。
NameServer的存在主要是为了解决这类问题,由NameServer维护这些配置信息、状态信息,其他角色都通过NameServer来协同执行。
NameServer是整个消息队列中的状态服务器,集群的各个组件通过它来了解全局的信息。各个角色的机器要定时向NameServer上报自己的状态,如果超时未上报,NameServer会认为某个机器出故障不可用了,其他的组件会把这个机器从可用列表中删除。
NameServer可以部署多个,相互之间独立,其他角色同时向多个NameServer上报状态信息,从而达到热备份的目的。NameServer本身是无状态的,也就是说NameServer中的Broker、Topic等信息都不会持久化,都是由各个角色定时上报并存储到内存中的(NameServer支持参数的持久化,一般用不到)。
在nameserver模块下的RouteInfoManager可以看到有五个HashMap变量保存了集群的信息。
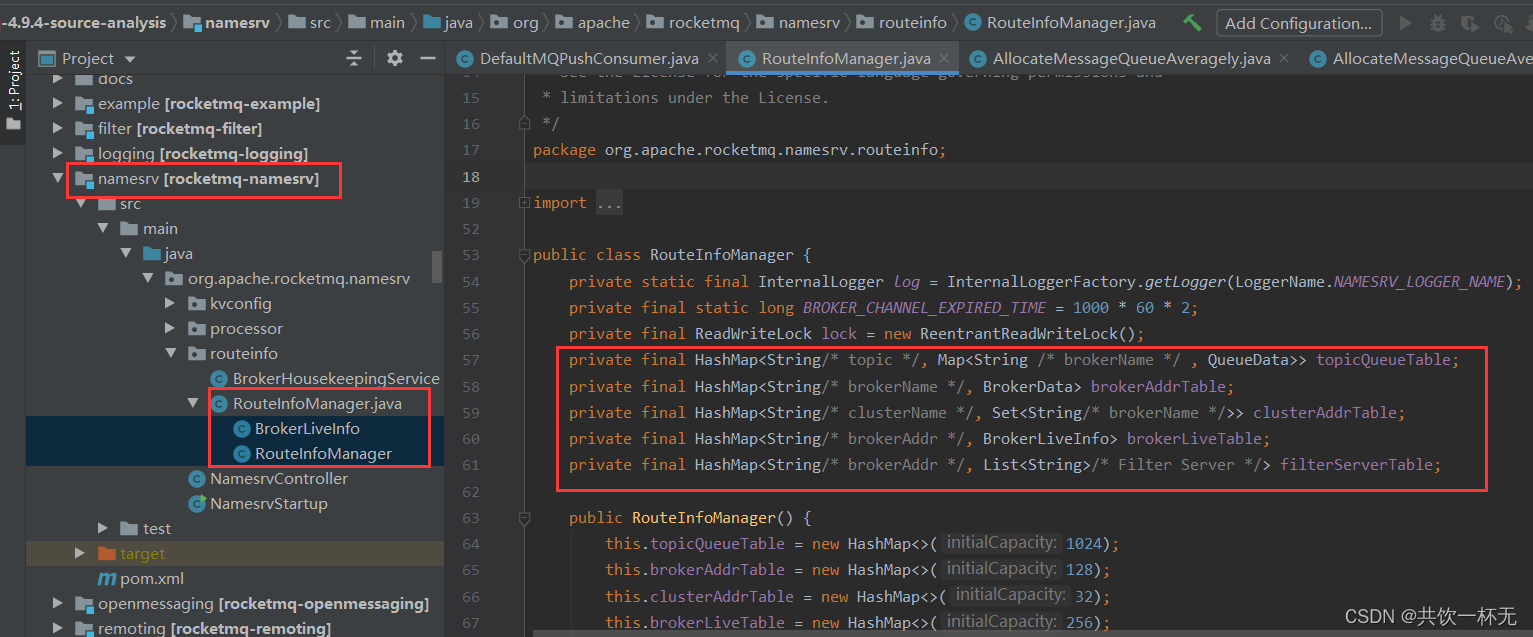
/**
* 存储所有Topic与Broker关联的属性信息
*/
private final HashMap<String/* topic */, Map<String /* brokerName */ , QueueData>> topicQueueTable;
/**
* 存储BrokerName对应的属性信息
*/
private final HashMap<String/* brokerName */, BrokerData> brokerAddrTable;
/**
* 存储集群的信息
*/
private final HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;
/**
* 存储Broker机器的实时状态
*/
private final HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
/**
* 存储过滤服务器信息
*/
private final HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
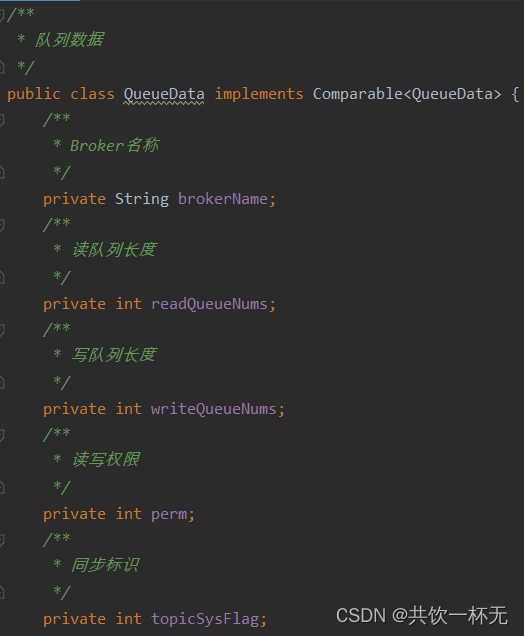
HashMap<String/* topic */, Map<String /* brokerName */ , QueueData>> topicQueueTable;
key:Topic的名称。
value:value是个一个Map集合,集合中存的brokerName与QueueData(队列数据)的关联信息。QueueData存储着Broker的名称,读写Queue的数量、同步标识等。
HashMap<String/* brokerName */, BrokerData> brokerAddrTable;
key:brokerName
value:BrokerData里面存了broker相关数据信息。

HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;
key:cluster(集群)的名称
value:Broker Name组成的集合。
即一个cluster名称对应的一个BrokerName的集合。
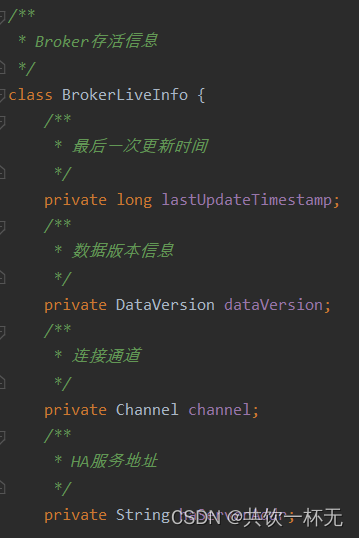
HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
key:Broker的地址,brokerAddr 对应着一台机器。
value:BrokerLiveInfo存储的内容是这台 Broker 机器的实时状态,包括上次更新状态的时间戳,NameServer 会定期检查这个时间戳,超时没有更新就认为这个 Broker 无效了,将其从 Broker 列表里清除。
HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
key:BrokerAddr
value:FilterServer的地址列表。
Filter Server是过滤服务器,是RocketMQ的一种服务端过滤方式。一个Broker可以有一个或多个Filter Server。
总结:NameServer 通过 brokerLiveInfo 来维护存活的 Broker。Producer 会获取上面的路由信息,发送消息的时候指定发送到哪个 Topic,根据 Topic 可以从 topicQueueTable 选择一个 Broker,根据 BrokerName 可以从 BrokerAddrTable 获取到Broker IP 地址。有了地址 Producer 就可以将消息通过网络传递给 Broker。
Zookeeper为分布式应用程序提供协调服务,Zookeeper的功能很强大,包括自动Master选举,RocketMQ的设计决定了它不需要进行Master选举,用不到这些复杂的功能,只需要一个轻量级的元数据服务器就足够了。
中间件对稳定性要求很高,RocketMQ的NameServer只有很少的代码,容易维护,所以不需要再依赖另一个中间件,从而减少整体维护成本。
本文内容到此结束了,
如有收获欢迎点赞👍收藏💖关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问💬欢迎各位指出。
主页:共饮一杯无的博客汇总👨💻保持热爱,奔赴下一场山海。🏃🏃🏃

我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
我有一个Ruby数组[1,4]。我想在中间插入另一个数组[2,3],这样它就变成了[1,2,3,4]。我可以使用[1,4].insert(1,[2,3]).flatten实现这一点,但是有更好的方法吗? 最佳答案 您可以通过以下方式进行。[1,4].insert(1,*[2,3])insert()方法处理多个参数。因此,您可以使用splat运算符*将数组转换为参数。 关于ruby-如何在数组中间插入一个数组?,我们在StackOverflow上找到一个类似的问题:
在rails开发环境中,cache_classes是关闭的,所以你可以修改app/下的代码,不用重启服务器就可以看到变化。不过,在所有环境中,中间件只会创建一次。所以如果我有这样的中间件:classMyMiddlewaredefinitialize(app)@app=appenddefcall(env)env['model']=MyModel.firstendend我在config/environments/development.rb中执行此操作:config.cache_classes=false#thedefaultfordevelopmentconfig.middleware.
有没有办法在liquidtemplate中输出(用于调试/信息目的)可用对象和对象属性??也就是说,假设我正在使用jekyll站点生成工具,并且我在我的index.html模板中(据我所知,这是一个液体模板)。它可能看起来像这样{%forpostinsite.posts%}{{post.date|date_to_string}}»{{post.title}}{%endfor%}是否有任何我可以使用的模板标签会告诉我/输出名为post的变量在此模板(以及其他模板)中可用。此外,是否有任何模板标签可以告诉我post对象具有键date、title、url、摘录、永久链接等
如果有人有兴趣将PDF文件保存在PDFKit中间件gem显示的文件系统中,那么这里是...重写middleware.rb文件的call方法。在覆盖中只需替换这一行:body=PDFKit.new(translate_paths(body,env),@options).to_pdf与pdf=PDFKit.new(translate_paths(body,env),@options)file=pdf.to_file('Your/file/name/path')Mymodel.my_method()#Youcanwriteyourmethodheretousethatfilebody=pdf
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代
我尝试在我的应用中只使用:symbols作为关键词。我尝试在:symbol=>logic或string=>UI/languagespecific之间做出严格的决定但我也得到了每个JSON的一些“值”(即选项等),因为JSON中没有:symbols,所以我调用的所有哈希都具有“with_indifferent_access”属性。但是:数组是否有相同的东西?像那样a=['std','elliptic',:cubic].with_indifferent_accessa.include?:std=>true?编辑:将rails添加到标签 最佳答案
我的Rails4应用程序使用了一个自定义Rack中间件。如果客户端未提供有效信息(我'正在开发API)。因此,在每个请求之前它会更改这些header,并且在每个请求之后它会添加一个带有自定义媒体类型信息的自定义X-Something-Media-Typeheader。我想切换到Puma,因此我有点担心这种中间件的线程安全性。我没有使用实例变量,除了我们在每个中间件中遇到的常见@app.call一次,但即使在这里我也复制了一些我在RailsCasts的评论中读到的内容:definitialize(app)@app=appenddefcall(env)dup._call(env)endde